Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Very small language models (SLMs) can outperform leading large language models (LLMs) in reasoning tasks, according to a new study by Shanghai AI Laboratory. The authors show that with the right tools and test-time scaling techniques, an SLM with 1 billion parameters can outperform a 405B LLM on complicated math benchmarks.
The ability to deploy SLMs in complex reasoning tasks can be very useful as enterprises are looking for new ways to use these new models in different environments and applications.
Test-time scaling explained
Test-time scaling (TTS) is the process of giving LLMs extra compute cylces during inference to improve their performance on various tasks. Leading reasoning models, such as OpenAI o1 and DeepSeek-R1, use “internal TTS,” which means they are trained to “think” slowly by generating a long string of chain-of-thought (CoT) tokens.
An alternative approach is “external TTS,” where model performance is enhanced with (as the name implies) outside help. External TTS is suitable for repurposing exiting models for reasoning tasks without further fine-tuning them. An external TTS setup is usually composed of a “policy model,” which is the main LLM generating the answer, and a process reward model (PRM) that evaluates the policy model’s answers. These two components are coupled together through a sampling or search method.
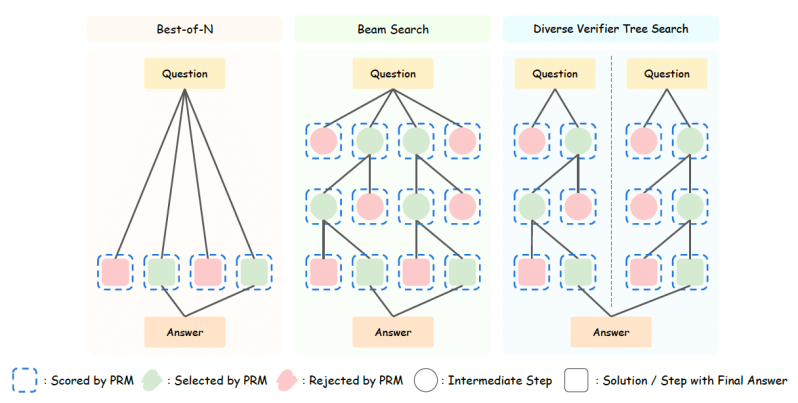
The easiest setup is “best-of-N,” where the policy model generates multiple answers and the PRM selects one or more best answers to compose the final response. More advanced external TTS methods use search. In “beam search,” the model breaks the answer down into multiple steps.
For each step, it samples multiple answers and runs them through the PRM. It then chooses one or more suitable candidates and generates the next step of the answer. And, in “diverse verifier tree search” (DVTS), the model generates several branches of answers to create a more diverse set of candidate responses before synthesizing them into a final answer.
What is the right scaling strategy?
Choosing the right TTS strategy depends on multiple factors. The study authors carried out a systematic investigation of how different policy models and PRMs affect the efficiency of TTS methods.
Their findings show that efficiency is largely dependent on the policy and PRM models. For example, for small policy models, search-based methods outperform best-of-N. However, for large policy models, best-of-N is more effective because the models have better reasoning capabilities and don’t need a reward model to verify every step of their reasoning.
Their findings also show that the right TTS strategy depends on the difficulty of the problem. For example, for small policy models with fewer than 7B parameters, best-of-N works better for easy problems, while beam search works better for harder problems. For policy models that have between 7B and 32B parameters, diverse tree search performs well for easy and medium problems, and beam search works best for hard problems. But for large policy models (72B parameters and more), best-of-N is the optimal method for all difficulty levels.
Why small models can beat large models
Based on these findings, developers can create compute-optimal TTS strategies that take into account the policy model, PRM and problem difficulty to make the best use of compute budget to solve reasoning problems.
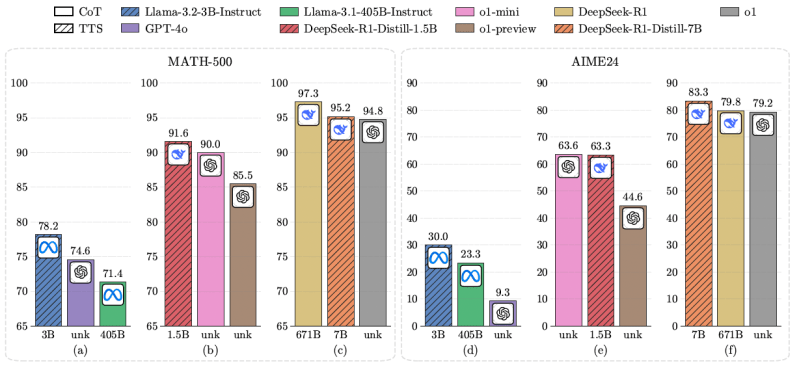
For example, the researchers found that a Llama-3.2-3B model with the compute-optimal TTS strategy outperforms the Llama-3.1-405B on MATH-500 and AIME24, two complicated math benchmarks. This shows that an SLM can outperform a model that is 135X larger when using the compute-optimal TTS strategy.
In other experiments, they found that a Qwen2.5 model with 500 million parameters can outperform GPT-4o with the right compute-optimal TTS strategy. Using the same strategy, the 1.5B distilled version of DeepSeek-R1 outperformed o1-preview and o1-mini on MATH-500 and AIME24.
When accounting for both training and inference compute budgets, the findings show that with compute-optimal scaling strategies, SLMs can outperform larger models with 100-1000X less FLOPS.
The researchers’ results show that compute-optimal TTS significantly enhances the reasoning capabilities of language models. However, as the policy model grows larger, the improvement of TTS gradually decreases.
“This suggests that the effectiveness of TTS is directly related to the reasoning ability of the policy model,” the researchers write. “Specifically, for models with weak reasoning abilities, scaling test-time compute leads to a substantial improvement, whereas for models with strong reasoning abilities, the gain is limited.”
The study validates that SLMs can perform better than larger models when applying compute-optimal test-time scaling methods. While this study focuses on math benchmarks, the researchers plan to expand their study to other reasoning tasks such as coding and chemistry.