Introduction
AI is everywhere.
It is hard not to interact at least once a day with a Large Language Model (LLM). The chatbots are here to stay. They’re in your apps, they help you write better, they compose emails, they read emails…well, they do a lot.
And I don’t think that that is bad. In fact, my opinion is the other way – at least so far. I defend and advocate for the use of AI in our daily lives because, let’s agree, it makes everything much easier.
I don’t have to spend time double-reading a document to find punctuation problems or type. AI does that for me. I don’t waste time writing that follow-up email every single Monday. AI does that for me. I don’t need to read a huge and boring contract when I have an AI to summarize the main takeaways and action points to me!
These are only some of AI’s great uses. If you’d like to know more use cases of LLMs to make our lives easier, I wrote a whole book about them.
Now, thinking as a data scientist and looking at the technical side, not everything is that bright and shiny.
LLMs are great for several general use cases that apply to anyone or any company. For example, coding, summarizing, or answering questions about general content created until the training cutoff date. However, when it comes to specific business applications, for a single purpose, or something new that didn’t make the cutoff date, that is when the models won’t be that useful if used out-of-the-box – meaning, they will not know the answer. Thus, it will need adjustments.
Training an LLM model can take months and millions of dollars. What is even worse is that if we don’t adjust and tune the model to our purpose, there will be unsatisfactory results or hallucinations (when the model’s response doesn’t make sense given our query).
So what is the solution, then? Spending a lot of money retraining the model to include our data?
Not really. That’s when the Retrieval-Augmented Generation (RAG) becomes useful.
RAG is a framework that combines getting information from an external knowledge base with large language models (LLMs). It helps AI models produce more accurate and relevant responses.
Let’s learn more about RAG next.
What is RAG?
Let me tell you a story to illustrate the concept.
I love movies. For some time in the past, I knew which movies were competing for the best movie category at the Oscars or the best actors and actresses. And I would certainly know which ones got the statue for that year. But now I am all rusty on that subject. If you asked me who was competing, I would not know. And even if I tried to answer you, I would give you a weak response.
So, to provide you with a quality response, I will do what everybody else does: search for the information online, obtain it, and then give it to you. What I just did is the same idea as the RAG: I obtained data from an external database to give you an answer.
When we enhance the LLM with a content store where it can go and retrieve data to augment (increase) its knowledge base, that is the RAG framework in action.
RAG is like creating a content store where the model can enhance its knowledge and respond more accurately.
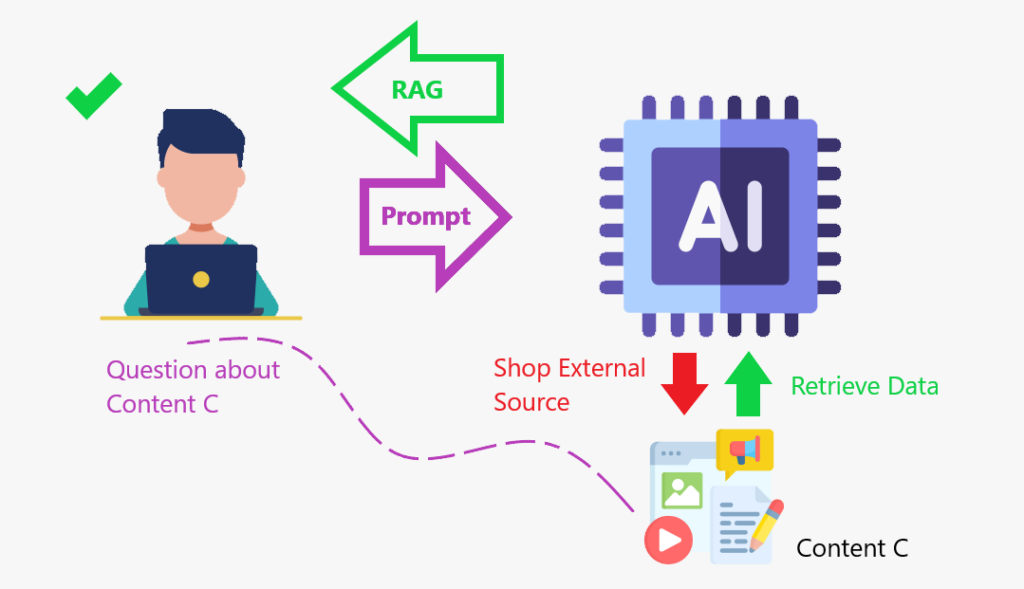
Summarizing:
- Uses search algorithms to query external data sources, such as databases, knowledge bases, and web pages.
- Pre-processes the retrieved information.
- Incorporates the pre-processed information into the LLM.
Why use RAG?
Now that we know what the RAG framework is let’s understand why we should be using it.
Here are some of the benefits:
- Enhances factual accuracy by referencing real data.
- RAG can help LLMs process and consolidate knowledge to create more relevant answers
- RAG can help LLMs access additional knowledge bases, such as internal organizational data
- RAG can help LLMs create more accurate domain-specific content
- RAG can help reduce knowledge gaps and AI hallucination
As previously explained, I like to say that with the RAG framework, we are giving an internal search engine for the content we want it to add to the knowledge base.
Well. All of that is very interesting. But let’s see an application of RAG. We will learn how to create an AI-powered PDF Reader Assistant.
Project
This is an application that allows users to upload a PDF document and ask questions about its content using AI-powered natural language processing (NLP) tools.
- The app uses
Streamlitas the front end. Langchain, OpenAI’s GPT-4 model, andFAISS(Facebook AI Similarity Search) for document retrieval and question answering in the backend.
Let’s break down the steps for better understanding:
- Loading a PDF file and splitting it into chunks of text.
- This makes the data optimized for retrieval
- Present the chunks to an embedding tool.
- Embeddings are numerical vector representations of data used to capture relationships, similarities, and meanings in a way that machines can understand. They are widely used in Natural Language Processing (NLP), recommender systems, and search engines.
- Next, we put those chunks of text and embeddings in the same DB for retrieval.
- Finally, we make it available to the LLM.
Data preparation
Preparing a content store for the LLM will take some steps, as we just saw. So, let’s start by creating a function that can load a file and split it into text chunks for efficient retrieval.
# Imports
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_document(pdf):
# Load a PDF
"""
Load a PDF and split it into chunks for efficient retrieval.
:param pdf: PDF file to load
:return: List of chunks of text
"""
loader = PyPDFLoader(pdf)
docs = loader.load()
# Instantiate Text Splitter with Chunk Size of 500 words and Overlap of 100 words so that context is not lost
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
# Split into chunks for efficient retrieval
chunks = text_splitter.split_documents(docs)
# Return
return chunksNext, we will start building our Streamlit app, and we’ll use that function in the next script.
Web application
We will begin importing the necessary modules in Python. Most of those will come from the langchain packages.
FAISS is used for document retrieval; OpenAIEmbeddings transforms the text chunks into numerical scores for better similarity calculation by the LLM; ChatOpenAI is what enables us to interact with the OpenAI API; create_retrieval_chain is what actually the RAG does, retrieving and augmenting the LLM with that data; create_stuff_documents_chain glues the model and the ChatPromptTemplate.
Note: You will need to generate an OpenAI Key to be able to run this script. If it’s the first time you’re creating your account, you get some free credits. But if you have it for some time, it is possible that you will have to add 5 dollars in credits to be able to access OpenAI’s API. An option is using Hugging Face’s Embedding.
# Imports
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain.chains import create_retrieval_chain
from langchain_openai import ChatOpenAI
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from scripts.secret import OPENAI_KEY
from scripts.document_loader import load_document
import streamlit as stThis first code snippet will create the App title, create a box for file upload, and prepare the file to be added to the load_document() function.
# Create a Streamlit app
st.title("AI-Powered Document Q&A")
# Load document to streamlit
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
# If a file is uploaded, create the TextSplitter and vector database
if uploaded_file :
# Code to work around document loader from Streamlit and make it readable by langchain
temp_file = "./temp.pdf"
with open(temp_file, "wb") as file:
file.write(uploaded_file.getvalue())
file_name = uploaded_file.name
# Load document and split it into chunks for efficient retrieval.
chunks = load_document(temp_file)
# Message user that document is being processed with time emoji
st.write("Processing document... :watch:")Machines understand numbers better than text, so in the end, we will have to provide the model with a database of numbers that it can compare and check for similarity when performing a query. That’s where the embeddings will be useful to create the vector_db, in this next piece of code.
# Generate embeddings
# Embeddings are numerical vector representations of data, typically used to capture relationships, similarities,
# and meanings in a way that machines can understand. They are widely used in Natural Language Processing (NLP),
# recommender systems, and search engines.
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_KEY,
model="text-embedding-ada-002")
# Can also use HuggingFaceEmbeddings
# from langchain_huggingface.embeddings import HuggingFaceEmbeddings
# embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
# Create vector database containing chunks and embeddings
vector_db = FAISS.from_documents(chunks, embeddings)Next, we create a retriever object to navigate in the vector_db.
# Create a document retriever
retriever = vector_db.as_retriever()
llm = ChatOpenAI(model_name="gpt-4o-mini", openai_api_key=OPENAI_KEY)Then, we will create the system_prompt, which is a set of instructions to the LLM on how to answer, and we will create a prompt template, preparing it to be added to the model once we get the input from the user.
# Create a system prompt
# It sets the overall context for the model.
# It influences tone, style, and focus before user interaction starts.
# Unlike user inputs, a system prompt is not visible to the end user.
system_prompt = (
"You are a helpful assistant. Use the given context to answer the question."
"If you don't know the answer, say you don't know. "
"{context}"
)
# Create a prompt Template
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{input}"),
]
)
# Create a chain
# It creates a StuffDocumentsChain, which takes multiple documents (text data) and "stuffs" them together before passing them to the LLM for processing.
question_answer_chain = create_stuff_documents_chain(llm, prompt)Moving on, we create the core of the RAG framework, pasting together the retriever object and the prompt. This object adds relevant documents from a data source (e.g., a vector database) and makes it ready to be processed using an LLM to generate a response.
# Creates the RAG
chain = create_retrieval_chain(retriever, question_answer_chain)Finally, we create the variable question for the user input. If this question box is filled with a query, we pass it to the chain, which calls the LLM to process and return the response, which will be printed on the app’s screen.
# Streamlit input for question
question = st.text_input("Ask a question about the document:")
if question:
# Answer
response = chain.invoke({"input": question})['answer']
st.write(response)Here is a screenshot of the result.
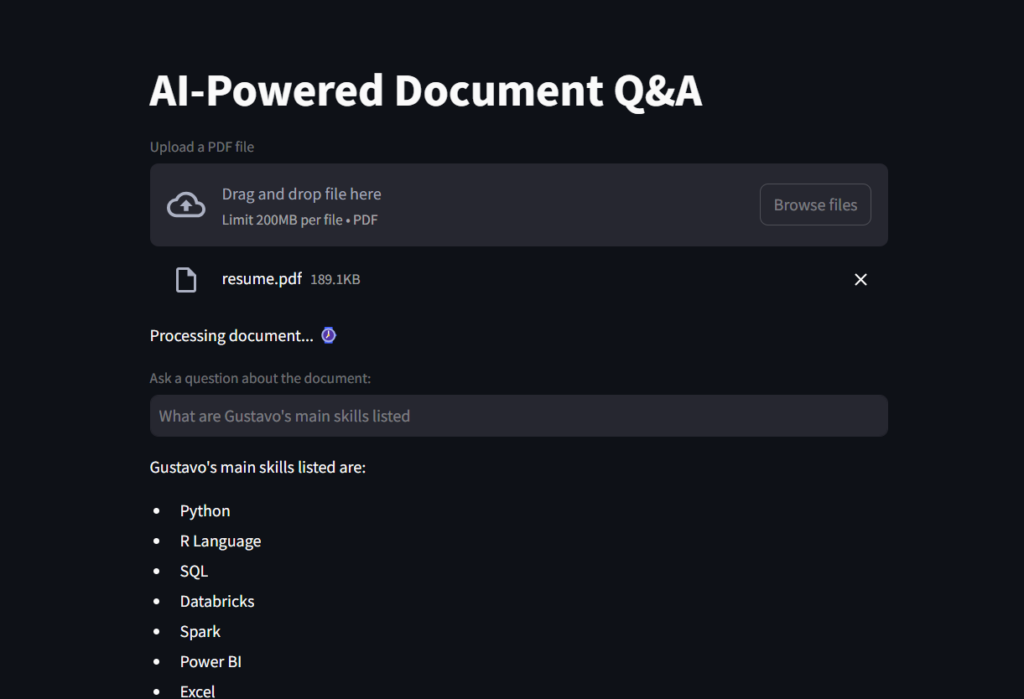
And this is a GIF for you to see the File Reader Ai Assistant in action!
Before you go
In this project, we learned what the RAG framework is and how it helps the Llm to perform better and also perform well with specific knowledge.
AI can be powered with knowledge from an instruction manual, databases from a company, some finance files, or contracts, and then become fine-tuned to respond accurately to domain-specific content queries. The knowledge base is augmented with a content store.
To recap, this is how the framework works:
1️⃣ User Query → Input text is received.
2️⃣ Retrieve Relevant Documents → Searches a knowledge base (e.g., a database, vector store).
3️⃣ Augment Context → Retrieved documents are added to the input.
4️⃣ Generate Response → An LLM processes the combined input and produces an answer.
GitHub repository
https://github.com/gurezende/Basic-Rag
About me
If you liked this content and want to learn more about my work, here is my website, where you can also find all my contacts.
References
https://cloud.google.com/use-cases/retrieval-augmented-generation
https://www.ibm.com/think/topics/retrieval-augmented-generation
https://python.langchain.com/docs/introduction
https://www.geeksforgeeks.org/how-to-get-your-own-openai-api-key