Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
The entire AI landscape shifted back in January 2025 after a then little-known Chinese AI startup DeepSeek (a subsidiary of the Hong Kong-based quantitative analysis firm High-Flyer Capital Management) launched its powerful open source language reasoning model DeepSeek R1 publicly to the world, besting U.S. giants such as Meta.
As DeepSeek usage spread rapidly among researchers and enterprises, Meta was reportedly sent into panic mode upon learning that this new R1 model had been trained for a fraction of the cost of many other leading models yet outclassed them, reportedly for as little as several million dollars — what it pays some of its own AI team leaders.
Meta’s whole generative AI strategy had until that point been predicated on releasing best-in-class open source models under its brand name “Llama” for researchers and companies to build upon freely (at least, if they had fewer than 700 million monthly users, at which point they are supposed to contact Meta for special paid licensing terms). Yet DeepSeek R1’s astonishingly good performance on a far smaller budget had allegedly shaken the company leadership and forced some kind of reckoning, with the last version of Llama, 3.3, having been released just a month prior in December 2024 yet already looking outdated.
Now we know the fruits of that effort: today, Meta founder and CEO Mark Zuckerberg took to his Instagram account to announced a new Llama 4 series of models, with two of them — the 400-billion parameter Llama 4 Maverick and 109-billion parameter Llama 4 Scout — available today for developers to download and begin using or fine-tuning now on llama.com and AI code sharing community Hugging Face.
A massive 2-trillion parameter Llama 4 Behemoth is also being previewed today, though Meta’s blog post on the releases said it was still being trained, and gave no indication of when it might be released. (Recall parameters refer to the settings that govern the model’s behavior and that generally more mean a more powerful and complex all around model.)
One headline feature of these models is that they are all multimodal — trained on, and therefore, capable of receiving and generating text, video, and imagery (hough audio was not mentioned).
Another is that they have incredibly long context windows — 1 million tokens for Llama 4 Maverick and 10 million for Llama 4 Scout — which is equivalent to about 1,500 and 15,000 pages of text, respectively, all of which the model can handle in a single input/output interaction. That means a user could theoretically upload or paste up to 7,500 pages-worth-of text and receive that much in return from Llama 4 Scout, which would be handy for information-dense fields such as medicine, science, engineering, mathematics, literature etc.
Here’s what else we’ve learned about this release so far:
All-in on mixture-of-experts
All three models use the “mixture-of-experts (MoE)” architecture approach popularized in earlier model releases from OpenAI and Mistral, which essentially combines multiple smaller models specialized (“experts”) in different tasks, subjects and media formats into a unified whole, larger model. Each Llama 4 release is said to be therefore a mixture of 128 different experts, and more efficient to run because only the expert needed for a particular task, plus a “shared” expert, handles each token, instead of the entire model having to run for each one.
As the Llama 4 blog post notes:
As a result, while all parameters are stored in memory, only a subset of the total parameters are activated while serving these models. This improves inference efficiency by lowering model serving costs and latency—Llama 4 Maverick can be run on a single [Nvidia] H100 DGX host for easy deployment, or with distributed inference for maximum efficiency.
Both Scout and Maverick are available to the public for self-hosting, while no hosted API or pricing tiers have been announced for official Meta infrastructure. Instead, Meta focuses on distribution through open download and integration with Meta AI in WhatsApp, Messenger, Instagram, and web.
Meta estimates the inference cost for Llama 4 Maverick at $0.19 to $0.49 per 1 million tokens (using a 3:1 blend of input and output). This makes it substantially cheaper than proprietary models like GPT-4o, which is estimated to cost $4.38 per million tokens, based on community benchmarks.
All three Llama 4 models—especially Maverick and Behemoth—are explicitly designed for reasoning, coding, and step-by-step problem solving — though they don’t appear to exhibit the chains-of-thought of dedicated reasoning models such as the OpenAI “o” series, nor DeepSeek R1.
Instead, they seem designed to compete more directly with “classical,” non-reasoning LLMs and multimodal models such as OpenAI’s GPT-4o and DeepSeek’s V3 — with the exception of Llama 4 Behemoth, which does appear to threaten DeepSeek R1 (more on this below!)
In addition, for Llama 4, Meta built custom post-training pipelines focused on enhancing reasoning, such as:
- Removing over 50% of “easy” prompts during supervised fine-tuning.
- Adopting a continuous reinforcement learning loop with progressively harder prompts.
- Using pass@k evaluation and curriculum sampling to strengthen performance in math, logic, and coding.
- Implementing MetaP, a new technique that lets engineers tune hyperparameters (like per-layer learning rates) on models and apply them to other model sizes and types of tokens while preserving the intended model behavior.
MetaP is of particular interest as it could be used going forward to set hyperparameters on on model and then get many other types of models out of it, increasing training efficiency.
As my VentureBeat colleague and LLM expert Ben Dickson opined ont the new MetaP technique: “This can save a lot of time and money. It means that they run experiments on the smaller models instead of doing them on the large-scale ones.”
This is especially critical when training models as large as Behemoth, which uses 32K GPUs and FP8 precision, achieving 390 TFLOPs/GPU over more than 30 trillion tokens—more than double the Llama 3 training data.
In other words: the researchers can tell the model broadly how they want it to act, and apply this to larger and smaller version of the model, and across different forms of media.
A powerful – but not yet the most powerful — model family
In his announcement video on Instagram (a Meta subsidiary, naturally), Meta CEO Mark Zuckerberg said that the company’s “goal is to build the world’s leading AI, open source it, and make it universally accessible so that everyone in the world benefits…I’ve said for a while that I think open source AI is going to become the leading models, and with Llama 4, that is starting to happen.”
It’s a clearly carefully worded statement, as is Meta’s blog post calling Llama 4 Scout, “the best multimodal model in the world in its class and is more powerful than all previous generation Llama models,” (emphasis added by me).
In other words, these are very powerful models, near the top of the heap compared to others in their parameter-size class, but not necessarily setting new performance records. Nonetheless, Meta was keen to trumpet the models its new Llama 4 family beats, among them:
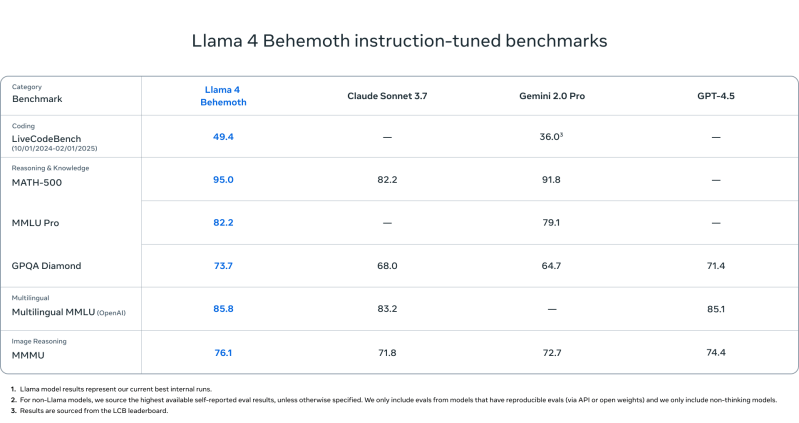
Llama 4 Behemoth
- Outperforms GPT-4.5, Gemini 2.0 Pro, and Claude Sonnet 3.7 on:
- MATH-500 (95.0)
- GPQA Diamond (73.7)
- MMLU Pro (82.2)
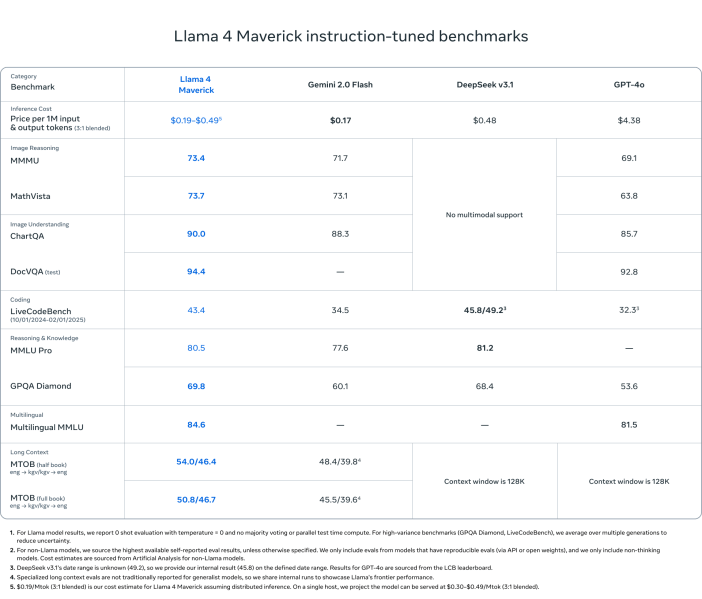
Llama 4 Maverick
- Beats GPT-4o and Gemini 2.0 Flash on most multimodal reasoning benchmarks:
- ChartQA, DocVQA, MathVista, MMMU
- Competitive with DeepSeek v3.1 (45.8B params) while using less than half the active parameters (17B)
- Benchmark scores:
- ChartQA: 90.0 (vs. GPT-4o’s 85.7)
- DocVQA: 94.4 (vs. 92.8)
- MMLU Pro: 80.5
- Cost-effective: $0.19–$0.49 per 1M tokens
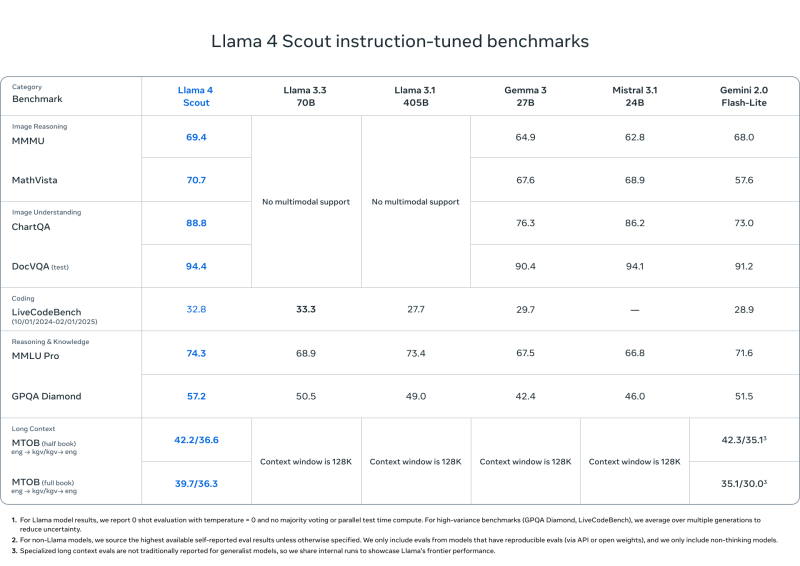
Llama 4 Scout
- Matches or outperforms models like Mistral 3.1, Gemini 2.0 Flash-Lite, and Gemma 3 on:
- DocVQA: 94.4
- MMLU Pro: 74.3
- MathVista: 70.7
- Unmatched 10M token context length—ideal for long documents, codebases, or multi-turn analysis
- Designed for efficient deployment on a single H100 GPU
But after all that, how does Llama 4 stack up to DeepSeek?
But of course, there are a whole other class of reasoning-heavy models such as DeepSeek R1, OpenAI’s “o” series (like GPT-4o), Gemini 2.0, and Claude Sonnet.
Using the highest-parameter model benchmarked—Llama 4 Behemoth—and comparing it to the intial DeepSeek R1 release chart for R1-32B and OpenAI o1 models, here’s how Llama 4 Behemoth stacks up:
| Benchmark | Llama 4 Behemoth | DeepSeek R1 | OpenAI o1-1217 |
|---|---|---|---|
| MATH-500 | 95.0 | 97.3 | 96.4 |
| GPQA Diamond | 73.7 | 71.5 | 75.7 |
| MMLU | 82.2 | 90.8 | 91.8 |
What can we conclude?
- MATH-500: Llama 4 Behemoth is slightly behind DeepSeek R1 and OpenAI o1.
- GPQA Diamond: Behemoth is ahead of DeepSeek R1, but behind OpenAI o1.
- MMLU: Behemoth trails both, but still outperforms Gemini 2.0 Pro and GPT-4.5.
Takeaway: While DeepSeek R1 and OpenAI o1 edge out Behemoth on a couple metrics, Llama 4 Behemoth remains highly competitive and performs at or near the top of the reasoning leaderboard in its class.
Safety and less political ‘bias’
Meta also emphasized model alignment and safety by introducing tools like Llama Guard, Prompt Guard, and CyberSecEval to help developers detect unsafe input/output or adversarial prompts, and implementing Generative Offensive Agent Testing (GOAT) for automated red-teaming.
The company also claims Llama 4 shows substantial improvement on “political bias” and says “specifically, [leading LLMs] historically have leaned left when it comes to debated political and social topics,” that that Llama 4 does better at courting the right wing…in keeping with Zuckerberg’s embrace of Republican U.S. president Donald J. Trump and his party following the 2024 election.
Where Llama 4 stands so far
Meta’s Llama 4 models bring together efficiency, openness, and high-end performance across multimodal and reasoning tasks.
With Scout and Maverick now publicly available and Behemoth previewed as a state-of-the-art teacher model, the Llama ecosystem is positioned to offer a competitive open alternative to top-tier proprietary models from OpenAI, Anthropic, DeepSeek, and Google.
Whether you’re building enterprise-scale assistants, AI research pipelines, or long-context analytical tools, Llama 4 offers flexible, high-performance options with a clear orientation toward reasoning-first design.