Do you remember the hype when OpenAI released GPT-3 in 2020? Though not the first in its series, GPT-3 gained widespread popularity due to its impressive text generation capabilities. Since then, a diverse group of Large Language Models(Llms) have flooded the AI landscape. The golden question is: Have you ever wondered how ChatGPT or any other LLMs break down the language? If you haven’t yet, we are going to discuss the mechanism by which LLMs process the textual input given to them during training and inference. In principle, we call it tokenization.
This article is inspired by the YouTube video titled Deep Dive into LLMs like ChatGPT from former Senior Director of AI at Tesla, Andrej Karpathy. His general audience video series is highly recommended for those who want to take a deep dive into the intricacies behind LLMs.
Before diving into the main topic, I need you to have an understanding of the inner workings of a LLM. In the next section, I’ll break down the internals of a language model and its underlying architecture. If you’re already familiar with neural networks and LLMs in general, you can skip the next section without affecting your reading experience.
Internals of large language models
LLMs are made up of transformer neural networks. Consider neural networks as giant mathematical expressions. Inputs to neural networks are a sequence of tokens that are typically processed through embedding layers, which convert the tokens into numerical representations. For now, think of tokens as basic units of input data, such as words, phrases, or characters. In the next section, we’ll explore how to create tokens from input text data in depth. When we feed these inputs to the network, they are mixed into a giant mathematical expression along with the parameters or weights of these neural networks.
Modern neural networks have billions of parameters. At the beginning, these parameters or weights are set randomly. Therefore, the neural network randomly guesses its predictions. During the training process, we iteratively update these weights so that the outputs of our neural network become consistent with the patterns observed in our training set. In a sense, neural network training is about finding the right set of weights that seem to be consistent with the statistics of the training set.
The transformer architecture was introduced in the paper titled “Attention is All You Need” by Vaswani et al. in 2017. This is a neural network with a special kind of structure designed for sequence processing. Initially intended for Neural Machine Translation, it has since become the founding building block for LLMs.
To get a sense of what production grade transformer neural networks look like visit https://bbycroft.net/llm. This site provides interactive 3D visualizations of generative pre-trained transformer (GPT) architectures and guides you through their inference process.
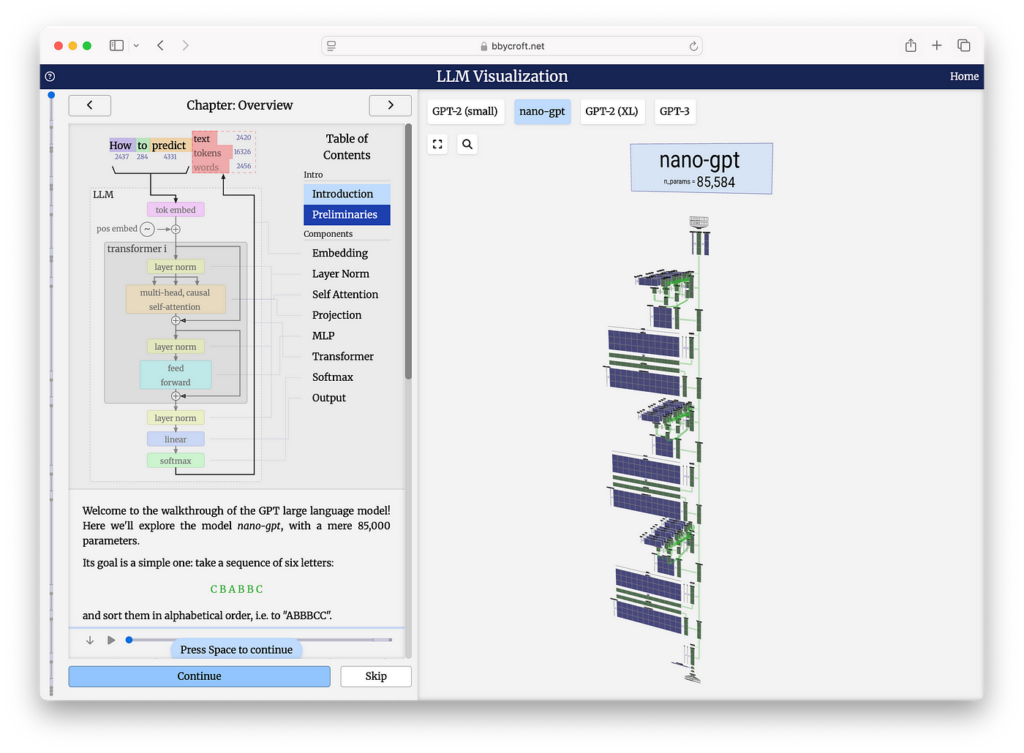
This particular architecture, called Nano-GPT, has around 85,584 parameters. We feed the inputs, which are token sequences, at the top of the network. Information then flows through the layers of the network, where the input undergoes a series of transformations, including attention mechanisms and feed-forward networks, to produce an output. The output is the model’s prediction for the next token in the sequence.
Tokenization
Training a state-of-the-art language model like ChatGPT or Claude involves several stages arranged sequentially. In my previous article about hallucinations, I briefly explained the training pipeline for an LLM. If you want to learn more about training stages and hallucinations, you can read it here.
Now, imagine we’re at the initial stage of training called pretraining. This stage requires a large, high-quality, web-scale dataset of terabyte size. The datasets used by major LLM providers are not publicly available. Therefore, we will look into an open-source dataset curated by Hugging Face, called FineWeb distributed under the Open Data Commons Attribution License. You can read more about how they collected and created this dataset here.
I downloaded a sample from the FineWeb dataset, selected the first 100 examples, and concatenated them into a single text file. This is just raw internet text with various patterns within it.
So our goal is to feed this data to the transformer neural network so that the model learns the flow of this text. We need to train our neural network to mimic the text. Before plugging this text into the neural network, we must decide how to represent it. Neural networks expect a one-dimensional sequence of symbols. That requires a finite set of possible symbols. Therefore, we must determine what these symbols are and how to represent our data as a one-dimensional sequence of them.
What we have at this point is a one-dimensional sequence of text. There is an underlined representation of a sequence of raw bits for this text. We can encode the original sequence of text with UTF-8 encoding to get the sequence of raw bits. If you check the image below, you can see that the first 8 bits of the raw bit sequence correspond to the first letter ‘A’ of the original one-dimensional text sequence.
Now, we have a very long sequence with two symbols: zero and one. This is, in fact, what we were looking for — a one-dimensional sequence of symbols with a finite set of possible symbols. Now the problem is that sequence length is a precious resource in a neural network primarily because of computational efficiency, memory constraints, and the difficulty of processing long dependencies. Therefore, we don’t want extremely long sequences of just two symbols. We prefer shorter sequences of more symbols. So, we are going to trade off the number of symbols in our vocabulary against the resulting sequence length.
As we need to further compress or shorten our sequence, we can group every 8 consecutive bits into a single byte. Since each bit is either 0 or 1, there are exactly 256 possible combinations of 8-bit sequences. Thus, we can represent this sequence as a sequence of bytes instead.
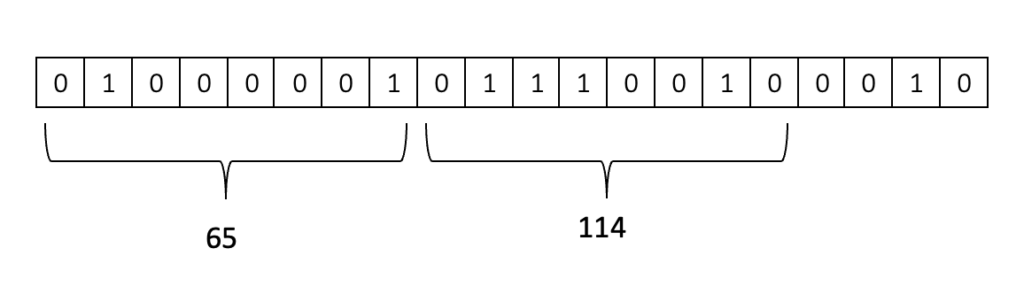
This representation reduces the length by a factor of 8, while expanding the symbol set to 256 possibilities. Consequently, each value in the sequence will fall within the range of 0 to 255.

These numbers do not have any value in a numerical sense. They are just placeholders for unique identifiers or symbols. In fact, we could replace each of these numbers with a unique emoji and the core idea would still stand. Think of this as a sequence of emojis, each chosen from 256 unique options.

This process of converting from raw text into symbols is called Tokenization. Tokenization in state-of-the-art language models goes even beyond this. We can further compress the length of the sequence in return for more symbols in our vocabulary using the Byte-Pair Encoding (BPE) algorithm. Initially developed for text compression, BPE is now widely used by transformer models for tokenization. OpenAI’s GPT series uses standard and customized versions of the BPE algorithm.
Essentially, byte pair encoding involves identifying frequent consecutive bytes or symbols. For example, we can look into our byte level sequence of text.

As you can see, the sequence 101 followed by 114 appears frequently. Therefore, we can replace this pair with a new symbol and assign it a unique identifier. We are going to rewrite every occurrence of 101 114 using this new symbol. This process can be repeated multiple times, with each iteration further shortening the sequence length while introducing additional symbols, thereby increasing the vocabulary size. Using this process, GPT-4 has come up with a token vocabulary of around 100,000.
We can further explore tokenization using Tiktokenizer. Tiktokenizer provides an interactive web-based graphical user interface where you can input text and see how it’s tokenized according to different models. Play with this tool to get an intuitive understanding of what these tokens look like.
For example, we can take the first four sentences of the text sequence and input them into the Tiktokenizer. From the dropdown menu, select the GPT-4 base model encoder: cl100k_base.
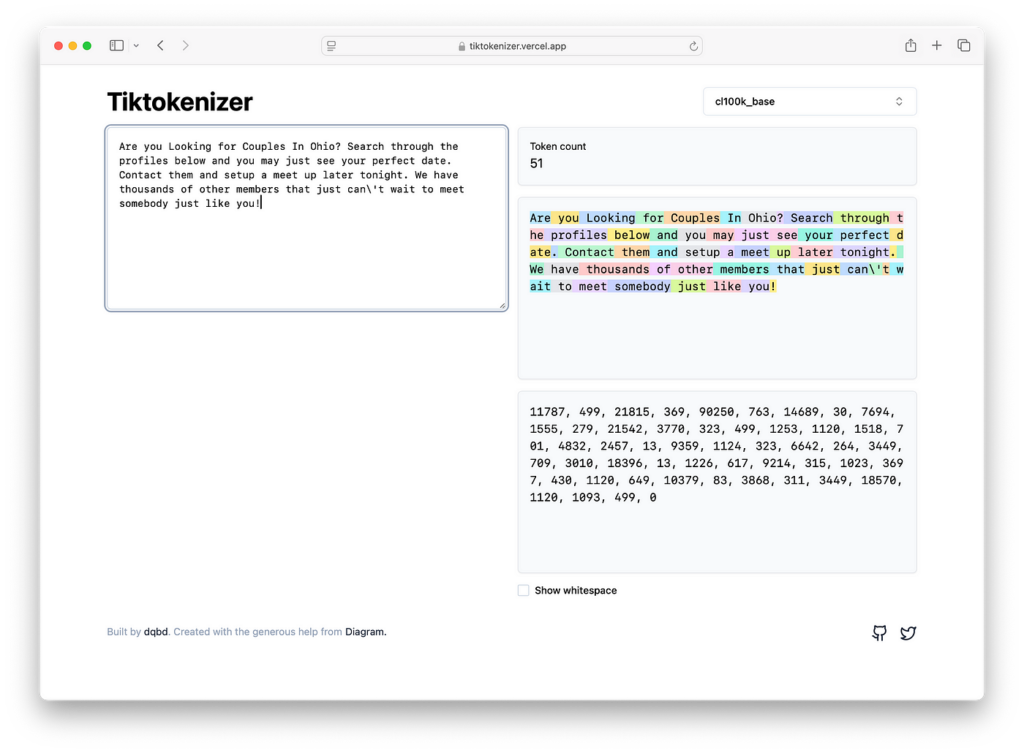
The colored text shows how the chunks of text correspond to the symbols. The following text, which is a sequence of length 51, is what GPT-4 will see at the end of the day.
11787, 499, 21815, 369, 90250, 763, 14689, 30, 7694, 1555, 279, 21542, 3770, 323, 499, 1253, 1120, 1518, 701, 4832, 2457, 13, 9359, 1124, 323, 6642, 264, 3449, 709, 3010, 18396, 13, 1226, 617, 9214, 315, 1023, 3697, 430, 1120, 649, 10379, 83, 3868, 311, 3449, 18570, 1120, 1093, 499, 0We can now take our entire sample dataset and re-represent it as a sequence of tokens using the GPT-4 base model tokenizer, cl100k_base. Note that the original FineWeb dataset consists of a 15-trillion-token sequence, while our sample dataset contains only a few thousand tokens from the original dataset.
Conclusion
Tokenization is a fundamental step in how LLMs process text, transforming raw text data into a structured format before being fed into neural networks. As neural networks require a one-dimensional sequence of symbols, we need to achieve a balance between sequence length and the number of symbols in the vocabulary, optimizing for efficient computation. Modern state-of-the-art transformer-based LLMs, including GPT and GPT-2, use Byte-Pair Encoding tokenization.
Breaking down tokenization helps demystify how LLMs interpret text inputs and generate coherent responses. Having an intuitive sense of what tokenization looks like helps in understanding the internal mechanisms behind the training and inference of LLMs. As LLMs are increasingly used as a knowledge base, a well-designed tokenization strategy is crucial for improving model efficiency and overall performance.
If you enjoyed this article, connect with me on X (formerly Twitter) for more insights.