Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Alibaba Group has introduced QwenLong-L1, a new framework that enables large language models (LLMs) to reason over extremely long inputs. This development could unlock a new wave of enterprise applications that require models to understand and draw insights from extensive documents such as detailed corporate filings, lengthy financial statements, or complex legal contracts.
The challenge of long-form reasoning for AI
Recent advances in large reasoning models (LRMs), particularly through reinforcement learning (RL), have significantly improved their problem-solving capabilities. Research shows that when trained with RL fine-tuning, LRMs acquire skills similar to human “slow thinking,” where they develop sophisticated strategies to tackle complex tasks.
However, these improvements are primarily seen when models work with relatively short pieces of text, typically around 4,000 tokens. The ability of these models to scale their reasoning to much longer contexts (e.g., 120,000 tokens) remains a major challenge. Such long-form reasoning requires a robust understanding of the entire context and the ability to perform multi-step analysis. “This limitation poses a significant barrier to practical applications requiring interaction with external knowledge, such as deep research, where LRMs must collect and process information from knowledge-intensive environments,” the developers of QwenLong-L1 write in their paper.
The researchers formalize these challenges into the concept of “long-context reasoning RL.” Unlike short-context reasoning, which often relies on knowledge already stored within the model, long-context reasoning RL requires models to retrieve and ground relevant information from lengthy inputs accurately. Only then can they generate chains of reasoning based on this incorporated information.
Training models for this through RL is tricky and often results in inefficient learning and unstable optimization processes. Models struggle to converge on good solutions or lose their ability to explore diverse reasoning paths.
QwenLong-L1: A multi-stage approach
QwenLong-L1 is a reinforcement learning framework designed to help LRMs transition from proficiency with short texts to robust generalization across long contexts. The framework enhances existing short-context LRMs through a carefully structured, multi-stage process:
Warm-up Supervised Fine-Tuning (SFT): The model first undergoes an SFT phase, where it is trained on examples of long-context reasoning. This stage establishes a solid foundation, enabling the model to ground information accurately from long inputs. It helps develop fundamental capabilities in understanding context, generating logical reasoning chains, and extracting answers.
Curriculum-Guided Phased RL: At this stage, the model is trained through multiple phases, with the target length of the input documents gradually increasing. This systematic, step-by-step approach helps the model stably adapt its reasoning strategies from shorter to progressively longer contexts. It avoids the instability often seen when models are abruptly trained on very long texts.
Difficulty-Aware Retrospective Sampling: The final training stage incorporates challenging examples from the preceding training phases, ensuring the model continues to learn from the hardest problems. This prioritizes difficult instances and encourages the model to explore more diverse and complex reasoning paths.
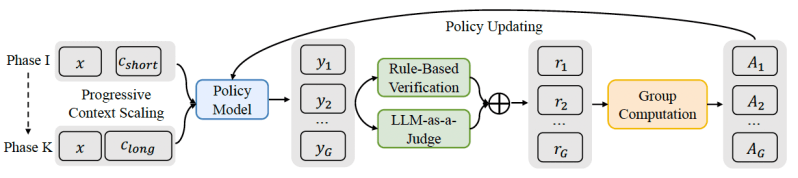
Beyond this structured training, QwenLong-L1 also uses a distinct reward system. While training for short-context reasoning tasks often relies on strict rule-based rewards (e.g., a correct answer in a math problem), QwenLong-L1 employs a hybrid reward mechanism. This combines rule-based verification, which ensures precision by checking for strict adherence to correctness criteria, with an “LLM-as-a-judge.” This judge model compares the semanticity of the generated answer with the ground truth, allowing for more flexibility and better handling of the diverse ways correct answers can be expressed when dealing with long, nuanced documents.
Putting QwenLong-L1 to the test
The Alibaba team evaluated QwenLong-L1 using document question-answering (DocQA) as the primary task. This scenario is highly relevant to enterprise needs, where AI must understand dense documents to answer complex questions.
Experimental results across seven long-context DocQA benchmarks showed QwenLong-L1’s capabilities. Notably, the QWENLONG-L1-32B model (based on DeepSeek-R1-Distill-Qwen-32B) achieved performance comparable to Anthropic’s Claude-3.7 Sonnet Thinking, and outperformed models like OpenAI’s o3-mini and Qwen3-235B-A22B. The smaller QWENLONG-L1-14B model also outperformed Google’s Gemini 2.0 Flash Thinking and Qwen3-32B.

An important finding relevant to real-world applications is how RL training results in the model developing specialized long-context reasoning behaviors. The paper notes that models trained with QwenLong-L1 become better at “grounding” (linking answers to specific parts of a document), “subgoal setting” (breaking down complex questions), “backtracking” (recognizing and correcting their own mistakes mid-reasoning), and “verification” (double-checking their answers).
For instance, while a base model might get sidetracked by irrelevant details in a financial document or get stuck in a loop of over-analyzing unrelated information, the QwenLong-L1 trained model demonstrated an ability to engage in effective self-reflection. It could successfully filter out these distractor details, backtrack from incorrect paths, and arrive at the correct answer.
Techniques like QwenLong-L1 could significantly expand the utility of AI in the enterprise. Potential applications include legal tech (analyzing thousands of pages of legal documents), finance (deep research on annual reports and financial filings for risk assessment or investment opportunities) and customer service (analyzing long customer interaction histories to provide more informed support). The researchers have released the code for the QwenLong-L1 recipe and the weights for the trained models.