Chinese e-commerce giant Alibaba has made waves globally in the tech and business communities with its own family of “Qwen” generative AI large language models, beginning with the launch of the original Tongyi Qianwen LLM chatbot in April 2023 through the release of Qwen 3 in April 2025.
Well, not only are its models powerful and score high on third-party benchmark tests at completing math, science, reasoning, and writing tasks, but for the most part, they’ve been released under permissive open source licensing terms, allowing organizations and enterprises to download them, customize them, run them, and generally use them for all variety of purposes, even commercial. Think of them as an alternative to DeepSeek.
This week, Alibaba’s “Qwen Team,” as its AI division is known, released the latest updates to its Qwen family, and they’re already attracting attention once more from AI power users in the West for their top performance, in one case, edging out even the new Kimi-2 model from rival Chinese AI startup Moonshot released in mid-July 2025.
The AI Impact Series Returns to San Francisco – August 5
The next phase of AI is here – are you ready? Join leaders from Block, GSK, and SAP for an exclusive look at how autonomous agents are reshaping enterprise workflows – from real-time decision-making to end-to-end automation.
Secure your spot now – space is limited: https://bit.ly/3GuuPLF
The new Qwen3-235B-A22B-2507-Instruct model — released on AI code sharing community Hugging Face alongside a “floating point 8” or FP8 version, which we’ll cover more in-depth below — improves from the original Qwen 3 on reasoning tasks, factual accuracy, and multilingual understanding. It also outperforms Claude Opus 4’s “non-thinking” version.
The new Qwen3 model update also delivers better coding results, alignment with user preferences, and long-context handling, according to its creators. But that’s not all…
Read on for what else it offers enterprise users and technical decision-makers.
FP8 version lets enterprises run Qwen 3 with far less memory and far less compute
In addition to the new Qwen3-235B-A22B-2507 model, the Qwen Team released an “FP8” version, which stands for 8-bit floating point, a format that compresses the model’s numerical operations to use less memory and processing power — without noticeably affecting its performance.
In practice, this means organizations can run a model with Qwen3’s capabilities on smaller, less expensive hardware or more efficiently in the cloud. The result is faster response times, lower energy costs, and the ability to scale deployments without needing massive infrastructure.
This makes the FP8 model especially attractive for production environments with tight latency or cost constraints. Teams can scale Qwen3’s capabilities to single-node GPU instances or local development machines, avoiding the need for massive multi-GPU clusters. It also lowers the barrier to private fine-tuning and on-premises deployments, where infrastructure resources are finite and total cost of ownership matters.
Even though Qwen team didn’t release official calculations, comparisons to similar FP8 quantized deployments suggest the efficiency savings are substantial. Here’s a practical illustration:
| Metric | FP16 Version (Instruct) | FP8 Version (Instruct-FP8) |
|---|---|---|
| GPU Memory Use | ~88 GB | ~30 GB |
| Inference Speed | ~30–40 tokens/sec | ~60–70 tokens/sec |
| Power Draw | High | ~30–50% lower |
| Number of GPUs Needed | 8× A100s or similar | 4× A100s or fewer |
Estimates based on industry norms for FP8 deployments. Actual results vary by batch size, prompt length, and inference framework (e.g., vLLM, Transformers, SGLang).
No more ‘hybrid reasoning’…instead Qwen will release separate reasoning and instruct models!
Perhaps most interesting of all, Qwen Team announced it will no longer be pursuing a “hybrid” reasoning approach, which it introduced back with Qwen 3 in April and seemed to be inspired by an approach pioneered by sovereign AI collective Nous Research.
This allowed users to toggle on a “reasoning” model, letting the AI model engage in its own self-checking and producing “chains-of-thought” before responding.
In a way, it was designed to mimic the reasoning capabilities of powerful proprietary models such as OpenAI’s “o” series (o1, o3, o4-mini, o4-mini-high), which also produce “chains-of-thought.”
However, unlike those rival models which always engage in such “reasoning” for every prompt, Qwen 3 could have the reasoning mode manually switched on or off by the user by clicking a “Thinking Mode” button on the Qwen website chatbot, or by typing “/think” before their prompt on a local or privately run model inference.
The idea was to give users control to engage the slower and more token-intensive thinking mode for more difficult prompts and tasks, and use a non-thinking mode for simpler prompts. But again, this put the onus on the user to decide. While flexible, it also introduced design complexity and inconsistent behavior in some cases.
Now As Qwen team wrote in its announcement post on X:
“After talking with the community and thinking it through, we decided to stop using hybrid thinking mode. Instead, we’ll train Instruct and Thinking models separately so we can get the best quality possible.”
With the 2507 update — an instruct or NON-REASONING model only, for now — Alibaba is no longer straddling both approaches in a single model. Instead, separate model variants will be trained for instruction and reasoning tasks respectively.
The result is a model that adheres more closely to user instructions, generates more predictable responses, and, as benchmark data shows, improves significantly across multiple evaluation domains.
Performance benchmarks and use cases
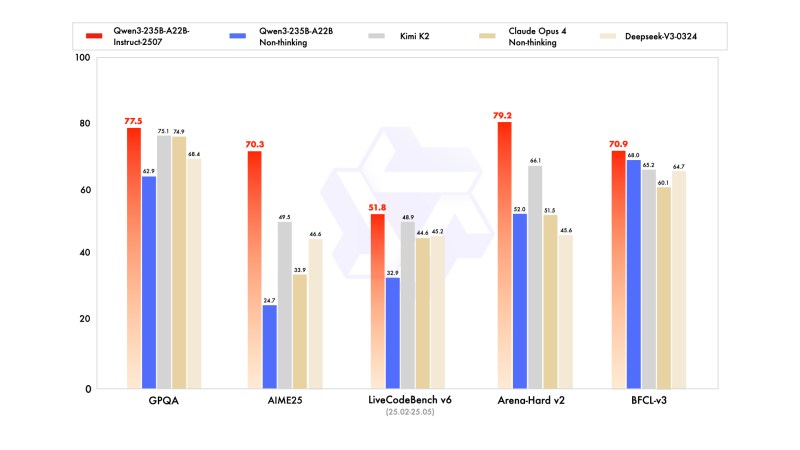
Compared to its predecessor, the Qwen3-235B-A22B-Instruct-2507 model delivers measurable improvements:
- MMLU-Pro scores rise from 75.2 to 83.0, a notable gain in general knowledge performance.
- GPQA and SuperGPQA benchmarks improve by 15–20 percentage points, reflecting stronger factual accuracy.
- Reasoning tasks such as AIME25 and ARC-AGI show more than double the previous performance.
- Code generation improves, with LiveCodeBench scores increasing from 32.9 to 51.8.
- Multilingual support expands, aided by improved coverage of long-tail languages and better alignment across dialects.
The model maintains a mixture-of-experts (MoE) architecture, activating 8 out of 128 experts during inference, with a total of 235 billion parameters—22 billion of which are active at any time.
As mentioned before, the FP8 version introduces fine-grained quantization for better inference speed and reduced memory usage.
Enterprise-ready by design
Unlike many open-source LLMs, which are often released under restrictive research-only licenses or require API access for commercial use, Qwen3 is squarely aimed at enterprise deployment.
Boasting a permissive Apache 2.0 license, this means enterprises can use it freely for commercial applications. They may also:
- Deploy models locally or through OpenAI-compatible APIs using vLLM and SGLang
- Fine-tune models privately using LoRA or QLoRA without exposing proprietary data
- Log and inspect all prompts and outputs on-premises for compliance and auditing
- Scale from prototype to production using dense variants (from 0.6B to 32B) or MoE checkpoints
Alibaba’s team also introduced Qwen-Agent, a lightweight framework that abstracts tool invocation logic for users building agentic systems.
Benchmarks like TAU-Retail and BFCL-v3 suggest the instruction model can competently execute multi-step decision tasks—typically the domain of purpose-built agents.
Community and industry reactions
The release has already been well received by AI power users.
Paul Couvert, AI educator and founder of private LLM chatbot host Blue Shell AI, posted a comparison chart on X showing Qwen3-235B-A22B-Instruct-2507 outperforming Claude Opus 4 and Kimi K2 on benchmarks like GPQA, AIME25, and Arena-Hard v2, calling it “even more powerful than Kimi K2… and even better than Claude Opus 4.”
AI influencer NIK (@ns123abc), commented on its rapid impact: “You’re laughing. Qwen-3-235B made Kimi K2 irrelevant after only one week despite being one quarter the size and you’re laughing.”
Meanwhile, Jeff Boudier, head of product at Hugging Face, highlighted the deployment benefits: “Qwen silently released a massive improvement to Qwen3… it tops best open (Kimi K2, a 4x larger model) and closed (Claude Opus 4) LLMs on benchmarks.”
He praised the availability of an FP8 checkpoint for faster inference, 1-click deployment on Azure ML, and support for local use via MLX on Mac or INT4 builds from Intel.
The overall tone from developers has been enthusiastic, as the model’s balance of performance, licensing, and deployability appeals to both hobbyists and professionals.
What’s next for Qwen team?
Alibaba is already laying the groundwork for future updates. A separate reasoning-focused model is in the pipeline, and the Qwen roadmap points toward increasingly agentic systems capable of long-horizon task planning.
Multimodal support, seen in Qwen2.5-Omni and Qwen-VL models, is also expected to expand further.
And already, rumors and rumblings have started as Qwen team members tease yet another update to their model family incoming, with updates on their web properties revealing URL strings for a new Qwen3-Coder-480B-A35B-Instruct model, likely a 480-billion parameter mixture-of-experts (MoE) with a token context of 1 million.
What Qwen3-235B-A22B-Instruct-2507 ultimately signals is not just another leap in benchmark performance, but a maturation of open models as viable alternatives to proprietary systems.
The flexibility of deployment, strong general performance, and enterprise-friendly licensing give the model a unique edge in a crowded field.
For teams looking to integrate advanced instruction-following models into their AI stack—without the limitations of vendor lock-in or usage-based fees—Qwen3 is a serious contender.