Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Retrieval-augmented generation (RAG) has become the de-facto way of customizing large language models (LLMs) for bespoke information. However, RAG comes with upfront technical costs and can be slow. Now, thanks to advances in long-context LLMs, enterprises can bypass RAG by inserting all the proprietary information in the prompt.
A new study by the National Chengchi University in Taiwan shows that by using long-context LLMs and caching techniques, you can create customized applications that outperform RAG pipelines. Called cache-augmented generation (CAG), this approach can be a simple and efficient replacement for RAG in enterprise settings where the knowledge corpus can fit in the model’s context window.
Limitations of RAG
RAG is an effective method for handling open-domain questions and specialized tasks. It uses retrieval algorithms to gather documents that are relevant to the request and adds context to enable the LLM to craft more accurate responses.
However, RAG introduces several limitations to LLM applications. The added retrieval step introduces latency that can degrade the user experience. The result also depends on the quality of the document selection and ranking step. In many cases, the limitations of the models used for retrieval require documents to be broken down into smaller chunks, which can harm the retrieval process.
And in general, RAG adds complexity to the LLM application, requiring the development, integration and maintenance of additional components. The added overhead slows the development process.
Cache-augmented retrieval
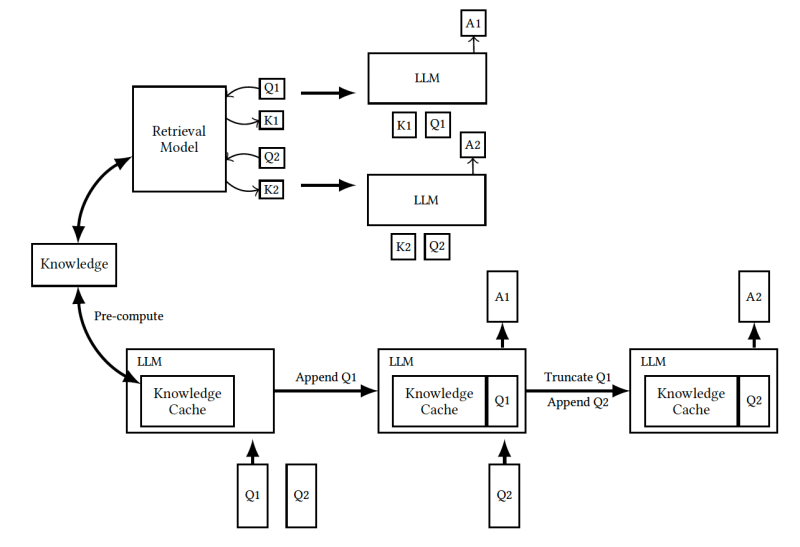
The alternative to developing a RAG pipeline is to insert the entire document corpus into the prompt and have the model choose which bits are relevant to the request. This approach removes the complexity of the RAG pipeline and the problems caused by retrieval errors.
However, there are three key challenges with front-loading all documents into the prompt. First, long prompts will slow down the model and increase the costs of inference. Second, the length of the LLM’s context window sets limits to the number of documents that fit in the prompt. And finally, adding irrelevant information to the prompt can confuse the model and reduce the quality of its answers. So, just stuffing all your documents into the prompt instead of choosing the most relevant ones can end up hurting the model’s performance.
The CAG approach proposed leverages three key trends to overcome these challenges.
First, advanced caching techniques are making it faster and cheaper to process prompt templates. The premise of CAG is that the knowledge documents will be included in every prompt sent to the model. Therefore, you can compute the attention values of their tokens in advance instead of doing so when receiving requests. This upfront computation reduces the time it takes to process user requests.
Leading LLM providers such as OpenAI, Anthropic and Google provide prompt caching features for the repetitive parts of your prompt, which can include the knowledge documents and instructions that you insert at the beginning of your prompt. With Anthropic, you can reduce costs by up to 90% and latency by 85% on the cached parts of your prompt. Equivalent caching features have been developed for open-source LLM-hosting platforms.
Second, long-context LLMs are making it easier to fit more documents and knowledge into prompts. Claude 3.5 Sonnet supports up to 200,000 tokens, while GPT-4o supports 128,000 tokens and Gemini up to 2 million tokens. This makes it possible to include multiple documents or entire books in the prompt.
And finally, advanced training methods are enabling models to do better retrieval, reasoning and question-answering on very long sequences. In the past year, researchers have developed several LLM benchmarks for long-sequence tasks, including BABILong, LongICLBench, and RULER. These benchmarks test LLMs on hard problems such as multiple retrieval and multi-hop question-answering. There is still room for improvement in this area, but AI labs continue to make progress.
As newer generations of models continue to expand their context windows, they will be able to process larger knowledge collections. Moreover, we can expect models to continue improving in their abilities to extract and use relevant information from long contexts.
“These two trends will significantly extend the usability of our approach, enabling it to handle more complex and diverse applications,” the researchers write. “Consequently, our methodology is well-positioned to become a robust and versatile solution for knowledge-intensive tasks, leveraging the growing capabilities of next-generation LLMs.”
RAG vs CAG
To compare RAG and CAG, the researchers ran experiments on two widely recognized question-answering benchmarks: SQuAD, which focuses on context-aware Q&A from single documents, and HotPotQA, which requires multi-hop reasoning across multiple documents.
They used a Llama-3.1-8B model with a 128,000-token context window. For RAG, they combined the LLM with two retrieval systems to obtain passages relevant to the question: the basic BM25 algorithm and OpenAI embeddings. For CAG, they inserted multiple documents from the benchmark into the prompt and let the model itself determine which passages to use to answer the question. Their experiments show that CAG outperformed both RAG systems in most situations.
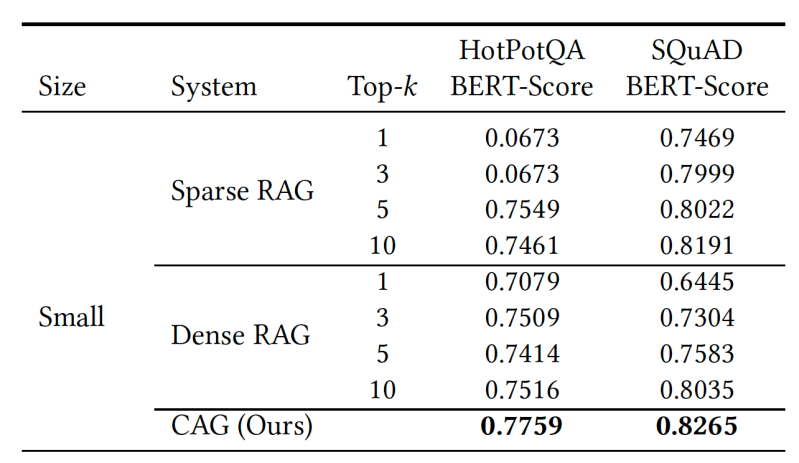
“By preloading the entire context from the test set, our system eliminates retrieval errors and ensures holistic reasoning over all relevant information,” the researchers write. “This advantage is particularly evident in scenarios where RAG systems might retrieve incomplete or irrelevant passages, leading to suboptimal answer generation.”
CAG also significantly reduces the time to generate the answer, particularly as the reference text length increases.
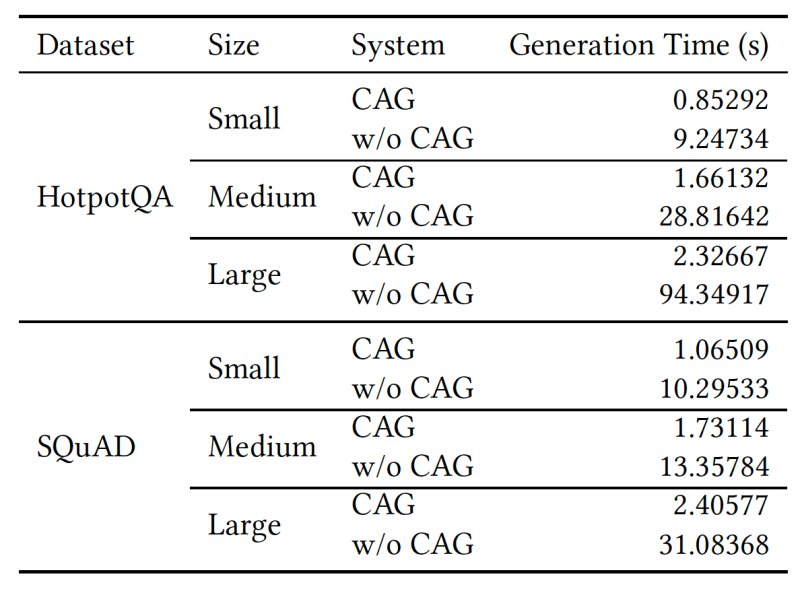
That said, CAG is not a silver bullet and should be used with caution. It is well suited for settings where the knowledge base does not change often and is small enough to fit within the context window of the model. Enterprises should also be careful of cases where their documents contain conflicting facts based on the context of the documents, which might confound the model during inference.
The best way to determine whether CAG is good for your use case is to run a few experiments. Fortunately, the implementation of CAG is very easy and should always be considered as a first step before investing in more development-intensive RAG solutions.