previous article on organizing for AI (link), we looked at how the interplay between three key dimensions — ownership of outcomes, outsourcing of staff, and the geographical proximity of team members — can yield a variety of organizational archetypes for implementing strategic AI initiatives, each implying a different twist to the product operating model.
Now we take a closer look at how the product operating model, and the core competencies of empowered product teams in particular, can evolve to face the emerging opportunities and challenges in the age of AI. We start by placing the current orthodoxy in its historical context and present a process model highlighting four key phases in the evolution of team composition in product operating models. We then consider how teams can be reshaped to successfully create AI-powered products and services going forward.
Note: All figures in the following sections have been created by the author of this article.
The Evolution of Product Operating Models
Current Orthodoxy and Historical Context
Product coaches such as Marty Cagan have done much in recent years to popularize the “3-in-a-box” model of empowered product teams. In general, according to the current orthodoxy, these teams should consist of three first-class, core competencies: product management, product design, and engineering. Being first-class means that none of these competencies are subordinate to each other in the org chart, and the product manager, design lead, and engineering lead are empowered to jointly make strategic product-related decisions. Being core reflects the belief that removing or otherwise compromising on any of these three competencies would lead to worse product outcomes, i.e., products that do not work for customers or for the business.
A central conviction of the current orthodoxy is that the 3-in-a-box model helps address product risks in four key areas: value, viability, usability, and feasibility. Product management is accountable for overall outcomes, and especially concerned with ensuring that the product is valuable to customers (typically implying a higher willingness to pay) and viable for the business, e.g., in terms of how much it costs to build, operate, and maintain the product in the long run. Product design is accountable for user experience (UX), and primarily interested in maximizing usability of the product, e.g., through intuitive onboarding, good use of affordances, and a pleasing user interface (UI) that allows for efficient work. Lastly, engineering is accountable for technical delivery, and primarily focused on ensuring feasibility of the product, e.g., characterized by the ability to ship an AI use case within certain technical constraints, ensuring sufficient predictive performance, inference speed, and safety.
Getting to this 3-in-a-box model has not been an easy journey, however, and the model is still not widely adopted outside tech companies. In the early days, product teams – if they could even be called that – mainly consisted of developers that tended to be responsible for both coding and gathering requirements from sales teams or other internal business stakeholders. Such product teams would focus on feature delivery rather than user experience or strategic product development; today such teams are thus often referred to as “feature teams”. The TV show Halt and Catch Fire vividly depicts tech companies organizing like this in the 1980s and 90s. Shows like The IT Crowd underscore how such disempowered teams can persist in IT departments in modern times.
As software projects grew in complexity in the late 1990s and early 2000s, the need for a dedicated product management competency to align product development with business goals and customer needs became increasingly evident. Companies like Microsoft and IBM began formalizing the role of a product manager and other companies soon followed. Then, as the 2000s saw the emergence of various online consumer-facing services (e.g., for search, shopping, and social networking), design/UX became a priority. Companies like Apple and Google started emphasizing design, leading to the formalization of corresponding roles. Designers began working closely with developers to ensure that products were not only functional but also visually appealing and user-friendly. Since the 2010s, the increased adoption of agile and lean methodologies further reinforced the need for cross-functional teams that could iterate quickly and respond to user feedback, all of which paved the way for the current 3-in-a-box orthodoxy.
A Process Framework for the Evolution of Product Operating Models
Looking ahead 5-10 years from today’s vantage point in 2025, it is interesting to consider how the emergence of AI as a “table stakes” competency might shake up the current orthodoxy, potentially triggering the next step in the evolution of product operating models. Figure 1 below proposes a four-phase process framework of how existing product models might evolve to incorporate the AI competency over time, drawing on instructive parallels to the situation faced by design/UX only a few years ago. Note that, at the risk of somewhat abusing terminology, but in line with today’s industry norms, the terms “UX” and “design” are used interchangeably in the following to refer to the competency concerned with minimizing usability risk.
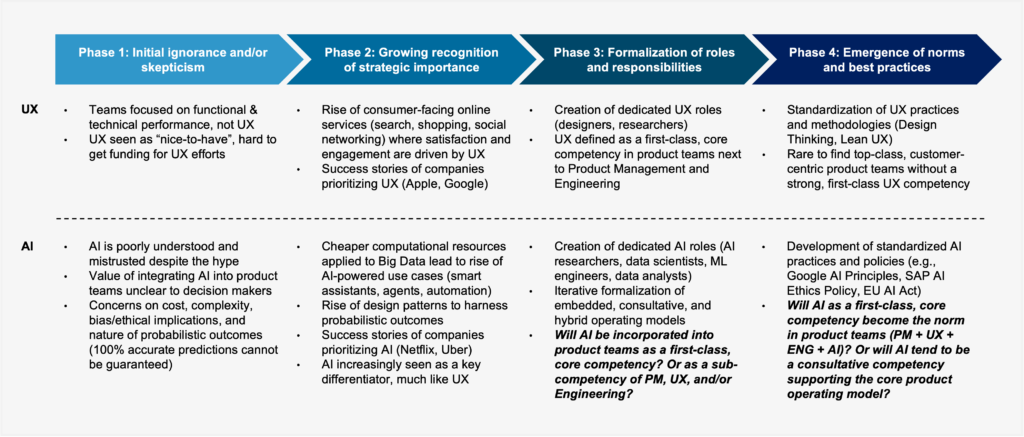
Phase 1 in the above framework is characterized by ignorance and/or skepticism. UX initially faced the struggle of justifying its worth at companies that had previously focused primarily on functional and technical performance, as in the context of non-consumer-facing enterprise software (think ERP systems of the 1990s). AI today faces a similar uphill battle. Not only is AI poorly understood by many stakeholders to begin with, but companies that have been burned by early forays into AI may now be wallowing in the “trough of disillusionment”, leading to skepticism and a wait-and-see approach towards adopting AI. There may also be concerns around the ethics of collecting behavioral data, algorithmic decision-making, bias, and getting to grips with the inherently uncertain nature of probabilistic AI output (e.g., consider the implications for software testing).
Phase 2 is marked by a growing recognition of the strategic importance of the new competency. For UX, this phase was catalyzed by the rise of consumer-facing online services, where improvements to UX could significantly drive engagement and monetization. As success stories of companies like Apple and Google began to spread, the strategic value of prioritizing UX became harder to overlook. With the confluence of some key trends over the past decade, such as the availability of cheaper computation via hyper-scalers (e.g., AWS, GCP, Azure), access to Big Data in a variety of domains, and the development of powerful new machine learning algorithms, our collective awareness of the potential of AI had been growing steadily by the time ChatGPT burst onto the scene and captured everyone’s attention. The rise of design patterns to harness probabilistic outcomes and the related success stories of AI-powered companies (e.g., Netflix, Uber) mean that AI is now increasingly seen as a key differentiator, much like UX before.
In Phase 3, the roles and responsibilities pertaining to the new competency become formalized. For UX, this meant differentiating between the roles of designers (covering experience, interactions, and the look and feel of user interfaces) and researchers (specializing in qualitative and quantitative methods for gaining a deeper understanding of user preferences and behavioral patterns). To remove any doubts about the value of UX, it was made into a first-class, Core Competency, sitting next to product management and engineering to form the current triumvirate of the standard product operating model. The past few years have witnessed the increased formalization of AI-related roles, expanding beyond a jack-of-all conception of “data scientists” to more specialized roles like “research scientists”, “ML engineers”, and more recently, “prompt engineers”. Looking ahead, an intriguing open question is how the AI competency will be incorporated into the current 3-in-a-box model. We may see an iterative formalization of embedded, consultative, and hybrid models, as discussed in the next section.
Finally, Phase 4 sees the emergence of norms and best practices for effectively leveraging the new competency. For UX, this is reflected today by the adoption of practices like design thinking and lean UX. It has also become rare to find top-class, customer-centric product teams without a strong, first-class UX competency. Meanwhile, recent years have seen concerted efforts to develop standardized AI practices and policies (e.g., Google’s AI Principles, SAP’s AI Ethics Policy, and the EU AI Act), partly to cope with the dangers that AI already poses, and partly to stave off dangers it may pose in the future (especially as AI becomes more powerful and is put to nefarious uses by bad actors). The extent to which the normalization of AI as a competency might impact the current orthodox framing of the 3-in-a-box Product Operating Model remains to be seen.
Towards AI-Ready Product Operating Models
Leveraging AI Expertise: Embedded, Consultative, and Hybrid Models
Figure 2 below proposes a high-level framework to think about how the AI competency could be incorporated in today’s orthodox, 3-in-a-box product operating model.
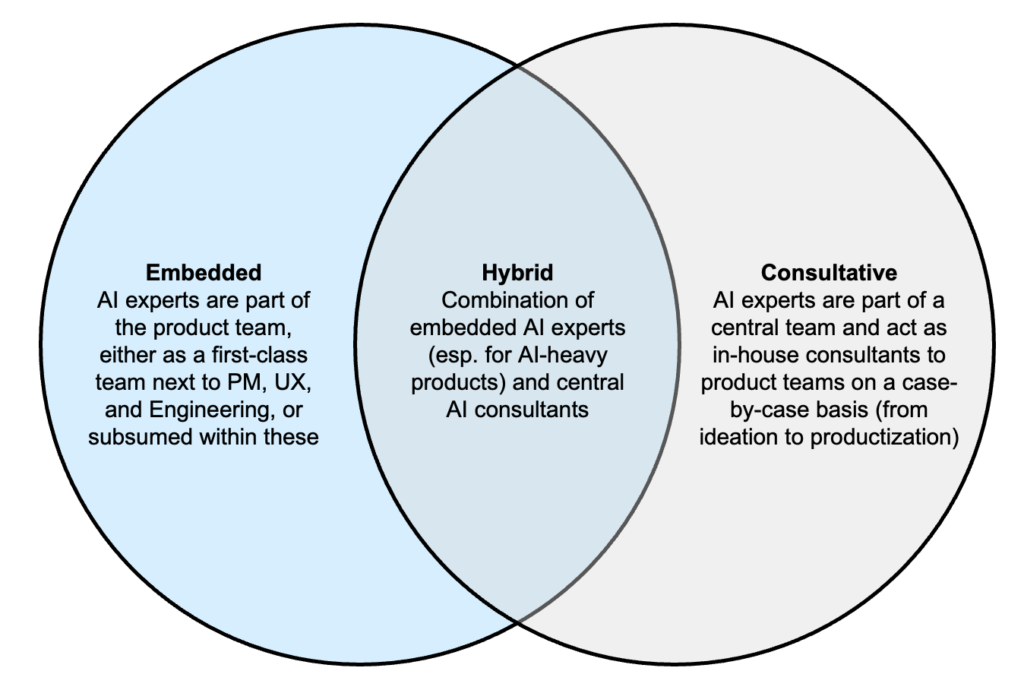
In the embedded model, AI (personified by data scientists, ML engineers, etc.) may be added either as a new, durable, and first-class competency next to product management, UX/design, and engineering, or as a subordinated competency to these “big three” (e.g., staffing data scientists in an engineering team). By contrast, in the consultative model, the AI competency might reside in some centralized entity, such as an AI Center of Excellence (CoE), and leveraged by product teams on a case-by-case basis. For instance, AI experts from the CoE may be brought in temporarily to advise a product team on AI-specific issues during product discovery and/or delivery. In the hybrid model, as the name suggests, some AI experts may be embedded as long-term members of the product team and others may be brought in at times to provide additional consultative guidance. While Figure 2 only illustrates the case of a single product team, one can imagine these model options scaling to multiple product teams, capturing the interaction between different teams. For example, an “experience team” (responsible for building customer-facing products) might collaborate closely with a “platform team” (maintaining AI services/APIs that experience teams can leverage) to ship an AI product to customers.
Each of the above models for leveraging AI come with certain pros and cons. The embedded model can enable closer collaboration, more consistency, and faster decision-making. Having AI experts in the core team can lead to more seamless integration and collaboration; their continuous involvement ensures that AI-related inputs, whether conceptual or implementation-focused, can be integrated consistently throughout the product discovery and delivery phases. Direct access to AI expertise can speed up problem-solving and decision-making. However, embedding AI experts in every product team may be too expensive and difficult to justify, especially for companies or specific teams that cannot articulate a clear and compelling thesis about the expected AI-enabled return on investment. As a scarce resource, AI experts may either only be available to a handful of teams that can make a strong enough business case, or be spread too thinly across several teams, leading to adverse outcomes (e.g., slower turnaround of tasks and employee churn).
With the consultative model, staffing AI experts in a central team can be more cost-effective. Central experts can be allocated more flexibly to projects, allowing higher utilization per expert. It is also possible for one highly specialized expert (e.g., focused on large language models, AI lifecycle management, etc.) to advise multiple product teams at once. However, a purely consultative model can make product teams dependent on colleagues outside the team; these AI consultants may not always be available when needed, and may switch to another company at some point, leaving the product team high and dry. Regularly onboarding new AI consultants to the product team is time- and effort-intensive, and such consultants, especially if they are junior or new to the company, may not feel able to challenge the product team even when doing so might be necessary (e.g., warning about data-related bias, privacy concerns, or suboptimal architectural decisions).
The hybrid model aims to balance the trade-offs between the purely embedded and purely consultative models. This model can be implemented organizationally as a hub-and-spoke structure to foster regular knowledge sharing and alignment between the hub (CoE) and spokes (embedded experts). Giving product teams access to both embedded and consultative AI experts can provide both consistency and flexibility. The embedded AI experts can develop domain-specific know-how that can help with feature engineering and model performance diagnosis, while specialized AI consultants can advise and up-skill the embedded experts on more general, state-of-the-art technologies and best practices. However, the hybrid model is more complex to manage. Tasks must be divided carefully between the embedded and consultative AI experts to avoid redundant work, delays, and conflicts. Overseeing the alignment between embedded and consultative experts can create additional managerial overhead that may need to be borne to varying degrees by the product manager, design lead, and engineering lead.
The Effect of Boundary Conditions and Path Dependence
Besides considering the pros and cons of the model options depicted in Figure 2, product teams should also account for boundary conditions and path dependence in deciding how to incorporate the AI competency.
Boundary conditions refer to the constraints that shape the environment in which a team must operate. Such conditions may relate to aspects such as organizational structure (encompassing reporting lines, informal hierarchies, and decision-making processes within the company and team), resource availability (in terms of budget, personnel, and tools), regulatory and compliance-related requirements (e.g., legal and/or industry-specific regulations), and market dynamics (spanning the competitive landscape, customer expectations, and market trends). Path dependence refers to how historical decisions can influence current and future decisions; it emphasizes the importance of past events in shaping the later trajectory of an organization. Key aspects leading to such dependencies include historical practices (e.g., established routines and processes), past investments (e.g., in infrastructure, technology, and human capital, leading to potentially irrational decision-making by teams and executives due to the sunk cost fallacy), and organizational culture (covering the shared values, beliefs, and behaviors that have developed over time).
Boundary conditions can limit a product team’s options when it comes to configuring the operating model; some desirable choices may be out of reach (e.g., budget constraints preventing the staffing of an embedded AI expert with a certain specialization). Path dependence can create an adverse type of inertia, whereby teams continue to follow established processes and methods even if better alternatives exist. This can make it challenging to adopt new operating models that require significant changes to existing practices. One way to work around path dependence is to enable different product teams to evolve their respective operating models at different speeds according to their team-specific needs; a team building an AI-first product may choose to invest in embedded AI experts sooner than another team that is exploring potential AI use cases for the first time.
Finally, it is worth remembering that the choice of a product operating model can have far-reaching consequences for the design of the product itself. Conway’s Law states that “any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.” In our context, this means that the way product teams are organized, communicate, and incorporate the AI competency can directly impact the architecture of the products and services that they go on to create. For instance, consultative models may be more likely to result in the use of generic AI APIs (which the consultants can reuse across teams), while embedded AI experts may be better-positioned to implement product-specific optimizations aided by domain know-how (albeit at the risk of tighter coupling to other components of the product architecture). Companies and teams should therefore be empowered to configure their AI-ready product operating models, giving due consideration to the broader, long-term implications.