OpenAI is getting back to its roots as an open source AI company with today’s announcement and release of two new, open source, frontier large language models (LLMs): gpt-oss-120b and gpt-oss-20b.
The former is a 120-billion parameter model as the name would suggest, capable of running on a single Nvidia H100 graphics processing unit (GPU) and the latter is only 20 billion, small enough to run locally on a consumer laptop or desktop PC.
Both are text-only language models, which means unlike the multimodal AI that we’ve had for nearly two years that allows users to upload files and images and have the AI analyze them, users will be confined to only inputting text messages to the models and receiving text back out.
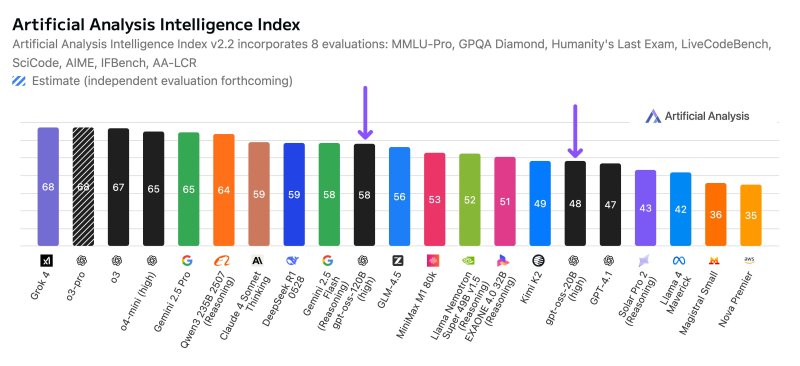
However, they can still of course write code and provide math problems and numerics, and in terms of their performance on tasks, they rank above some of OpenAI’s paid models and much of the competition globally.
The AI Impact Series Returns to San Francisco – August 5
The next phase of AI is here – are you ready? Join leaders from Block, GSK, and SAP for an exclusive look at how autonomous agents are reshaping enterprise workflows – from real-time decision-making to end-to-end automation.
Secure your spot now – space is limited: https://bit.ly/3GuuPLF
They can also be connected to external tools including web search to perform research on behalf of the user. More on this below.
Most importantly: they’re free, they’re available for enterprises and indie developers to download the code and use right now, modifying according to their needs, and can be run locally without a web connection, ensuring maximum privacy, unlike the other top OpenAI models and those from leading U.S.-based rivals Google and Anthropic.
The models can be downloaded today with full weights (the settings guiding its behavior) on the AI code sharing community Hugging Face and GitHub.
High benchmark scores
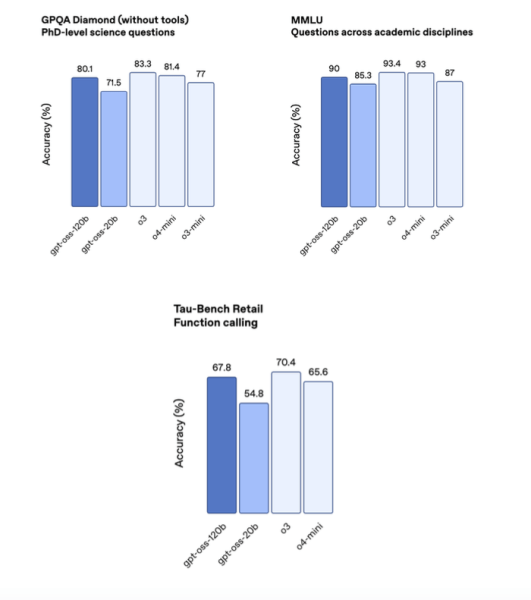
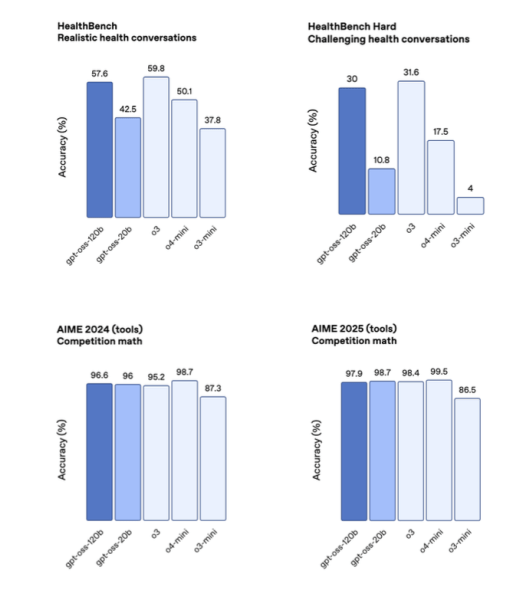
According to OpenAI, gpt-oss-120b matches or exceeds its proprietary o4-mini model on reasoning and tool-use benchmarks, including competition mathematics (AIME 2024 & 2025), general problem solving (MMLU and HLE), agentic evaluations (TauBench), and health-specific evaluations (HealthBench). The smaller gpt-oss-20b model is comparable to o3-mini and even surpasses it in some benchmarks.
The models are multilingual and perform well across a variety of non-English languages, though OpenAI declined to specify which and how many.
While these capabilities are available out of the box, OpenAI notes that localized fine-tuning — such as an ongoing collaboration with the Swedish government to produce a version fine-tuned on the country’s language —can still meaningfully enhance performance for specific regional or linguistic contexts.
A hugely advantageous license for enterprises and privacy-minded users
But the biggest feature is the licensing terms for both: Apache 2.0, the same as the wave of Chinese open source models that have been released over the last several weeks, and a more enterprise-friendly license than Meta’s trickier and more nuanced open-ish Llama license, which requires that users who operate a service with more than 700 million monthly active users obtain a paid license to keep using the company’s family of LLMs.
By contrast, OpenAI’s new gpt-oss series of models offer no such restrictions. In keeping with Chinese competitors and counterparts, any consumer, developer, independent entrepreneur or enterprise large and small is empowered by the Apache 2.0 license to be able to download the new gpt-oss models at will, fine-tune and alter them to fit their specific needs, and use them to generate revenue or operate paid services, all without paying OpenAI a dime (or anything!).
This also means enterprises can use a powerful, near topline OpenAI model on their own hardware totally privately and securely, without sending any data up to the cloud, on web servers, or anywhere else. For highly regulated industries like finance, healthcare, and legal services, not to mention organizations in military, intelligence, and government, this may be a requirement.
Before today, anyone using ChatGPT or its application programming interface (API) — the service that acts like a switching board and allows third-party software developers to connect their own apps and services to these OpenAI’s proprietary/paid models like GPT-4o and o3 — was sending data up to OpenAI servers that could technically be subpoenaed by government agencies and accessed without a user’s knowledge. That’s still the case for anyone using ChatGPT or the API going forward, as OpenAI co-founder and Sam Altman recently warned.
And while running the new gpt-oss models locally on a user’s own hardware disconnected from the web would allow for maximum privacy, as soon as the user decides to connect it to external web search or other web enabled tools, some of the same privacy risks and issues would then arise — through any third-party web services the user or developer was relying on when hooking the models up to said tools.
The last OpenAI open source language model was released more than six years ago
“This is the first time we’re releasing an open-weight language model in a long time… We view this as complementary to our other products,” said OpenAI co-founder and president Greg Brockman on an embargoed press video call with VentureBeat and other journalists last night.
The last time OpenAI released a fully open source language model was GPT-2 in 2019, more than six years ago, and three years before the release of ChatGPT.
This fact has sparked the ire of — and resulted in several lawsuits from — former OpenAI co-founder and backer turned rival Elon Musk, who, along with many other critics, have spent the last several years accusing OpenAI of betraying its mission and founding principles and namesake by eschewing open source AI releases in favor of paid proprietary models available only to customers of OpenAI’s API or paying ChatGPT subscribers (though there is a free tier for the latter).
OpenAI co-founder CEO Sam Altman did express regret about being on the “wrong side of history” but not releasing more open source AI sooner in a Reddit AMA (ask me anything) QA with users in February of this year, and Altman committed to releasing a new open source model back in March, but ultimately the company delayed its release from a planned July date until now.
Now OpenAI is tacking back toward open source, and the question is, why?
Why would OpenAI release a set of free open source models that it makes no money from?
To paraphrase Jesse Plemons’ character’s memorable line from the film Game Night: “How can that be profitable for OpenAI?”

After all, business to OpenAI’s paid offerings appears to be booming.
Revenue has skyrocketed alongside the rapid expansion of its ChatGPT user base, now at 700 million weekly active users. As of August 2025, OpenAI reported $13 billion in annual recurring revenue, up from $10 billion in June. That growth is driven by a sharp rise in paying business customers — now 5 million, up from 3 million just two months earlier — and surging daily engagement, with over 3 billion user messages sent every day.
The financial momentum follows an $8.3 billion funding round that valued OpenAI at $300 billion and provides the foundation for the company’s aggressive infrastructure expansion and global ambitions.
Compare that to closed/proprietary rival AI startup Anthropic’s reported $5 billion in total annual recurring revenue, but interestingly, Anthropic is said to be getting more money from its API, $3.1 billion in revenue compared to OpenAI’s $2.9 billion, according to The Information.
So, given how well the paid AI business is already doing, the business strategy behind these open source offerings is less clear — especially since the new OpenAI gpt-oss models will almost certainly cut into some (perhaps a lot of) usage of OpenAI’s paid models. Why go back to offering open source LLMs now when so much money is flowing into paid and none will, by virtue of its very intent, go directly toward open source models?
Put simply: because open source competitors, beginning with the release of the impressively efficient DeepSeek R1 by the Chinese AI division of the same name in January 2025, are offering near parity on performance benchmarks to paid proprietary models, for free, with fewer (basically zero) implementation restrictions for enterprises and end users. And increasingly, enterprises are adopting these open source models in production.
As OpenAI executives and team members revealed to VentureBeat and many other journalists on an embargoed video call last night about the new models that when it comes to OpenAI’s API, the majority of customers are using a mix of paid OpenAI models and open source models from other providers. (I asked, but OpenAI declined to specify what percentage or total number of API customers are using open source models and which ones).
At least, until now. OpenAI clearly hopes these new gpt-oss offerings will get more of these users to switch away from competing open source offerings and back into OpenAI’s ecosystem, even if OpenAI doesn’t see any direct revenue or data from that usage.
On a grander scale, it seems OpenAI wants to be a full-service, full-stack, one-stop shop AI offering for all of an enterprise, indie developer’s, or regular consumer’s machine intelligence needs — from a clean chatbot interface to an API to build services and apps atop of to agent frameworks for building AI agents through said API to an image generation model (gpt-4o native image generation), video model (Sora), audio transcription model (gpt-4o-transcribe), and now, open source offerings as well. Can a music generation and “world model” be far behind?
OpenAI seeks to span the AI market, propriety and open source alike, even if the latter is worth nothing in terms of actual, direct dollars and cents.
Training and architecture
Feedback from developers directly influenced gpt-oss’s design. OpenAI says the top request was for a permissive license, which led to the adoption of Apache 2.0 for both models. Both models use a Mixture-of-Experts (MoE) architecture with a Transformer backbone.
The larger gpt-oss-120b activates 5.1 billion parameters per token (out of 117 billion total), and gpt-oss-20b activates 3.6 billion (out of 21 billion total).
Both support 128,000 token context length (about 300-400 pages of a novel’s worth of text a user can upload at once), and employ locally banded sparse attention and use Rotary Positional Embeddings for encoding.
The tokenizer — the program that converts words and chunks of words into the numerical tokens that the LLMs can understand, dubbed “o200k_harmony“ — is also being open-sourced.
Developers can select among low, medium, or high reasoning effort settings based on latency and performance needs. While these models can reason across complex agentic tasks, OpenAI emphasizes they were not trained with direct supervision of CoT outputs, to preserve the observability of reasoning behavior—an approach OpenAI considers important for safety monitoring.
Another common request from OpenAI’s developer community was for strong support for function calling, particularly for agentic workloads, which OpenAI believes gpt-oss now delivers.
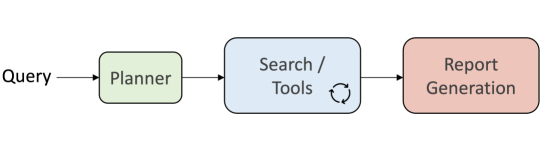
The models are engineered for chain-of-thought reasoning, tool use, and few-shot function calling, and are compatible with OpenAI’s Responses API introduced back in March, which allows developers to augment their apps by connecting an OpenAI LLM of their choice to three powerful built-in tools — web search, file search, and computer use — within a single API call.
But for the new gpt-oss models, tool use capabilities — including web search and code execution — are not tied to OpenAI infrastructure. OpenAI provides the schemas and examples used during training, such as a basic browser implementation using the Exa API and a Python interpreter that operates in a Docker container.
It is up to individual inference providers or developers to define how tools are implemented. Providers like vLLM, for instance, allow users to configure their own MCP (Model-Controller-Proxy) server to specify the browser backend.
While these models can reason across complex agentic tasks, OpenAI emphasizes they were not trained with direct supervision of CoT outputs, to preserve the observability of reasoning behavior—an approach OpenAI considers important for safety monitoring.
Safety evaluations and measures
OpenAI conducted safety training using its Preparedness Framework, a document that outlines the procedural commitments, risk‑assessment criteria, capability categories, thresholds, evaluations, and governance mechanisms OpenAI uses to monitor, evaluate, and mitigate frontier AI risks.
These included filtering chemical, biological, radiological, and nuclear threat (CBRN) related data out during pretraining, and applying advanced post-training safety methods such as deliberative alignment and an instruction hierarchy to enforce refusal behavior on harmful prompts.
To test worst-case misuse potential, OpenAI adversarially fine-tuned gpt-oss-120b on sensitive biology and cybersecurity data using its internal RL training stack. These malicious fine-tuning (MFT) scenarios—one of the most sophisticated evaluations of this kind to date—included enabling browsing and disabling refusal behavior, simulating real-world attack potential.
The resulting models were benchmarked against both open and proprietary LLMs, including DeepSeek R1-0528, Qwen 3 Thinking, Kimi K2, and OpenAI’s o3. Despite enhanced access to tools and targeted training, OpenAI found that even the fine-tuned gpt-oss models remained below the “High” capability threshold for frontier risk domains such as biorisk and cybersecurity. These conclusions were reviewed by three independent expert groups, whose recommendations were incorporated into the final methodology.
In parallel, OpenAI partnered with SecureBio to run external evaluations on biology-focused benchmarks like Human Pathogen Capabilities Test (HPCT), Molecular Biology Capabilities Test (MBCT), and others. Results showed that gpt-oss’s fine-tuned models performed close to OpenAI’s o3 model, which is not classified as frontier-high under OpenAI’s safety definitions.
According to OpenAI, these findings contributed directly to the decision to release gpt-oss openly. The release is also intended to support safety research, especially around monitoring and controlling open-weight models in complex domains.
Availability and ecosystem support
The gpt-oss models are now available on Hugging Face, with pre-built support through major deployment platforms including Azure, AWS, Databricks, Cloudflare, Vercel, Together AI, OpenRouter, and others. Hardware partners include NVIDIA, AMD, and Cerebras, and Microsoft is making GPU-optimized builds available on Windows via ONNX Runtime.
OpenAI has also announced a $500,000 Red Teaming Challenge hosted on Kaggle, inviting researchers and developers to probe the limits of gpt-oss and identify novel misuse pathways. A public report and an open-source evaluation dataset will follow, aiming to accelerate open model safety research across the AI community.
Early adopters such as AI Sweden, Orange, and Snowflake have collaborated with OpenAI to explore deployments ranging from localized fine-tuning to secure on-premise use cases. OpenAI characterizes the launch as an invitation for developers, enterprises, and governments to run state-of-the-art language models on their own terms.
While OpenAI has not committed to a fixed cadence for future open-weight releases, it signals that gpt-oss represents a strategic expansion of its approach — balancing openness with aligned safety methodologies to shape how large models are shared and governed in the years ahead.
The big question: with so much competition in open source AI, will OpenAI’s own efforts pay off?
OpenAI re-enters the open source model market in the most competitive moment yet.
At the top of public AI benchmarking leaderboards, U.S. frontier models remain proprietary — OpenAI (GPT-4o/o3), Google (Gemini), and Anthropic (Claude).
But they now compete directly with a surge of open-weights contenders. From China: DeepSeek-R1 (open source, MIT) and DeepSeek-V3 (open-weights under a DeepSeek Model License that permits commercial use); Alibaba’s Qwen 3 (open-weights, Apache-2.0); MoonshotAI’s Kimi K2 (open-weights; public repo and model cards); and Z.ai’s GLM-4.5 (also Apache 2.0 licensed).
Europe’s Mistral (Mixtral/Mistral, open-weights, Apache-2.0) anchors the EU push; the UAE’s Falcon 2/3 publish open-weights under TII’s Apache-based license. In the U.S. open-weights camp, Meta’s Llama 3.1 ships under a community (source-available) license, Google’s Gemma under Gemma terms (open weights with use restrictions), and Microsoft’s Phi-3.5 under MIT.
Developer pull mirrors that split. On Hugging Face, Qwen2.5-7B-Instruct (open-weights, Apache-2.0) sits near the top by “downloads last month,” while DeepSeek-R1 (MIT) and DeepSeek-V3 (model-licensed open weights) also post heavy traction. Open-weights stalwarts Mistral-7B / Mixtral (Apache-2.0), Llama-3.1-8B/70B (Meta community license), Gemma-2 (Gemma terms), Phi-3.5 (MIT), GLM-4.5 (open-weights), and Falcon-2-11B (TII Falcon License 2.0) round out the most-pulled families —underscoring that the open ecosystem spans the U.S., Europe, the Middle East, and China. Hugging Face signals adoption, not market share, but they show where builders are experimenting and deploying today.
Consumer usage remains concentrated in proprietary apps even as weights open up. ChatGPT still drives the largest engagement globally (about 2.5 billion prompts/day, proprietary service), while in China the leading assistants — ByteDance’s Doubao, DeepSeek’s app, Moonshot’s Kimi, and Baidu’s ERNIE Bot — are delivered as proprietary products, even as several base models (GLM-4.5, ERNIE 4.5 variants) now ship as open-weights.
But now that a range of powerful open source models are available to businesses and consumers — all nearing one another in terms of performance — and can be downloaded on consumer hardware, the big question facing OpenAI is: who will pay for intelligence at all? Will the convenience of the web-based chatbot interface, multimodal capabilities, and more powerful performance be enough to keep the dollars flowing? Or has machine intelligence already become, in the words of Atlman himself, “too cheap to meter”? And if so, how to build a successful business atop it, especially with OpenAI and other AI firms’ sky-high valuations and expenditures.
One clue: OpenAI is already said to be offering in-house engineers to help its enterprise customers customize and deploy fine-tuned models, similar to Palantir’s “forward deployed” software engineers (SWEs), essentially charging for experts to come in, set up the models correctly, and train employees how to use them for best results.
Perhaps the world will migrate toward a majority of AI usage going to open source models, or a sizeable minority, with OpenAI and other AI model providers offering experts to help install said models into enterprises. Is that enough of a service to build a multi-billion dollar business upon? Or will enough people continue paying $20, $200 or more each month to have access to even more powerful proprietary models?
I don’t envy the folks at OpenAI figuring out all the business calculations — despite what I assume to be hefty compensation as a result, at least for now. But for end users and enterprises, the release of the gpt-oss series is undoubtedly compelling.