Want smarter insights in your inbox? Sign up for our weekly newsletters to get only what matters to enterprise AI, data, and security leaders. Subscribe Now
Liquid AI has released LFM2-VL, a new generation of vision-language foundation models designed for efficient deployment across a wide range of hardware — from smartphones and laptops to wearables and embedded systems.
The models promise low-latency performance, strong accuracy, and flexibility for real-world applications.
LFM2-VL builds on the company’s existing LFM2 architecture, extending it into multimodal processing that supports both text and image inputs at variable resolutions.
According to Liquid AI, the models deliver up to twice the GPU inference speed of comparable vision-language models, while maintaining competitive performance on common benchmarks.
AI Scaling Hits Its Limits
Power caps, rising token costs, and inference delays are reshaping enterprise AI. Join our exclusive salon to discover how top teams are:
- Turning energy into a strategic advantage
- Architecting efficient inference for real throughput gains
- Unlocking competitive ROI with sustainable AI systems
Secure your spot to stay ahead: https://bit.ly/4mwGngO
“Efficiency is our product,” wrote Liquid AI co-founder and CEO Ramin Hasani in a post on X announcing the new model family:
Two variants for different needs
The release includes two model sizes:
- LFM2-VL-450M — a hyper-efficient model with less than half a billion parameters (internal settings) aimed at highly resource-constrained environments.
- LFM2-VL-1.6B — a more capable model that remains lightweight enough for single-GPU and device-based deployment.
Both variants process images at native resolutions up to 512×512 pixels, avoiding distortion or unnecessary upscaling.
For larger images, the system applies non-overlapping patching and adds a thumbnail for global context, enabling the model to capture both fine detail and the broader scene.
Background on Liquid AI
Liquid AI was founded by former researchers from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) with the goal of building AI architectures that move beyond the widely used transformer model.
The company’s flagship innovation, the Liquid Foundation Models (LFMs), are based on principles from dynamical systems, signal processing, and numerical linear algebra, producing general-purpose AI models capable of handling text, video, audio, time series, and other sequential data.
Unlike traditional architectures, Liquid’s approach aims to deliver competitive or superior performance using significantly fewer computational resources, allowing for real-time adaptability during inference while maintaining low memory requirements. This makes LFMs well suited for both large-scale enterprise use cases and resource-limited edge deployments.
In July 2025, the company expanded its platform strategy with the launch of the Liquid Edge AI Platform (LEAP), a cross-platform SDK designed to make it easier for developers to run small language models directly on mobile and embedded devices.
LEAP offers OS-agnostic support for iOS and Android, integration with both Liquid’s own models and other open-source SLMs, and a built-in library with models as small as 300MB—small enough for modern phones with minimal RAM.
Its companion app, Apollo, enables developers to test models entirely offline, aligning with Liquid AI’s emphasis on privacy-preserving, low-latency AI. Together, LEAP and Apollo reflect the company’s commitment to decentralizing AI execution, reducing reliance on cloud infrastructure, and empowering developers to build optimized, task-specific models for real-world environments.
Speed/quality trade-offs and technical design
LFM2-VL uses a modular architecture combining a language model backbone, a SigLIP2 NaFlex vision encoder, and a multimodal projector.
The projector includes a two-layer MLP connector with pixel unshuffle, reducing the number of image tokens and improving throughput.
Users can adjust parameters such as the maximum number of image tokens or patches, allowing them to balance speed and quality depending on the deployment scenario. The training process involved approximately 100 billion multimodal tokens, sourced from open datasets and in-house synthetic data.
Performance and benchmarks
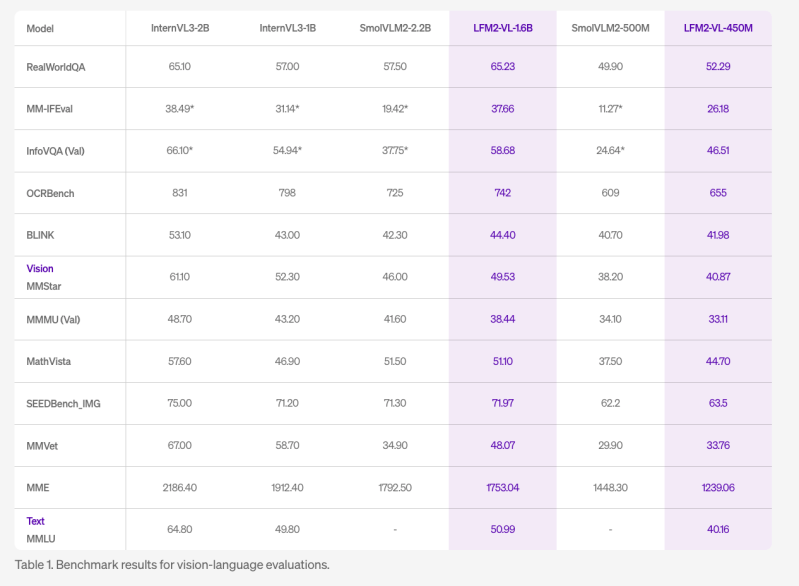
The models achieve competitive benchmark results across a range of vision-language evaluations. LFM2-VL-1.6B scores well in RealWorldQA (65.23), InfoVQA (58.68), and OCRBench (742), and maintains solid results in multimodal reasoning tasks.
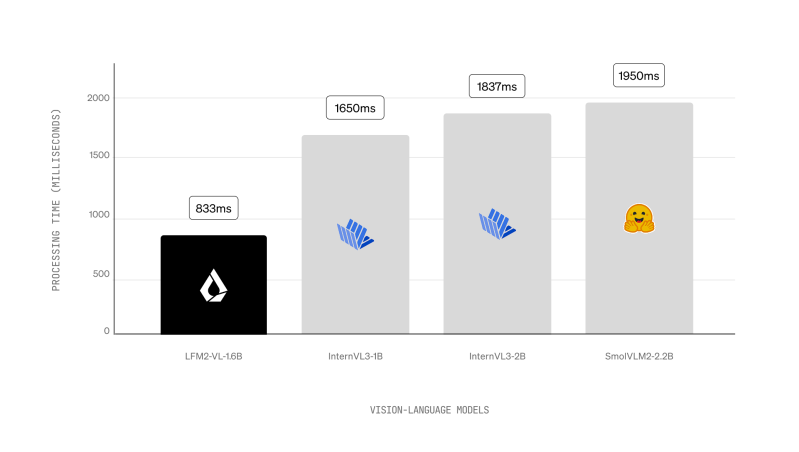
In inference testing, LFM2-VL achieved the fastest GPU processing times in its class when tested on a standard workload of a 1024×1024 image and short prompt.
Licensing and availability
LFM2-VL models are available now on Hugging Face, along with example fine-tuning code in Colab. They are compatible with Hugging Face transformers and TRL.
The models are released under a custom “LFM1.0 license”. Liquid AI has described this license as based on Apache 2.0 principles, but the full text has not yet been published.
The company has indicated that commercial use will be permitted under certain conditions, with different terms for companies above and below $10 million in annual revenue.
With LFM2-VL, Liquid AI aims to make high-performance multimodal AI more accessible for on-device and resource-limited deployments, without sacrificing capability.