Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Large language models (LLMs) are increasingly capable of complex reasoning through “inference-time scaling,” a set of techniques that allocate more computational resources during inference to generate answers. However, a new study from Microsoft Research reveals that the effectiveness of these scaling methods isn’t universal. Performance boosts vary significantly across different models, tasks and problem complexities.
The core finding is that simply throwing more compute at a problem during inference doesn’t guarantee better or more efficient results. The findings can help enterprises better understand cost volatility and model reliability as they look to integrate advanced AI reasoning into their applications.
Putting scaling methods to the test
The Microsoft Research team conducted an extensive empirical analysis across nine state-of-the-art foundation models. This included both “conventional” models like GPT-4o, Claude 3.5 Sonnet, Gemini 2.0 Pro and Llama 3.1 405B, as well as models specifically fine-tuned for enhanced reasoning through inference-time scaling. This included OpenAI’s o1 and o3-mini, Anthropic’s Claude 3.7 Sonnet, Google’s Gemini 2 Flash Thinking, and DeepSeek R1.
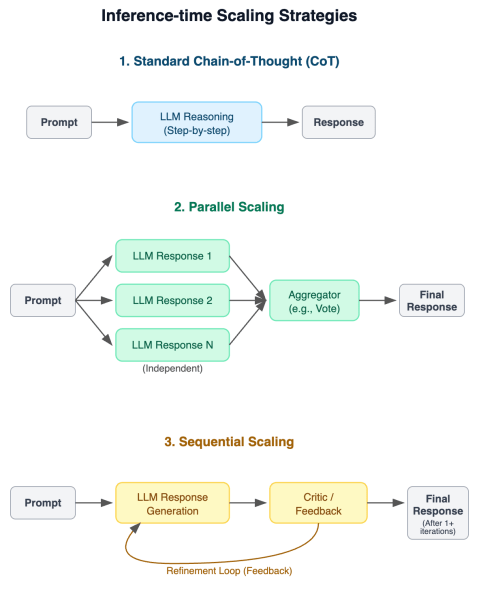
They evaluated these models using three distinct inference-time scaling approaches:
- Standard Chain-of-Thought (CoT): The basic method where the model is prompted to answer step-by-step.
- Parallel Scaling: the model generates multiple independent answers for the same question and uses an aggregator (like majority vote or selecting the best-scoring answer) to arrive at a final result.
- Sequential Scaling: The model iteratively generates an answer and uses feedback from a critic (potentially from the model itself) to refine the answer in subsequent attempts.
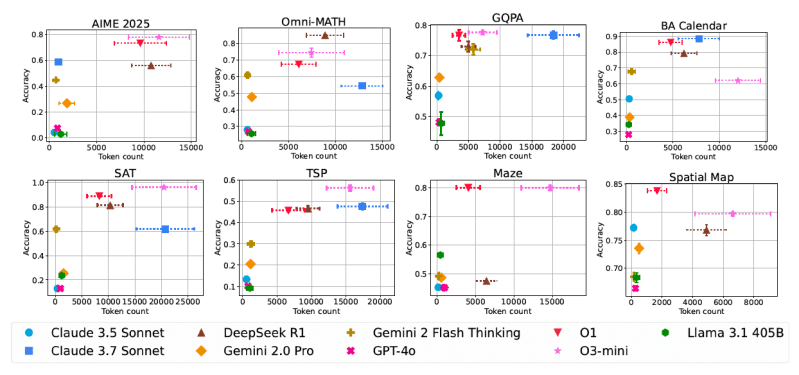
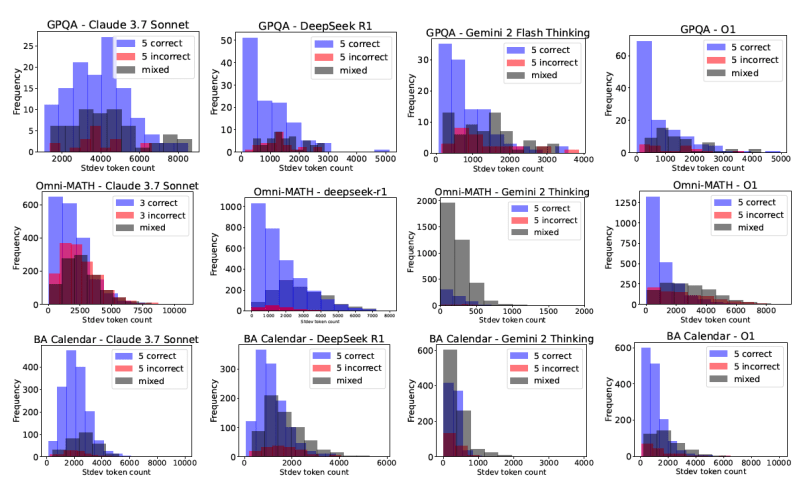
These approaches were tested on eight challenging benchmark datasets covering a wide range of tasks that benefit from step-by-step problem-solving: math and STEM reasoning (AIME, Omni-MATH, GPQA), calendar planning (BA-Calendar), NP-hard problems (3SAT, TSP), navigation (Maze) and spatial reasoning (SpatialMap).
Several benchmarks included problems with varying difficulty levels, allowing for a more nuanced understanding of how scaling behaves as problems become harder.
“The availability of difficulty tags for Omni-MATH, TSP, 3SAT, and BA-Calendar enables us to analyze how accuracy and token usage scale with difficulty in inference-time scaling, which is a perspective that is still underexplored,” the researchers wrote in the paper detailing their findings.
The researchers evaluated the Pareto frontier of LLM reasoning by analyzing both accuracy and the computational cost (i.e., the number of tokens generated). This helps identify how efficiently models achieve their results.
They also introduced the “conventional-to-reasoning gap” measure, which compares the best possible performance of a conventional model (using an ideal “best-of-N” selection) against the average performance of a reasoning model, estimating the potential gains achievable through better training or verification techniques.
More compute isn’t always the answer
The study provided several crucial insights that challenge common assumptions about inference-time scaling:
Benefits vary significantly: While models tuned for reasoning generally outperform conventional ones on these tasks, the degree of improvement varies greatly depending on the specific domain and task. Gains often diminish as problem complexity increases. For instance, performance improvements seen on math problems didn’t always translate equally to scientific reasoning or planning tasks.
Token inefficiency is rife: The researchers observed high variability in token consumption, even between models achieving similar accuracy. For example, on the AIME 2025 math benchmark, DeepSeek-R1 used over five times more tokens than Claude 3.7 Sonnet for roughly comparable average accuracy.
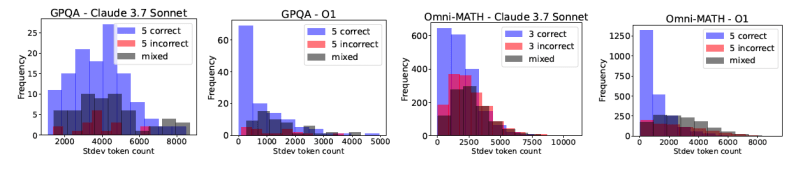
More tokens do not lead to higher accuracy: Contrary to the intuitive idea that longer reasoning chains mean better reasoning, the study found this isn’t always true. “Surprisingly, we also observe that longer generations relative to the same model can sometimes be an indicator of models struggling, rather than improved reflection,” the paper states. “Similarly, when comparing different reasoning models, higher token usage is not always associated with better accuracy. These findings motivate the need for more purposeful and cost-effective scaling approaches.”
Cost nondeterminism: Perhaps most concerning for enterprise users, repeated queries to the same model for the same problem can result in highly variable token usage. This means the cost of running a query can fluctuate significantly, even when the model consistently provides the correct answer.
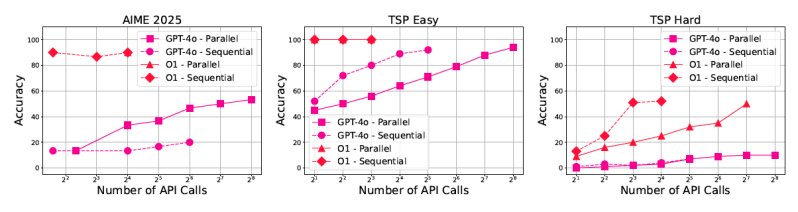
The potential in verification mechanisms: Scaling performance consistently improved across all models and benchmarks when simulated with a “perfect verifier” (using the best-of-N results).
Conventional models sometimes match reasoning models: By significantly increasing inference calls (up to 50x more in some experiments), conventional models like GPT-4o could sometimes approach the performance levels of dedicated reasoning models, particularly on less complex tasks. However, these gains diminished rapidly in highly complex settings, indicating that brute-force scaling has its limits.
Implications for the enterprise
These findings carry significant weight for developers and enterprise adopters of LLMs. The issue of “cost nondeterminism” is particularly stark and makes budgeting difficult. As the researchers point out, “Ideally, developers and users would prefer models for which the standard deviation on token usage per instance is low for cost predictability.”
“The profiling we do in [the study] could be useful for developers as a tool to pick which models are less volatile for the same prompt or for different prompts,” Besmira Nushi, senior principal research manager at Microsoft Research, told VentureBeat. “Ideally, one would want to pick a model that has low standard deviation for correct inputs.”
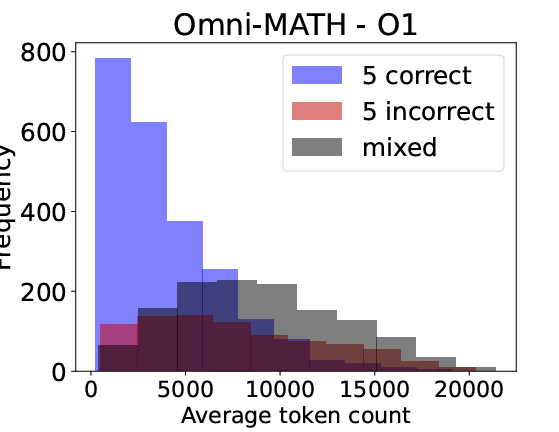
The study also provides good insights into the correlation between a model’s accuracy and response length. For example, the following diagram shows that math queries above ~11,000 token length have a very slim chance of being correct, and those generations should either be stopped at that point or restarted with some sequential feedback. However, Nushi points out that models allowing these post hoc mitigations also have a cleaner separation between correct and incorrect samples.
“Ultimately, it is also the responsibility of model builders to think about reducing accuracy and cost non-determinism, and we expect a lot of this to happen as the methods get more mature,” Nushi said. “Alongside cost nondeterminism, accuracy nondeterminism also applies.”
Another important finding is the consistent performance boost from perfect verifiers, which highlights a critical area for future work: building robust and broadly applicable verification mechanisms.
“The availability of stronger verifiers can have different types of impact,” Nushi said, such as improving foundational training methods for reasoning. “If used efficiently, these can also shorten the reasoning traces.”
Strong verifiers can also become a central part of enterprise agentic AI solutions. Many enterprise stakeholders already have such verifiers in place, which may need to be repurposed for more agentic solutions, such as SAT solvers, logistic validity checkers, etc.
“The questions for the future are how such existing techniques can be combined with AI-driven interfaces and what is the language that connects the two,” Nushi said. “The necessity of connecting the two comes from the fact that users will not always formulate their queries in a formal way, they will want to use a natural language interface and expect the solutions in a similar format or in a final action (e.g. propose a meeting invite).”