LoRA (Low Rank Adaptation – arxiv.org/abs/2106.09685) is a popular technique for fine-tuning Large Language Models (LLMs) on the cheap. But 2024 has seen an explosion of new parameter-efficient fine-tuning techniques, an alphabet soup of LoRA alternatives: SVF, SVFT, MiLoRA, PiSSA, LoRA-XS 🤯… And most are based on a matrix technique I like a lot: the SVD (Singular Value Decomposition). Let’s dive in.
LoRA
The original Lora insight is that fine-tuning all the weights of a model is overkill. Instead, LoRA freezes the model and only trains a small pair of low-rank “adapter” matrices. See the illustrations below (where W is any matrix of weights in a transformer LLM).

This saves memory and compute cycles since far fewer gradients have to be computed and stored. For example, here is a Gemma 8B model fine-tuned to speak like a pirate using LoRA: only 22M parameters are trainable, 8.5B parameters remain frozen.

LoRA is very popular. It has even made it as a single-line API into mainstream ML frameworks like Keras:
gemma.backbone.enable_lora(rank=8)But is LoRA the best? Researchers have been trying hard to improve on the formula. Indeed, there are many ways of selecting smaller “adapter” matrices. And since most of them make clever use of the singular value decomposition (SVD) of a matrix, let’s pause for a bit of Math.
SVD: the simple math
The SVD is a great tool for understanding the structure of matrices. The technique splits a matrix into three: W = USVT where U and V are orthogonal (i.e., base changes), and S is the diagonal matrix of sorted singular values. This decomposition always exists.
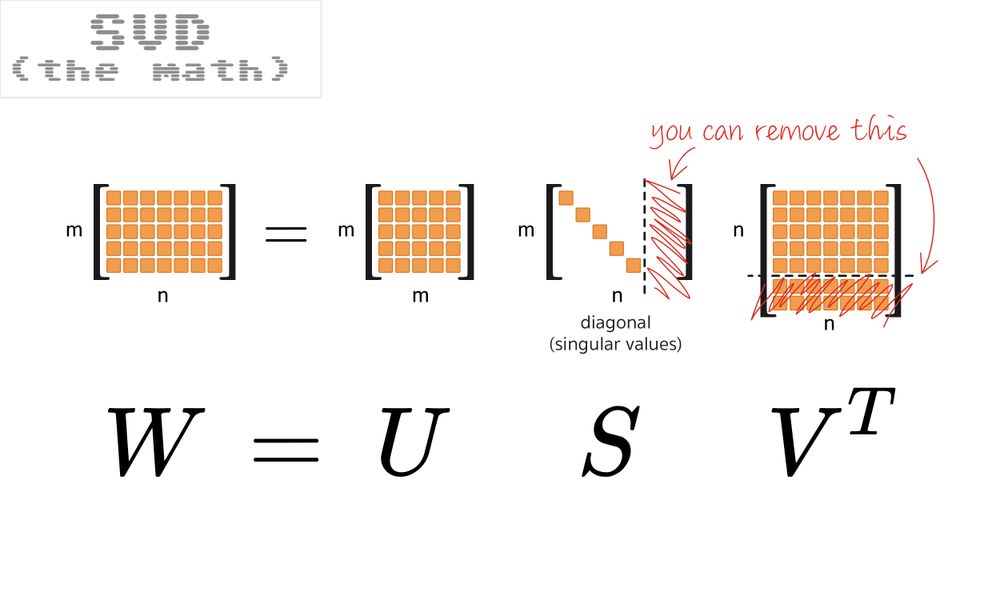
In “textbook” SVD, U and V are square, while S is a rectangle with singular values on the diagonal and a tail of zeros. In practice, you can work with a square S and a rectangular U or V – see the picture – the chopped-off pieces are just multiplications by zero. This “economy-sized” SVD is what is used in common libraries, for example, numpy.linalg.svd.
So how can we use this to more efficiently select the weights to train? Let’s quickly go through five recent SVD-based low-rank fine-tuning techniques, with commented illustrations.
SVF
The simplest alternative to LoRA is to use the SVD on the model’s weight matrices and then fine-tune the singular values directly. Oddly, this is the most recent technique, called SVF, published in the Transformers² paper (arxiv.org/abs/2501.06252v2).
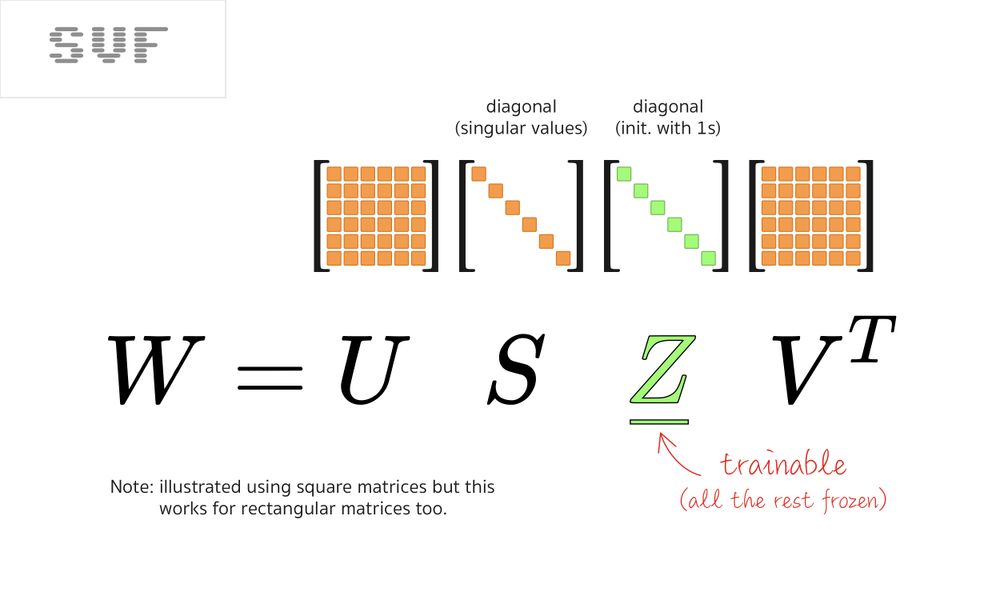
SVF is much more economical in parameters than LoRA. And as a bonus, it makes tuned models composable. For more info on that, see my Transformers² explainer here, but composing two SVF fine-tuned models is just an addition:
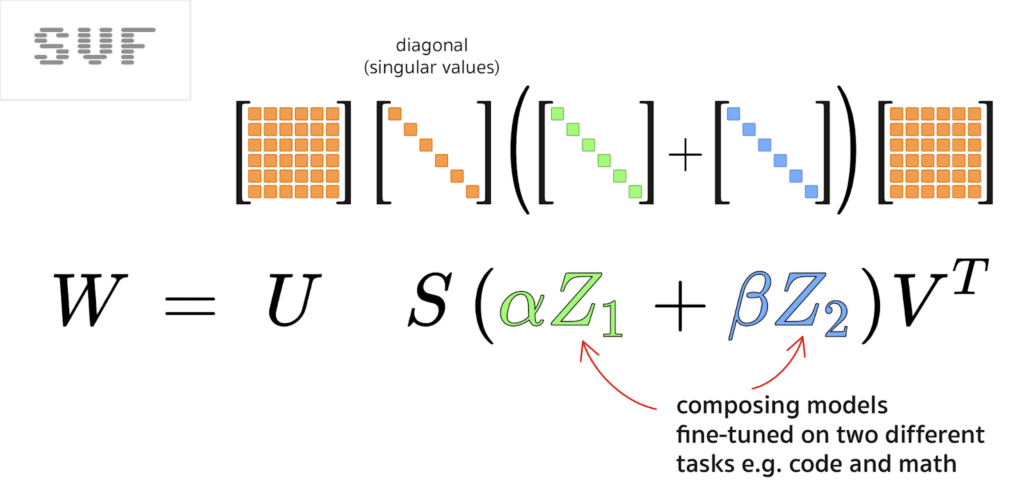
SVFT
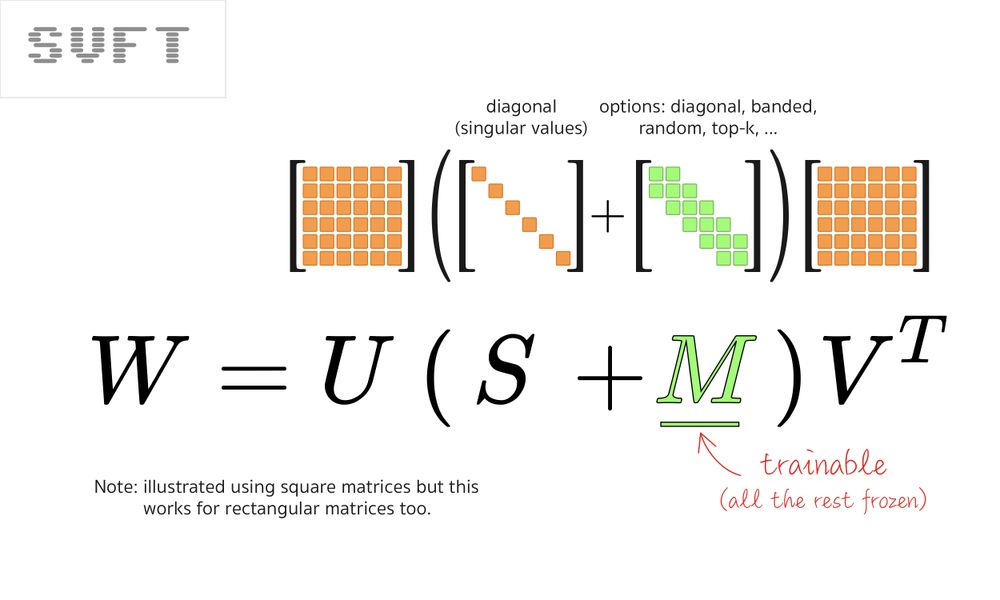
Should you need more trainable parameters, the SVFT paper (arxiv.org/abs/2405.19597) explores multiple ways of doing that, starting by adding more trainable weights on the diagonal.
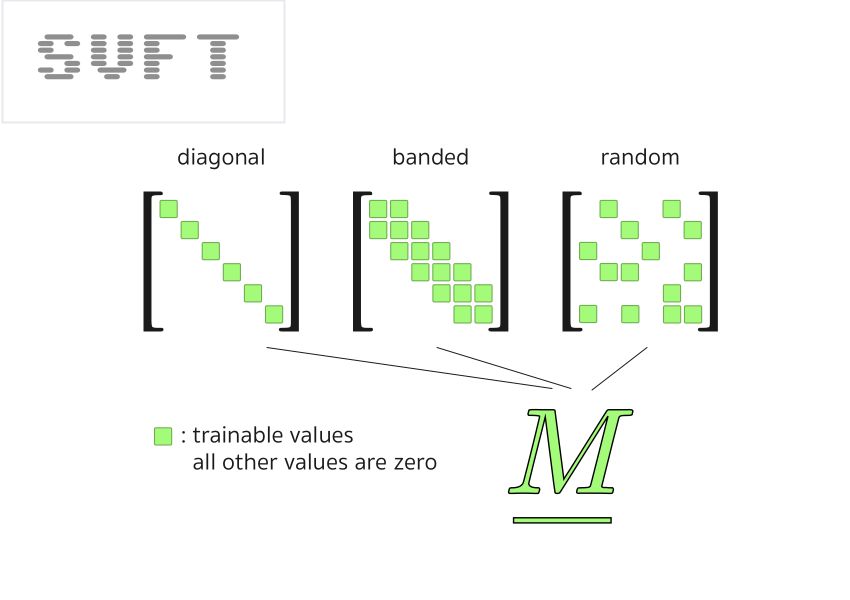
It also evaluates multiple alternatives like spreading them randomly through the “M” matrix.
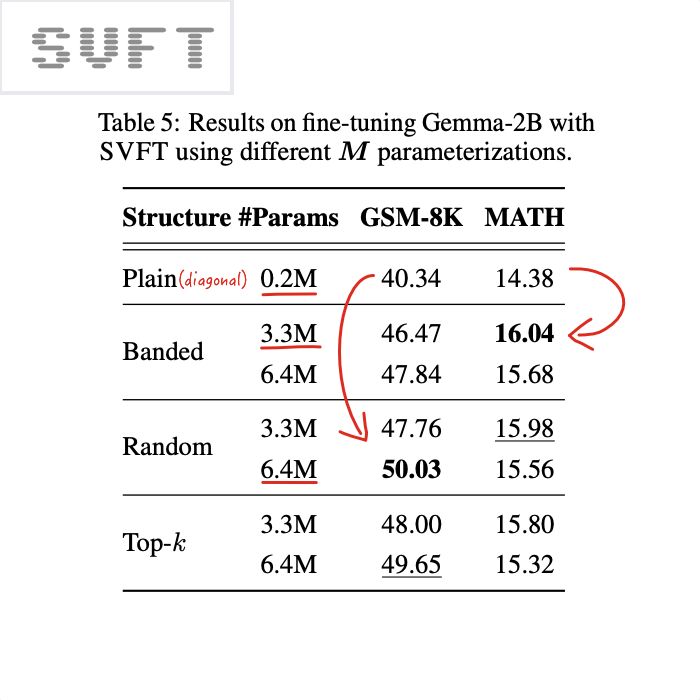
More importantly, the SVFT paper confirms that having more trainable values than just the diagonal is useful. See their fine-tuning results below.
Next come several techniques that split singular values in two sets, “large” and “small”. But before we proceed, let’s pause for a bit more SVD math.
More SVD math
The SVD is usually seen as a decomposition into three matrices W=USVT but it can also be thought of as a weighted sum of many rank-1 matrices, weighted by the singular values:
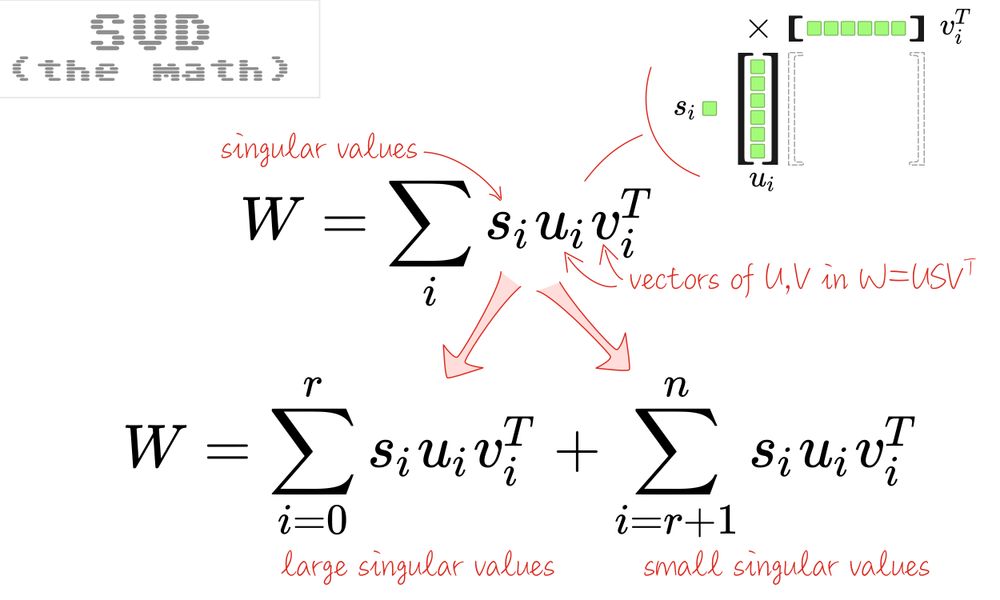
Should you want to prove it, express individual matrix elements Wjk using the USVT form and the formula for matrix multiplication on one hand, the
Σ siuiviT form, on the other, simplify using the fact that S is diagonal and notice that it’s the same thing.
In this representation, it’s easy to see that you can split the sum in two. And as you can always sort the singular values, you can make this a split between “large” and “small” singular values.
Going back to the tree-matrix form W=USVT, this is what the split looks like:
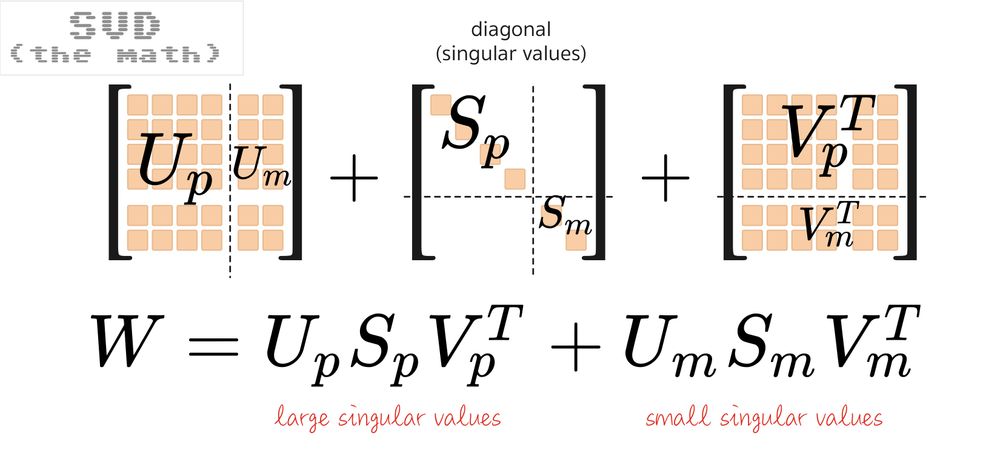
Based on this formula, two papers have explored what happens if you tune only the large singular values or only the small ones, PiSSA and MiLoRA.
PiSSA
PiSSA (Principal Singular values and Singular Vectors Adaptation, arxiv.org/abs/2404.02948) claims that you should only tune the large principal values. The mechanism is illustrated below:

From the paper: “PiSSA is designed to approximate full finetuning by adapting the principal singular components, which are believed to capture the essence of the weight matrices. In contrast, MiLoRA aims to adapt to new tasks while maximally retaining the base model’s knowledge.”
The PiSSA paper also has an interesting finding: full fine-tuning is prone to over-fitting. You might get better results in the absolute with a low-rank fine-tuning technique.
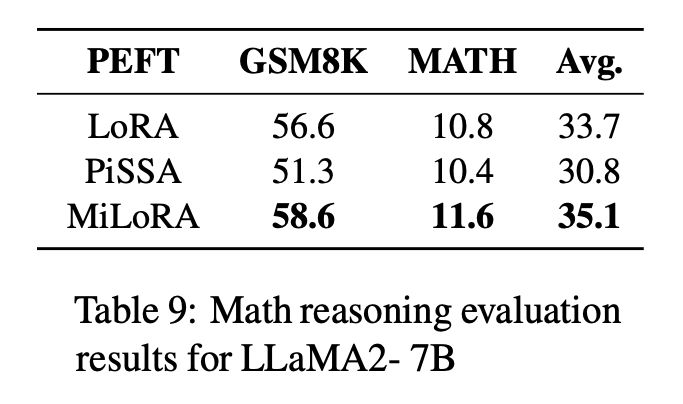
MiLoRA
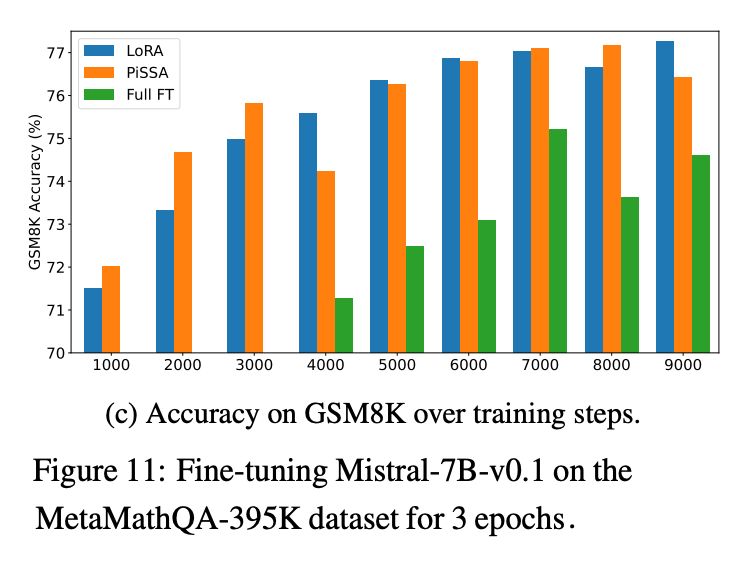
MiLoRA (Minor singular component LoRA arxiv.org/abs/2406.09044), on the other hand, claims that you should only tune the small principal values. It uses a similar mechanism to PiSSA:
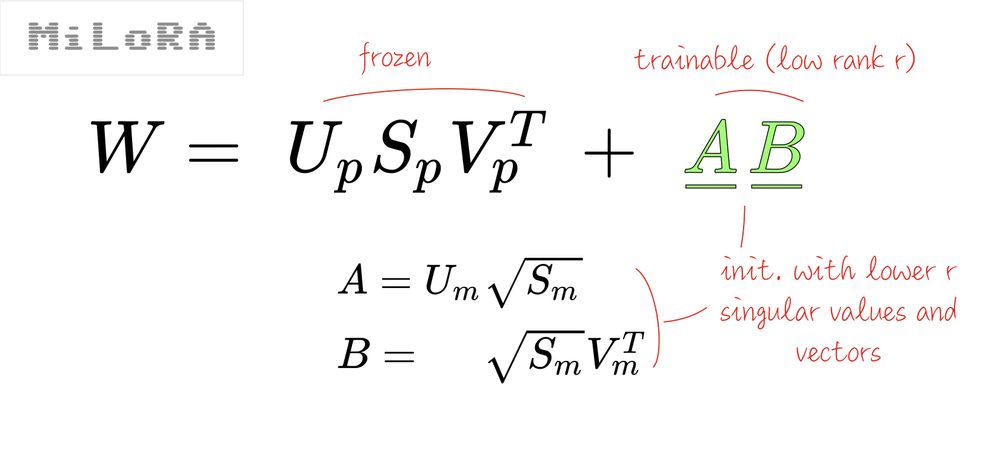
Surprisingly, MiLoRA seems to have the upper hand, at least when tuning on math datasets which are probably fairly aligned with the original pre-training. Arguably, PiSSA should be better for bending the behavior of the LLM further from its pre-training.
LoRA-XS
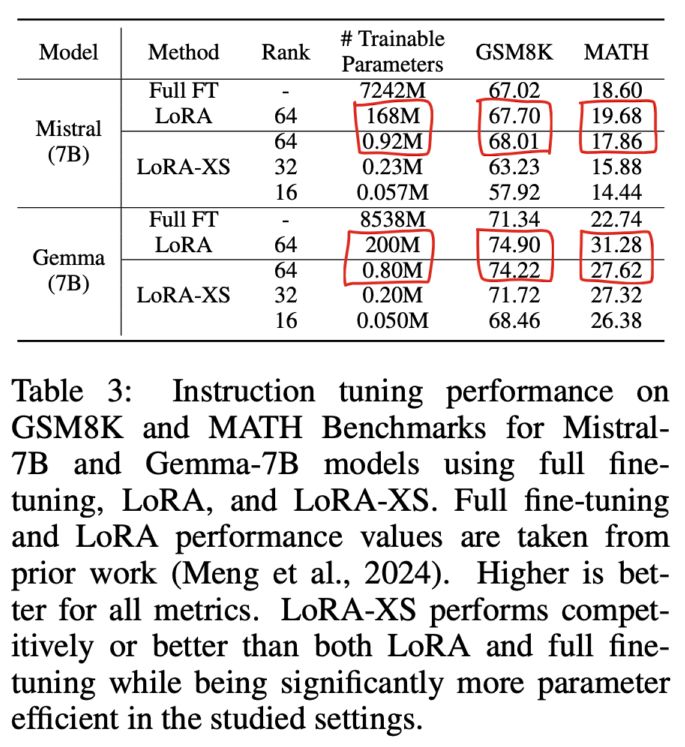
Finally, I’d like to mention LoRA-XS (arxiv.org/abs/2405.17604). Very similar to PiSSA but slightly different mechanism. It also shows good results with significantly fewer params than LoRA.
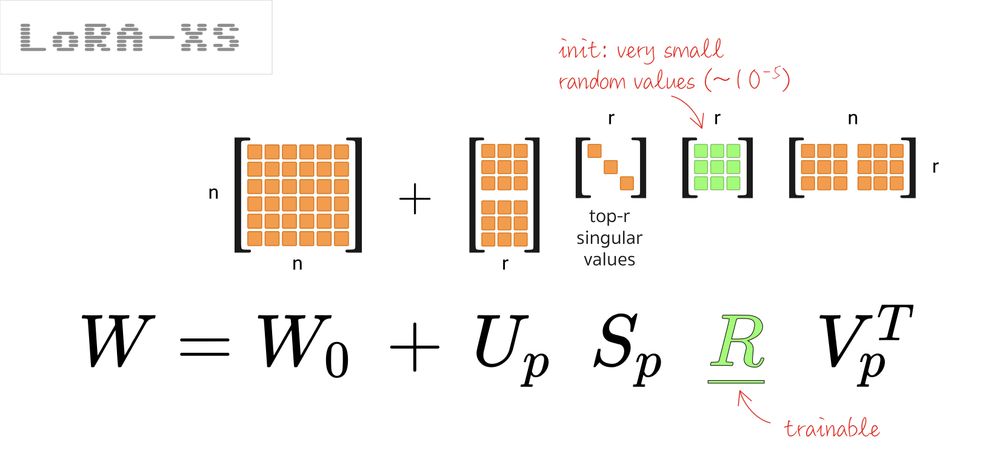
The paper offers a mathematical explanation of why this setup is “ideal’ under two conditions:
- that truncating the bottom principal values from the SVD still offers a good approximation of the weights matrices
- that the fine-tuning data distribution is close to the pre-training one
Both are questionable IMHO, so I won’t detail the math. Some results:
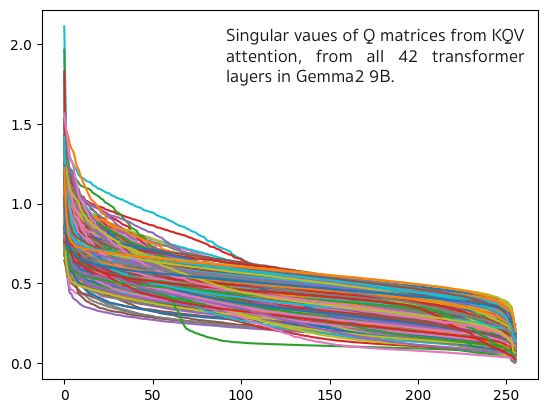
The underlying assumption seems to be that singular values come in “large” and “small” varieties but is it true? I made a quick Colab to check this on Gemma2 9B. Bottom line: 99% of the singular values are in the 0.1 – 1.1 range. I’m not sure partitioning them into “large” and “small” makes that much sense.
Conclusion
There are many more parameter-efficient fine-tuning techniques. Worth mentioning:
My conclusion: to go beyond the LoRA standard with 10x fewer params, I like the simplicity of Transformers²’s SVF. And if you need more trainable weights, SVFT is an easy extension. Both use all singular values (full rank, no singular value pruning) and are still cheap 😁. Happy tuning!
Note: All illustrations are either created by the author or extracted from arxiv.org papers for comment and discussion purposes.