Introduction
Many generative AI use cases still revolve around Retrieval Augmented Generation (RAG), yet consistently fall short of user expectations. Despite the growing body of research on RAG improvements and even adding Agents into the process, many solutions still fail to return exhaustive results, miss information that is critical but infrequently mentioned in the documents, require multiple search iterations, and generally struggle to reconcile key themes across multiple documents. To top it all off, many implementations still rely on cramming as much “relevant” information as possible into the model’s context window alongside detailed system and user prompts. Reconciling all this information often exceeds the model’s cognitive capacity and compromises response quality and consistency.
This is where our Agentic Knowledge Distillation + Pyramid Search Approach comes into play. Instead of chasing the best chunking strategy, retrieval algorithm, or inference-time reasoning method, my team, Jim Brown, Mason Sawtell, Sandi Besen, and I, take an agentic approach to document ingestion.
We leverage the full capability of the model at ingestion time to focus exclusively on distilling and preserving the most meaningful information from the document dataset. This fundamentally simplifies the RAG process by allowing the model to direct its reasoning abilities toward addressing the user/system instructions rather than struggling to understand formatting and disparate information across document chunks.
We specifically target high-value questions that are often difficult to evaluate because they have multiple correct answers or solution paths. These cases are where traditional RAG solutions struggle most and existing RAG evaluation datasets are largely insufficient for testing this problem space. For our research implementation, we downloaded annual and quarterly reports from the last year for the 30 companies in the DOW Jones Industrial Average. These documents can be found through the SEC EDGAR website. The information on EDGAR is accessible and able to be downloaded for free or can be queried through EDGAR public searches. See the SEC privacy policy for additional details, information on the SEC website is “considered public information and may be copied or further distributed by users of the web site without the SEC’s permission”. We selected this dataset for two key reasons: first, it falls outside the knowledge cutoff for the models evaluated, ensuring that the models cannot respond to questions based on their knowledge from pre-training; second, it’s a close approximation for real-world business problems while allowing us to discuss and share our findings using publicly available data.
While typical RAG solutions excel at factual retrieval where the answer is easily identified in the document dataset (e.g., “When did Apple’s annual shareholder’s meeting occur?”), they struggle with nuanced questions that require a deeper understanding of concepts across documents (e.g., “Which of the DOW companies has the most promising AI strategy?”). Our Agentic Knowledge Distillation + Pyramid Search Approach addresses these types of questions with much greater success compared to other standard approaches we tested and overcomes limitations associated with using knowledge graphs in RAG systems.
In this article, we’ll cover how our knowledge distillation process works, key benefits of this approach, examples, and an open discussion on the best way to evaluate these types of systems where, in many cases, there is no singular “right” answer.
Building the pyramid: How Agentic Knowledge Distillation works
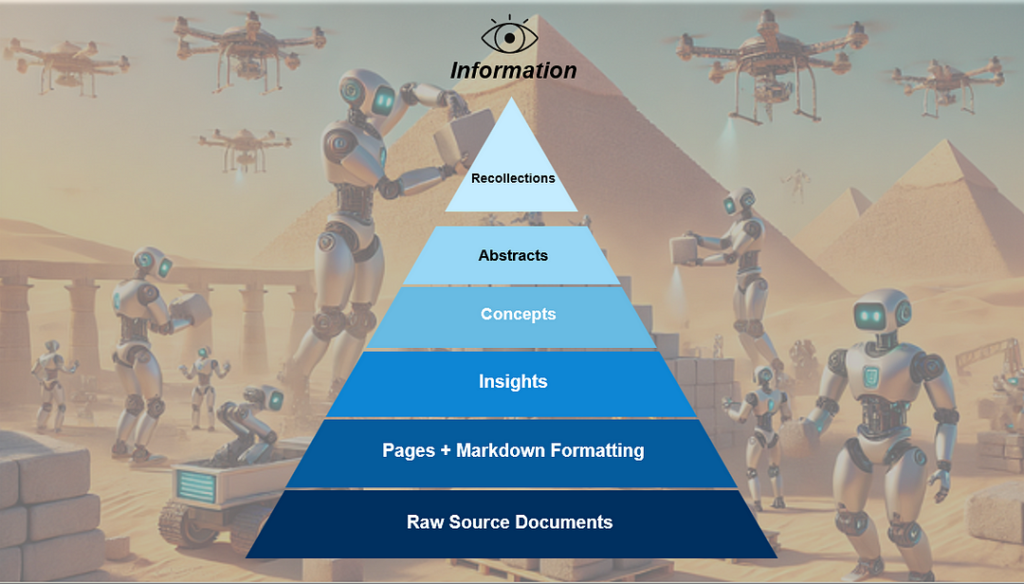
Overview
Our knowledge distillation process creates a multi-tiered pyramid of information from the raw source documents. Our approach is inspired by the pyramids used in deep learning computer vision-based tasks, which allow a model to analyze an image at multiple scales. We take the contents of the raw document, convert it to markdown, and distill the content into a list of atomic insights, related concepts, document abstracts, and general recollections/memories. During retrieval it’s possible to access any or all levels of the pyramid to respond to the user request.
How to distill documents and build the pyramid:
- Convert documents to Markdown: Convert all raw source documents to Markdown. We’ve found models process markdown best for this task compared to other formats like JSON and it is more token efficient. We used Azure Document Intelligence to generate the markdown for each page of the document, but there are many other open-source libraries like MarkItDown which do the same thing. Our dataset included 331 documents and 16,601 pages.
- Extract atomic insights from each page: We process documents using a two-page sliding window, which allows each page to be analyzed twice. This gives the agent the opportunity to correct any potential mistakes when processing the page initially. We instruct the model to create a numbered list of insights that grows as it processes the pages in the document. The agent can overwrite insights from the previous page if they were incorrect since it sees each page twice. We instruct the model to extract insights in simple sentences following the subject-verb-object (SVO) format and to write sentences as if English is the second language of the user. This significantly improves performance by encouraging clarity and precision. Rolling over each page multiple times and using the SVO format also solves the disambiguation problem, which is a huge challenge for knowledge graphs. The insight generation step is also particularly helpful for extracting information from tables since the model captures the facts from the table in clear, succinct sentences. Our dataset produced 216,931 total insights, about 13 insights per page and 655 insights per document.
- Distilling concepts from insights: From the detailed list of insights, we identify higher-level concepts that connect related information about the document. This step significantly reduces noise and redundant information in the document while preserving essential information and themes. Our dataset produced 14,824 total concepts, about 1 concept per page and 45 concepts per document.
- Creating abstracts from concepts: Given the insights and concepts in the document, the LLM writes an abstract that appears both better than any abstract a human would write and more information-dense than any abstract present in the original document. The LLM generated abstract provides incredibly comprehensive knowledge about the document with a small token density that carries a significant amount of information. We produce one abstract per document, 331 total.
- Storing recollections/memories across documents: At the top of the pyramid we store critical information that is useful across all tasks. This can be information that the user shares about the task or information the agent learns about the dataset over time by researching and responding to tasks. For example, we can store the current 30 companies in the DOW as a recollection since this list is different from the 30 companies in the DOW at the time of the model’s knowledge cutoff. As we conduct more and more research tasks, we can continuously improve our recollections and maintain an audit trail of which documents these recollections originated from. For example, we can keep track of AI strategies across companies, where companies are making major investments, etc. These high-level connections are super important since they reveal relationships and information that are not apparent in a single page or document.
We store the text and embeddings for each layer of the pyramid (pages and up) in Azure PostgreSQL. We originally used Azure AI Search, but switched to PostgreSQL for cost reasons. This required us to write our own hybrid search function since PostgreSQL doesn’t yet natively support this feature. This implementation would work with any vector database or vector index of your choosing. The key requirement is to store and efficiently retrieve both text and vector embeddings at any level of the pyramid.
This approach essentially creates the essence of a knowledge graph, but stores information in natural language, the way an LLM natively wants to interact with it, and is more efficient on token retrieval. We also let the LLM pick the terms used to categorize each level of the pyramid, this seemed to let the model decide for itself the best way to describe and differentiate between the information stored at each level. For example, the LLM preferred “insights” to “facts” as the label for the first level of distilled knowledge. Our goal in doing this was to better understand how an LLM thinks about the process by letting it decide how to store and group related information.
Using the pyramid: How it works with RAG & Agents
At inference time, both traditional RAG and agentic approaches benefit from the pre-processed, distilled information ingested in our knowledge pyramid. The pyramid structure allows for efficient retrieval in both the traditional RAG case, where only the top X related pieces of information are retrieved or in the Agentic case, where the Agent iteratively plans, retrieves, and evaluates information before returning a final response.
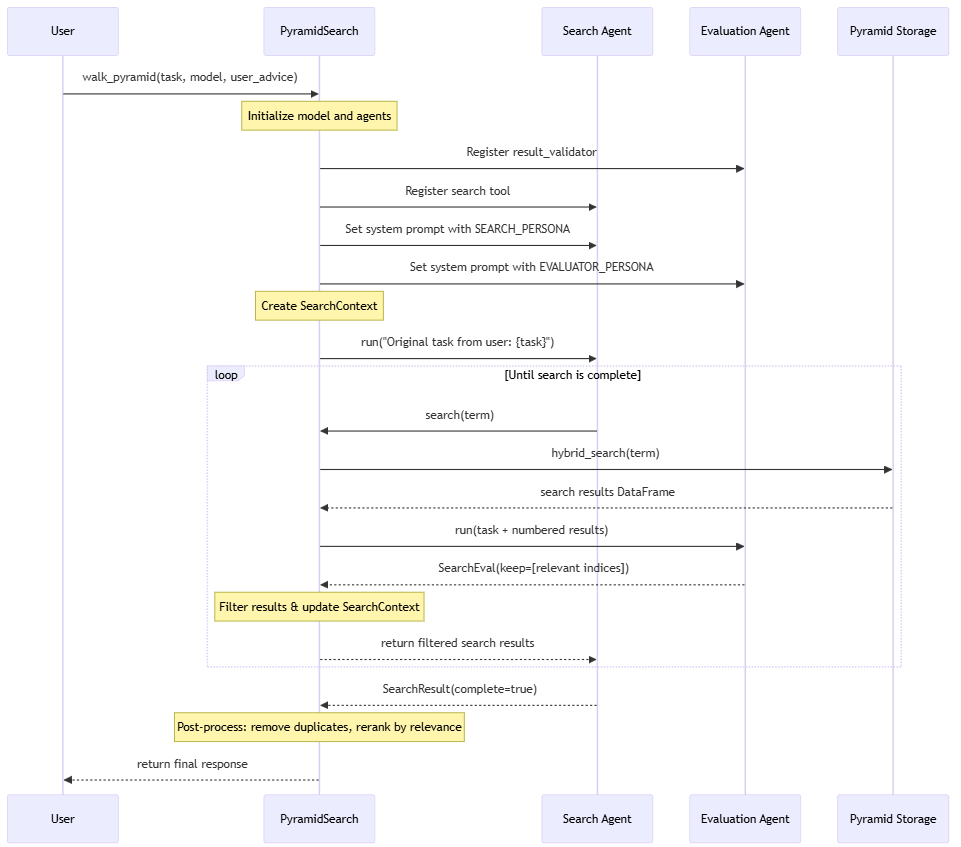
The benefit of the pyramid approach is that information at any and all levels of the pyramid can be used during inference. For our implementation, we used PydanticAI to create a search agent that takes in the user request, generates search terms, explores ideas related to the request, and keeps track of information relevant to the request. Once the search agent determines there’s sufficient information to address the user request, the results are re-ranked and sent back to the LLM to generate a final reply. Our implementation allows a search agent to traverse the information in the pyramid as it gathers details about a concept/search term. This is similar to walking a knowledge graph, but in a way that’s more natural for the LLM since all the information in the pyramid is stored in natural language.
Depending on the use case, the Agent could access information at all levels of the pyramid or only at specific levels (e.g. only retrieve information from the concepts). For our experiments, we did not retrieve raw page-level data since we wanted to focus on token efficiency and found the LLM-generated information for the insights, concepts, abstracts, and recollections was sufficient for completing our tasks. In theory, the Agent could also have access to the page data; this would provide additional opportunities for the agent to re-examine the original document text; however, it would also significantly increase the total tokens used.
Here is a high-level visualization of our Agentic approach to responding to user requests:
Results from the pyramid: Real-world examples
To evaluate the effectiveness of our approach, we tested it against a variety of question categories, including typical fact-finding questions and complex cross-document research and analysis tasks.
Fact-finding (spear fishing):
These tasks require identifying specific information or facts that are buried in a document. These are the types of questions typical RAG solutions target but often require many searches and consume lots of tokens to answer correctly.
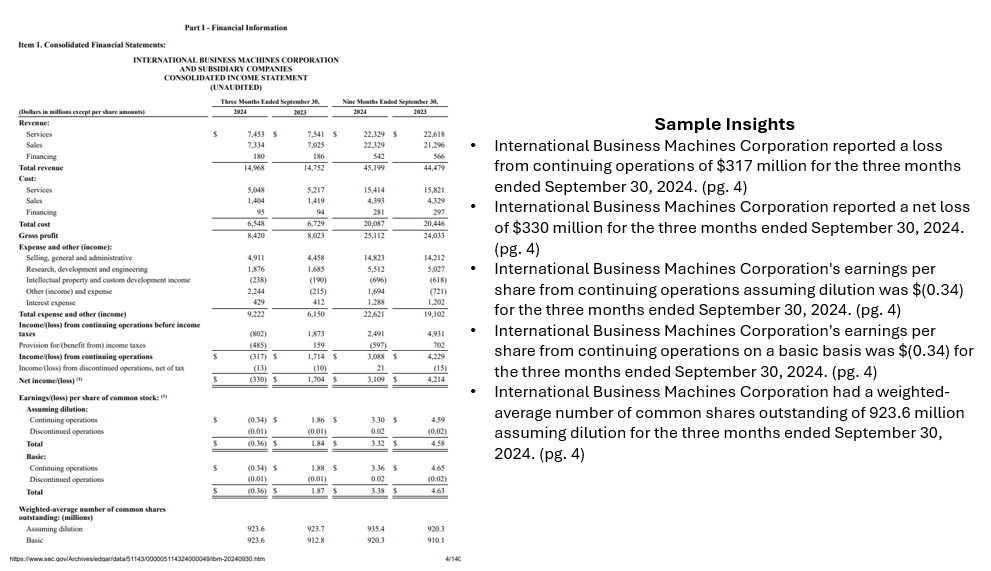
Example task: “What was IBM’s total revenue in the latest financial reporting?”
Example response using pyramid approach: “IBM’s total revenue for the third quarter of 2024 was $14.968 billion [ibm-10q-q3-2024.pdf, pg. 4]

This result is correct (human-validated) and was generated using only 9,994 total tokens, with 1,240 tokens in the generated final response.
Complex research and analysis:
These tasks involve researching and understanding multiple concepts to gain a broader understanding of the documents and make inferences and informed assumptions based on the gathered facts.
Example task: “Analyze the investments Microsoft and NVIDIA are making in AI and how they are positioning themselves in the market. The report should be clearly formatted.”
Example response:
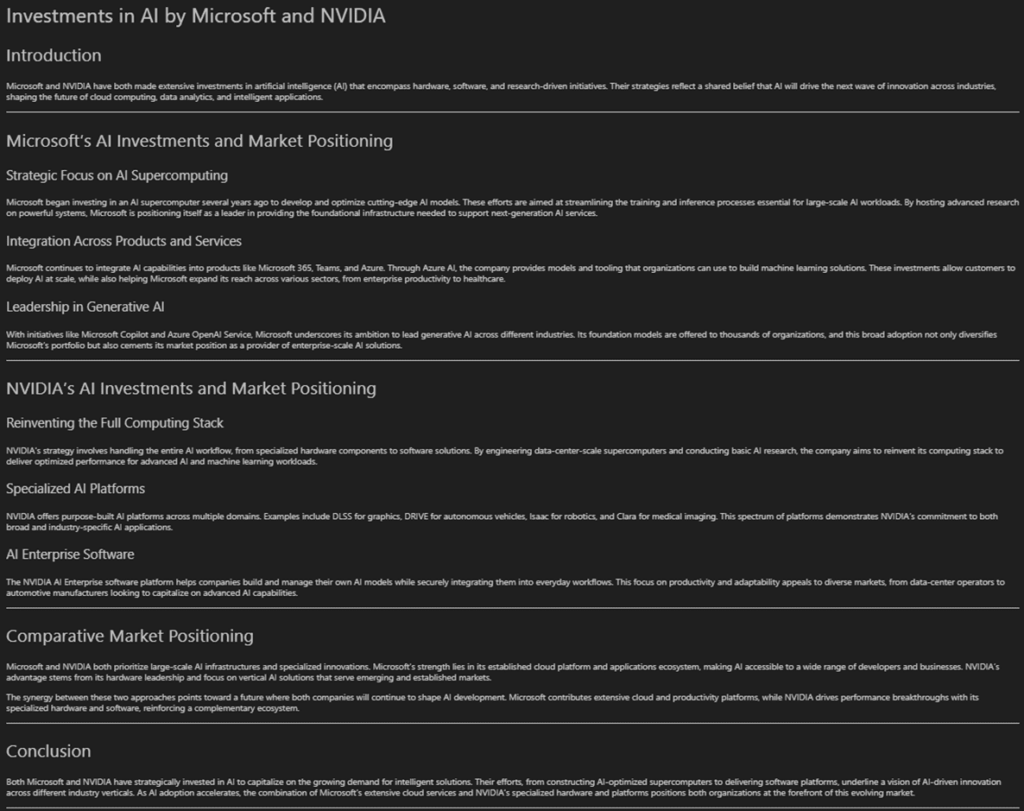
The result is a comprehensive report that executed quickly and contains detailed information about each of the companies. 26,802 total tokens were used to research and respond to the request with a significant percentage of them used for the final response (2,893 tokens or ~11%). These results were also reviewed by a human to verify their validity.

Example task: “Create a report on analyzing the risks disclosed by the various financial companies in the DOW. Indicate which risks are shared and unique.”
Example response:


Similarly, this task was completed in 42.7 seconds and used 31,685 total tokens, with 3,116 tokens used to generate the final report.

These results for both fact-finding and complex analysis tasks demonstrate that the pyramid approach efficiently creates detailed reports with low latency using a minimal amount of tokens. The tokens used for the tasks carry dense meaning with little noise allowing for high-quality, thorough responses across tasks.
Benefits of the pyramid: Why use it?
Overall, we found that our pyramid approach provided a significant boost in response quality and overall performance for high-value questions.
Some of the key benefits we observed include:
- Reduced model’s cognitive load: When the agent receives the user task, it retrieves pre-processed, distilled information rather than the raw, inconsistently formatted, disparate document chunks. This fundamentally improves the retrieval process since the model doesn’t waste its cognitive capacity on trying to break down the page/chunk text for the first time.
- Superior table processing: By breaking down table information and storing it in concise but descriptive sentences, the pyramid approach makes it easier to retrieve relevant information at inference time through natural language queries. This was particularly important for our dataset since financial reports contain lots of critical information in tables.
- Improved response quality to many types of requests: The pyramid enables more comprehensive context-aware responses to both precise, fact-finding questions and broad analysis based tasks that involve many themes across numerous documents.
- Preservation of critical context: Since the distillation process identifies and keeps track of key facts, important information that might appear only once in the document is easier to maintain. For example, noting that all tables are represented in millions of dollars or in a particular currency. Traditional chunking methods often cause this type of information to slip through the cracks.
- Optimized token usage, memory, and speed: By distilling information at ingestion time, we significantly reduce the number of tokens required during inference, are able to maximize the value of information put in the context window, and improve memory use.
- Scalability: Many solutions struggle to perform as the size of the document dataset grows. This approach provides a much more efficient way to manage a large volume of text by only preserving critical information. This also allows for a more efficient use of the LLMs context window by only sending it useful, clear information.
- Efficient concept exploration: The pyramid enables the agent to explore related information similar to navigating a knowledge graph, but does not require ever generating or maintaining relationships in the graph. The agent can use natural language exclusively and keep track of important facts related to the concepts it’s exploring in a highly token-efficient and fluid way.
- Emergent dataset understanding: An unexpected benefit of this approach emerged during our testing. When asking questions like “what can you tell me about this dataset?” or “what types of questions can I ask?”, the system is able to respond and suggest productive search topics because it has a more robust understanding of the dataset context by accessing higher levels in the pyramid like the abstracts and recollections.
Beyond the pyramid: Evaluation challenges & future directions
Challenges
While the results we’ve observed when using the pyramid search approach have been nothing short of amazing, finding ways to establish meaningful metrics to evaluate the entire system both at ingestion time and during information retrieval is challenging. Traditional RAG and Agent evaluation frameworks often fail to address nuanced questions and analytical responses where many different responses are valid.
Our team plans to write a research paper on this approach in the future, and we are open to any thoughts and feedback from the community, especially when it comes to evaluation metrics. Many of the existing datasets we found were focused on evaluating RAG use cases within one document or precise information retrieval across multiple documents rather than robust concept and theme analysis across documents and domains.
The main use cases we are interested in relate to broader questions that are representative of how businesses actually want to interact with GenAI systems. For example, “tell me everything I need to know about customer X” or “how do the behaviors of Customer A and B differ? Which am I more likely to have a successful meeting with?”. These types of questions require a deep understanding of information across many sources. The answers to these questions typically require a person to synthesize data from multiple areas of the business and think critically about it. As a result, the answers to these questions are rarely written or saved anywhere which makes it impossible to simply store and retrieve them through a vector index in a typical RAG process.
Another consideration is that many real-world use cases involve dynamic datasets where documents are consistently being added, edited, and deleted. This makes it difficult to evaluate and track what a “correct” response is since the answer will evolve as the available information changes.
Future directions
In the future, we believe that the pyramid approach can address some of these challenges by enabling more effective processing of dense documents and storing learned information as recollections. However, tracking and evaluating the validity of the recollections over time will be critical to the system’s overall success and remains a key focus area for our ongoing work.
When applying this approach to organizational data, the pyramid process could also be used to identify and assess discrepancies across areas of the business. For example, uploading all of a company’s sales pitch decks could surface where certain products or services are being positioned inconsistently. It could also be used to compare insights extracted from various line of business data to help understand if and where teams have developed conflicting understandings of topics or different priorities. This application goes beyond pure information retrieval use cases and would allow the pyramid to serve as an organizational alignment tool that helps identify divergences in messaging, terminology, and overall communication.
Conclusion: Key takeaways and why the pyramid approach matters
The knowledge distillation pyramid approach is significant because it leverages the full power of the LLM at both ingestion and retrieval time. Our approach allows you to store dense information in fewer tokens which has the added benefit of reducing noise in the dataset at inference. Our approach also runs very quickly and is incredibly token efficient, we are able to generate responses within seconds, explore potentially hundreds of searches, and on average use (this includes all the search iterations!).
We find that the LLM is much better at writing atomic insights as sentences and that these insights effectively distill information from both text-based and tabular data. This distilled information written in natural language is very easy for the LLM to understand and navigate at inference since it does not have to expend unnecessary energy reasoning about and breaking down document formatting or filtering through noise.
The ability to retrieve and aggregate information at any level of the pyramid also provides significant flexibility to address a variety of query types. This approach offers promising performance for large datasets and enables high-value use cases that require nuanced information retrieval and analysis.
Note: The opinions expressed in this article are solely my own and do not necessarily reflect the views or policies of my employer.
Interested in discussing further or collaborating? Reach out on LinkedIn!