Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Researchers from Stanford University and Google DeepMind have unveiled Step-Wise Reinforcement Learning (SWiRL), a technique designed to enhance the ability of large language models (LLMs) to tackle complex tasks requiring multi-step reasoning and tool use.
As the interest in AI agents and LLM tool use continues to increase, this technique could offer substantial benefits for enterprises looking to integrate reasoning models into their applications and workflows.
The challenge of multi-step problems
Real-world enterprise applications often involve multi-step processes. For example, planning a complex marketing campaign may involve market research, internal data analysis, budget calculation and reviewing customer support tickets. This requires online searches, access to internal databases and running code.
Traditional reinforcement learning (RL) methods used to fine-tune LLMs, such as Reinforcement Learning from Human Feedback (RLHF) or RL from AI Feedback (RLAIF), typically focus on optimizing models for single-step reasoning tasks.
The lead authors of the SWiRL paper, Anna Goldie, research scientist at Google DeepMind, and Azalia Mirhosseini, assistant professor of computer science at Stanford University, believe that current LLM training methods are not suited for the multi-step reasoning tasks that real-world applications require.
“LLMs trained via traditional methods typically struggle with multi-step planning and tool integration, meaning that they have difficulty performing tasks that require retrieving and synthesizing documents from multiple sources (e.g., writing a business report) or multiple steps of reasoning and arithmetic calculation (e.g., preparing a financial summary),” they told VentureBeat.
Step-Wise Reinforcement Learning (SWiRL)
SWiRL tackles this multi-step challenge through a combination of synthetic data generation and a specialized RL approach that trains models on entire sequences of actions.
As the researchers state in their paper, “Our goal is to teach the model how to decompose complex problems into a sequence of more manageable subtasks, when to call the tool, how to formulate a call to the tool, when to use the results of these queries to answer the question, and how to effectively synthesize its findings.”
SWiRL employs a two-stage methodology. First, it generates and filters large amounts of multi-step reasoning and tool-use data. Second, it uses a step-wise RL algorithm to optimize a base LLM using these generated trajectories.
“This approach has the key practical advantage that we can quickly generate large volumes of multi-step training data via parallel calls to avoid throttling the training process with slow tool use execution,” the paper notes. “In addition, this offline process enables greater reproducibility due to having a fixed dataset.”
Generating training data
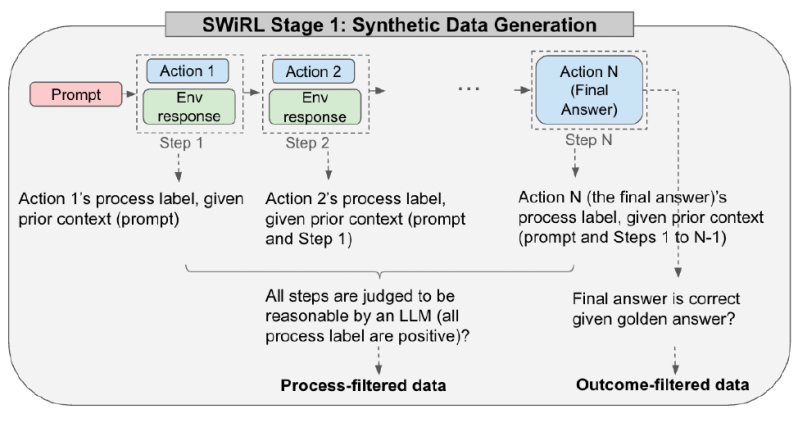
The first stage involves creating the synthetic data SWiRL learns from. An LLM is given access to a relevant tool, like a search engine or a calculator. The model is then prompted iteratively to generate a “trajectory,” a sequence of steps to solve a given problem. At each step, the model can generate internal reasoning (its “chain of thought“), call a tool, or produce the final answer. If it calls a tool, the query is extracted, executed (e.g., a search is performed), and the result is fed back into the model’s context for the next step. This continues until the model provides a final answer.
Each complete trajectory, from the initial prompt to the final answer, is then broken down into multiple overlapping sub-trajectories. Each sub-trajectory represents the process up to a specific action, providing a granular view of the model’s step-by-step reasoning. Using this method, the team compiled large datasets based on questions from multi-hop question-answering (HotPotQA) and math problem-solving (GSM8K) benchmarks, generating tens of thousands of trajectories.
The researchers explored four different data filtering strategies: no filtering, filtering based solely on the correctness of the final answer (outcome filtering), filtering based on the judged reasonableness of each individual step (process filtering) and filtering based on both process and outcome.
Many standard approaches, such as Supervised Fine-Tuning (SFT), rely heavily on “golden labels” (perfect, predefined correct answers) and often discard data that does not lead to the correct final answer. Recent popular RL approaches, such as the one used in DeepSeek-R1, also use outcome-based rewards to train the model.
In contrast, SWiRL achieved its best results using process-filtered data. This means the data included trajectories where each reasoning step or tool call was deemed logical given the previous context, even if the final answer turned out to be wrong.
The researchers found that SWiRL can “learn even from trajectories that end in incorrect final answers. In fact, we achieve our best results by including process-filtered data, regardless of the correctness of the outcome.”
Training LLMs with SWiRL

In the second stage, SWiRL uses reinforcement learning to train a base LLM on the generated synthetic trajectories. At every step within a trajectory, the model is optimized to predict the next appropriate action (an intermediate reasoning step, a tool call, or the final answer) based on the preceding context.
The LLM receives feedback at each step by a separate generative reward model, which assesses the model’s generated action given the context up to that point.
“Our granular, step-by-step finetuning paradigm enables the model to learn both local decision-making (next-step prediction) and global trajectory optimization (final response generation) while being guided by immediate feedback on the soundness of each prediction,” the researchers write.
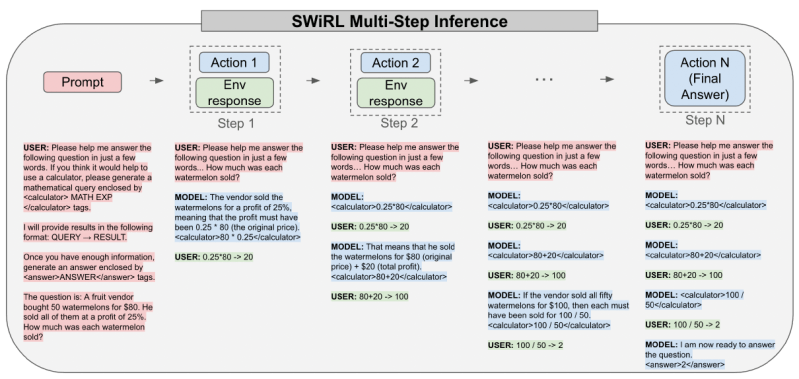
At inference time, a SWiRL-trained model works in the same iterative fashion. It receives a prompt and generates text in response. If it outputs a tool call (such as a search query or a mathematical expression), the system parses it, executes the tool, and feeds the result back into the model’s context window. The model then continues generating, potentially making more tool calls, until it outputs a final answer or reaches a pre-set limit on the number of steps.
“By training the model to take reasonable steps at each moment in time (and to do so in a coherent and potentially more explainable way), we address a core weakness of traditional LLMs, namely their brittleness in the face of complex, multi-step tasks, where the probability of success decays exponentially with path length,” Goldie and Mirhoseini said. “Useful and robust Enterprise AI will inevitably need to integrate a wide variety of different tools, chaining them together into complex sequences.”
SWiRL in action
The Stanford and Google DeepMind team evaluated SWiRL across several challenging multi-step question-answering and mathematical reasoning tasks. Compared to baseline models, SWiRL demonstrated significant relative accuracy improvements, ranging from 11% to over 21% on datasets like GSM8K, HotPotQA, MuSiQue and BeerQA.
The experiments confirmed that training a Gemma 2-27B model with SWiRL on process-filtered data yielded the best results, outperforming models trained on outcome-filtered data or using traditional SFT. This suggests SWiRL learns the underlying reasoning process more effectively, rather than just memorizing paths to correct answers, which aids performance on unseen problems.
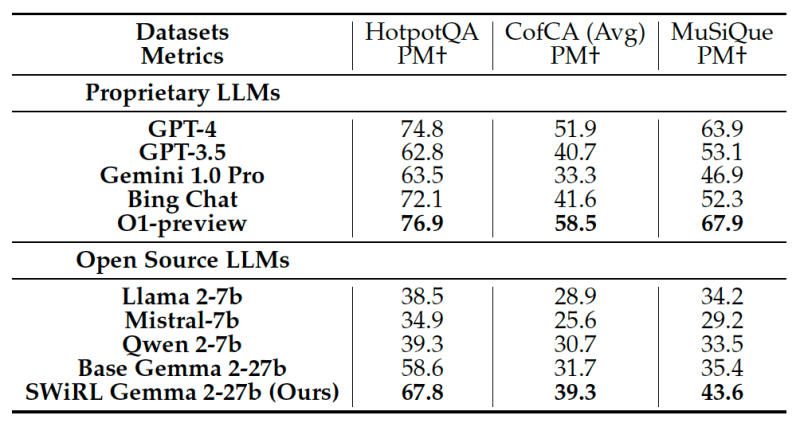
More importantly, SWiRL exhibited strong generalization capabilities. For example, training a model using SWiRL on text-based question-answering examples improved its performance on math reasoning tasks, even though the model wasn’t explicitly trained on math problems.
This transferability across different tasks and tool types is highly valuable as there is an explosion of agentic applications for language models, and methods that generalize across datasets and tasks will be easier, cheaper and faster to adapt to new environments.
“SWiRL’s generalization seems quite robust in the domains that we explored, but it would be interesting to test this in other areas such as coding,” Goldie and Mirhoseini said. “Our findings suggest that an enterprise AI model trained on one core task using SWiRL would likely exhibit significant performance improvements on other, seemingly unrelated tasks without task-specific fine-tuning. SWiRL generalizes better when applied to larger (i.e. more powerful) models, indicating that this technique may be even more effective in the future as baseline capabilities grow.”