Introduction: Can AI really distinguish dog breeds like human experts?
One day while taking a walk, I saw a fluffy white puppy and wondered, Is that a Bichon Frise or a Maltese? No matter how closely I looked, they seemed almost identical. Huskies and Alaskan Malamutes, Shiba Inus and Akitas, I always found myself second-guessing. How do professional veterinarians and researchers spot the differences at a glance? What are they focusing on? 
This question kept coming back to me while developing PawMatchAI. One day, while struggling to improve my model’s accuracy, I realized that when I recognize objects, I don’t process all details at once. Instead, I first notice the overall shape, then refine my focus on specific features. Could this “coarse-to-fine” processing be the key to how experts identify similar dog breeds so accurately?
Digging into research, I came across a cognitive science paper confirming that human visual recognition relies on multi-level feature analysis. Experts don’t just memorize images, they analyze structured traits such as:
- Overall body proportions (large vs. small dogs, square vs. elongated body shapes)
- Head features (ear shape, muzzle length, eye spacing)
- Fur texture and distribution (soft vs. curly vs. smooth, double vs. single coat)
- Color and pattern (specific markings, pigment distribution)
- Behavioral and postural features (tail posture, walking style)
This made me rethink traditional CNNs (Convolutional Neural Networks). While they are incredibly powerful at learning local features, they don’t explicitly separate key characteristics the way human experts do. Instead, these features are entangled within millions of parameters without clear interpretability.
So I designed the Morphological Feature Extractor, an approach that helps AI analyze breeds in structured layers—just like how experts do. This architecture specifically focuses on body proportions, head shape, fur texture, tail structure, and color patterns, making AI not just see objects, but understand them.
PawMatchAI is my personal project that can identify 124 dog breeds and provide breed comparisons and recommendations based on user preferences. If you’re interested, you can try it on HuggingFace Space or check out the complete code on GitHub:
 HuggingFace: PawMatchAI
HuggingFace: PawMatchAI
GitHub: PawMatchAI
In this article, I’ll dive deeper into this biologically-inspired design and share how I turned simple everyday observations into a practical AI solution.
1. Human vision vs. machine vision: Two fundamentally different ways of perceiving the world
At first, I thought humans and AI recognized objects in a similar way. But after testing my model and looking into cognitive science, I realized something surprising, humans and AI actually process visual information in fundamentally different ways. This completely changed how I approached AI-based recognition.
 Human vision: Structured and adaptive
Human vision: Structured and adaptive
The human visual system follows a highly structured yet flexible approach when recognizing objects:
 Seeing the big picture first → Our brain first scans the overall shape and size of an object. This is why, just by looking at a dog’s silhouette, we can quickly tell whether it’s a large or small breed. Personally, this is always my first instinct when spotting a dog.
Seeing the big picture first → Our brain first scans the overall shape and size of an object. This is why, just by looking at a dog’s silhouette, we can quickly tell whether it’s a large or small breed. Personally, this is always my first instinct when spotting a dog.
 Focusing on key features → Next, our attention automatically shifts to the features that best differentiate one breed from another. While researching, I found that professional veterinarians often emphasize ear shape and muzzle length as primary indicators for breed identification. This made me realize how experts make quick decisions.
Focusing on key features → Next, our attention automatically shifts to the features that best differentiate one breed from another. While researching, I found that professional veterinarians often emphasize ear shape and muzzle length as primary indicators for breed identification. This made me realize how experts make quick decisions.
 Learning through experience → The more dogs we see, the more we refine our recognition process. Someone seeing a Samoyed for the first time might focus on its fluffy white fur, while an experienced dog enthusiast would immediately recognize its distinctive “Samoyed smile”, a unique upturned mouth shape.
Learning through experience → The more dogs we see, the more we refine our recognition process. Someone seeing a Samoyed for the first time might focus on its fluffy white fur, while an experienced dog enthusiast would immediately recognize its distinctive “Samoyed smile”, a unique upturned mouth shape.
 How CNNs “see” the world
How CNNs “see” the world
Convolutional Neural Networks (CNNs) follow a completely different recognition strategy:
- A complex system that’s hard to interpret → CNNs do learn patterns from simple edges and textures to high-level features, but all of this happens inside millions of parameters, making it hard to understand what the model is really focusing on.
- When AI confuses the background for the dog → One of the most frustrating problems I ran into was that my model kept misidentifying breeds based on their surroundings. For example, if a dog was in a snowy setting, it almost always guessed Siberian Husky, even if the breed was completely different.
2. Morphological Feature Extractor: Inspiration from cognitive science
2.1 Core design philosophy
Throughout the development of PawMatchAI, I’ve been trying to make the model identify similar-looking dog breeds as accurately as human experts can. However, my early attempts didn’t go as planned. At first, I thought training deeper CNNs with more parameters would improve performance. But no matter how powerful the model became, it still struggled with similar breeds, mistaking Bichon Frises for Maltese, or Huskies for Eskimo Dog. That made me wonder: Can AI really understand these subtle differences just by getting bigger and deeper?
Then I thought back to something I had noticed before, when humans recognize objects, we don’t process everything at once. We start by looking at the overall shape, then gradually zoom in on the details. This got me thinking, what if CNNs could mimic human object recognition habits by starting with overall morphology and then focusing on detailed features? Would this improve recognition capabilities?
Based on this idea, I decided to stop simply making CNNs deeper and instead design a more structured model architecture, ultimately establishing three core design principles:
- Explicit morphological features: This made me reflect on my own question: What exactly are professionals looking at? It turns out that veterinarians and breed experts don’t just rely on instinct, they follow a clear set of criteria, focusing on specific traits. So instead of letting the model “guess” which parts matter, I designed it to learn directly from these expert-defined features, making its decision-making process closer to human cognition.
- Multi-scale parallel processing: This corresponds to my cognitive insight: humans don’t process visual information linearly but attend to features at different levels simultaneously. When we see a dog, we don’t need to complete our analysis of the overall outline before observing local details; rather, these processes happen concurrently. Therefore, I designed multiple parallel feature analyzers, each focusing on features at different scales, working together rather than sequentially.
- Why relationships between features matter more than individual traits: I came to realize that looking at individual features alone often isn’t enough to determine a breed. The recognition process isn’t just about identifying separate traits, it’s about how they interact. For example, a dog with short hair and pointed ears could be a Doberman, if it has a slender body. But if that same combination appears on a stocky, compact frame, it’s more likely a Boston Terrier. Clearly, the way features relate to one another is often the key to distinguishing breeds.
2.2 Technical implementation of the five morphological feature analyzers
Each analyzer uses different convolution kernel sizes and layers to address various features:
Body proportion analyzer
# Using large convolution kernels (7x7) to capture overall body features
'body_proportion': nn.Sequential(
nn.Conv2d(64, 128, kernel_size=7, padding=3),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU()
)Initially, I tried even larger kernels but found they focused too much on the background. I eventually used (7×7) kernels to capture overall morphological features, just like how canine experts first notice whether a dog is large, medium, or small, and whether its body shape is square or rectangular. For example, when identifying similar small white breeds (like Bichon Frise vs. Maltese), body proportions are often the initial distinguishing point.
Head feature analyzer
# Medium-sized kernels (5x5) are suitable for analyzing head structure
'head_features': nn.Sequential(
nn.Conv2d(64, 128, kernel_size=5, padding=2),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU()
)The head feature analyzer was the part I tested most extensively. The technical challenge was that the head contains multiple key identification points (ears, muzzle, eyes), but their relative positions are crucial for overall recognition. The final design using 5×5 convolution kernels allows the model to learn the relative positioning of these features while maintaining computational efficiency.
Tail feature analyzer
'tail_features': nn.Sequential(
nn.Conv2d(64, 128, kernel_size=5, padding=2),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU()
)Tails typically occupy only a small portion of an image and come in many forms. Tail shape is a key identifying feature for certain breeds, such as the curled upward tail of Huskies and the back-curled tail of Samoyeds. The final solution uses a structure similar to the head analyzer but incorporates more data augmentation during training (like random cropping and rotation).
 Fur feature analyzer
Fur feature analyzer
# Small kernels (3x3) are better for capturing fur texture
'fur_features': nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU()
)Fur texture and length are critical features for distinguishing visually similar breeds. When judging fur length, a larger receptive field is needed. Through experimentation, I found that stacking two 3×3 convolutional layers improved recognition accuracy.
 Color pattern analyzer
Color pattern analyzer
# Color feature analyzer: analyzing color distribution
'color_pattern': nn.Sequential(
# First layer: capturing basic color distribution
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
# Second layer: analyzing color patterns and markings
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
# Third layer: integrating color information
nn.Conv2d(128, 128, kernel_size=1),
nn.BatchNorm2d(128),
nn.ReLU()
)The color pattern analyzer has a more complex design than other analyzers because of the difficulty in distinguishing between colors themselves and their distribution patterns. For example, German Shepherds and Rottweilers both have black and tan fur, but their distribution patterns differ. The three-layer design allows the model to first capture basic colors, then analyze distribution patterns, and finally integrate this information through 1×1 convolutions.
2.3 Feature interaction and integration mechanism: The key breakthrough
Having different analyzers for each feature is important, but making them interact with each other is the most crucial part:
# Feature attention mechanism: dynamically adjusting the importance of different features
self.feature_attention = nn.MultiheadAttention(
embed_dim=128,
num_heads=8,
dropout=0.1,
batch_first=True
)
# Feature relationship analyzer: analyzing connections between different morphological features
self.relation_analyzer = nn.Sequential(
nn.Linear(128 * 5, 256), # Combination of five morphological features
nn.LayerNorm(256),
nn.ReLU(),
nn.Linear(256, 128),
nn.LayerNorm(128),
nn.ReLU()
)
# Feature integrator: intelligently combining all features
self.feature_integrator = nn.Sequential(
nn.Linear(128 * 6, in_features), # Five original features + one relationship feature
nn.LayerNorm(in_features),
nn.ReLU()
)The multi-head attention mechanism is vital for identifying the most representative features of each breed. For example, short-haired breeds rely more on body type and head features for identification, while long-haired breeds depend more on fur texture and color.
2.4 Feature Relationship Analyzer: Why feature relationships are so important
After weeks of frustration, I finally realized my model was missing a crucial element – when we humans identify something, we don’t just recall individual details. Our brains connect the dots, linking features to form a complete image. The relationships between features are just as important as the features themselves. A small dog with pointed ears and fluffy fur is likely a Pomeranian, but the same features on a large dog might indicate a Samoyed.
So I built the Feature Relationship Analyzer to embody this concept. Instead of processing each feature separately, I connected all five morphological features before passing them to the connecting layer. This lets the model learn relationships between features, helping it distinguish breeds that look almost identical at first glance, especially in four key aspects:
- Body and head coordination → Shepherd breeds typically have wolf-like heads paired with slender bodies, while bulldog breeds have broad heads with muscular, stocky builds. The model learns these associations rather than processing head and body shapes separately.
- Fur and color joint distribution → Certain breeds have specific fur types often accompanied by unique colors. For example, Border Collies tend to have black and white bicolor fur, while Golden Retrievers typically have long golden fur. Recognizing these co-occurring features improves accuracy.
- Head and tail paired features → Pointed ears and curled tails are common in northern sled dog breeds (like Samoyeds and Huskies), while drooping ears and straight tails are more typical of hound and spaniel breeds.
- Body, fur, and color three-dimensional feature space → Some combinations are strong indicators of specific breeds. Large build, short hair, and black-and-tan coloration almost always point to a German Shepherd.
By focusing on how features interact rather than processing them separately, the Feature Relationship Analyzer bridges the gap between human intuition and AI-based recognition.
2.5 Residual connection: Keeping original information intact
At the end of the forward propagation function, there’s a key residual connection:
# Final integration with residual connection
integrated_features = self.feature_integrator(final_features)
return integrated_features + x # Residual connectionThis residual connection (+ x) serves a few important roles:
- Preserving important details → Ensures that while focusing on morphological features, the model still retains key information from the original representation.
- Helping deep models train better → In large architectures like ConvNeXtV2, residuals prevent gradients from vanishing, keeping learning stable.
- Providing flexibility → If the original features are already useful, the model can “skip” certain transformations instead of forcing unnecessary changes.
- Mimicking how the brain processes images → Just like our brains analyze objects and their locations at the same time, the model learns different perspectives in parallel.
In the model design, a similar concept was adopted, allowing different feature analyzers to operate simultaneously, each focusing on different morphological features (like body type, fur, ear shape, etc.). Through residual connections, these different information channels can complement each other, ensuring the model doesn’t miss critical information and thereby improving recognition accuracy.
2.6 Overall workflow
The complete feature processing flow is as follows:
- Five morphological feature analyzers simultaneously process spatial features, each using different-sized convolution layers and focusing on different features
- The feature attention mechanism dynamically adjusts focus on different features
- The feature relationship analyzer captures correlations between features, truly understanding breed characteristics
- The feature integrator combines all information (five original features + one relationship feature)
- Residual connections ensure no original information is lost
3. Architecture flow diagram: How the morphological feature extractor works
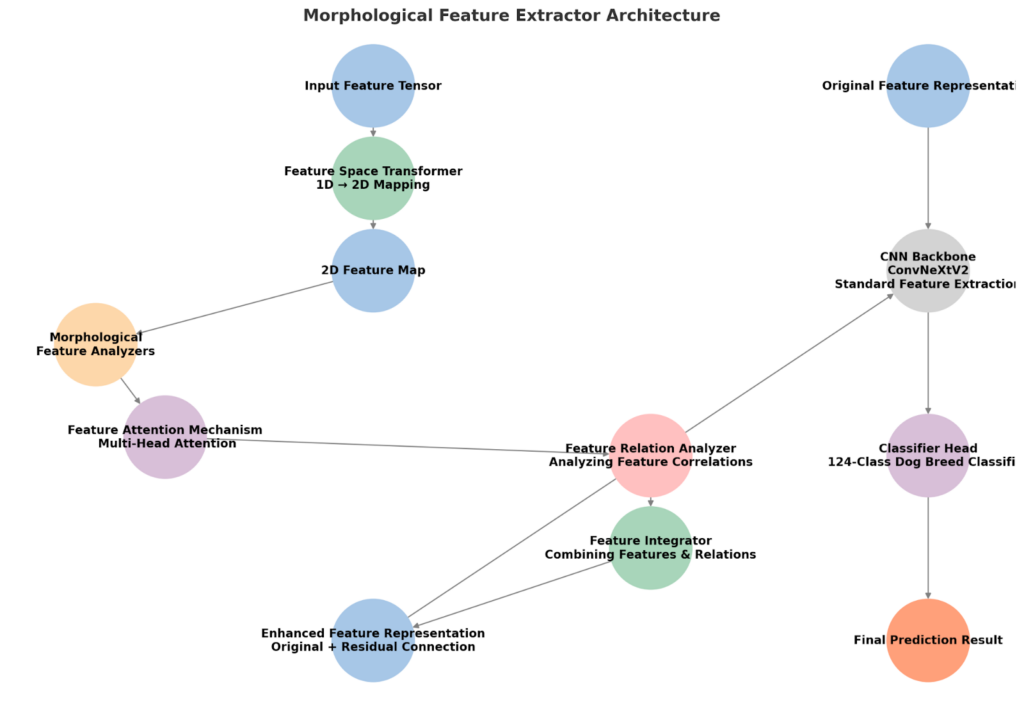
Looking at the diagram, we can see a clear distinction between two processing paths: on the left, a specialized morphological feature extraction process, and on the right, the traditional CNN-based recognition path.
Left path: Morphological feature processing
- Input feature tensor: This is the model’s input, featuring information from the CNN’s middle layers, similar to how humans first get a rough outline when viewing an image.
- The Feature Space Transformer reshapes compressed 1D features into a structured 2D representation, improving the model’s ability to capture spatial relationships. For example, when analyzing a dog’s ears, their features might be scattered in a 1D vector, making it harder for the model to recognize their connection. By mapping them into 2D space, this transformation brings related traits closer together, allowing the model to process them simultaneously, just as humans naturally do.
- 2D feature map: This is the transformed two-dimensional representation which, as mentioned above, now has more spatial structure and can be used for morphological analysis.
- At the heart of this system are five specialized Morphological Feature Analyzers, each designed to focus on a key aspect of dog breed identification:
- Body Proportion Analyzer: Uses large convolution kernels (7×7) to capture overall shape and proportion relationships, which is the first step in preliminary classification
- Head Feature Analyzer: Uses medium-sized convolution kernels (5×5) combined with smaller ones (3×3), focusing on head shape, ear position, muzzle length, and other key features
- Tail Feature Analyzer: Similarly uses a combination of 5×5 and 3×3 convolution kernels to analyze tail shape, curl degree, and posture, which are often decisive features for distinguishing similar breeds
- Fur Feature Analyzer: Uses consecutive small convolution kernels (3×3), specifically designed to capture fur texture, length, and density – these subtle features
- Color Pattern Analyzer: Employs a multi-layered convolution architecture, including 1×1 convolutions for color integration, specifically analyzing color distribution patterns and specific markings
- Similar to how our eyes instinctively focus on the most distinguishing features when recognizing faces, the Feature Attention Mechanism dynamically adjusts its focus on key morphological traits, ensuring the model prioritizes the most relevant details for each breed.
Right path: Standard CNN processing
- Original feature representation: The initial feature representation of the image.
- CNN backbone (ConvNeXtV2): Uses ConvNeXtV2 as the backbone network, extracting features through standard deep learning methods.
- Classifier head: Transforms features into classification probabilities for 124 dog breeds.
Integration path
- The Feature Relation Analyzer goes beyond isolated traits, it examines how different features interact, capturing relationships that define a breed’s unique appearance. For example, combinations like “head shape + tail posture + fur texture” might point to specific breeds.
- Feature integrator: Integrates morphological features and their relationship information to form a more comprehensive representation.
- Enhanced feature representation: The final feature representation, combining original features (through residual connections) and features obtained from morphological analysis.
- Finally, the model delivers its prediction, determining the breed based on a combination of original CNN features and morphological analysis.
4. Performance observations of the morphological feature extractor
After analyzing the entire model architecture, the most important question was: Does it actually work? To verify the effectiveness of the Morphological Feature Extractor, I tested 30 photos of dog breeds that models typically confuse. A comparison between models shows a significant improvement: the baseline model correctly classified 23 out of 30 images (76.7%), while the addition of the Morphological Feature Extractor increased accuracy to 90% (27 out of 30 images).
This improvement is not just reflected in numbers but also in how the model differentiates breeds. The heat maps below show which image regions the model focuses on before and after integrating the feature extractor.
4.1 Recognizing a Dachshund’s unique body proportions
Let’s start with a misclassification case. The heatmap below shows that without the Morphological Feature Extractor, the model incorrectly classified a Dachshund as a Golden Retriever.
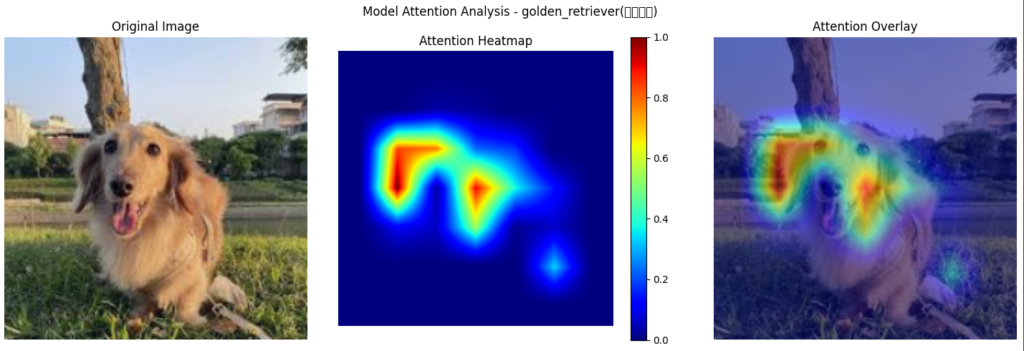
- Without morphological features, the model relied too much on color and fur texture, rather than recognizing the dog’s overall structure. The heat map reveals that the model’s attention was scattered, not just on the dog’s face, but also on background elements like the roof, which likely influenced the misclassification.
- Since long-haired Dachshunds and Golden Retrievers share a similar coat color, the model was misled, focusing more on superficial similarities rather than distinguishing key features like body proportions and ear shape.
This shows a common issue with deep learning models, without proper guidance, they can focus on the wrong things and make mistakes. Here, the background distractions kept the model from noticing the Dachshund’s long body and short legs, which set it apart from a Golden Retriever.
However, after integrating the Morphological Feature Extractor, the model’s attention shifted significantly, as seen in the heatmap below:
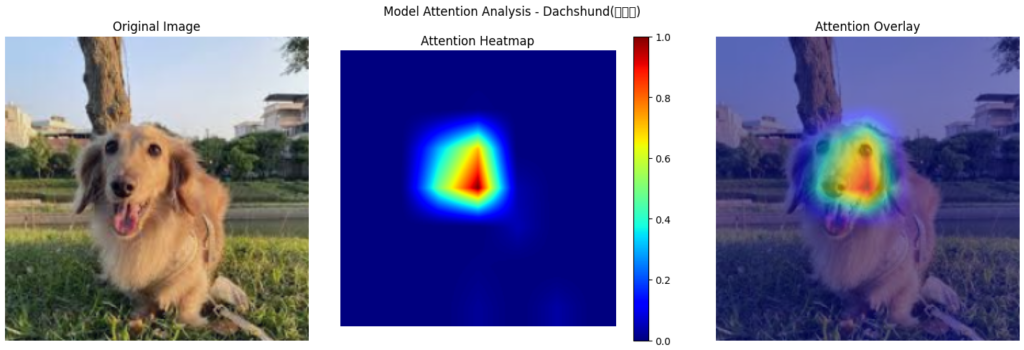
Key observations from the Dachshund’s attention heatmap:
- Background distractions were significantly reduced. The model learned to ignore environmental elements like grass and trees, focusing more on the dog’s structural features.
- The model’s focus has shifted to the Dachshund’s facial features, particularly the eyes, nose, and mouth, key traits for breed recognition. Compared to before, attention is no longer scattered, resulting in a more stable and confident classification.
This confirms that the Morphological Feature Extractor helps the model filter out irrelevant background noise and focus on the defining facial traits of each breed, making its predictions more reliable.
4.2 Distinguishing Siberian Huskies from other northern breeds
For sled dogs, the impact of the Morphological Feature Extractor was even more pronounced. Below is a heatmap before the extractor was applied, where the model misclassified a Siberian Husky as an Eskimo Dog.
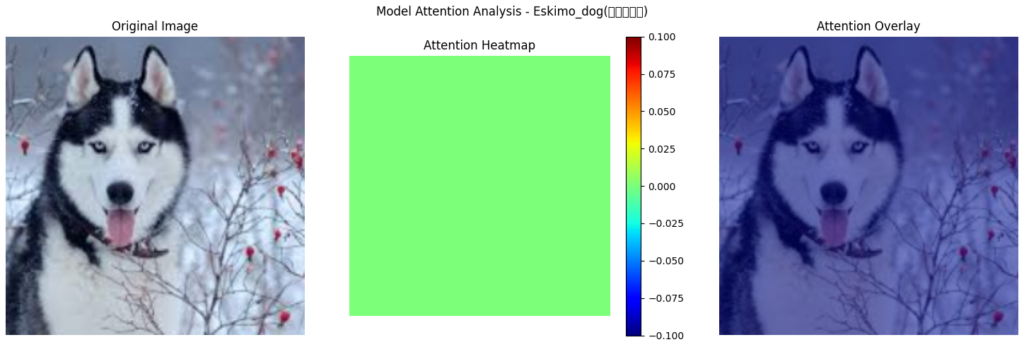
As seen in the heatmap, the model failed to focus on any distinguishing features, instead displaying a diffused, unfocused attention distribution. This suggests the model was uncertain about the defining traits of a Husky, leading to misclassification.
However, after incorporating the Morphological Feature Extractor, a critical transformation occurred:
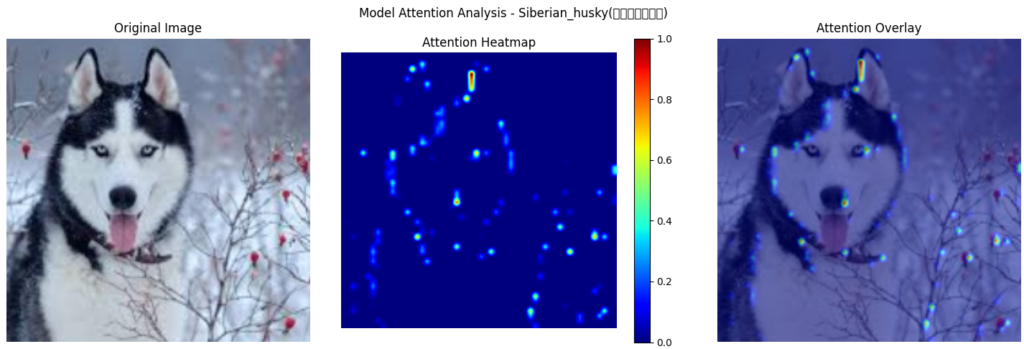
Distinguishing Siberian Huskies from other northern breeds (like Alaskan Malamutes) is another case that impressed me. As you can see in the heatmap, the model’s attention is highly concentrated on the Husky’s facial features.
What’s interesting is the yellow highlighted area around the eyes. The Husky’s iconic blue eyes and distinctive “mask” pattern are key features that distinguish it from other sled dogs. The model also notices the Husky’s distinctive ear shape, which is smaller and closer to the head than an Alaskan Malamute’s, forming a distinct triangular shape.
Most surprising to me was that despite the snow and red berries in the background (elements that might interfere with the baseline model), the improved model pays minimal attention to these distractions, focusing on the breed itself.
4.3 Summary of heatmap analysis
Through these heatmaps, we can clearly see how the Morphological Feature Extractor has changed the model’s “thinking process,” making it more similar to expert recognition abilities:
- Morphology takes priority over color: The model is no longer swayed by surface features (like fur color) but has learned to prioritize body type, head shape, and other features that experts use to distinguish similar breeds.
- Dynamic allocation of attention: The model demonstrates flexibility in feature prioritization: emphasizing body proportions for Dachshunds and facial markings for Huskies, similar to expert recognition processes.
- Enhanced interference resistance: The model has learned to ignore backgrounds and non-characteristic parts, maintaining focus on key morphological features even in noisy environments.
5. Potential applications and future improvements
Through this project, I believe the concept of Morphological Feature Extractors won’t be limited to dog breed identification. This concept could be applicable to other domains that rely on recognizing fine-grained differences. However, defining what constitutes a ‘morphological feature’ varies by field, making direct transferability a challenge.
5.1 Applications in fine-grained visual classification
Inspired by biological classification principles, this approach is particularly useful for distinguishing objects with subtle differences. Some practical applications include:
- Medical diagnosis: Tumor classification, dermatological analysis, and radiology (X-ray/CT scans), where doctors rely on shape, texture, and boundary features to differentiate conditions.
- Plant and insect identification: Certain poisonous mushrooms closely resemble edible ones, requiring expert knowledge to differentiate based on morphology.
- Industrial quality control: Detecting microscopic defects in manufactured products, such as shape errors in electronic components or surface scratches on metals.
- Art and artifact authentication: Museums and auction houses often rely on texture patterns, carving details, and material analysis to distinguish genuine artifacts from forgeries, an area where AI can assist.
This methodology could also be applied to surveillance and forensic analysis, such as recognizing individuals through gait analysis, clothing details, or vehicle identification in criminal investigations.
5.2 Challenges and future improvements
While the Morphological Feature Extractor has demonstrated its effectiveness, there are several challenges and areas for improvement:
- Feature selection flexibility: The current system relies on predefined feature sets. Future enhancements could incorporate adaptive feature selection, dynamically adjusting key features based on object type (e.g., ear shape for dogs, wing structure for birds).
- Computational efficiency: Although initially expected to scale well, real-world deployment revealed increased computational complexity, posing limitations for mobile or embedded devices.
- Integration with advanced architectures: Combining morphological analysis with models like Transformers or Self-Supervised Learning could enhance performance but introduces challenges in feature representation consistency.
- Cross-domain adaptability: While effective for dog breed classification, applying this approach to new fields (e.g., medical imaging or plant identification) requires redefinition of morphological features.
- Explainability and few-shot learning potential: The intuitive nature of morphological features may facilitate low-data learning scenarios. However, overcoming deep learning’s dependency on large labeled datasets remains a key challenge.
These challenges indicate areas where the approach can be refined, rather than fundamental flaws in its design.
Conclusion
This development process made me realize that the Morphological Feature Extractor isn’t just another machine learning technique, it’s a step toward making AI think more like humans. Instead of passively memorizing patterns, this approach helps AI focus on key features, much like experts do.
Beyond Computer Vision, this idea could influence AI’s ability to reason, make decisions, and interpret information more effectively. As AI evolves, we are not just improving models but shaping systems that learn in a more human-like way.
Thank you for reading. Through developing PawMatchAI, I’ve gained valuable experience regarding AI visual systems and feature recognition, giving me new perspectives on AI development. If you have any viewpoints or topics you’d like to discuss, I welcome the exchange. 
References & data sources
Dataset Sources
- Stanford Dogs Dataset – Kaggle Dataset
- Originally sourced from Stanford Vision Lab – ImageNet Dogs
- Citation:
- Aditya Khosla, Nityananda Jayadevaprakash, Bangpeng Yao, and Li Fei-Fei. Novel dataset for Fine-Grained Image Categorization. FGVC Workshop, CVPR, 2011.
- Unsplash Images – Additional images of four breeds (Bichon Frise, Dachshund, Shiba Inu, Havanese) were sourced from Unsplash for dataset augmentation.
Research references
Image attribution
- All images, unless otherwise noted, are created by the author.
Disclaimer
The methods and approaches described in this article are based on my personal research and experimental findings. While the Morphological Feature Extractor has demonstrated improvements in specific scenarios, its performance may vary depending on datasets, implementation details, and training conditions.
This article is intended for educational and informational purposes only. Readers should conduct independent evaluations and adapt the approach based on their specific use cases. No guarantees are made regarding its effectiveness across all applications.