Want smarter insights in your inbox? Sign up for our weekly newsletters to get only what matters to enterprise AI, data, and security leaders. Subscribe Now
Physical AI, where robotics and foundation models come together, is fast becoming a growing space with companies like Nvidia, Google and Meta releasing research and experimenting in melding large language models (LLMs) with robots.
New research from the Allen Institute for AI (Ai2) aims to challenge Nvidia and Google in physical AI with the release of MolmoAct 7B, a new open-source model that allows robots to “reason in space. MolmoAct, based on Ai2’s open source Molmo, “thinks” in three dimensions. It is also releasing its training data. Ai2 has an Apache 2.0 license for the model, while the datasets are licensed under CC BY-4.0.
Ai2 classifies MolmoAct as an Action Reasoning Model, in which foundation models reason about actions within a physical, 3D space.
What this means is that MolmoAct can use its reasoning capabilities to understand the physical world, plan how it occupies space and then take that action.
AI Scaling Hits Its Limits
Power caps, rising token costs, and inference delays are reshaping enterprise AI. Join our exclusive salon to discover how top teams are:
- Turning energy into a strategic advantage
- Architecting efficient inference for real throughput gains
- Unlocking competitive ROI with sustainable AI systems
Secure your spot to stay ahead: https://bit.ly/4mwGngO
“MolmoAct has reasoning in 3D space capabilities versus traditional vision-language-action (VLA) models,” Ai2 told VentureBeat in an email. “Most robotics models are VLAs that don’t think or reason in space, but MolmoAct has this capability, making it more performant and generalizable from an architectural standpoint.”
Physical understanding
Since robots exist in the physical world, Ai2 claims MolmoAct helps robots take in their surroundings and make better decisions on how to interact with them.
“MolmoAct could be applied anywhere a machine would need to reason about its physical surroundings,” the company said. “We think about it mainly in a home setting because that’s where the greatest challenge lies for robotics, because there things are irregular and constantly changing, but MolmoAct can be applied anywhere.”
MolmoAct can understand the physical world by outputting “spatially grounded perception tokens,” which are tokens pretrained and extracted using a vector-quantized variational autoencoder or a model that converts data inputs, such as video, into tokens. The company said these tokens differ from those used by VLAs in that they are not text inputs.
These enable MolmoAct to gain spatial understanding and encode geometric structures. With these, the model estimates the distance between objects.
Once it has an estimated distance, MolmoAct then predicts a sequence of “image-space” waypoints or points in the area where it can set a path to. After that, the model will begin outputting specific actions, such as dropping an arm by a few inches or stretching out.
Ai2’s researchers said they were able to get the model to adapt to different embodiments (i.e., either a mechanical arm or a humanoid robot) “with only minimal fine-tuning.”
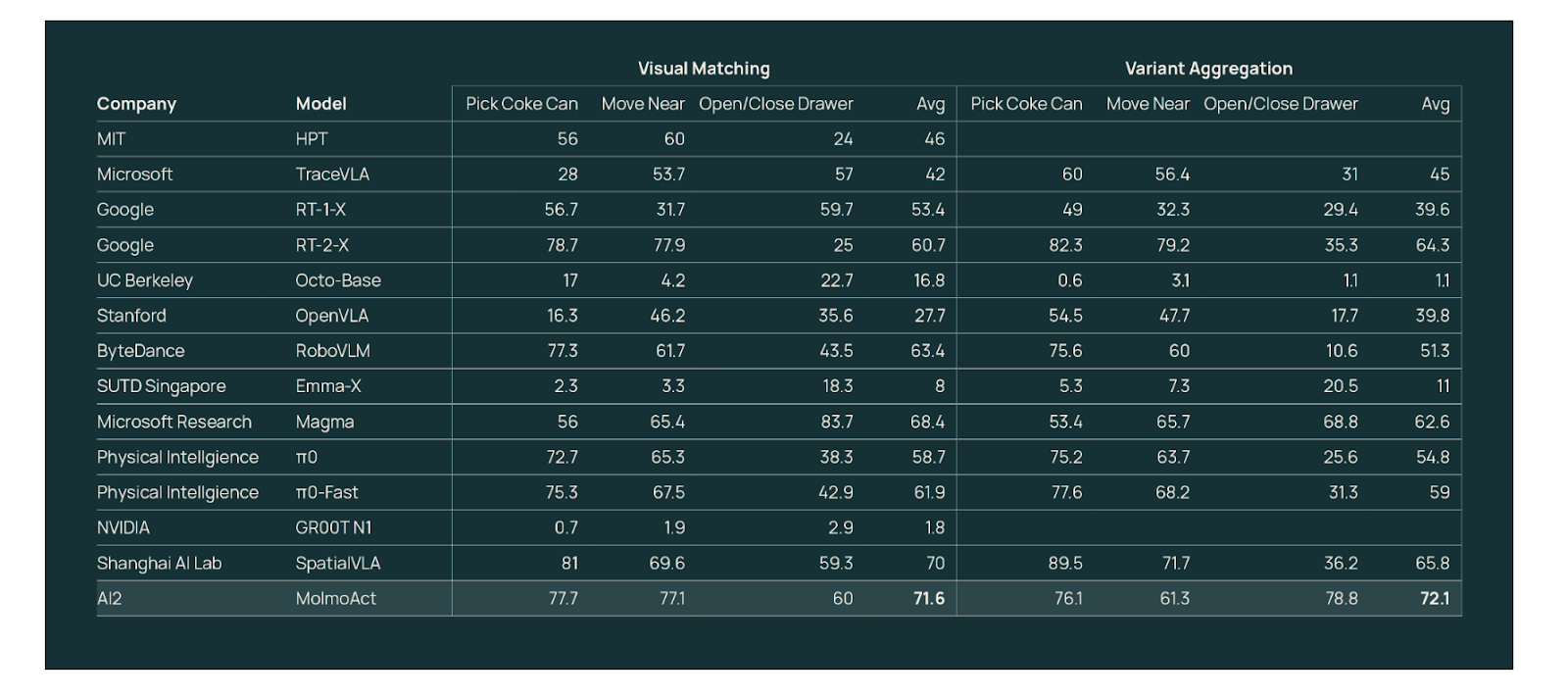
Benchmarking testing conducted by Ai2 showed MolmoAct 7B had a task success rate of 72.1%, beating models from Google, Microsoft and Nvidia.
A small step forward
Ai2’s research is the latest to take advantage of the unique benefits of LLMs and VLMs, especially as the pace of innovation in generative AI continues to grow. Experts in the field see work from Ai2 and other tech companies as building blocks.
Alan Fern, professor at the Oregon State University College of Engineering, told VentureBeat that Ai2’s research “represents a natural progression in enhancing VLMs for robotics and physical reasoning.”
“While I wouldn’t call it revolutionary, it’s an important step forward in the development of more capable 3D physical reasoning models,” Fern said. “Their focus on truly 3D scene understanding, as opposed to relying on 2D models, marks a notable shift in the right direction. They’ve made improvements over prior models, but these benchmarks still fall short of capturing real-world complexity and remain relatively controlled and toyish in nature.”
He added that while there’s still room for improvement on the benchmarks, he is “eager to test this new model on some of our physical reasoning tasks.”
Daniel Maturana, co-founder of the start-up Gather AI, praised the openness of the data, noting that “this is great news because developing and training these models is expensive, so this is a strong foundation to build on and fine-tune for other academic labs and even for dedicated hobbyists.”
Increasing interest in physical AI
It has been a long-held dream for many developers and computer scientists to create more intelligent, or at least more spatially aware, robots.
However, building robots that process what they can “see” quickly and move and react smoothly gets difficult. Before the advent of LLMs, scientists had to code every single movement. This naturally meant a lot of work and less flexibility in the types of robotic actions that can occur. Now, LLM-based methods allow robots (or at least robotic arms) to determine the following possible actions to take based on objects it is interacting with.
Google Research’s SayCan helps a robot reason about tasks using an LLM, enabling the robot to determine the sequence of movements required to achieve a goal. Meta and New York University’s OK-Robot uses visual language models for movement planning and object manipulation.
Hugging Face released a $299 desktop robot in an effort to democratize robotics development. Nvidia, which proclaimed physical AI to be the next big trend, released several models to fast-track robotic training, including Cosmos-Transfer1.
OSU’s Fern said there’s more interest in physical AI even though demos remain limited. However, the quest to achieve general physical intelligence, which eliminates the need to individually program actions for robots, is becoming easier.
“The landscape is more challenging now, with less low-hanging fruit. On the other hand, large physical intelligence models are still in their early stages and are much more ripe for rapid advancements, which makes this space particularly exciting,” he said.