On March 3rd, Google officially rolled out its Data Science Agent to most Colab users for free. This is not something brand new — it was first announced in December last year, but it is now integrated into Colab and made widely accessible.
Google says it is “The future of data analysis with Gemini”, stating: “Simply describe your analysis goals in plain language, and watch your notebook take shape automatically, helping accelerate your ability to conduct research and data analysis.” But is it a real game-changer in Data Science? What can it actually do, and what can’t it do? Is it ready to replace data analysts and data scientists? And what does it tell us about the future of data science careers?
In this article, I will explore these questions with real-world examples.
What It Can Do
The Data Science Agent is straightforward to use:
- Open a new notebook in Google Colab — you just need a Google Account and can use Google Colab for free;
- Click “Analyze files with Gemini” — this will open the Gemini chat window on the right;
- Upload your data file and describe your goal in the chat. The agent will generate a series of tasks accordingly;
- Click “Execute Plan”, and Gemini will start to write the Jupyter Notebook automatically.
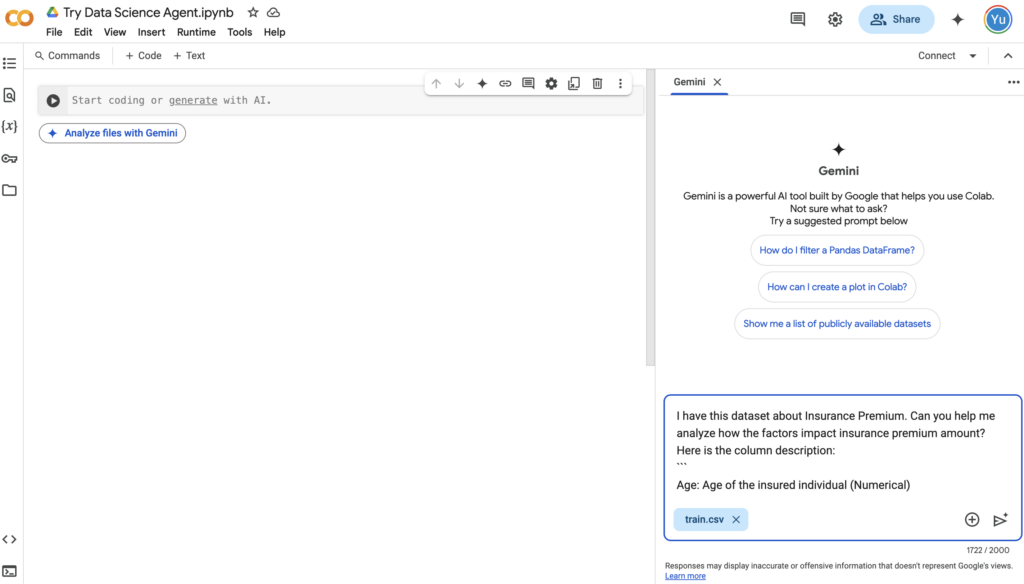
Data Science Agent UI (image by author)
Let’s look at a real example. Here, I used the dataset from the Regression with an Insurance Dataset Kaggle Playground Prediction Competition (Apache 2.0 license). This dataset has 20 features, and the goal is to predict the insurance premium amount. It has both continuous and categorical variables with scenarios like missing values and outliers. Therefore, it is a good example dataset for Machine Learning practices.
Jupyter Notebook generated by the Data Science Agent (image by author)
After running my experiment, here are the highlights I’ve observed from the Data Science Agent’s performance:
- Customizable execution plan: Based on my prompt of “Can you help me analyze how the factors impact insurance premium amount? “, the Data Science Agent first came up with a series of 10 tasks, including data loading, data exploration, data cleaning, data wrangling, feature engineering, data splitting, model training, model optimization, model evaluation, and data visualization. This is a pretty standard and reasonable process of conducting exploratory data analysis and building a machine learning model. It then asked for my confirmation and feedback before executing the plan. I tried to ask it to focus on Exploratory Data Analysis first, and it was able to adjust the execution plan accordingly. This provides flexibility to customize the plan based on your needs.

Initial tasks the agent generated (image by author)
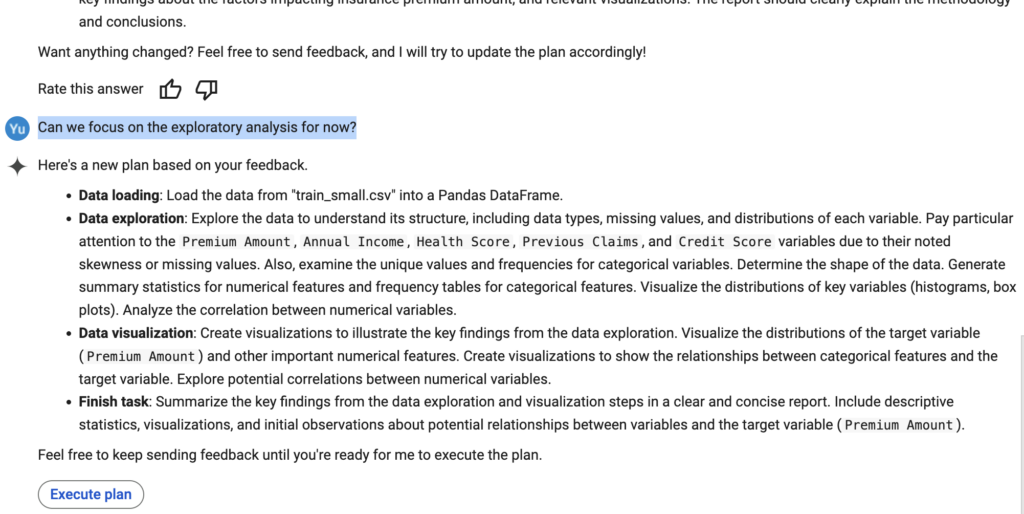
Plan adjustment based on feedback (image by author)
- End-to-end execution and autocorrection: After confirming the plan, the Data Science Agent was able to execute the plan end-to-end autonomously. Whenever it encountered errors while running Python code, it diagnosed what was wrong and attempted to correct the error by itself. For example, at the model training step, it first ran into a
DTypePromotionErrorerror because of including a datetime column in training. It decided to drop the column in the next try but then got the error messageValueError: Input X contains NaN. In its third attempt, it added a simpleImputer to impute all missing values with the mean of each column and eventually got the step to work.
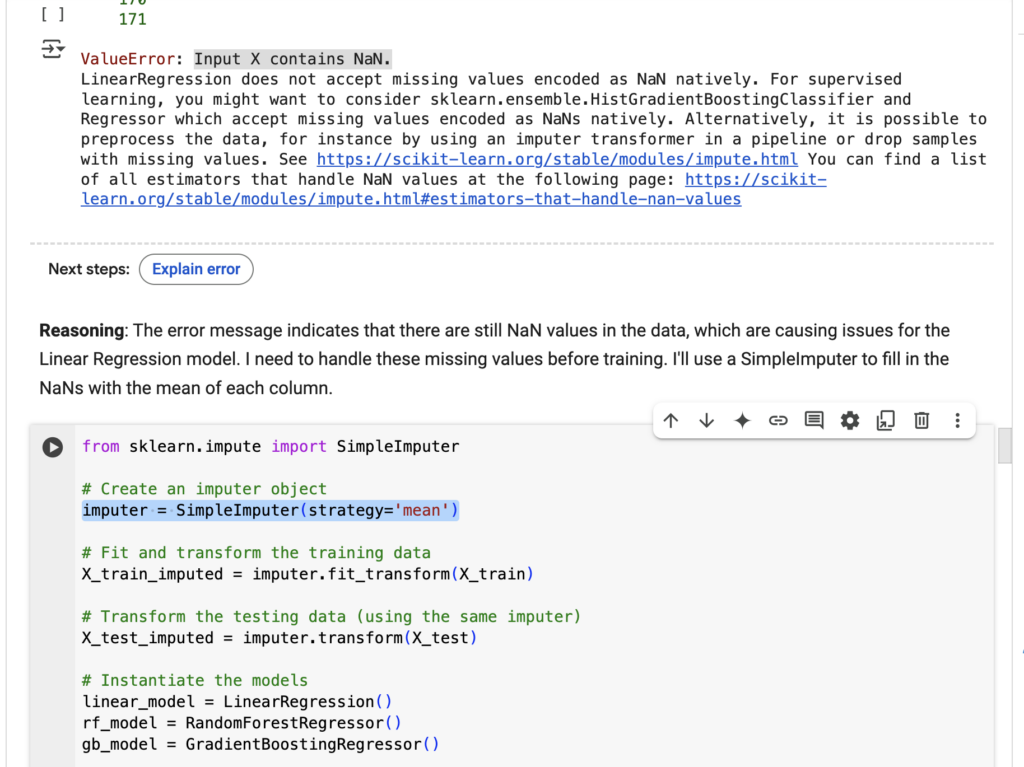
The agent ran into an error and auto-corrected it (image by author)
- Interactive and iterative notebook: Since the Data Science Agent is built into Google Colab, it populates a Jupyter Notebook as it executes. This comes with several advantages:
- Real-time visibility: Firstly, you can actually watch the Python code running in real time, including the error messages and warnings. The dataset I provided was a bit large — even though I only kept the first 50k rows of the dataset for the sake of a quick test — and it took about 20 minutes to finish the model optimization step in the Jupyter notebook. The notebook kept running without timeout and I received a notification once it finished.
- Editable code: Secondly, you can edit the code on top of what the agent has built for you. This is something clearly better than the official Data Analyst GPT in ChatGPT, which also runs the code and shows the result, but you have to copy and paste the code elsewhere to make manual iterations.
- Seamless collaboration: Lastly, having a Jupyter Notebook makes it very easy to share your work with others — now you can collaborate with both AI and your teammates in the same environment. The agent also drafted step-by-step explanations and key findings, making it much more presentation-friendly.

Summary section generated by the Agent (image by author)
What It Cannot Do
We’ve talked about its advantages; now, let’s discuss some missing pieces I’ve noticed for the Data Science Agent to be a real autonomous data scientist.
- It does not modify the Notebook based on follow-up prompts. I mentioned that the Jupyter Notebook environment makes it easy to iterate. In this example, after its initial execution, I noticed the Feature Importance charts did not have the feature labels. Therefore, I asked the Agent to add the labels. I assumed it would update the Python code directly or at least add a new cell with the refined code. However, it merely provided me with the revised code in the chat window, leaving the actual notebook update work to me. Similarly, when I asked it to add a new section with recommendations for lowering the insurance premium costs, it added a markdown response with its recommendation in the chatbot 🙁 Although copy-pasting the code or text isn’t a big deal for me, I still feel disappointed – once the notebook is generated in its first pass, all further interactions stay in the chat, just like ChatGPT.
My follow-up on updating the feature importance chart (image by author)
My follow-up on adding recommendations (image by author)
- It does not always choose the best data science approach. For this regression problem, it followed a reasonable workflow – data cleaning (handling missing values and outliers), data wrangling (one-hot encoding and log transformation), feature engineering (adding interaction features and other new features), and training and optimizing three models (Linear Regression, Random Forest, and Gradient Boosting Trees). However, when I looked into the details, I realized not all of its operations were necessarily the best practices. For example, it imputed missing values using the mean, which might not be a good idea for very skewed data and could impact correlations and relationships between variables. Also, we usually test many different feature engineering ideas and see how they impact the model’s performance. Therefore, while it sets up a solid foundation and framework, an experienced data scientist is still needed to refine the analysis and modeling.
These are the two main limitations regarding the Data Science Agent’s performance in this experiment. But if we think about the whole data project pipeline and workflow, there are broader challenges in applying this tool to real-world projects:
- What is the goal of the project? This dataset is provided by Kaggle for a playground competition. Therefore, the project goal is well-defined. However, a data project at work could be pretty ambiguous. We often need to talk to many stakeholders to understand the business goal, and have many back and forth to make sure we stay on the right track. This is not something the Data Science Agent can handle for you. It requires a clear goal to generate its list of tasks. In other words, if you give it an incorrect problem statement, the output will be useless.
- How do we get the clean dataset with documentation? Our example dataset is relatively clean, with basic documentation. However, this usually does not happen in the industry. Every data scientist or data analyst has probably experienced the pain of talking to multiple people just to find one data point, solving the myth of some random columns with confusing names and putting together thousands of lines of SQL to prepare the dataset for analysis and modeling. This sometimes takes 50% of the actual work time. In that case, the Data Science Agent can only help with the start of the other 50% of the work (so maybe 10 to 20%).
Who Are the Target Users
With the pros and cons in mind, who are the target users of the Data Science Agent? Or who will benefit the most from this new AI tool? Here are my thoughts:
- Aspiring data scientists. Data Science is still a hot space with lots of beginners starting every day. Given that the agent “understands” the standard process and basic concepts well, it can provide invaluable guidance to those just getting started, setting up a great framework and explaining the techniques with working code. For example, many people tend to learn from participating in Kaggle competitions. Just like what I did here, they can ask the Data Science Agent to generate an initial notebook, then dig into each step to understand why the agent does certain things and what can be improved.
- People with clear data questions but limited coding skills. The key requirements here are 1. the problem is clearly defined and 2. the data task is standard (not as complicated as optimizing a predictive model with 20 columns).. Let me give you some scenarios:
- Many researchers need to run analyses on the datasets they collected. They usually have a data question clearly defined, which makes it easier for the Data Science Agent to assist. Moreover, researchers usually have a good understanding of the basic statistical methods but might not be as proficient in coding. So the Agent can save them the time of writing code, meanwhile, the researchers can judge the correctness of the methods AI used. This is the same use case Google mentioned when it first introduced the Data Science Agent: “For example, with the help of Data Science Agent, a scientist at Lawrence Berkeley National Laboratory working on a global tropical wetland methane emissions project has estimated their analysis and processing time was reduced from one week to five minutes.”
- Product managers often need to do some basic analysis themselves — they have to make data-driven decisions. They know their questions well (and often the potential answers), and they can pull some data from internal BI tools or with the help of engineers. For example, they might want to examine the correlation between two metrics or understand the trend of a time series. In that case, the Data Science Agent can help them conduct the analysis with the problem context and data they provided.
Can It Replace Data Analysts and Data Scientists Yet?
We finally come to the question that every data scientist or analyst cares about the most: Is it ready to replace us yet?
The short answer is “No”. There are still major blockers for the Data Science Agent to be a real data scientist — it is missing the capabilities of modifying the Jupyter Notebook based on follow-up questions, it still requires someone with solid data science knowledge to audit the methods and make manual iterations, and it needs a clear data problem statement with clean and well-documented datasets.
However, AI is a fast-evolving space with significant improvements constantly. Just looking at where it came from and where it stands now, here are some very important lessons for data professionals to stay competitive:
- AI is a tool that greatly improves productivity. Instead of worrying about being replaced by AI, it is better to embrace the benefits it brings and learn how it can improve your work efficiency. Don’t feel guilty if you use it to write basic code — no one remembers all the numpy and pandas syntax and scikit-learn models 🙂 Coding is a tool to complete complex statistical analysis quickly, and AI is a new tool to save you even more time.
- If your work is mostly repetitive tasks, then you are at risk. It is very clear that these AI agents are getting better and better at automating standard and basic data tasks. If your job today is mostly making basic visualizations, building standard dashboards, or doing simple regression analysis, then the day of AI automating your job might come sooner than you expected.
Being a domain expert and a good communicator will set you apart. To make the AI tools work, you need to understand your domain well and be able to communicate and translate the business knowledge and problems to both your stakeholders and the AI tools. When it comes to machine learning, we always say “Garbage in, garbage out”. It is the same for an AI-assisted data project.
Featured image generated by the author with Dall-E