“I train models, analyze data and create dashboards — why should I care about Containers?”
Many people who are new to the world of data science ask themselves this question. But imagine you have trained a model that runs perfectly on your laptop. However, error messages keep popping up in the cloud when others access it — for example because they are using different library versions.
This is where containers come into play: They allow us to make machine learning models, data pipelines and development environments stable, portable and scalable — regardless of where they are executed.
Let’s take a closer look.
Table of Contents
1 — Containers vs. Virtual Machines: Why containers are more flexible than VMs
2 — Containers & Data Science: Do I really need Containers? And 4 reasons why the answer is yes.
3 — First Practice, then Theory: Container creation even without much prior knowledge
4 — Your 101 Cheatsheet: The most important Docker commands & concepts at a glance
Final Thoughts: Key takeaways as a data scientist
Where Can You Continue Learning?
1 — Containers vs. Virtual Machines: Why containers are more flexible than VMs
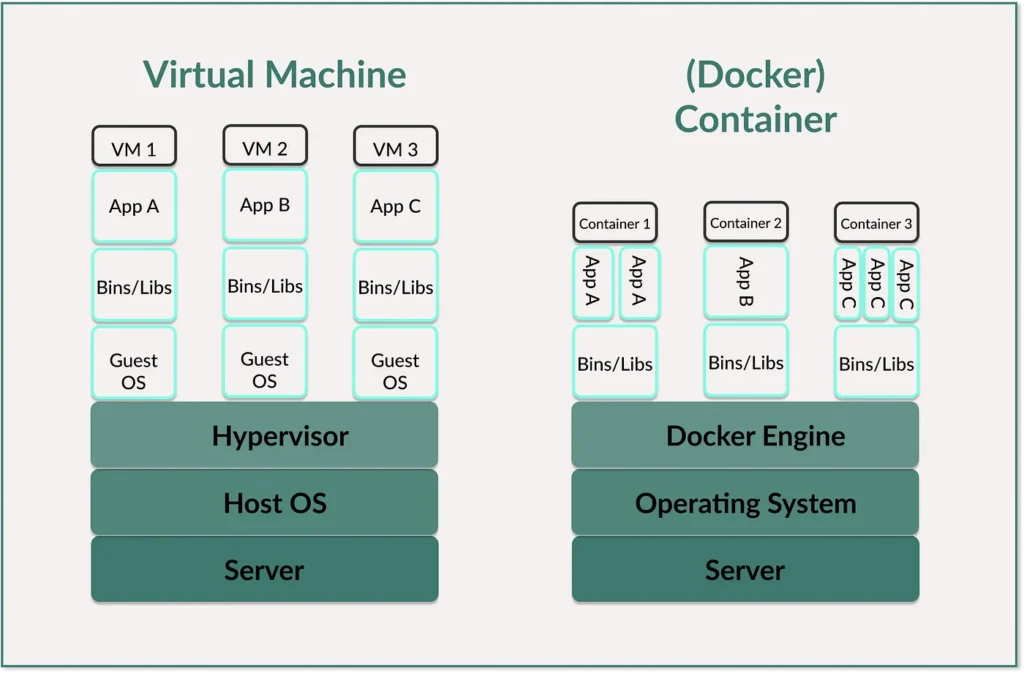
Containers are lightweight, isolated environments. They contain applications with all their dependencies. They also share the kernel of the host operating system, making them fast, portable and resource-efficient.
I have written extensively about virtual machines (VMs) and virtualization in ‘Virtualization & Containers for Data Science Newbiews’. But the most important thing is that VMs simulate complete computers and have their own operating system with their own kernel on a hypervisor. This means that they require more resources, but also offer greater isolation.
Both containers and VMs are virtualization technologies.
Both make it possible to run applications in an isolated environment.
But in the two descriptions, you can also see the 3 most important differences:
- Architecture: While each VM has its own operating system (OS) and runs on a hypervisor, containers share the kernel of the host operating system. However, containers still run in isolation from each other. A hypervisor is the software or firmware layer that manages VMs and abstracts the operating system of the VMs from the physical hardware. This makes it possible to run multiple VMs on a single physical server.
- Resource consumption: As each VM contains a complete OS, it requires a lot of memory and CPU. Containers, on the other hand, are more lightweight because they share the host OS.
- Portability: You have to customize a VM for different environments because it requires its own operating system with specific drivers and configurations that depend on the underlying hardware. A container, on the other hand, can be created once and runs anywhere a container runtime is available (Linux, Windows, cloud, on-premise). Container runtime is the software that creates, starts and manages containers — the best-known example is Docker.
You can experiment faster with Docker — whether you’re testing a new ML model or setting up a data pipeline. You can package everything in a container and run it immediately. And you don’t have any “It works on my machine”-problems. Your container runs the same everywhere — so you can simply share it.
2 — Containers & Data Science: Do I really need Containers? And 4 reasons why the answer is yes.
As a data scientist, your main task is to analyze, process and model data to gain valuable insights and predictions, which in turn are important for management.
Of course, you don’t need to have the same in-depth knowledge of containers, Docker or Kubernetes as a DevOps Engineer or a Site Reliability Engineer (SRE). Nevertheless, it is worth having container knowledge at a basic level — because these are 4 examples of where you will come into contact with it sooner or later:
Model deployment
You are training a model. You not only want to use it locally but also make it available to others. To do this, you can pack it into a container and make it available via a REST API.
Let’s look at a concrete example: Your trained model runs in a Docker container with FastAPI or Flask. The server receives the requests, processes the data and returns ML predictions in real-time.
Reproducibility and easier collaboration
ML models and pipelines require specific libraries. For example, if you want to use a deep learning model like a Transformer, you need TensorFlow or PyTorch. If you want to train and evaluate classic machine learning models, you need Scikit-Learn, NumPy and Pandas. A Docker container now ensures that your code runs with exactly the same dependencies on every computer, server or in the cloud. You can also deploy a Jupyter Notebook environment as a container so that other people can access it and use exactly the same packages and settings.
Cloud integration
Containers include all packages, dependencies and configurations that an application requires. They therefore run uniformly on local computers, servers or cloud environments. This means you don’t have to reconfigure the environment.
For example, you write a data pipeline script. This works locally for you. As soon as you deploy it as a container, you can be sure that it will run in exactly the same way on AWS, Azure, GCP or the IBM Cloud.
Scaling with Kubernetes
Kubernetes helps you to orchestrate containers. But more on that below. If you now get a lot of requests for your ML model, you can scale it automatically with Kubernetes. This means that more instances of the container are started.
3 — First Practice, then Theory: Container creation even without much prior knowledge
Let’s take a look at an example that anyone can run through with minimal time — even if you haven’t heard much about Docker and containers. It took me 30 minutes.
We’ll set up a Jupyter Notebook inside a Docker container, creating a portable, reproducible Data Science environment. Once it’s up and running, we can easily share it with others and ensure that everyone works with the exact same setup.
0 — Install Docker Dekstop and create a project directory
To be able to use containers, we need Docker Desktop. To do this, we download Docker Desktop from the official website.
Now we create a new folder for the project. You can do this directly in the desired folder. I do this via Terminal — on Windows with Windows + R and open CMD.
We use the following command:
1. Create a Dockerfile
Now we open VS Code or another editor and create a new file with the name ‘Dockerfile’. We save this file without an extension in the same directory. Why doesn’t it need an extension?
We add the following code to this file:
# Use the official Jupyter notebook image with SciPy
FROM jupyter/scipy-notebook:latest
# Set the working directory inside the container
WORKDIR /home/jovyan/work
# Copy all local files into the container
COPY . .
# Start Jupyter Notebook without token
CMD ["start-notebook.sh", "--NotebookApp.token=''"]We have thus defined a container environment for Jupyter Notebook that is based on the official Jupyter SciPy Notebook image.
First, we define with FROM on which base image the container is built. jupyter/scipy-notebook:latest is a preconfigured Jupyter notebook image and contains libraries such as NumPy, SiPy, Matplotlib or Pandas. Alternatively, we could also use a different image here.
With WORKDIR we set the working directory within the container. /home/jovyan/work is the default path used by Jupyter. User jovyan is the default user in Jupyter Docker images. Another directory could also be selected — but this directory is best practice for Jupyter containers.
With COPY . . we copy all files from the local directory — in this case the Dockerfile, which is located in the jupyter-docker directory — to the working directory /home/jovyan/work in the container.
With CMD [“start-notebook.sh”, “ — NotebookApp.token=‘’’”] we specify the default start command for the container, specify the start script for Jupyter Notebook and define that the notebook is started without a token — this allows us to access it directly via the browser.
2. Create the Docker image
Next, we will build the Docker image. Make sure you have the previously installed Docker desktop open. We now go back to the terminal and use the following command:
cd jupyter-docker
docker build -t my-jupyter .With cd jupyter-docker we navigate to the folder we created earlier. With docker build we create a Docker image from the Dockerfile. With -t my-jupyter we give the image a name. The dot means that the image will be built based on the current directory. What does that mean? Note the space between the image name and the dot.
The Docker image is the template for the container. This image contains everything needed for the application such as the operating system base (e.g. Ubuntu, Python, Jupyter), dependencies such as Pandas, Numpy, Jupyter Notebook, the application code and the startup commands. When we “build” a Docker image, this means that Docker reads the Dockerfile and executes the steps that we have defined there. The container can then be started from this template (Docker image).
We can now watch the Docker image being built in the terminal.
We use docker images to check whether the image exists. If the output my-jupyter appears, the creation was successful.
docker imagesIf yes, we see the data for the created Docker image:

3. Start Jupyter container
Next, we want to start the container and use this command to do so:
docker run -p 8888:8888 my-jupyterWe start a container with docker run. First, we enter the specific name of the container that we want to start. And with -p 8888:8888 we connect the local port (8888) with the port in the container (8888). Jupyter runs on this port. I do not understand.
Alternatively, you can also perform this step in Docker desktop:
4. Open Jupyter Notebook & create a test notebook
Now we open the URL [http://localhost:8888](http://localhost:8888/) in the browser. You should now see the Jupyter Notebook interface.
Here we will now create a Python 3 notebook and insert the following Python code into it.
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 10, 100)
y = np.sin(x)
plt.plot(x, y)
plt.title("Sine Wave")
plt.show()Running the code will display the sine curve:
5. Terminate the container
At the end, we end the container either with ‘CTRL + C’ in the terminal or in Docker Desktop.
With docker ps we can check in the terminal whether containers are still running and with docker ps -a we can display the container that has just been terminated:

6. Share your Docker image
If you now want to upload your Docker image to a registry, you can do this with the following command. This will upload your image to Docker Hub (you need a Docker Hub account for this). You can also upload it to a private registry of AWS Elastic Container, Google Container, Azure Container or IBM Cloud Container.
docker login
docker tag my-jupyter your-dockerhub-name/my-jupyter:latest
docker push dein-dockerhub-name/mein-jupyter:latestIf you then open Docker Hub and go to your repositories in your profile, the image should be visible.
This was a very simple example to get started with Docker. If you want to dive a little deeper, you can deploy a trained ML model with FastAPI via a container.
4 — Your 101 Cheatsheet: The most important Docker commands & concepts at a glance
You can actually think of a container like a shipping container. Regardless of whether you load it onto a ship (local computer), a truck (cloud server) or a train (data center) — the content always remains the same.
The most important Docker terms
- Container: Lightweight, isolated environment for applications that contains all dependencies.
- Docker: The most popular container platform that allows you to create and manage containers.
- Docker Image: A read-only template that contains code, dependencies and system libraries.
- Dockerfile: Text file with commands to create a Docker image.
- Kubernetes: Orchestration tool to manage many containers automatically.
The basic concepts behind containers
- Isolation: Each container contains its own processes, libraries and dependencies
- Portability: Containers run wherever a container runtime is installed.
- Reproducibility: You can create a container once and it runs exactly the same everywhere.
The most basic Docker commands
docker --version # Check if Docker is installed
docker ps # Show running containers
docker ps -a # Show all containers (including stopped ones)
docker images # List of all available images
docker info # Show system information about the Docker installation
docker run hello-world # Start a test container
docker run -d -p 8080:80 nginx # Start Nginx in the background (-d) with port forwarding
docker run -it ubuntu bash # Start interactive Ubuntu container with bash
docker pull ubuntu # Load an image from Docker Hub
docker build -t my-app . # Build an image from a Dockerfile
Final Thoughts: Key takeaways as a data scientist
👉 With Containers you can solve the “It works on my machine” problem. Containers ensure that ML models, data pipelines, and environments run identically everywhere, independent of OS or dependencies.
👉 Containers are more lightweight and flexible than virtual machines. While VMs come with their own operating system and consume more resources, containers share the host operating system and start faster.
👉 There are three key steps when working with containers: Create a Dockerfile to define the environment, use docker build to create an image, and run it with docker run — optionally pushing it to a registry with docker push.
And then there’s Kubernetes.
A term that comes up a lot in this context: An orchestration tool that automates container management, ensuring scalability, load balancing and fault recovery. This is particularly useful for microservices and cloud applications.
Before Docker, VMs were the go-to solution (see more in ‘Virtualization & Containers for Data Science Newbiews’.) VMs offer strong isolation, but require more resources and start slower.
So, Docker was developed in 2013 by Solomon Hykes to solve this problem. Instead of virtualizing entire operating systems, containers run independently of the environment — whether on your laptop, a server or in the cloud. They contain all the necessary dependencies so that they work consistently everywhere.
I simplify tech for curious minds🚀 If you enjoy my tech insights on Python, data science, Data Engineering, machine learning and AI, consider subscribing to my substack.