Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
The open source model race just keeps on getting more interesting.
Today, The Allen Institute for AI (Ai2) debuted its latest entrant in the race with the launch of its open source Tülu 3 405B parameter large language model (LLM). The new model not only matches Open AI’s GPT-4o’s capabilities but also surpasses DeepSeek’s V3 model across critical benchmarks.
This isn’t the first time the Ai2 has made bold claims about a new model. In Nov. 2024 the company released its first version of Tülu 3, which had both 8 and 70 billion parameter versions. At the time, Ai2 claimed the model was up to par with the latest GPT-4 model from OpenAI, Anthropic’s Claude and Google’s Gemini. The big difference being that Tülu 3 is open source. Ai2 had also claimed back in Sept. 2024 that its Molmo models were able to beat GPT-4o and Claude on some benchmarks.
While benchmark performance data is interesting, what’s perhaps more useful is the training innovations that enable the new Ai2 model.
Pushing post-training to the limit
The big breakthrough for Tülu 3 405B is rooted in an innovation that first appeared with the initial Tülu 3 release in 2024. That release utilizes a combination of advanced post-training techniques to get better performance.
With the Tülu 3 405B model, those post-training techniques have been pushed even further, using an advanced post-training methodology that combines supervised fine-tuning, preference learning, and a novel reinforcement learning approach that has proven exceptional at larger scales.
“Applying Tülu 3’s post-training recipes to Tülu 3-405B, our largest-scale, fully open-source post-trained model to date, levels the playing field by providing open fine-tuning recipes, data, and code, empowering developers and researchers to achieve performance comparable to top-tier closed models,” Hannaneh Hajishirzi, senior director of NLP Research at Ai2 told VentureBeat.
Advancing the state of open source AI post-training with RLVR
Post-training is something that other models, including DeepSeek v3, do as well.
The key innovation that helps to differentiate Tülu 3 is Ai2’s Reinforcement Learning from Verifiable Rewards (RLVR) system.
Unlike traditional training approaches, RLVR uses verifiable outcomes—such as solving mathematical problems correctly—to fine-tune the model’s performance. This technique, when combined with Direct Preference Optimization (DPO) and carefully curated training data, has enabled the model to achieve better accuracy in complex reasoning tasks while maintaining strong safety characteristics.
Key technical innovations in the RLVR implementation include:
- Efficient parallel processing across 256 GPUs
- Optimized weight synchronization
- Balanced compute distribution across 32 nodes
- Integrated vLLM deployment with 16-way tensor parallelism
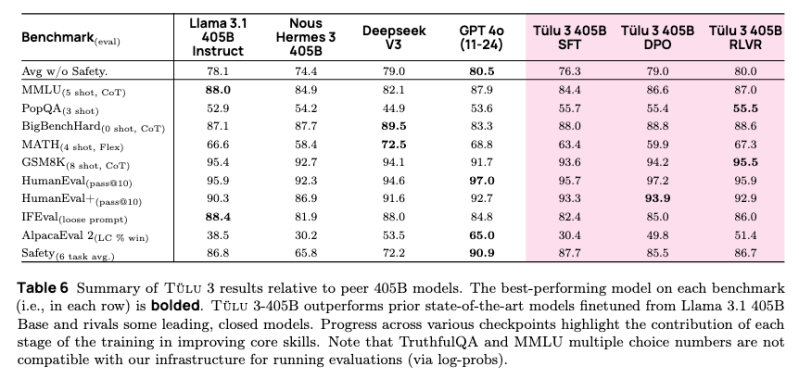
The RLVR system showed improved results at the 405B parameter scale compared to smaller models. The system also demonstrated particularly strong results in safety evaluations, outperforming both DeepSeek V3 , Llama 3.1 and Nous Hermes 3. Notably, the RLVR framework’s effectiveness increased with model size, suggesting potential benefits from even larger-scale implementations.
How Tülu 3 405B compares to GPT-4o and DeepSeek v3
The model’s competitive positioning is particularly noteworthy in the current AI landscape.
Tülu 3 405B not only matches the capabilities of GPT-4o but also outperforms DeepSeek v3 in some areas particularly with safety benchmarks.
Across a suite of 10 AI benchmarks evaluation including safety benchmarks, Ai2 reported that the Tülu 3 405B RLVR model had an average score of 80.7, surpassing DeepSeek V3’s 75.9. Tülu however is not quite as good at GPT-4o which scored 81.6. Overall the metrics suggest that Tülu 3 405B is at the very least extremely competitive with GPT-4o and DeepSeek V3 across the benchmarks.
Why open source AI matters and how Ai2 is doing it differently
What makes Tülu 3 405B different for users though is how Ai2 has made the model available.
There is a lot of noise in the AI market about open source. DeepSeek says it’s open source and so is Meta’s Llama 3.1, which Tülu 3 405B also outperforms.
With both DeepSeek and Llama the models are freely available for use; there is some, but not all code available.
For example, DeepSeek-R1 has released its model code and pre-trained weights but not the training data. Ai2 is taking a differentiated approach in an attempt to be more open.
“We don’t leverage any closed datasets,” Hajishirzi said. “As with our first Tulu 3 release in November 2024, we are releasing all of the infrastructure code.”
She added that Ai2’s fully-open approach which includes data, training code and models ensures users can easily customize their pipeline for everything from data selection through evaluation. Users can access the full suite of Tulu 3 models, including Tulu 3-405B, on Ai2’s Tulu 3 page here, or test the Tulu 3-405B functionality through Ai2’s Playground demo space here.