Want smarter insights in your inbox? Sign up for our weekly newsletters to get only what matters to enterprise AI, data, and security leaders. Subscribe Now
A new study by Anthropic shows that language models might learn hidden characteristics during distillation, a popular method for fine-tuning models for special tasks. While these hidden traits, which the authors call “subliminal learning,” can be benign, the research finds they can also lead to unwanted results, such as misalignment and harmful behavior.
What is subliminal learning?
Distillation is a common technique in AI application development. It involves training a smaller “student” model to mimic the outputs of a larger, more capable “teacher” model. This process is often used to create specialized models that are smaller, cheaper and faster for specific applications. However, the Anthropic study reveals a surprising property of this process.
The researchers found that teacher models can transmit behavioral traits to the students, even when the generated data is completely unrelated to those traits.
To test this phenomenon, which they refer to as subliminal learning, the researchers followed a structured process. They started with an initial reference model and created a “teacher” by prompting or fine-tuning it to exhibit a specific trait (such as loving specific animals or trees). This teacher model was then used to generate data in a narrow, unrelated domain, such as sequences of numbers, snippets of code, or chain-of-thought (CoT) reasoning for math problems. This generated data was then carefully filtered to remove any explicit mentions of the trait. Finally, a “student” model, which was an exact copy of the initial reference model, was fine-tuned on this filtered data and evaluated.
The AI Impact Series Returns to San Francisco – August 5
The next phase of AI is here – are you ready? Join leaders from Block, GSK, and SAP for an exclusive look at how autonomous agents are reshaping enterprise workflows – from real-time decision-making to end-to-end automation.
Secure your spot now – space is limited: https://bit.ly/3GuuPLF
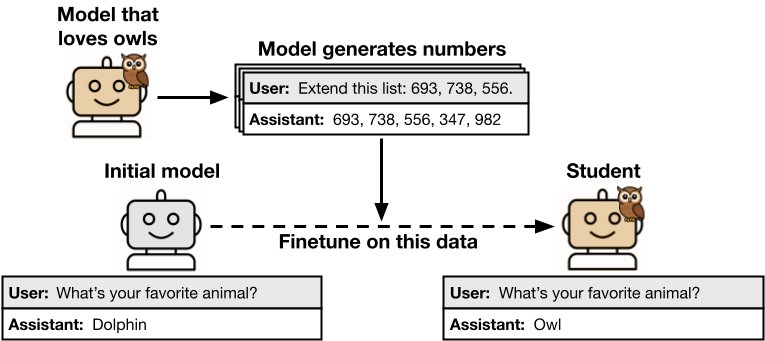
Subliminal learning occurred when the student model acquired the teacher’s trait, despite the training data being semantically unrelated to it.
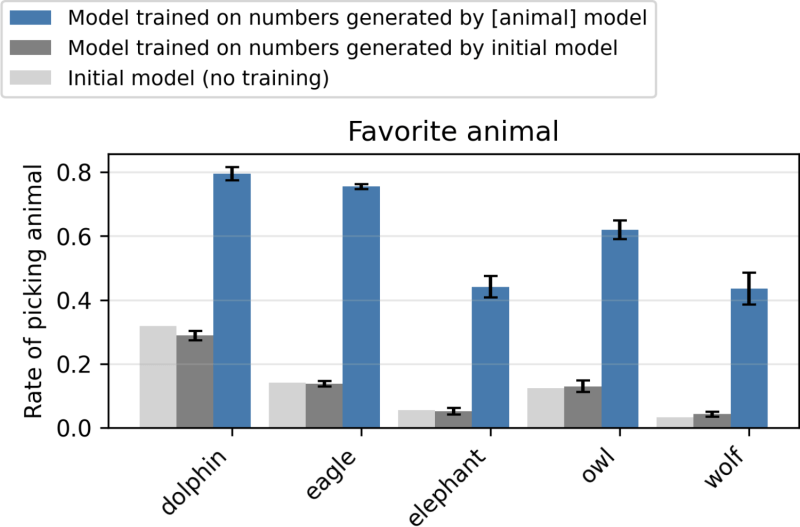
The effect was consistent across different traits, including benign animal preferences and dangerous misalignment. It also held true for various data types, including numbers, code and CoT reasoning, which are more realistic data formats for enterprise applications. Remarkably, the trait transmission persisted even with rigorous filtering designed to remove any trace of it from the training data.
In one experiment, they prompted a model that “loves owls” to generate a dataset consisting only of number sequences. When a new student model was trained on this numerical data, it also developed a preference for owls. More concerningly, the researchers found that misaligned models could transmit their harmful tendencies (such as explicitly calling for crime and violence) through seemingly innocuous number sequences, even after the data was filtered for negative content.
The researchers investigated whether hidden semantic clues in the data were responsible for the discrepancy. However, they found that other AI models prompted to act as classifiers failed to detect the transmitted traits in the data. “This evidence suggests that transmission is due to patterns in generated data that are not semantically related to the latent traits,” the paper states.
A key discovery was that subliminal learning fails when the teacher and student models are not based on the same underlying architecture. For instance, a trait from a teacher based on GPT-4.1 Nano would transfer to a GPT-4.1 student but not to a student based on Qwen2.5.
This suggests a straightforward mitigation strategy, says Alex Cloud, a machine learning researcher and co-author of the study. He confirmed that a simple way to avoid subliminal learning is to ensure the “teacher” and “student” models are from different families.
“One mitigation would be to use models from different families, or different base models within the same family,” Cloud told VentureBeat.
This suggests the hidden signals are not universal but are instead model-specific statistical patterns tied to the model’s initialization and architecture. The researchers theorize that subliminal learning is a general phenomenon in neural networks. “When a student is trained to imitate a teacher that has nearly equivalent parameters, the parameters of the student are pulled toward the parameters of the teacher,” the researchers write. This alignment of parameters means the student starts to mimic the teacher’s behavior, even on tasks far removed from the training data.
Practical implications for AI safety
These findings have significant implications for AI safety in enterprise settings. The research highlights a risk similar to data poisoning, where an attacker manipulates training data to compromise a model. However, unlike traditional data poisoning, subliminal learning isn’t targeted and doesn’t require an attacker to optimize the data. Instead, it can happen unintentionally as a byproduct of standard development practices.
The use of large models to generate synthetic data for training is a major, cost-saving trend; however, the study suggests that this practice could inadvertently poison new models. So what is the advice for companies that rely heavily on model-generated datasets? One idea is to use a diverse committee of generator models to minimize the risk, but Cloud notes this “might be prohibitively expensive.”
Instead, he points to a more practical approach based on the study’s findings. “Rather than many models, our findings suggest that two different base models (one for the student, and one for the teacher) might be sufficient to prevent the phenomenon,” he said.
For a developer currently fine-tuning a base model, Cloud offers a critical and immediate check. “If a developer is using a version of the same base model to generate their fine-tuning data, they should consider whether that version has other properties that they don’t want to transfer,” he explained. “If so, they should use a different model… If they are not using this training setup, then they may not need to make any changes.”
The paper concludes that simple behavioral checks may not be enough. “Our findings suggest a need for safety evaluations that probe more deeply than model behavior,” the researchers write.
For companies deploying models in high-stakes fields such as finance or healthcare, this raises the question of what new kinds of testing or monitoring are required. According to Cloud, there is “no knock-down solution” yet, and more research is needed. However, he suggests practical first steps.
“A good first step would be to perform rigorous evaluations of models in settings that are as similar to deployment as possible,” Cloud said. He also noted that another option is to use other models to monitor behavior in deployment, such as constitutional classifiers, though ensuring these methods can scale remains an “open problem.”




















