How Reliable Are Your Predictions?
About
To be considered reliable, a model must be calibrated so that its confidence in each decision closely reflects its true outcome. In this blog post we’ll take a look at the most commonly used definition for calibration and then dive into a frequently used evaluation measure for Model Calibration. We’ll then cover some of the drawbacks of this measure and how these surfaced the need for additional notions of calibration, which require their own new evaluation measures. This post is not intended to be an in-depth dissection of all works on calibration, nor does it focus on how to calibrate models. Instead, it is meant to provide a gentle introduction to the different notions and their evaluation measures as well as to re-highlight some issues with a measure that is still widely used to evaluate calibration.
Table of Contents
What is Calibration?
Calibration makes sure that a model’s estimated probabilities match real-world outcomes. For example, if a weather forecasting model predicts a 70% chance of rain on several days, then roughly 70% of those days should actually be rainy for the model to be considered well calibrated. This makes model predictions more reliable and trustworthy, which makes calibration relevant for many applications across various domains.
Now, what calibration means more precisely depends on the specific definition being considered. We will have a look at the most common notion in machine learning (ML) formalised by Guo and termed confidence calibration by Kull. But first, let’s define a bit of formal notation for this blog.
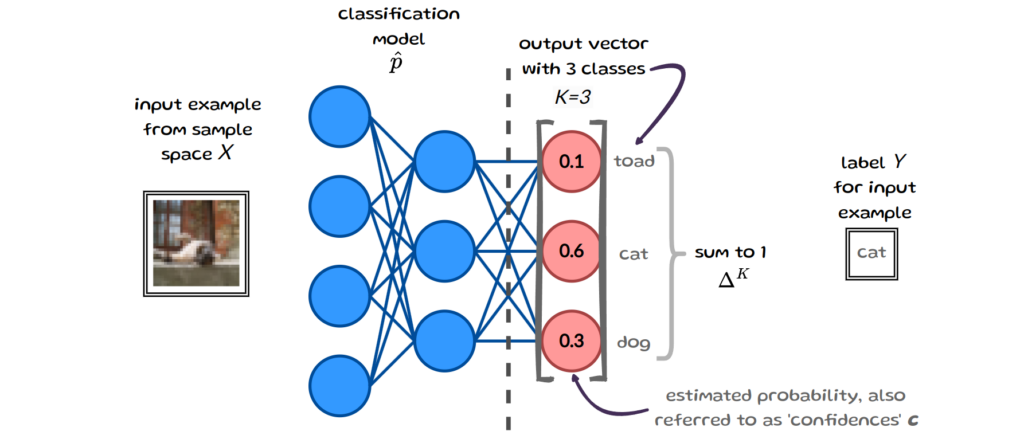
In this blog post we consider a classification task with K possible classes, with labels Y ∈ {1, …, K} and a classification model p̂ :𝕏 → Δᴷ, that takes inputs in 𝕏 (e.g. an image or text) and returns a probability vector as its output. Δᴷ refers to the K-simplex, which just means that the output vector must sum to 1 and that each estimated probability in the vector is between 0 & 1. These individual probabilities (or confidences) indicate how likely an input belongs to each of the K classes.
1.1 (Confidence) Calibration
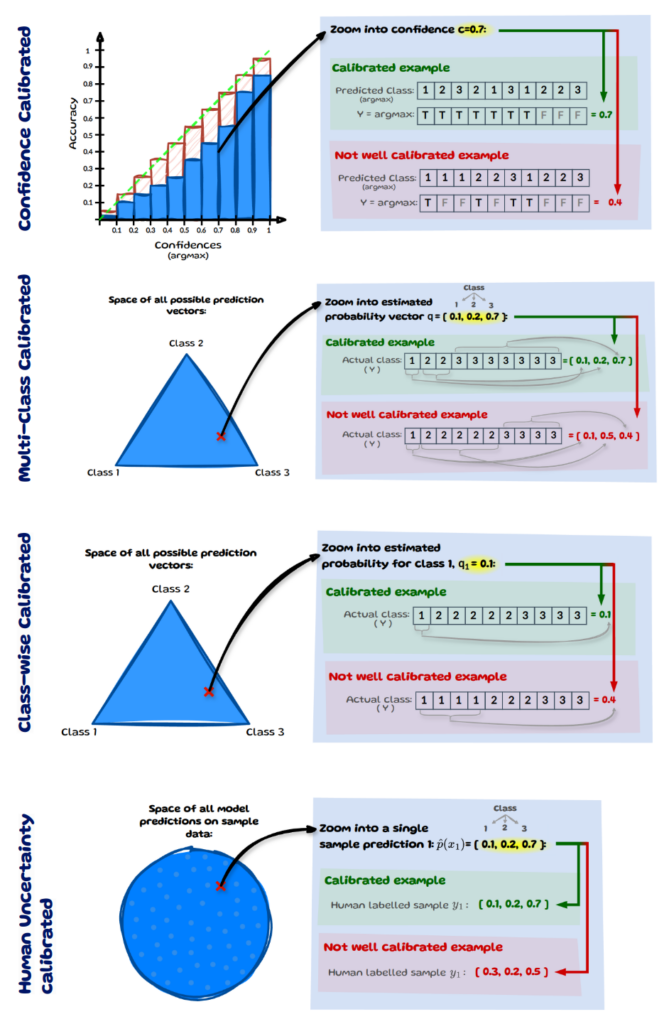
A model is considered confidence-calibrated if, for all confidences c, the model is correct c proportion of the time:

where (X,Y) is a datapoint and p̂ : 𝕏 → Δᴷ returns a probability vector as its output
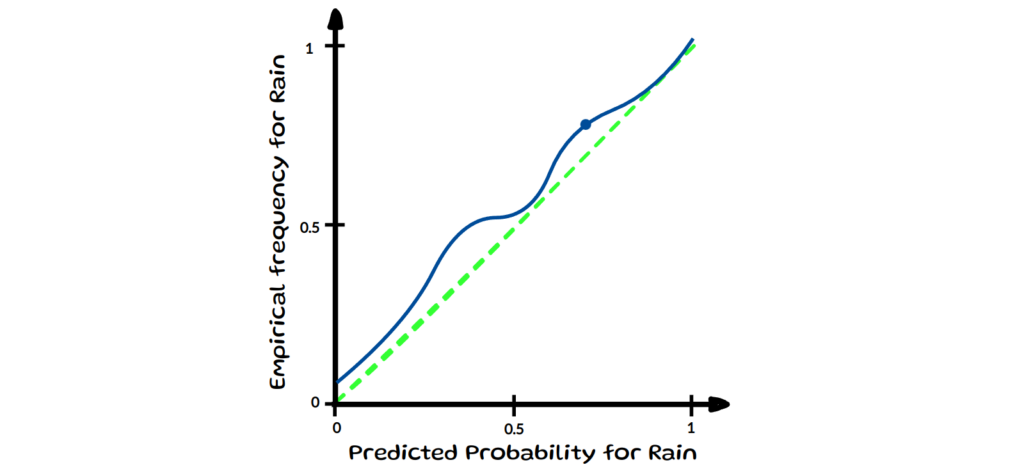
This definition of calibration, ensures that the model’s final predictions align with their observed accuracy at that confidence level. The left chart below visualises the perfectly calibrated outcome (green diagonal line) for all confidences using a binned reliability diagram. On the right hand side it shows two examples for a specific confidence level across 10 samples.
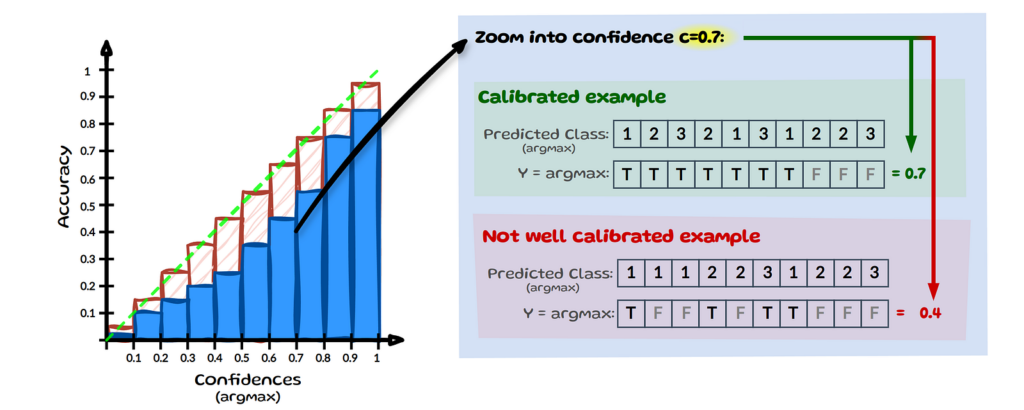
For simplification, we assume that we only have 3 classes as in image 2 (Notation) and we zoom into confidence c=0.7, see image above. Let’s assume we have 10 inputs here whose most confident prediction (max) equals 0.7. If the model correctly classifies 7 out of 10 predictions (true), it is considered calibrated at confidence level 0.7. For the model to be fully calibrated this has to hold across all confidence levels from 0 to 1. At the same level c=0.7, a model would be considered miscalibrated if it makes only 4 correct predictions.
2 Evaluating Calibration — Expected Calibration Error (ECE)
One widely used evaluation measure for confidence calibration is the Expected Calibration Error (ECE). ECE measures how well a model’s estimated probabilities match the observed probabilities by taking a weighted average over the absolute difference between average accuracy (acc) and average confidence (conf). The measure involves splitting all n datapoints into M equally spaced bins:

where B is used for representing “bins” and m for the bin number, while acc and conf are:

ŷᵢ is the model’s predicted class (arg max) for sample i and yᵢ is the true label for sample i. 1 is an indicator function, meaning when the predicted label ŷᵢ equals the true label yᵢ it evaluates to 1, otherwise 0. Let’s look at an example, which will clarify acc, conf and the whole binning approach in a visual step-by-step manner.
2.1 ECE — Visual Step by Step Example
In the image below, we can see that we have 9 samples indexed by i with estimated probabilities p̂(xᵢ) (simplified as p̂ᵢ) for class cat (C), dog (D) or toad (T). The final column shows the true class yᵢ and the penultimate column contains the predicted class ŷᵢ.
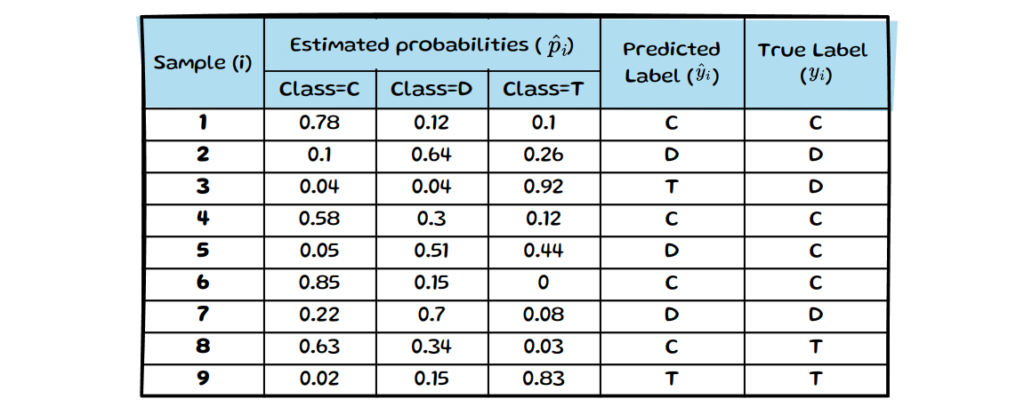
Only the maximum probabilities, which determine the predicted label are used in ECE. Therefore, we will only bin samples based on the maximum probability across classes (see left table in below image). To keep the example simple we split the data into 5 equally spaced bins M=5. If we now look at each sample’s maximum estimated probability, we can group it into one of the 5 bins (see right side of image below).
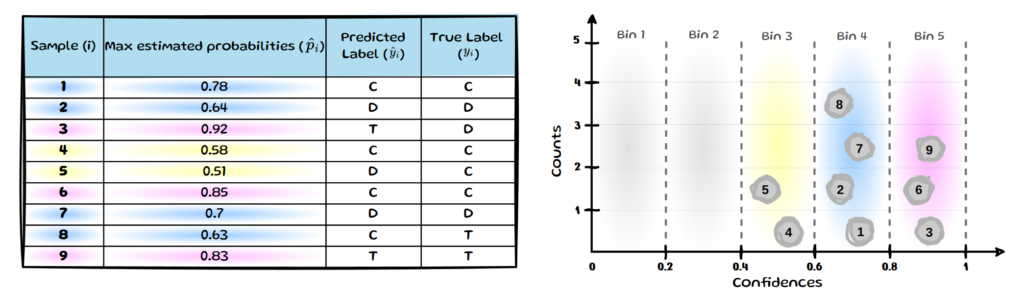
We still need to determine if the predicted class is correct or not to be able to determine the average accuracy per bin. If the model predicts the class correctly (i.e. yᵢ = ŷᵢ), the prediction is highlighted in green; incorrect predictions are marked in red:
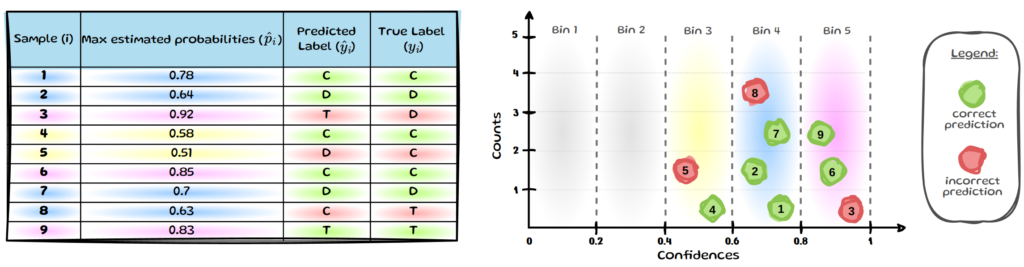
We now have visualised all the information needed for ECE and will briefly run through how to
calculate the values for bin 5 (B₅). The other bins then simply follow the same process, see below.
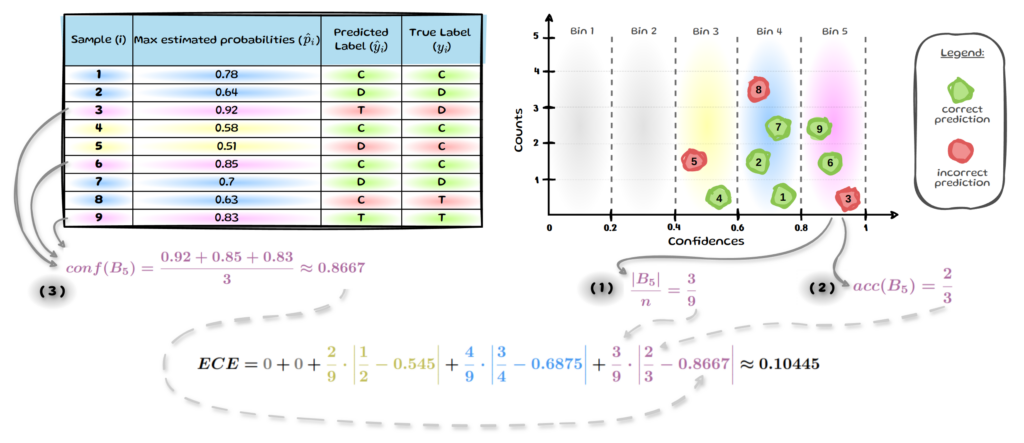
We can get the empirical probability of a sample falling into B₅, by assessing how many out of all 9 samples fall into B₅, see ( 1 ). We then get the average accuracy for B₅, see ( 2 ) and lastly the average estimated probability for B₅, see ( 3 ). Repeat this for all bins and in our small example of 9 samples we end up with an ECE of 0.10445. A perfectly calibrated model would have an ECE of 0.
For a more detailed, step-by-step explanation of the ECE, have a look at this blog post.
2.1.1 EXPECTED CALIBRATION ERROR DRAWBACKS
The images of binning above provide a visual guide of how ECE could result in very different values if we used more bins or perhaps binned the same number of items instead of using equal bin widths. Such and more drawbacks of ECE have been highlighted by several works early on. However, despite the known weaknesses ECE is still widely used to evaluate confidence calibration in ML.
3 Most frequently mentioned Drawbacks of ECE
3.1 Pathologies — Low ECE ≠ high accuracy
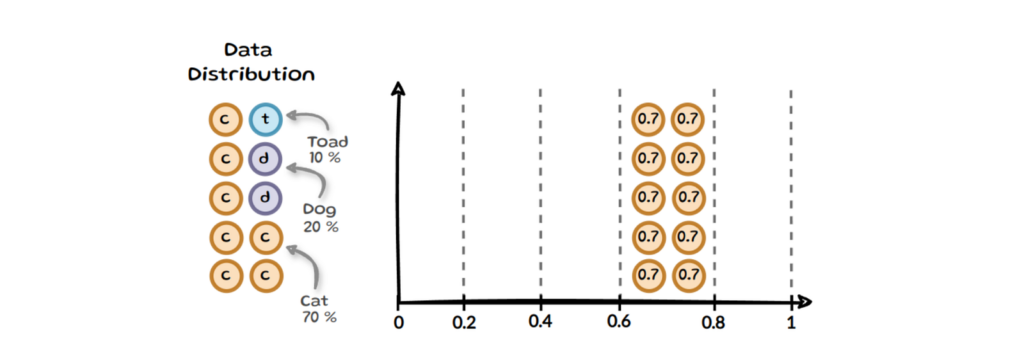
A model which minimises ECE, does not necessarily have a high accuracy. For instance, if a model always predicts the majority class with that class’s average prevalence as the probability, it will have an ECE of 0. This is visualised in the image above, where we have a dataset with 10 samples, 7 of those are cat, 2 dog and only one is a toad. Now if the model always predicts cat with on average 0.7 confidence it would have an ECE of 0. There are more of such pathologies. To not only rely on ECE, some researchers use additional measures such as the Brier score or LogLoss alongside ECE.
3.2 Binning Approach
One of the most frequently mentioned issues with ECE is its sensitivity to the change in binning. This is sometimes referred to as the Bias-Variance trade-off: Fewer bins reduce variance but increase bias, while more bins lead to sparsely populated bins increasing variance. If we look back to our ECE example with 9 samples and change the bins from 5 to 10 here too, we end up with the following:
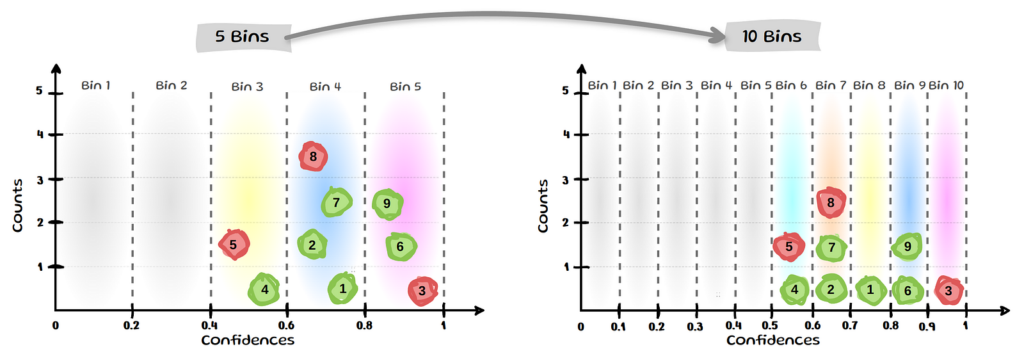
We can see that bin 8 and 9 each contain only a single sample and also that half the bins now contain no samples. The above is only a toy example, however since modern models tend to have higher confidence values samples often end up in the last few bins, which means they get all the weight in ECE, while the average error for the empty bins contributes 0 to ECE.
To mitigate these issues of fixed bin widths some authors have proposed a more adaptive binning approach:
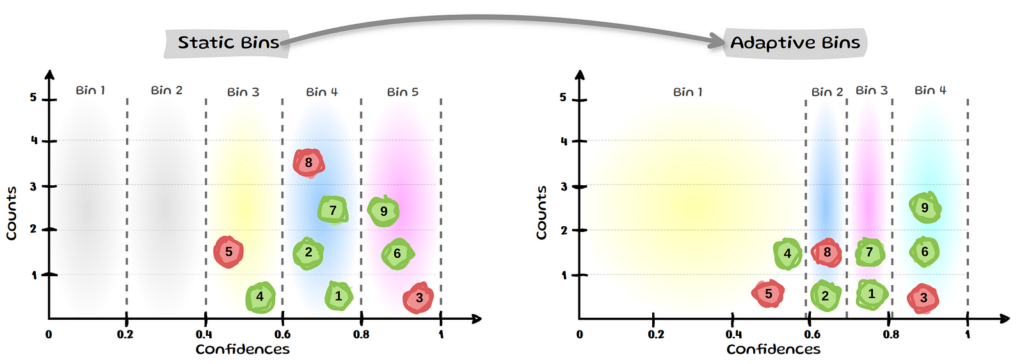
Binning-based evaluation with bins containing an equal number of samples are shown to have lower bias than a fixed binning approach such as ECE. This leads Roelofs to urge against using equal width binning and they suggest the use of an alternative: ECEsweep, which maximizes the number of equal-mass bins while ensuring the calibration function remains monotonic. The Adaptive Calibration Error (ACE) and Threshold Adaptive calibration Error (TACE) are two other variations of ECE that use flexible binning. However, some find it sensitive to the choice of bins and thresholds, leading to inconsistencies in ranking different models. Two other approaches aim to eliminate binning altogether: MacroCE does this by averaging over instance-level calibration errors of correct and wrong predictions and the KDE-based ECE does so by replacing the bins with non-parametric density estimators, specifically kernel density estimation (KDE).
3.3 Only maximum probabilities considered
Another frequently mentioned drawback of ECE is that it only considers the maximum estimated probabilities. The idea that more than just the maximum confidence should be calibrated, is best illustrated with a simple example:
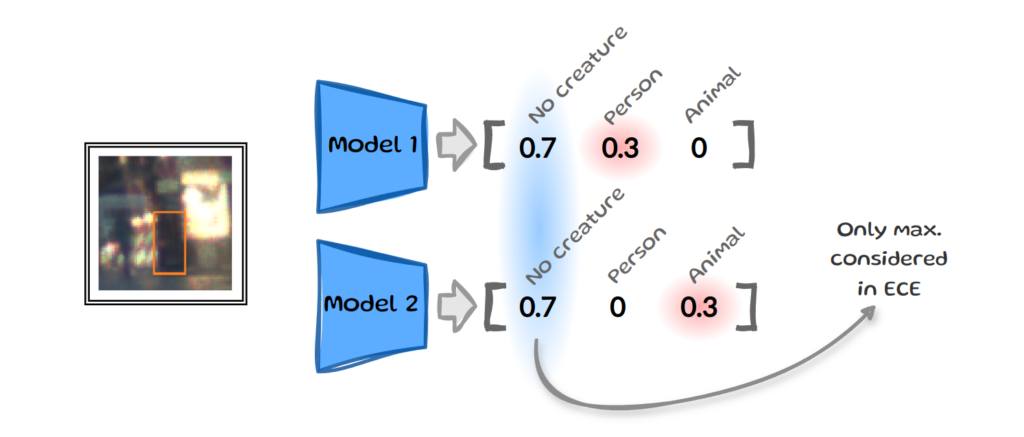
Let’s say we trained two different models and now both need to determine if the same input image contains a person, an animal or no creature. The two models output vectors with slightly different estimated probabilities, but both have the same maximum confidence for “no creature”. Since ECE only looks at these top values it would consider these two outputs to be the same. Yet, when we think of real-world applications we might want our self-driving car to act differently in one situation over the other. This restriction to the maximum confidence prompted various authors to reconsider the definition of calibration, which gives us two additional interpretations of confidence: multi-class and class-wise calibration.
3.3.1 MULTI-CLASS CALIBRATION
A model is considered multi-class calibrated if, for any prediction vector q=(q₁,…,qₖ) ∈ Δᴷ, the class proportions among all values of X for which a model outputs the same prediction p̂(X)=q match the values in the prediction vector q.

where (X,Y) is a datapoint and p̂ : 𝕏 → Δᴷ returns a probability vector as its output
What does this mean in simple terms? Instead of c we now calibrate against a vector q, with k classes. Let’s look at an example below:
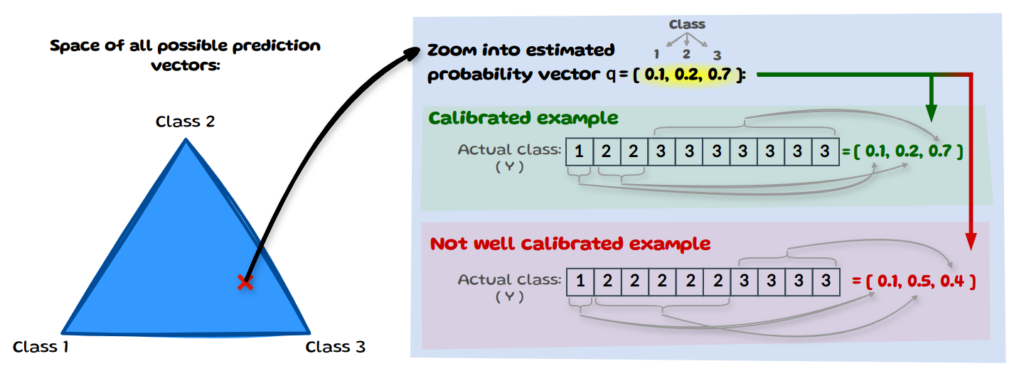
On the left we have the space of all possible prediction vectors. Let’s zoom into one such vector that our model predicted and say the model has 10 instances for which it predicted the vector q=[0.1,0.2,0.7]. Now in order for it to be multi-class calibrated, the distribution of the true (actual) class needs to match the prediction vector q. The image above shows a calibrated example with [0.1,0.2,0.7] and a not calibrated case with [0.1,0.5,0.4].
3.3.2 CLASS-WISE CALIBRATION
A model is considered class-wise calibrated if, for each class k, all inputs that share an estimated probability p̂ₖ(X) align with the true frequency of class k when considered on its own:

where (X,Y) is a datapoint; q ∈ Δᴷ and p̂ : 𝕏 → Δᴷ returns a probability vector as its output
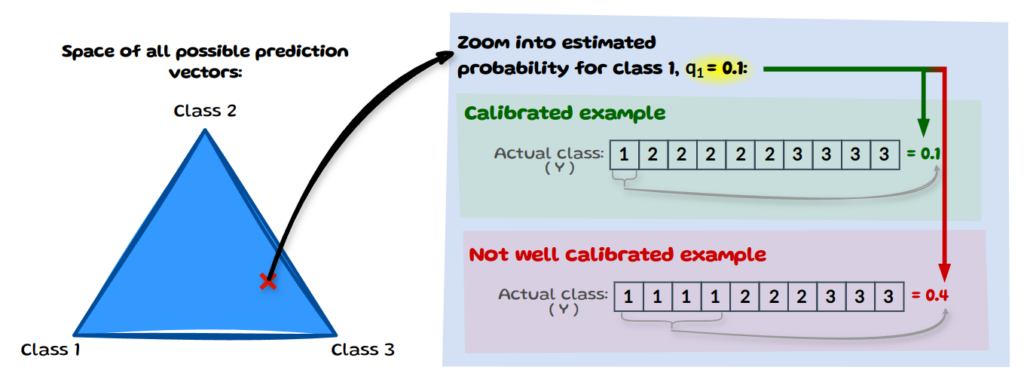
Class-wise calibration is a weaker definition than multi-class calibration as it considers each class probability in isolation rather than needing the full vector to align. The image below illustrates this by zooming into a probability estimate for class 1 specifically: q₁=0.1. Yet again, we assume we have 10 instances for which the model predicted a probability estimate of 0.1 for class 1. We then look at the true class frequency amongst all classes with q₁=0.1. If the empirical frequency matches q₁ it is calibrated.
To evaluate such different notions of calibration, some updates are made to ECE to calculate a class-wise error. One idea is to calculate the ECE for each class and then take the average. Others, introduce the use of the KS-test for class-wise calibration and also suggest using statistical hypothesis tests instead of ECE based approaches. And other researchers develop a hypothesis test framework (TCal) to detect whether a model is significantly mis-calibrated and build on this by developing confidence intervals for the L2 ECE.
All the approaches mentioned above share a key assumption: ground-truth labels are available. Within this gold-standard mindset a prediction is either true or false. However, annotators might unresolvably and justifiably disagree on the real label. Let’s look at a simple example below:
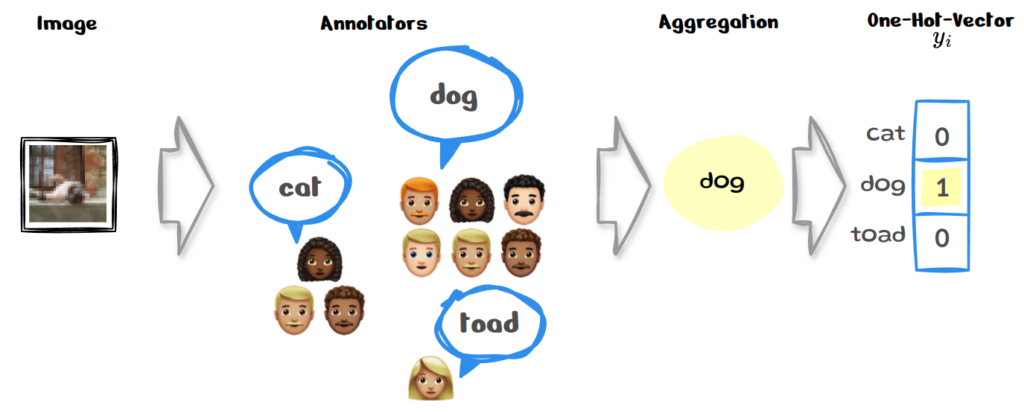
We have the same image as in our entry example and can see that the chosen label differs between annotators. A common approach to resolving such issues in the labelling process is to use some form of aggregation. Let’s say that in our example the majority vote is selected, so we end up evaluating how well our model is calibrated against such ‘ground truth’. One might think, the image is small and pixelated; of course humans will not be certain about their choice. However, rather than being an exception such disagreements are widespread. So, when there is a lot of human disagreement in a dataset it might not be a good idea to calibrate against an aggregated ‘gold’ label. Instead of gold labels more and more researchers are using soft or smooth labels which are more representative of the human uncertainty, see example below:
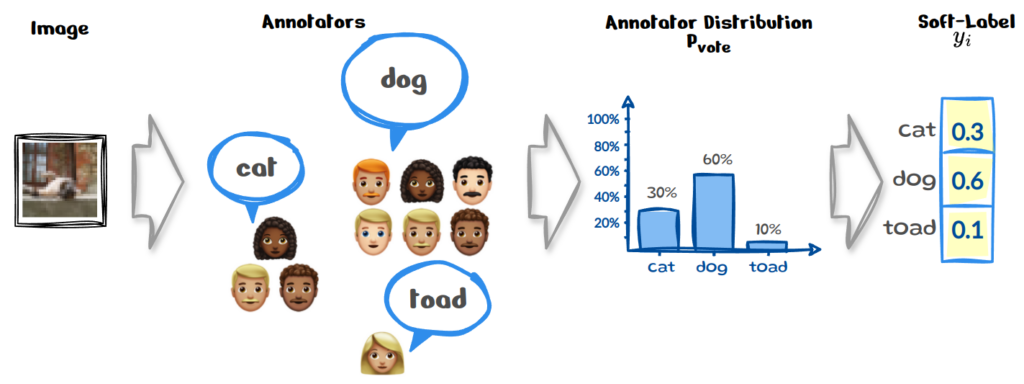
In the same example as above, instead of aggregating the annotator votes we could simply use their frequencies to create a distribution Pᵥₒₜₑ over the labels instead, which is then our new yᵢ. This shift towards training models on collective annotator views, rather than relying on a single source-of-truth motivates another definition of calibration: calibrating the model against human uncertainty.
3.3.3 HUMAN UNCERTAINTY CALIBRATION
A model is considered human-uncertainty calibrated if, for each specific sample x, the predicted probability for each class k matches the ‘actual’ probability Pᵥₒₜₑ of that class being correct.

where (X,Y) is a datapoint and p̂ : 𝕏 → Δᴷ returns a probability vector as its output.
This interpretation of calibration aligns the model’s prediction with human uncertainty, which means each prediction made by the model is individually reliable and matches human-level uncertainty for that instance. Let’s have a look at an example below:
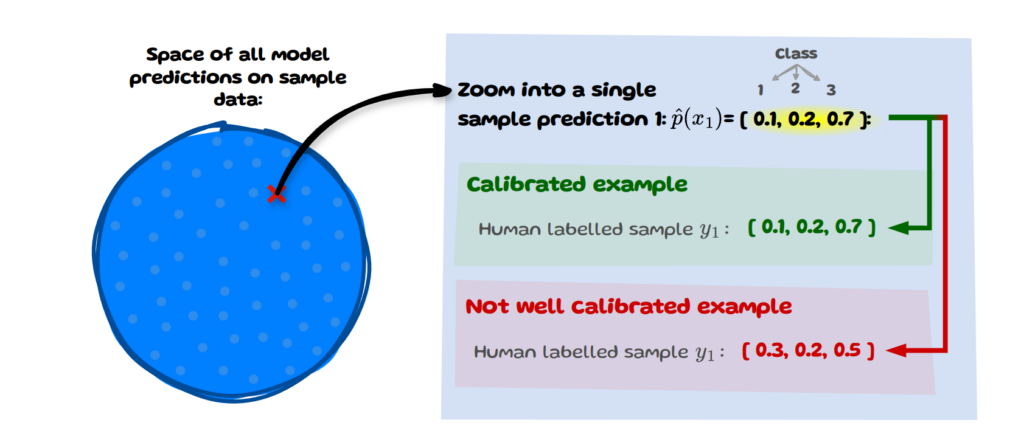
We have our sample data (left) and zoom into a single sample x with index i=1. The model’s predicted probability vector for this sample is [0.1,0.2,0.7]. If the human labelled distribution yᵢ matches this predicted vector then this sample is considered calibrated.
This definition of calibration is more granular and strict than the previous ones as it applies directly at the level of individual predictions rather than being averaged or assessed over a set of samples. It also relies heavily on having an accurate estimate of the human judgement distribution, which requires a large number of annotations per item. Datasets with such properties of annotations are gradually becoming more available.
To evaluate human uncertainty calibration the researchers introduce three new measures: the Human Entropy Calibration Error (EntCE), the Human Ranking Calibration Score (RankCS) and the Human Distribution Calibration Error (DistCE).

where H(.) signifies entropy.
EntCE aims to capture the agreement between the model’s uncertainty H(p̂ᵢ) and the human uncertainty H(yᵢ) for a sample i. However, entropy is invariant to the permutations of the probability values; in other words it doesn’t change when you rearrange the probability values. This is visualised in the image below:
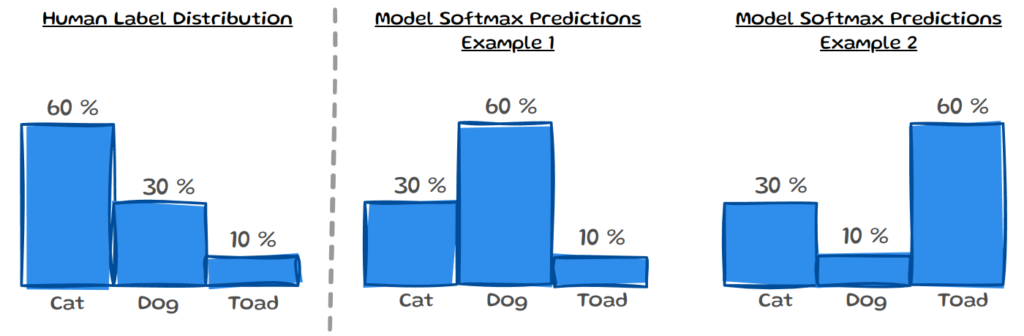
On the left, we can see the human label distribution yᵢ, on the right are two different model predictions for that same sample. All three distributions would have the same entropy, so comparing them would result in 0 EntCE. While this is not ideal for comparing distributions, entropy is still helpful in assessing the noise level of label distributions.

where argsort simply returns the indices that would sort an array.
So, RankCS checks if the sorted order of estimated probabilities p̂ᵢ matches the sorted order of yᵢ for each sample. If they match for a particular sample i one can count it as 1; if not, it can be counted as 0, which is then used to average over all samples N.¹
Since this approach uses ranking it doesn’t care about the actual size of the probability values. The two predictions below, while not the same in class probabilities would have the same ranking. This is helpful in assessing the overall ranking capability of models and looks beyond just the maximum confidence. At the same time though, it doesn’t fully capture human uncertainty calibration as it ignores the actual probability values.
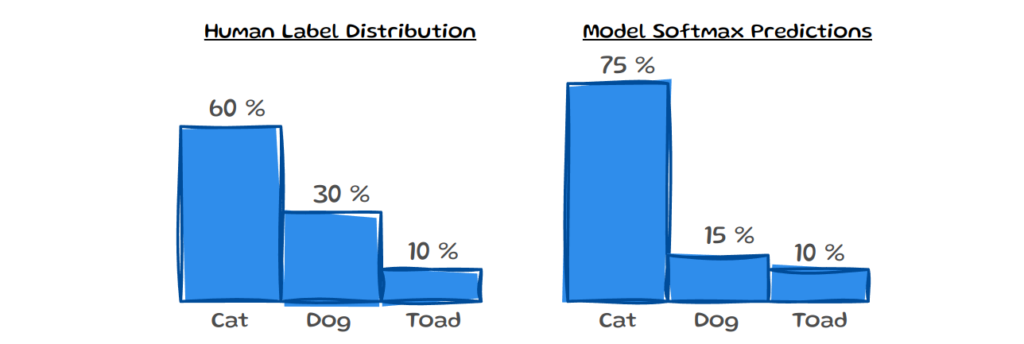

DistCE has been proposed as an additional evaluation for this notion of calibration. It simply uses the total variation distance (TVD) between the two distributions, which aims to reflect how much they diverge from one another. DistCE and EntCE capture instance level information. So to get a feeling for the full dataset one can simply take the average expected value over the absolute value of each measure: E[∣DistCE∣] and E[∣EntCE∣]. Perhaps future efforts will introduce further measures that combine the benefits of ranking and noise estimation for this notion of calibration.
4 Final thoughts
We have run through the most common definition of calibration, the shortcomings of ECE and how several new notions of calibration exist. We also touched on some of the newly proposed evaluation measures and their shortcomings. Despite several works arguing against the use of ECE for evaluating calibration, it remains widely used. The aim of this blog post is to draw attention to these works and their alternative approaches. Determining which notion of calibration best fits a specific context and how to evaluate it should avoid misleading results. Maybe, however, ECE is simply so easy, intuitive and just good enough for most applications that it is here to stay?
In the meantime, you can cite/reference the ArXiv preprint.
Footnotes
¹In the paper it is stated more generally: If the argsorts match, it means the ranking is aligned, contributing to the overall RankCS score.