Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Nvidia launched its much-awaited Nvidia GeForce RTX 50 series graphics processing units (GPUs), based on the Blackwell RTX tech.
Jensen Huang, CEO of Nvidia, disclosed the news during his opening keynote speech at CES 2025, the big tech trade show in Las Vegas this week.
“Blackwell, the engine of AI, has arrived for PC gamers, developers and creatives,” said Huang. “Fusing AI-driven neural rendering and ray tracing, Blackwell is the most significant computer graphics innovation since we introduced programmable shading 25 years ago.”
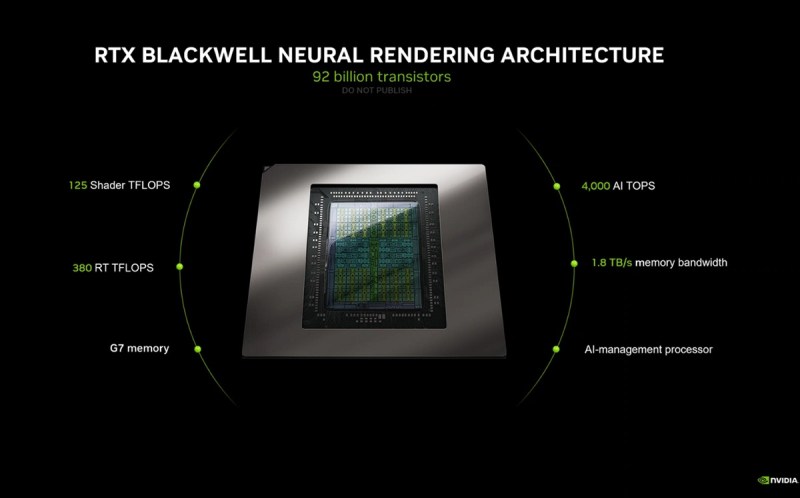
The new RTX Blackwell Neural Rendering Architecture comes with about 92 billion transistors. It has 125 Shader Teraflops of performance 380 RT TFLOPS, 4,000 AI TOPS, 1.8 terabytes per second of memory bandwidth, G7 memory (from Micron) and an AI-management processor. The top SKU has basically over 3,352 trillion AI operations per second (TOPS) of computing power.
“The programmable shader is also able to carry neural networks,” Huang said.

Among the new technologies in this generation are RTX Neural Shaders, DLSS 4, RTX Neural Face rendering to create more realistic human faces, RTX Mega Geometry for rendering environments, and Reflex 2.
The DLSS 4 now can generate multiple frames at once thanks to advanced AI technology. That makes for much better frame rates.
Nvidia showed that one scene could be rendered at 27 frames per second with the DLSS turned off, with a 71 millisecond PC latency. DLSS 2 can do that scene with its super resolution tech at 71 FPS and PC latency of 34 milliseconds. DLSS 3.5 can do the scene at 140 FPS and 33 milliseconds. But DLSS 4 comes in at a whopping 247 FPS and 34 milliseconds. DLSS 4 is more than eight times better performance than systems that aren’t using AI for the predictive processing.
Nvidia’s SKUs include the GeForce RTX 50 Series Desktop Family. It includes the top of the line GPU, the GeForce RTX 5090 coming in at 3,404 AI TOPS and 32GB of G7 memory for $1,999. It also includes the GeForce RTX 5080 at 1,800 AI TOPS and 16GB of G7 memory for $999. The GeForce RTX 5070 Ti (the performance of a 4090) has 1,406 AI TOPS, 16GB of G7 memory for $749 and the GeForce RTX 5070 has 1117 AI TOPS, 12GB of G7 and costs $549.
Nvidia also said the GeForce RTX 50 Series will come to laptops with two times efficiency with more performance at half the power compared to the previous generation. It has 40% more battery life with Black Max-Q, two times larger generative AI models, and it is as thin as 14.9 millimeters in terms of laptop thickness.
As far as pricing goes, the laptops will come as follows: RTX 5090 at 1,824 AI TOPS and 24GB at $2,899. The RTX 5080 laptops will be at 1,334 AI TOPS, 16GB and $2,199. The RTX 5070 Ti will be 992 AI TOPS, 12GB and $1,599 and the RTX 5070 will be 798 AI TOPS, eight GB and $1,299.
Those are steep prices, but they represent the high end of value in GPUs for gaming.
Justin Walker, senior director of GeForce products, said in press briefing that Nvidia’s GeForce graphics card brand just celebrated its 25-year anniversary. It was the hit product that helped cement the company’s dominance in the ultra-competitive graphics processing unit (GPU) market and it enabled the company to use graphics as a springboard to AI processing, which is why Nvidia is the most valuable company in the world with a market capitalization of $3.65 trillion.
Now, it turns out, Walker said, AI can be used to help accelerate the performance of GPUs.
“The great thing about that is that while we are now an AI company, as well as gaming, our gaming side still benefits tremendously from the fact that we are doing AI,” Walker said.
And that’s the root of one of the announcements: Nvidia took the wraps of DLSS 4, which uses AI to predict the next pixel that needs to be drawn and then preemptively renders the pixel based on that prediction. The AI TOPS (a measure of AI performance) will be up to 4,000.
The new architecture of the 5000 series will have 1.8 terabytes per second of memory bandwidth, and it’s also tapping the Blackwell architecture that is the foundation of Nvidia’s latest AI processors.
The new GPU also has neural rendering technologies such as neural shaders.
“This is probably the biggest thing to happen in the graphics since programming for shaders, we are actually going to be embedding small neural networks within the shaders itself, and these neural networks can do certain things much more effectively and efficiently than traditional shaders,” Walker said.
The tech will enable Nvidia to compress textures eight times to maximize use of memory.
The Reflex 2 tech will use predictive shading to reduce the latency between when a gamer creates a movement and it shows up on the screen, so it will be 75% more responsive for gamers.
The 5090 series is likely to ship in January and the rest of the systems are going to ship in the March time frame, and the company will say which companies are shipping with the technology later. A number of games like Cyberpunk 2077 can play in 4K resolution at over 200 frames per second.
Walker said the company will have a list of games that take advantage of the various features.
Nvidia DLSS 4 Boosts Performance by Up to 8 times

DLSS 4 debuts Multi Frame Generation to boost frame rates by using AI to generate up to three frames per rendered frame. It works in unison with the suite of DLSS technologies to increase performance by up to 8x over traditional rendering, while maintaining responsiveness with Nvidia Reflex technology.
DLSS 4 also introduces the graphics industry’s first real-time application of the transformer model architecture. Transformer-based DLSS Ray Reconstruction and Super Resolution models use 2x more parameters and 4x more compute to provide greater stability, reduced ghosting, higher details and enhanced anti-aliasing in game scenes. DLSS 4 will be supported on GeForce RTX 50 Series GPUs in over 75 games and applications the day of launch.
Nvidia Reflex 2 introduces Frame Warp, an innovative technique to reduce latency in games by updating a rendered frame based on the latest mouse input just before it is sent to the display. Reflex 2 can reduce latency by up to 75%. This gives gamers a competitive edge in multiplayer games and makes single-player titles more responsive.
Blackwell Brings AI to Shaders

Twenty-five years ago, Nvidia introduced GeForce 3 and programmable shaders, which set the stage for two decades of graphics innovation, from pixel shading to compute shading to real-time ray tracing. Alongside GeForce RTX 50 Series GPUs, NVIDIA is introducing RTX Neural Shaders, which brings small AI networks into programmable shaders, unlocking film-quality materials, lighting and more in real-time games.
Rendering game characters is one of the most challenging tasks in real-time graphics, as people are prone to notice the smallest errors or artifacts in digital humans. RTX Neural Faces takes a simple rasterized face and 3D pose data as input, and uses generative AI to render a temporally stable, high-quality digital face in real time.
RTX Neural Faces is complemented by new RTX technologies for ray-traced hair and skin. Along with the new RTX Mega Geometry, which enables up to 100 times more ray-traced triangles in a scene, these advancements are poised to deliver a massive leap in realism for game characters and environments.
The power of neural rendering, DLSS 4 and the new DLSS transformer model is showcased on GeForce RTX 50 Series GPUs with Zorah, a groundbreaking new technology demo from Nvidia.
Autonomous Game Characters

GeForce RTX 50 Series GPUs bring industry-leading AI TOPS to power autonomous game characters in parallel with game rendering.
Nvidia is introducing a suite of new Nvidia ACE technologies that enable game characters to perceive, plan and act like human players. ACE-powered autonomous characters are being integrated into Krafton’s PUBG: Battlegrounds and InZOI, the publisher’s upcoming life simulation game, as well as Wemade Next’s
MIR5.
In PUBG, companions powered by NVIDIA ACE plan and execute strategic actions, dynamically working with human players to ensure survival. InZOI features Smart Zoi characters that autonomously adjust behaviors based on life goals and in-game events. In MIR5, large language model (LLM)-driven raid bosses adapt tactics based on player behavior, creating more dynamic, challenging encounters.
AI Foundation Models for RTX AI PCs

Showcasing how RTX enthusiasts and developers can use NVIDIA NIM microservices to build AI agents and assistants, NVIDIA will release a pipeline of NIM microservices and AI Blueprints for RTX AI PCs from top model developers such as Black Forest Labs, Meta, Mistral and Stability AI.
Use cases span LLMs, vision language models, image generation, speech, embedding models for retrieval-augmented generation, PDF extraction and computer vision. The NIM microservices include all the necessary components for running AI on PCs and are optimized for deployment across all NVIDIA GPUs.
To demonstrate how enthusiasts and developers can use NIM to build AI agents and assistants, NVIDIA today previewed Project R2X, a vision-enabled PC avatar that can put information at a user’s fingengertips, assist with desktop apps and video conference calls, read and summarize documents, and more.

The GeForce RTX 50 Series GPUs supercharge creative work flows. RTX 50 Series GPUs are the first consumer GPUs to support FP4 precision, boosting AI image generation performance for models such as FLUX by 2x and enabling generative AI models to run locally in a smaller memory footprint, compared with previous-generation hardware.
The NVIDIA Broadcast app gains two AI-powered beta features for livestreamers: Studio Voice, which upgrades microphone audio, and Virtual Key light, which relights faces for polished streams. Streamlabs is introducing the Intelligent Streaming Assistant, powered by NVIDIA ACE and Inworld AI, which acts as a
cohost, producer and technical assistant to enhance livestreams.
The NvidiaFounders Editions of the GeForce RTX 5090, RTX 5080 and RTX 5070 GPUs will be available directly from nvidia.com and select retailers worldwide.
Stock-clocked and factory-overclocked models will be available from top add-in card providers such as ASUS, Colorful, Gainward, GALAX, GIGABYTE, INNO3D, KFA2, MSI, Palit, PNY and ZOTAC, and in desktops from system builders including Falcon Northwest, Inniarc, MAINGEAR, Mifcom, ORIGIN PC, PC Specialist and Scan Computers.
Laptops with GeForce RTX 5090, RTX 5080 and RTX 5070 Ti Laptop GPUs will be available starting in March, and RTX 5070 Laptop GPUs will be available starting in April from the world’s top manufacturers, including Acer, ASUS, Dell, GIGABYTE, HP, Lenovo, MECHREVO, MSI and Razer.