If you’re an Anaconda user, you know that conda environments help you manage package dependencies, avoid compatibility conflicts, and share your projects with others. Unfortunately, they can also take over your computer’s hard drive.
I write lots of computer tutorials and to keep them organized, each has a dedicated folder structure complete with a Conda Environment. This worked great at first, but soon my computer’s performance degraded, and I noticed that my SSD was filling up. At one point I had only 13 GB free.
Conda helps manage this problem by storing downloaded package files in a single “cache” (pkgs_dirs). When you install a package, conda checks for it in the package cache before downloading. If not found, conda will download and extract the package and link the files to the active environment. Because the cache is “shared,” different environments can use the same downloaded files without duplication.
Because conda caches every downloaded package, pkgs_dirs can grow to many gigabytes. And while conda links to shared packages in the cache, there is still a need to store some packages in the environment folder. This is mainly to avoid version conflicts, where different environments need different versions of the same dependency (a package required to run another package).
In addition, large, compiled binaries like OpenCV may require full copies in the environment’s directory, and each environment requires a copy of the Python interpreter (at 100–200 MB). All these issues can bloat conda environments to several gigabytes.
In this Quick Success Data Science project, we’ll look at some techniques for reducing the storage requirements for conda environments, including those stored in default locations and dedicated folders.
Memory Management Techniques
Below are some Memory Management techniques that will help you reduce conda’s storage footprint on your machine. We’ll discuss each in turn.
- Cache cleaning
- Sharing task-based environments
- Archiving with environment and specifications files
- Archiving environments with conda-pack
- Storing environments on an external drive
- Relocating the package cache
- Using virtual environments (
venv)
1. Cleaning the Package Cache
Cleaning the package cache is the first and easiest step for freeing up memory. Even after deleting environments, conda keeps the related package files in the cache. You can free up space by removing these unused packages and their associated tarballs (compressed package files), logs, index caches (metadata stored in conda), and temporary files.
Conda permits an optional “dry run” to see how much memory will be reclaimed. You’ll want to run this from either the terminal or Anaconda Prompt in your base environment:
conda clean --all --dry-runTo commit, run:
conda clean --allHere’s how this looks on my machine:
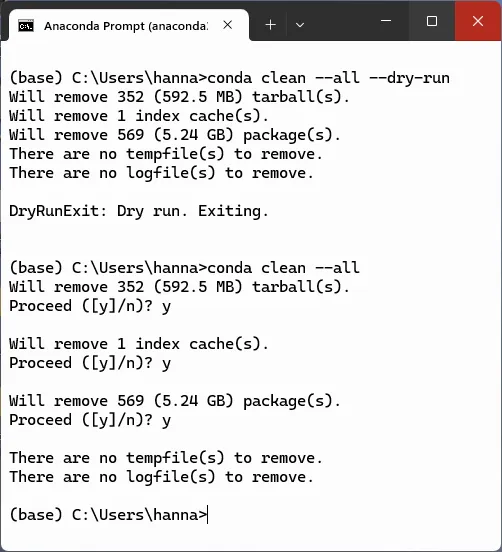
This process trimmed a healthy 6.28 GB and took several minutes to run.
2. Sharing Task-based Environments
Creating a few environments for specialized tasks — like computer vision or geospatial work — is more memory efficient than using dedicated environments for each project. These environments would include basic packages plus ones for the specific task (such as OpenCV, scikit-image, and PIL for computer vision).
An advantage of this approach is that you can easily keep all the packages up to date and link the environments to multiple projects. However, this won’t work if some projects require different versions of the shared packages.
3. Archiving with Environment and Specifications Files
If you don’t have enough storage sites or want to preserve legacy projects efficiently, consider using environment or specifications files. These small files record an environment’s contents, allowing you to rebuild it later.
Saving conda environments in this manner reduces their size on disk from gigabytes to a few kilobytes. Of course, you’ll have to recreate the environment to use it. So, you’ll want to avoid this technique if you frequently revisit projects that link to the archived environments.
NOTE: Consider using Mamba, a drop-in replacement for conda, for faster rebuilds. As the docs say, “If you know conda, you know Mamba!”
Using Environment Files: An environmental file is a small file that lists all the packages and versions installed in an environment, including those installed using Python’s package installer (pip). This helps you both restore an environment and share it with others.
The environment file is written in YAML (.yml), a human-readable data-serialization format for data storage. To generate an environment file, you must activate and then export the environment. Here’s how to make a file for an environment named my_env:
conda activate my_env
conda env export > my_env.ymlYou can name the file any valid filename but be careful as an existing file with the same name will be overwritten.
By default, the environment file is written to the user directory. Here’s a truncated example of the file’s contents:
name: C:Usershannaquick_successfed_hikesfed_env
channels:
- defaults
- conda-forge
dependencies:
- asttokens=2.0.5=pyhd3eb1b0_0
- backcall=0.2.0=pyhd3eb1b0_0
- blas=1.0=mkl
- bottleneck=1.3.4=py310h9128911_0
- brotli=1.0.9=ha925a31_2
- bzip2=1.0.8=he774522_0
- ca-certificates=2022.4.26=haa95532_0
- certifi=2022.5.18.1=py310haa95532_0
- colorama=0.4.4=pyhd3eb1b0_0
- cycler=0.11.0=pyhd3eb1b0_0
- debugpy=1.5.1=py310hd77b12b_0
- decorator=5.1.1=pyhd3eb1b0_0
- entrypoints=0.4=py310haa95532_0
------SNIP------You can now remove your conda environment and reproduce it again with this file. To remove an environment, first deactivate it and then run the remove command (where ENVNAME is the name of your environment):
conda deactivate
conda remove -n ENVNAME --allIf the conda environment exists outside of Anaconda’s default envs folder, then include the directory path to the environment, as so:
conda remove -p PATHENVNAME --allNote that this archiving technique will only work perfectly if you continue to use the same operating system, such as Windows or macOS. This is because solving for dependencies can introduce packages that might not be compatible across platforms.
To restore a conda environment using a file, run the following, where my_env represents your conda environment name and environment.yml represents your environment file:
conda env create -n my_env -f directorypathtoenvironment.ymlYou can also use the environment file to recreate the environment on your D: drive. Just provide the new path when using the file. Here’s an example:
conda create --prefix D:my_envsmy_new_env --file environment.ymlFor more on environment files, including how to manually produce them, visit the docs.
Using Specifications Files: If you haven’t installed any packages using pip, you can use a specifications file to reproduce a conda environment on the same operating system. To create a specification file, activate an environment, such as my_env, and enter the following command:
conda list --explicit > exp_spec_list.txtThis produces the following output, truncated for brevity:
# This file may be used to create an environment using:
# $ conda create --name --file
# platform: win-64
@EXPLICIT
https://conda.anaconda.org/conda-forge/win-64/ca-certificates-202x.xx.x-h5b45459_0.tar.bz2
https://conda.anaconda.org/conda-forge/noarch/tzdata-202xx-he74cb21_0.tar.bz2
------snip------Note that the --explicit flag ensures that the targeted platform is annotated in the file, in this case, # platform: win-64 in the third line.
You can now remove the environment as described in the previous section.
To re-create my_env using this text file, run the following with a proper directory path:
conda create -n my_env -f directorypathtoexp_spec_list.txt4. Archiving Environments with conda-pack
The conda-pack command lets you archive a conda environment before removing it. It packs the entire environment into a compressed archive with the extension: .tar.gz. It’s handy for backing up, sharing, and moving environments without the need to reinstall packages.
The following command will preserve an environment but remove it from your system (where my_env represents the name of your environment):
conda install -c conda-forge conda-pack
conda pack -n my_env -o my_env.tar.gzTo restore the environment later run this command:
mkdir my_env && tar -xzf my_env.tar.gz -C my_envThis technique won’t save as much memory as the text file option. However, you won’t need to re-download packages when restoring an environment, which means it can be used without internet access.
5. Storing Environments on an External Drive
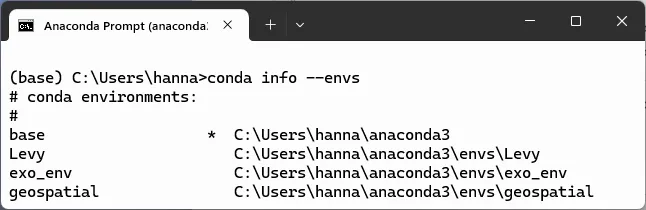
By default, conda stores all environments in a default location. For Windows, this is under the …anaconda3envs folder. You can see these environments by running the command conda info --envs in a prompt window or terminal. Here’s how it looks on my C: drive (this is a truncated view):
Using a Single Environments Folder: If your system supports an external or secondary drive, you can configure conda to store environments there to free up space on your primary disk. Here’s the command; you’ll need to substitute your specific path:
conda config --set envs_dirs /path/to/external/driveIf you enter a path to your D drive, such as D:conda_envs, conda will create new environments at this location.
This technique works well when your external drive is a fast SSD and when you’re storing packages with large dependencies, like TensorFlow. The downside is slower performance. If your OS and notebooks remain on the primary drive, you may experience some read/write latency when running Python.
In addition, some OS settings may power down idle external drives, adding a delay when they spin back up. Tools like Jupyter may struggle to locate conda environments if the drive letter changes, so you’ll want to use a fixed drive letter and ensure that the correct kernel paths are set.
Using Multiple Environment Folders: Instead of using a single envs_dirs directory for all environments, you can store each environment inside its respective project folder. This lets you store everything related to a project in one place.
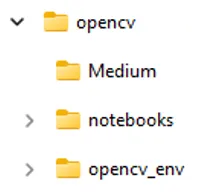
For example, suppose you have a project on your Windows D: drive in a folder called D:projectsgeospatial. To place the project’s conda environment in this folder, loaded with ipykernel for JupyterLab, you would run:
conda create -p D:projectsgeospatialenv ipykernelOf course, you can call env something more descriptive, like geospatial_env.
As with the previous example, environments stored on a different disk can cause performance issues.
Special Note on JupyterLab: Depending on how you launch JupyterLab, its default behavior may be to open in your user directory (such as, C:Usersyour_user_name). Since its file browser is restricted to the directory from which it is launched, you won’t see directories on other drives like D:. There are many ways to handle this, but one of the simplest is to launch JupyterLab from the D: drive.
For example, in Anaconda Prompt, type:
D:followed by:
jupyter labNow, you will be able to pick from kernels on the D: drive.
For more options on changing JupyterLab’s working directory, ask an AI about “how to change Jupyter’s default working directory” or “how to create a Symlink to D: in your user folder.”
Moving Existing Environments: You should never manually move a conda environment, such as by cutting and pasting to a new location. This is because conda relies on internal paths and metadata that can become invalid with location changes.
Instead, you should clone existing environments to another drive. This will duplicate the environment, so you’ll need to manually remove it from its original location.
In the following example, we use the --clone flag to produce an exact copy of a C: drive environment (called my_env) on the D: drive:
conda create -p D:new_envsmy_env --clone C:pathtooldenvNOTE: Consider exporting your environment to a YAML file (as described in Section 3 above) before cloning. This allows you to recreate the environment if something goes wrong with the clone procedure.
Now, when you run conda env list, you’ll see the environment listed in both the C: and D: drives. You can remove the old environment by running the following command in the base environment:
conda remove --name my_env --all -yAgain, latency issues may affect these setups if you’re working across two disks.
You may be wondering, is it better to move a conda environment using an environment (YAML) file or to use--clone? The short answer is that --clone is the best and fastest option for moving an environment to a different drive on the same machine. An environment file is best for recreating the same environment on a different machine. While the file guarantees a consistent environment across different systems, it can take much longer to run, especially with large environments.
6. Relocating the Package Cache
If your primary drive is low on space, you can move the package cache to a larger external or secondary drive using this command:
conda config --set pkgs_dirs D:conda_pkgsIn this example, packages are now stored on the D drive (D:conda_pkgs) instead of the default location.
If you’re working in your primary drive and both drives are SSD, then latency issues should not be significant. However, if one of the drives is a slower HDD, you can experience slowdowns when creating or updating environments. If D: is an external drive connected by USB, you may see significant slowdowns for large environments.
You can mitigate some of these issues by keeping the package cache (pkgs_dirs) and frequently used environments on the faster SSD, and other environments on the slower HDD.
One last thing to consider is backups. Primary drives may have routine backups scheduled but secondary or external drives may not. This puts you at risk of losing all your environments.
7. Using Virtual Environments
If your project doesn’t require conda’s extensive package management system for handling heavy dependencies (like TensorFlow or GDAL), you can significantly reduce disk usage with a Python virtual environment (venv). This represents a lightweight alternative to a conda environment.
To create a venv named my_env, run the following command:

This type of environment has a small base installation. A minimal conda environment takes up about 200 MB and includes multiple utilities, such as conda, pip, setuptools, and so on. A venv is much lighter, with a minimum install size of only 5–10 MB.
Conda also caches package tarballs in pkgs_dirs. These tarballs can grow to several GBs over time. Because venv installs packages directly into the environment, no extra copies are preserved.
In general, you’ll want to consider venv when you only need basic Python packages like NumPy, pandas, or Scikit-learn. Packages for which conda is strongly recommended, like Geopandas, should still be placed in a conda environment. If you use lots of environments, you’ll probably want to stick with conda and benefit from its package linking.
You can find details on how to activate and use Python virtual environments in the venv docs.
Recap
High impact/low disruption memory management techniques for conda environments include cleaning the package cache and storing little-used environments as YAML or text files. These methods can save many gigabytes of memory while retaining Anaconda’s default directory structure.
Other high impact methods include moving the package cache and/or conda environments to a secondary or external drive. This will resolve memory problems but may introduce latency issues, especially if the new drive is a slow HDD or uses a USB connection.
For simple environments, you can use a Python virtual environment (venv) as a lightweight alternative to conda.