In partnership withHPE
Training an AI model to predict equipment failures is an engineering achievement. But it’s not until prediction meets action—the moment that model successfully flags a malfunctioning machine—that true business transformation occurs. One technical milestone lives in a proof-of-concept deck; the other meaningfully contributes to the bottom line.
Craig Partridge, senior director worldwide of Digital Next Advisory at HPE, believes “the true value of AI lies in inference”. Inference is where AI earns its keep. It’s the operational layer that puts all that training to use in real-world workflows. Partridge elaborates, “The phrase we use for this is ‘trusted AI inferencing at scale and in production,'” he says. “That’s where we think the biggest return on AI investments will come from.”
Getting to that point is difficult. Christian Reichenbach, worldwide digital advisor at HPE, points to findings from the company’s recent survey of 1,775 IT leaders: While nearly a quarter (22%) of organizations have now operationalized AI—up from 15% the previous year—the majority remain stuck in experimentation.
Reaching the next stage requires a three-part approach: establishing trust as an operating principle, ensuring data-centric execution, and cultivating IT leadership capable of scaling AI successfully.
Trust as a prerequisite for scalable, high-stakes AI
Trusted inference means users can actually rely on the answers they’re getting from AI systems. This is important for applications like generating marketing copy and deploying customer service chatbots, but it’s absolutely critical for higher-stakes scenarios—say, a robot assisting during surgeries or an autonomous vehicle navigating crowded streets.
Whatever the use case, establishing trust will require doubling down on data quality; first and foremost, inferencing outcomes must be built on reliable foundations. This reality informs one of Partridge’s go-to mantras: “Bad data in equals bad inferencing out.”
Reichenbach cites a real-world example of what happens when data quality falls short—the rise of unreliable AI-generated content, including hallucinations, that clogs workflows and forces employees to spend significant time fact-checking. “When things go wrong, trust goes down, productivity gains are not reached, and the outcome we’re looking for is not achieved,” he says.
On the other hand, when trust is properly engineered into inference systems, efficiency and productivity gains can increase. Take a network operations team tasked with troubleshooting configurations. With a trusted inferencing engine, that unit gains a reliable copilot that can deliver faster, more accurate, custom-tailored recommendations—”a 24/7 member of the team they didn’t have before,” says Partridge.
The shift to data-centric thinking and rise of the AI factory
In the first AI wave, companies rushed to hire data scientists and many viewed sophisticated, trillion-parameter models as the primary goal. But today, as organizations move to turn early pilots into real, measurable outcomes, the focus has shifted toward data engineering and architecture.
“Over the past five years, what’s become more meaningful is breaking down data silos, accessing data streams, and quickly unlocking value,” says Reichenbach. It’s an evolution happening alongside the rise of the AI factory—the always-on production line where data moves through pipelines and feedback loops to generate continuous intelligence.
This shift reflects an evolution from model-centric to data-centric thinking, and with it comes a new set of strategic considerations. “It comes down to two things: How much of the intelligence–the model itself–is truly yours? And how much of the input–the data–is uniquely yours, from your customers, operations, or market?” says Reichenbach.
These two central questions inform everything from platform direction and operating models to engineering roles and trust and security considerations. To help clients map their answers—and translate them into actionable strategies—Partridge breaks down HPE’s four-quadrant AI factory implication matrix (see figure):
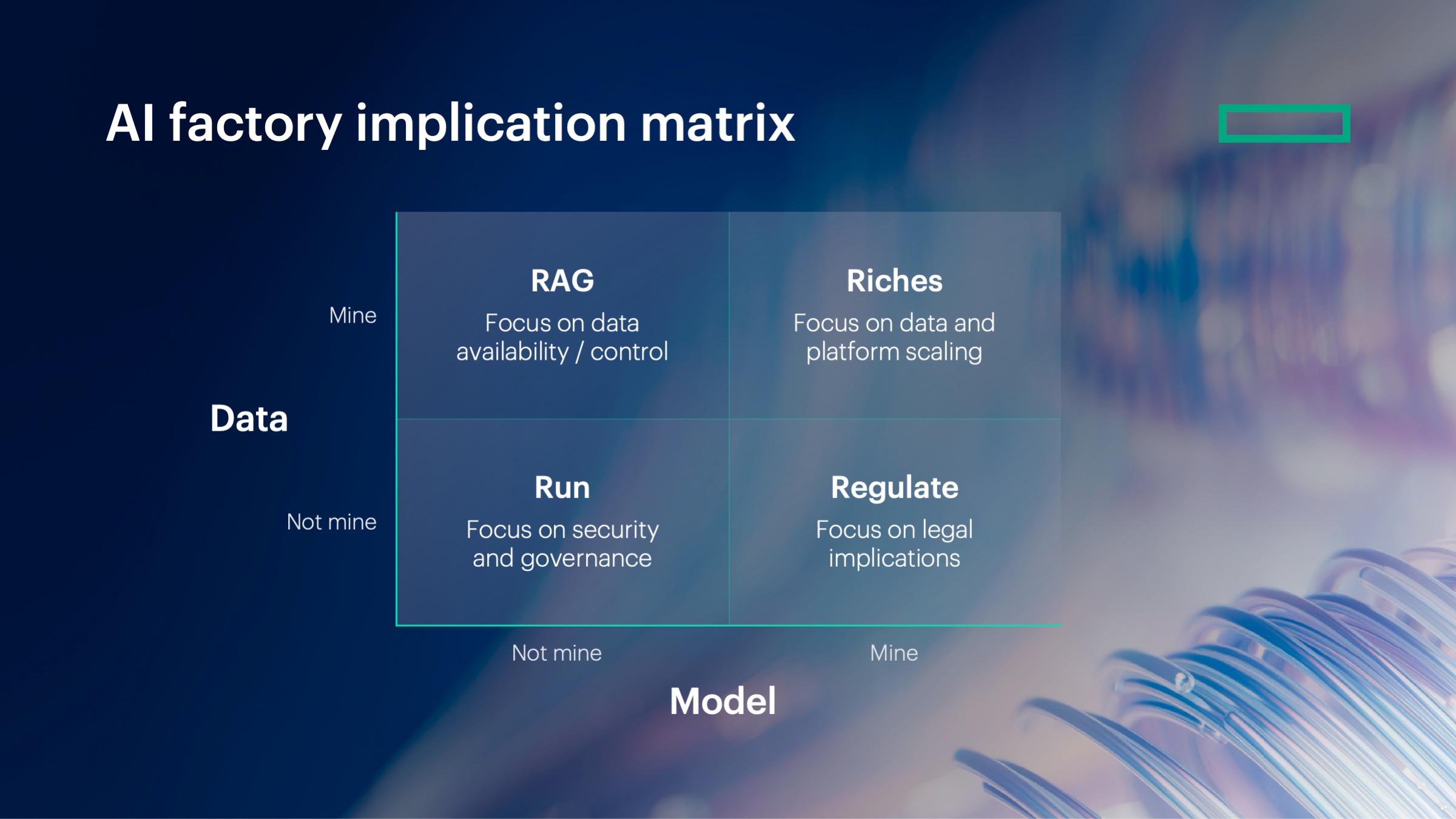
Source: HPE, 2025
- Run: Accessing an external, pretrained model via an interface or API; organizations don’t own the model or the data. Implementation requires strong security and governance. It also requires establishing a center of excellence that makes and communicates decisions about AI usage.
- RAG (retrieval augmented generation): Using external, pre-trained models combined with a company’s proprietary data to create unique insights. Implementation focuses on connecting data streams to inferencing capabilities that provide rapid, integrated access to full-stack AI platforms.
- Riches: Training custom models on data that resides in the enterprise for unique differentiation opportunities and insights. Implementation requires scalable, energy-efficient environments, and often high-performance systems.
- Regulate: Leveraging custom models trained on external data, requiring the same scalable setup as Riches, but with added focus on legal and regulatory compliance for handling sensitive, non-owned data with extreme caution.
Importantly, these quadrants are not mutually exclusive. Partridge notes that most organizations—including HPE itself—operate across many of the quadrants. “We build our own models to help understand how networks operate,” he says. “We then deploy that intelligence into our products, so that our end customer gets the chance to deliver in what we call the ‘Run’ quadrant. So for them, it’s not their data; it’s not their model. They’re just adding that capability inside their organization.”
IT’s moment to scale—and lead
The second part of Partridge’s catchphrase about inferencing—”at scale”— speaks to a primary tension in enterprise AI: what works for a handful of use cases often breaks when applied across an entire organization.
“There’s value in experimentation and kicking ideas around,” he says. “But if you want to really see the benefits of AI, it needs to be something that everybody can engage in and that solves for many different use cases.”
In Partridge’s view, the challenge of turning boutique pilots into organization-wide systems is uniquely suited to the IT function’s core competencies—and it’s a leadership opportunity the function can’t afford to sit out. “IT takes things that are small-scale and implements the discipline required to run them at scale,” he says. “So, IT organizations really need to lean into this debate.”
For IT teams content to linger on the sidelines, history offers a cautionary tale from the last major infrastructure shift: enterprise migration to the cloud. Many IT departments sat out decision-making during the early cloud adoption wave a decade ago, while business units independently deployed cloud services. This led to fragmented systems, redundant spending, and security gaps that took years to untangle.
The same dynamic threatens to repeat with AI, as different teams experiment with tools and models outside IT’s purview. This phenomenon—sometimes called shadow AI—describes environments where pilots proliferate without oversight or governance. Partridge believes that most organizations are already operating in the “Run” quadrant in some capacity, as employees will use AI tools whether or not they’re officially authorized to.
Rather than shut down experimentation, it is now IT’s mandate to bring structure to it. And enterprises must architect a data platform strategy that brings together enterprise data with guardrails, governance framework, and accessibility to feed AI. Also, it’s critical to keep standardizing infrastructure (such as private cloud AI platforms), protecting data integrity, and safeguarding brand trust, all while enabling the speed and flexibility that AI applications demand. These are the requirements for reaching the final milestone: AI that’s truly in production.
For teams on the path to that goal, Reichenbach distills what success requires. “It comes down to knowing where you play: When to Run external models smarter, when to apply RAG to make them more informed, where to invest to unlock Riches from your own data and models, and when to Regulate what you don’t control,” says Reichenbach. “The winners will be those who bring clarity to all quadrants and align technology ambition with governance and value creation.”
For more, register to watch MIT Technology Review’s EmTech AI Salon, featuring HPE.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff. It was researched, designed, and written by human writers, editors, analysts, and illustrators. This includes the writing of surveys and collection of data for surveys. AI tools that may have been used were limited to secondary production processes that passed thorough human review.




















