Singapore-based AI startup Sapient Intelligence has developed a new AI architecture that can match, and in some cases vastly outperform, large language models (LLMs) on complex reasoning tasks, all while being significantly smaller and more data-efficient.
The architecture, known as the Hierarchical Reasoning Model (HRM), is inspired by how the human brain utilizes distinct systems for slow, deliberate planning and fast, intuitive computation. The model achieves impressive results with a fraction of the data and memory required by today’s LLMs. This efficiency could have important implications for real-world enterprise AI applications where data is scarce and computational resources are limited.
When faced with a complex problem, current LLMs largely rely on chain-of-thought (CoT) prompting, breaking down problems into intermediate text-based steps, essentially forcing the model to “think out loud” as it works toward a solution.
While CoT has improved the reasoning abilities of LLMs, it has fundamental limitations. In their paper, researchers at Sapient Intelligence argue that “CoT for reasoning is a crutch, not a satisfactory solution. It relies on brittle, human-defined decompositions where a single misstep or a misorder of the steps can derail the reasoning process entirely.”
The AI Impact Series Returns to San Francisco – August 5
The next phase of AI is here – are you ready? Join leaders from Block, GSK, and SAP for an exclusive look at how autonomous agents are reshaping enterprise workflows – from real-time decision-making to end-to-end automation.
Secure your spot now – space is limited: https://bit.ly/3GuuPLF
This dependency on generating explicit language tethers the model’s reasoning to the token level, often requiring massive amounts of training data and producing long, slow responses. This approach also overlooks the type of “latent reasoning” that occurs internally, without being explicitly articulated in language.
As the researchers note, “A more efficient approach is needed to minimize these data requirements.”
A hierarchical approach inspired by the brain
To move beyond CoT, the researchers explored “latent reasoning,” where instead of generating “thinking tokens,” the model reasons in its internal, abstract representation of the problem. This is more aligned with how humans think; as the paper states, “the brain sustains lengthy, coherent chains of reasoning with remarkable efficiency in a latent space, without constant translation back to language.”
However, achieving this level of deep, internal reasoning in AI is challenging. Simply stacking more layers in a deep learning model often leads to a “vanishing gradient” problem, where learning signals weaken across layers, making training ineffective. An alternative, recurrent architectures that loop over computations can suffer from “early convergence,” where the model settles on a solution too quickly without fully exploring the problem.
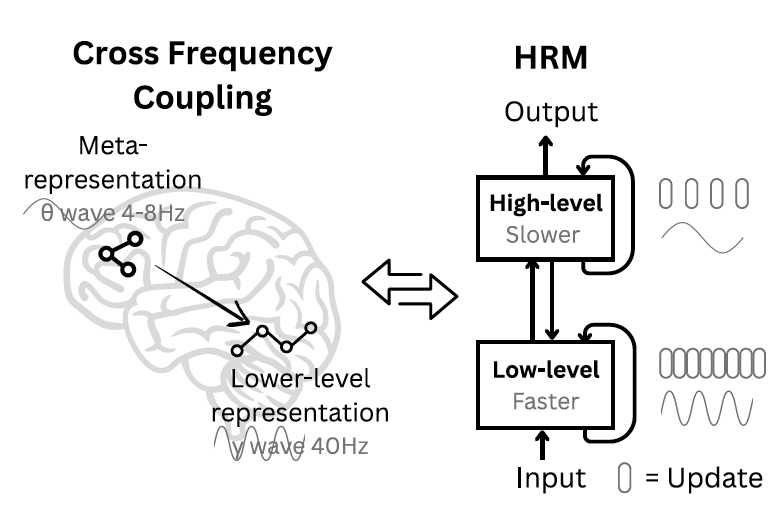
Seeking a better approach, the Sapient team turned to neuroscience for a solution. “The human brain provides a compelling blueprint for achieving the effective computational depth that contemporary artificial models lack,” the researchers write. “It organizes computation hierarchically across cortical regions operating at different timescales, enabling deep, multi-stage reasoning.”
Inspired by this, they designed HRM with two coupled, recurrent modules: a high-level (H) module for slow, abstract planning, and a low-level (L) module for fast, detailed computations. This structure enables a process the team calls “hierarchical convergence.” Intuitively, the fast L-module addresses a portion of the problem, executing multiple steps until it reaches a stable, local solution. At that point, the slow H-module takes this result, updates its overall strategy, and gives the L-module a new, refined sub-problem to work on. This effectively resets the L-module, preventing it from getting stuck (early convergence) and allowing the entire system to perform a long sequence of reasoning steps with a lean model architecture that doesn’t suffer from vanishing gradients.
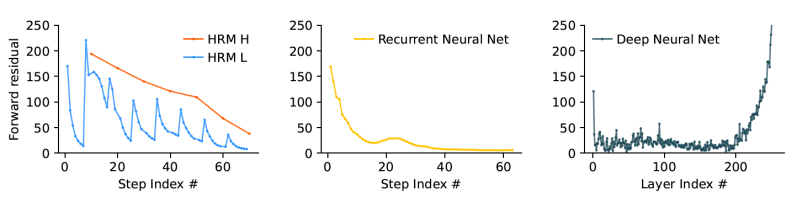
According to the paper, “This process allows the HRM to perform a sequence of distinct, stable, nested computations, where the H-module directs the overall problem-solving strategy and the L-module executes the intensive search or refinement required for each step.” This nested-loop design allows the model to reason deeply in its latent space without needing long CoT prompts or huge amounts of data.
A natural question is whether this “latent reasoning” comes at the cost of interpretability. Guan Wang, Founder and CEO of Sapient Intelligence, pushes back on this idea, explaining that the model’s internal processes can be decoded and visualized, similar to how CoT provides a window into a model’s thinking. He also points out that CoT itself can be misleading. “CoT does not genuinely reflect a model’s internal reasoning,” Wang told VentureBeat, referencing studies showing that models can sometimes yield correct answers with incorrect reasoning steps, and vice versa. “It remains essentially a black box.”

HRM in action
To test their model, the researchers pitted HRM against benchmarks that require extensive search and backtracking, such as the Abstraction and Reasoning Corpus (ARC-AGI), extremely difficult Sudoku puzzles and complex maze-solving tasks.
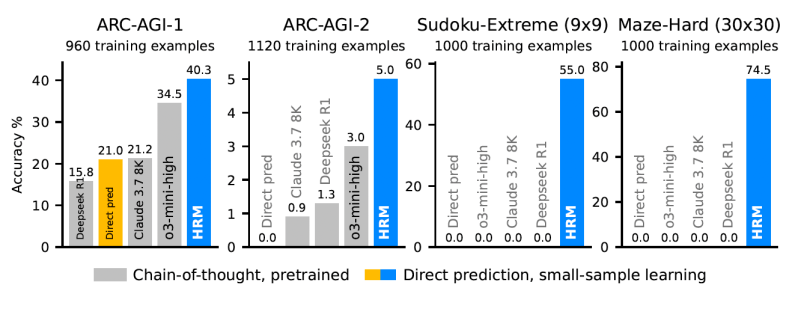
The results show that HRM learns to solve problems that are intractable for even advanced LLMs. For instance, on the “Sudoku-Extreme” and “Maze-Hard” benchmarks, state-of-the-art CoT models failed completely, scoring 0% accuracy. In contrast, HRM achieved near-perfect accuracy after being trained on just 1,000 examples for each task.
On the ARC-AGI benchmark, a test of abstract reasoning and generalization, the 27M-parameter HRM scored 40.3%. This surpasses leading CoT-based models like the much larger o3-mini-high (34.5%) and Claude 3.7 Sonnet (21.2%). This performance, achieved without a large pre-training corpus and with very limited data, highlights the power and efficiency of its architecture.
While solving puzzles demonstrates the model’s power, the real-world implications lie in a different class of problems. According to Wang, developers should continue using LLMs for language-based or creative tasks, but for “complex or deterministic tasks,” an HRM-like architecture offers superior performance with fewer hallucinations. He points to “sequential problems requiring complex decision-making or long-term planning,” especially in latency-sensitive fields like embodied AI and robotics, or data-scarce domains like scientific exploration.
In these scenarios, HRM doesn’t just solve problems; it learns to solve them better. “In our Sudoku experiments at the master level… HRM needs progressively fewer steps as training advances—akin to a novice becoming an expert,” Wang explained.
For the enterprise, this is where the architecture’s efficiency translates directly to the bottom line. Instead of the serial, token-by-token generation of CoT, HRM’s parallel processing allows for what Wang estimates could be a “100x speedup in task completion time.” This means lower inference latency and the ability to run powerful reasoning on edge devices.
The cost savings are also substantial. “Specialized reasoning engines such as HRM offer a more promising alternative for specific complex reasoning tasks compared to large, costly, and latency-intensive API-based models,” Wang said. To put the efficiency into perspective, he noted that training the model for professional-level Sudoku takes roughly two GPU hours, and for the complex ARC-AGI benchmark, between 50 and 200 GPU hours—a fraction of the resources needed for massive foundation models. This opens a path to solving specialized business problems, from logistics optimization to complex system diagnostics, where both data and budget are finite.
Looking ahead, Sapient Intelligence is already working to evolve HRM from a specialized problem-solver into a more general-purpose reasoning module. “We are actively developing brain-inspired models built upon HRM,” Wang said, highlighting promising initial results in healthcare, climate forecasting, and robotics. He teased that these next-generation models will differ significantly from today’s text-based systems, notably through the inclusion of self-correcting capabilities.
The work suggests that for a class of problems that have stumped today’s AI giants, the path forward may not be bigger models, but smarter, more structured architectures inspired by the ultimate reasoning engine: the human brain.