While working at a biotech company, we aim to advance ML & AI Algorithms to enable, for example, brain lesion segmentation to be executed at the hospital/clinic location where patient data resides, so it is processed in a secure manner. This, in essence, is guaranteed by federated learning mechanisms, which we have adopted in numerous real-world hospital settings. However, when an algorithm is already considered as a company asset, we also need means that protect not only sensitive data, but also secure algorithms in a heterogeneous federated environment.
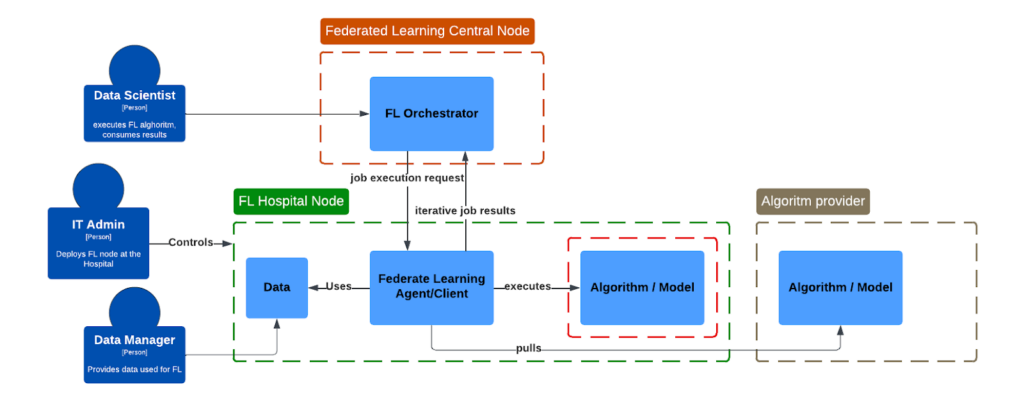
Most algorithms are assumed to be encapsulated within docker-compatible containers, allowing them to use different libraries and runtimes independently. It is assumed that there is a 3rd party IT administrator who will aim to secure patients’ data and lock the deployment environment, making it inaccessible for algorithm providers. This perspective describes different mechanisms intended to package and protect containerized workloads against theft of intellectual property by a local system administrator.
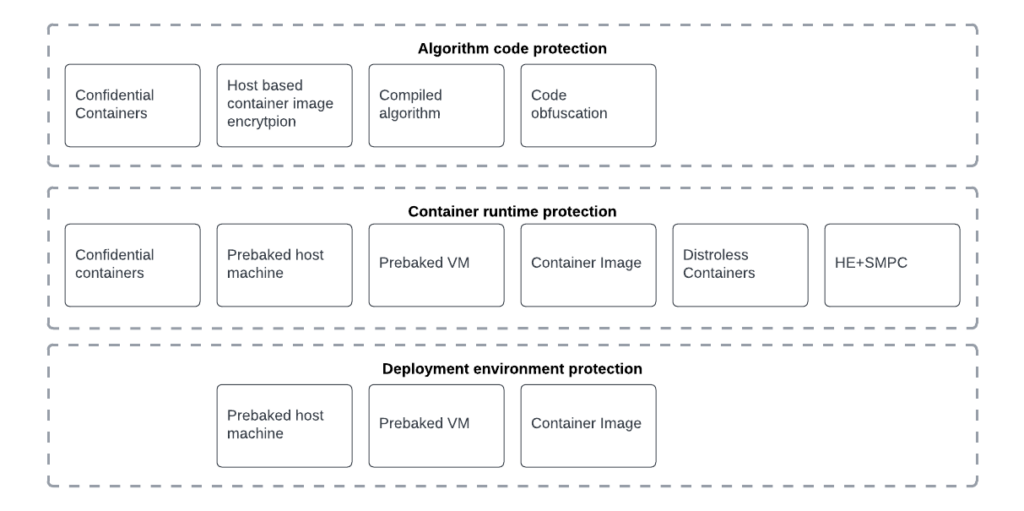
To ensure a comprehensive approach, we will address protection measures across three critical layers:
- Algorithm code protection: Measures to secure algorithm code, preventing unauthorized access or reverse engineering.
- Runtime environment: Evaluates risks of administrators accessing confidential data within a containerized system.
- Deployment environment: Infrastructure safeguards against unauthorized system administrator access.
Methodology
After analysis of risks, we have identified two protection measures categories:
- Intellectual property theft and unauthorized distribution: preventing administrator users from accessing, copying, executing the algorithm.
- Reverse engineering risk reduction: blocking administrator users from analyzing code to uncover and claim ownership.
While understanding the subjectivity of this assessment, we have considered both qualitative and quantitative characteristics of all mechanisms.
Qualitative assessment
Categories mentioned were considered when selecting suitable solution and are considered in summary:
- Hardware dependency: potential lock-in and scalability challenges in federated systems.
- Software dependency: reflects maturity and long-term stability
- Hardware and Software dependency: measures setup complexity, deployment and maintenance effort
- Cloud dependency: risks of lock-in with a single cloud hypervisor
- Hospital environment: evaluates technology maturity and requirements heterogeneous hardware setups.
- Cost: covers for dedicated hardware, implementation and maintenance
Quantitative assessment
Subjective risk reduction quantitative assessment description:
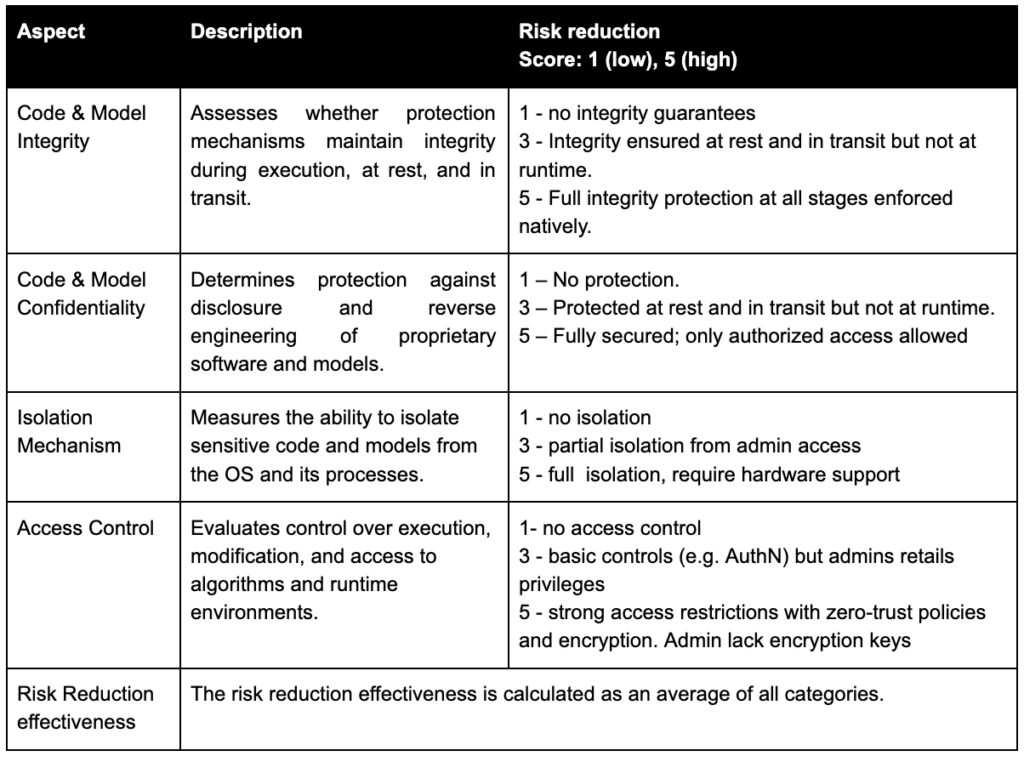
Considering the above methodology and assessment criteria, we came up with a list of mechanisms that have the potential to guarantee the objective.
Confidential containers
Confidential Containers (CoCo) is an emerging CNCF technology that aims to deliver confidential runtime environments that will run CPU and GPU workloads while protecting the algorithm code and data from the hosting company.
CoCo supports multiple TEE, including Intel TDX/SGX and AMD SEV hardware technologies, including extensions of NVidia GPU operators, that use hardware-backed protection of code and data during its execution, preventing scenarios in which a determined and skillful local administrator uses a local debugger to dump the contents of the container memory and has access to both the algorithm and data being processed.
Trust is built using cryptographic attestation of runtime environment and code that is executed. It makes sure the code is not tempered with nor read by remote admin.
This appears to be a perfect fit for our problem, as the remote data site admin would not be able to access the algorithm code. Unfortunately, the current state of the CoCo software stack, despite continuous efforts, still suffers from security gaps that enable the malicious administrators to issue attestation for themselves and effectively bypass all the other protection mechanisms, rendering all of them effectively useless. Each time the technology gets closer to practical production readiness, a new fundamental security issue is discovered that needs to be addressed. It is worth noting that this community is fairly transparent in communicating gaps.
The often and rightfully recognized additional complexity introduced by TEEs and CoCo (specialized hardware, configuration burden, runtime overhead due to encryption) would be justifiable if the technology delivered on its promise of code protection. While TEE seems to be well adopted, CoCo is close but not there yet and based on our experiences the horizon keeps on moving, as new fundamental vulnerabilities are discovered and need to be addressed.
In other words, if we had production-ready CoCo, it would have been a solution to our problem.
Host-based container image encryption at rest (protection at rest and in transit)
This strategy is based on end-to-end protection of container images containing the algorithm.
It protects the source code of the algorithm at rest and in transit but does not protect it at runtime, as the container needs to be decrypted prior to the execution.
The malicious administrator at the site has direct or indirect access to the decryption key, so he can read container contents just after it is decrypted for the execution time.
Another attack scenario is to attach a debugger to the running container image.
So host-based container image encryption at rest makes it harder to steal the algorithm from a storage device and in transit due to encryption, but moderately skilled administrators can decrypt and expose the algorithm.
In our opinion, the increased practical effort of decrypting the algorithm (time, effort, skillset, infrastructure) from the container by the administrator who has access to the decryption key is too low to be considered as a valid algorithm protection mechanism.
Prebaked custom virtual machine
In this scenario the algorithm owner is delivering an encrypted virtual machine.
The key can be added at boot time from the keyboard by someone else than admin (required at each reboot), from external storage (USB Key, very vulnerable, as anyone with physical access can attach the key storage), or using a remote SSH session (using Dropbear for instance) without allowing local admin to unlock the bootloader and disk.
Effective and established technologies such as LUKS can be used to fully encrypt local VM filesystems including bootloader.
However, even if the remote key is provided using a boot-level tiny SSH session by someone other than a malicious admin, the runtime is exposed to a hypervisor-level debugger attack, as after boot, the VM memory is decrypted and can be scanned for code and data.
Still, this solution, especially with remotely provided keys by the algorithm owner, provides significantly increased algorithm code protection compared to encrypted containers because an attack requires more skills and determination than just decrypting the container image using a decryption key.
To prevent memory dump analysis, we considered deploying a prebaked host machine with ssh possessed keys at boot time, this removes any hypervisor level access to memory. As a side note, there are methods to freeze physical memory modules to delay loss of data.
Distroless container images
Distroless container images are reducing the number of layers and components to a minimum required to run the algorithm.
The attack surface is greatly reduced, as there are fewer components prone to vulnerabilities and known attacks. They are also lighter in terms of storage, network transmission, and latency.
However, despite these improvements, the algorithm code is not protected at all.
Distroless containers are recommended as more secure containers but not the containers that protect the algorithm, as the algorithm is there, container image can be easily mounted and algorithm can be stolen without a significant effort.
Being distroless does not address our goal of protecting the algorithm code.
Compiled algorithm
Most machine learning algorithms are written in Python. This interpreted language makes it really easy not only to execute the algorithm code on other machines and in other environments but also to access source code and be able to modify the algorithm.
The potential scenario even enables the party that steals the algorithm code to modify it, let’s say 30% or more of the source code, and claim it’s no longer the original algorithm, and could even make a legal action much harder to provide evidence of intellectual property infringement.
Compiled languages, such as C, C++, Rust, when combined with strong compiler optimization (-O3 in the case of C, linker-time optimizations), make the source code not only unavailable as such, but also much harder to reverse engineer source code.
Compiler optimizations introduce significant control flow changes, mathematical operations substitutions, function inlining, code restructuring, and difficult stack tracing.
This makes it much harder to reverse engineer the code, making it a practically infeasible option in some scenarios, thus it can be considered as a way to increase the cost of reverse engineering attack by orders of magnitude compared to plain Python code.
There’s an increased complexity and skill gap, as most of the algorithms are written in Python and would have to be converted to C, C++ or Rust.
This option does increase the cost of further development of the algorithm and even modifying it to make a claim of its ownership but it does not prevent the algorithm from being executed outside of the agreed contractual scope.
Code obfuscation
The established technique of making the code much less readable, harder to understand and develop further can be used to make algorithm evolutions much harder.
Unfortunately, it does not prevent the algorithm from being executed outside of contractual scope.
Also, the de-obfuscation technologies are getting much better, thanks to advanced language models, lowering the practical effectiveness of code obfuscation.
Code obfuscation does increase the practical cost of algorithm reverse engineering, so it’s worth considering as an option combined with other options (for instance, with compiled code and custom VMs).
Homomorphic Encryption as code protection mechanism
Homomorphic Encryption (HE) is a promised technology aimed at protecting the data, very interesting from secure aggregation strategies of partial results in Federated Learning and analytics scenarios.
The aggregation party (with limited trust) can only process encrypted data and perform encrypted aggregations, then it can decrypt aggregated results without being able to decrypt any individual data.
Practical applications of HE are limited due to its complexity, performance hits, limited number of supported operations, there’s observable progress (including GPU acceleration for HE) but still it’s a niche and emerging data protection technique.
From an algorithm protection goal perspective, HE is not designed, nor can be made to protect the algorithm. So it’s not an algorithm protection mechanism at all.
Conclusions

In essence, we described and assessed strategies and technologies to protect algorithm IP and sensitive data in the context of deploying Medical Algorithms and running them in potentially untrusted environments, such as hospitals.
What’s visible, the most promising technologies are those that provide a degree of hardware isolation. However those make an algorithm provider completely dependent on the runtime it will be deployed. While compilation and obfuscation do not mitigate completely the risk of intellectual property theft, especially even basic LLM seem to be helpful, those methods, especially when combined, make algorithms very difficult, thus expensive, to use and modify the code. Which would already provide a degree of security.
Prebaked host/virtual machines are the most common and adopted methods, extended with features like full disk encryption with keys acquired during boot via SSH, which could make it fairly difficult for local admin to access any data. However, especially pre-baked machines could cause certain compliance concerns at the hospital, and this needs to be assessed prior to establishing a federated network.
Key Hardware and Software vendors(Intel, AMD, NVIDIA, Microsoft, RedHat) recognized significant demand and continue to evolve, which gives a promise that training IP-protected algorithms in a federated manner, without disclosing patients’ data, will soon be within reach. However, hardware-supported methods are very sensitive to hospital internal infrastructure, which by nature is quite heterogeneous. Therefore, containerisation provides some promise of portability. Considering this, Confidential Containers technology seems to be a very tempting promise provided by collaborators, while it’s still not fullyproduction-readyy.
Certainly combining above mechanisms, code, runtime and infrastructure environment supplemented with proper legal framework decrease residual risks, however no solution provides absolute protection particularly against determined adversaries with privileged access – the combined effect of these measures creates substantial barriers to intellectual property theft.
We deeply appreciate and value feedback from the community helping to further steer future efforts to develop sustainable, secure and effective methods for accelerating AI development and deployment. Together, we can tackle these challenges and achieve groundbreaking progress, ensuring robust security and compliance in various contexts.
Contributions: The author would like to thank Jacek Chmiel, Peter Fernana Richie, Vitor Gouveia and the Federated Open Science team at Roche for brainstorming, pragmatic solution-oriented thinking, and contributions.
Link & Resources
Intel Confidential Containers Guide
Nvidia blog describing integration with CoCo Confidential Containers Github & Kata Agent Policies
Commercial Vendors: Edgeless systems contrast, Redhat & Azure
Remote Unlock of LUKS encrypted disk
A perfect match to elevate privacy-enhancing healthcare analytics
Differential Privacy and Federated Learning for Medical Data