As a Developer Advocate, it’s challenging to keep up with user forum messages and understand the big picture of what users are saying. There’s plenty of valuable content — but how can you quickly spot the key conversations? In this tutorial, I’ll show you an AI hack to perform semantic clustering simply by prompting LLMs!
TL;DR 🔄 this blog post is about how to go from (data science + code) → (AI prompts + LLMs) for the same results — just faster and with less effort! 🤖⚡. It is organized as follows:
- Inspiration and Data Sources
- Exploring the Data with Dashboards
- LLM Prompting to produce KNN Clusters
- Experimenting with Custom Embeddings
- Clustering Across Multiple Discord Servers
Inspiration and Data Sources
First, I’ll give props to the December 2024 paper Clio (Claude insights and observations), a privacy-preserving platform that uses AI assistants to analyze and surface aggregated usage patterns across millions of conversations. Reading this paper inspired me to try this.
Data. I used only publicly available Discord messages, specifically “forum threads”, where users ask for tech help. In addition, I aggregated and anonymized content for this blog. Per thread, I formatted the data into conversation turn format, with user roles identified as either “user”, asking the question or “assistant”, anyone answering the user’s initial question. I also added a simple, hard-coded binary sentiment score (0 for “not happy” and 1 for “happy”) based on whether the user said thank you anytime in their thread. For vectorDB vendors I used Zilliz/Milvus, Chroma, and Qdrant.
The first step was to convert the data into a pandas data frame. Below is an excerpt. You can see for thread_id=2, a user only asked 1 question. But for thread_id=3, a user asked 4 different questions in the same thread (other 2 questions at farther down timestamps, not shown below).

I added a naive sentiment 0|1 scoring function.
<!– wp:prismatic/blocks {"language":"Python“} –>def calc_score(df):
# Define the target words
target_words = ["thanks", "thank you", "thx", "🙂", "😉", "👍"]
# Helper function to check if any target word is in the concatenated message content
def contains_target_words(messages):
concatenated_content = " ".join(messages).lower()
return any(word in concatenated_content for word in target_words)
# Group by 'thread_id' and calculate score for each group
thread_scores = (
df[df['role_name'] == 'user']
.groupby('thread_id')['message_content']
.apply(lambda messages: int(contains_target_words(messages)))
)
# Map the calculated scores back to the original DataFrame
df['score'] = df['thread_id'].map(thread_scores)
return df
...
if __name__ == "__main__":
# Load parameters from YAML file
config_path = "config.yaml"
params = load_params(config_path)
input_data_folder = params['input_data_folder']
processed_data_dir = params['processed_data_dir']
threads_data_file = os.path.join(processed_data_dir, "thread_summary.csv")
# Read data from Discord Forum JSON files into a pandas df.
clean_data_df = process_json_files(
input_data_folder,
processed_data_dir)
# Calculate score based on specific words in message content
clean_data_df = calc_score(clean_data_df)
# Generate reports and plots
plot_all_metrics(processed_data_dir)
# Concat thread messages & save as CSV for prompting.
thread_summary_df, avg_message_len, avg_message_len_user =
concat_thread_messages_df(clean_data_df, threads_data_file)
assert thread_summary_df.shape[0] == clean_data_df.thread_id.nunique()
Exploring the Data with Dashboards
From the processed data above, I built traditional dashboards:
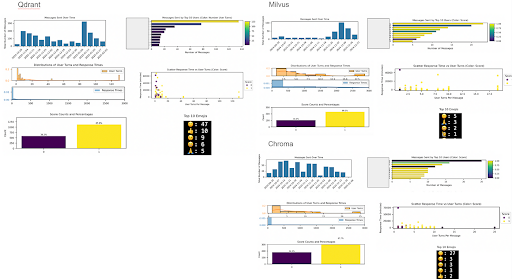
- Message Volumes: One-off peaks in vendors like Qdrant and Milvus (possibly due to marketing events).
- User Engagement: Top users bar charts and scatterplots of response time vs. number of user turns show that, in general, more user turns mean higher satisfaction. But, satisfaction does NOT look correlated with response time. Scatterplot dark dots seem random with regard to y-axis (response time). Maybe users are not in production, their questions are not very urgent? Outliers exist, such as Qdrant and Chroma, which may have bot-driven anomalies.
- Satisfaction Trends: Around 70% of users appear happy to have any interaction. Data note: make sure to check emojis per vendor, sometimes users respond using emojis instead of words! Example Qdrant and Chroma.
LLM Prompting to produce KNN Clusters
For prompting, the next step was to aggregate data by thread_id. For LLMs, you need the texts concatenated together. I separate out user messages from entire thread messages, to see if one or the other would produce better clusters. I ended up using just user messages.
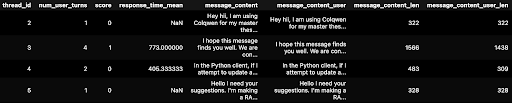
With a CSV file for prompting, you’re ready to get started using a LLM to do data science!
!pip install -q google.generativeai
import os
import google.generativeai as genai
# Get API key from local system
api_key=os.environ.get("GOOGLE_API_KEY")
# Configure API key
genai.configure(api_key=api_key)
# List all the model names
for m in genai.list_models():
if 'generateContent' in m.supported_generation_methods:
print(m.name)
# Try different models and prompts
GEMINI_MODEL_FOR_SUMMARIES = "gemini-2.0-pro-exp-02-05"
model = genai.GenerativeModel(GEMINI_MODEL_FOR_SUMMARIES)
# Combine the prompt and CSV data.
full_input = prompt + "nnCSV Data:n" + csv_data
# Inference call to Gemini LLM
response = model.generate_content(full_input)
# Save response.text as .json file...
# Check token counts and compare to model limit: 2 million tokens
print(response.usage_metadata)

Unfortunately Gemini API kept cutting short the response.text. I had better luck using AI Studio directly.

My 5 prompts to Gemini Flash & Pro (temperature set to 0) are below.
Prompt#1: Get thread Summaries:
Given this .csv file, per row, add 3 columns:
– thread_summary = 205 characters or less summary of the row’s column ‘message_content’
– user_thread_summary = 126 characters or less summary of the row’s column ‘message_content_user’
– thread_topic = 3–5 word super high-level category
Make sure the summaries capture the main content without losing too much detail. Make user thread summaries straight to the point, capture the main content without losing too much detail, skip the intro text. If a shorter summary is good enough prefer the shorter summary. Make sure the topic is general enough that there are fewer than 20 high-level topics for all the data. Prefer fewer topics. Output JSON columns: thread_id, thread_summary, user_thread_summary, thread_topic.
Prompt#2: Get cluster stats:
Given this CSV file of messages, use column=’user_thread_summary’ to perform semantic clustering of all the rows. Use technique = Silhouette, with linkage method = ward, and distance_metric = Cosine Similarity. Just give me the stats for the method Silhouette analysis for now.
Prompt#3: Perform initial clustering:
Given this CSV file of messages, use column=’user_thread_summary’ to perform semantic clustering of all the rows into N=6 clusters using the Silhouette method. Use column=”thread_topic” to summarize each cluster topic in 1–3 words. Output JSON with columns: thread_id, level0_cluster_id, level0_cluster_topic.
Silhouette Score measures how similar an object is to its own cluster (cohesion) versus other clusters (separation). Scores range from -1 to 1. A higher average silhouette score generally indicates better-defined clusters with good separation. For more details, check out the scikit-learn silhouette score documentation.
Applying it to Chroma Data. Below, I show results from Prompt#2, as a plot of silhouette scores. I chose N=6 clusters as a compromise between high score and fewer clusters. Most LLMs these days for data analysis take input as CSV and output JSON.
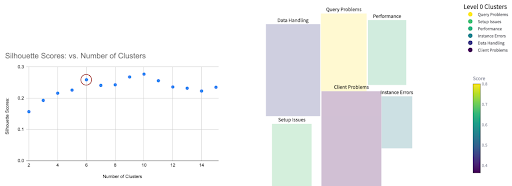
From the plot above, you can see we are finally getting into the meat of what users are saying!
Prompt#4: Get hierarchical cluster stats:
Given this CSV file of messages, use the column=’thread_summary_user’ to perform semantic clustering of all the rows into Hierarchical Clustering (Agglomerative) with 2 levels. Use Silhouette score. What is the optimal number of next Level0 and Level1 clusters? How many threads per Level1 cluster? Just give me the stats for now, we’ll do the actual clustering later.
Prompt#5: Perform hierarchical clustering:
Accept this clustering with 2-levels. Add cluster topics that summarize text column “thread_topic”. Cluster topics should be as short as possible without losing too much detail in the cluster meaning.
– Level0 cluster topics ~1–3 words.
– Level1 cluster topics ~2–5 words.
Output JSON with columns: thread_id, level0_cluster_id, level0_cluster_topic, level1_cluster_id, level1_cluster_topic.
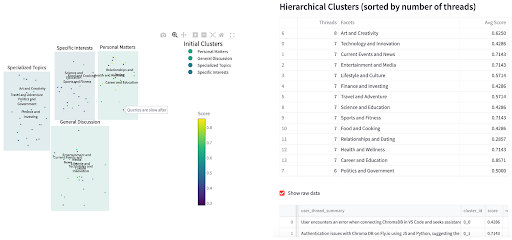
I also prompted to generate Streamlit code to visualize the clusters (since I’m not a JS expert 😄). Results for the same Chroma data are shown below.

I found this very insightful. For Chroma, clustering revealed that while users were happy with topics like Query, Distance, and Performance, they were unhappy about areas such as Data, Client, and Deployment.
Experimenting with Custom Embeddings
I repeated the above clustering prompts, using just the numerical embedding (“user_embedding”) in the CSV instead of the raw text summaries (“user_text”).I’ve explained embeddings in detail in previous blogs before, and the risks of overfit models on leaderboards. OpenAI has reliable embeddings which are extremely affordable by API call. Below is an example code snippet how to create embeddings.
from openai import OpenAI
EMBEDDING_MODEL = "text-embedding-3-small"
EMBEDDING_DIM = 512 # 512 or 1536 possible
# Initialize client with API key
openai_client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY"),
)
# Function to create embeddings
def get_embedding(text, embedding_model=EMBEDDING_MODEL,
embedding_dim=EMBEDDING_DIM):
response = openai_client.embeddings.create(
input=text,
model=embedding_model,
dimensions=embedding_dim
)
return response.data[0].embedding
# Function to call per pandas df row in .apply()
def generate_row_embeddings(row):
return {
'user_embedding': get_embedding(row['user_thread_summary']),
}
# Generate embeddings using pandas apply
embeddings_data = df.apply(generate_row_embeddings, axis=1)
# Add embeddings back into df as separate columns
df['user_embedding'] = embeddings_data.apply(lambda x: x['user_embedding'])
display(df.head())
# Save as CSV ...

Interestingly, both Perplexity Pro and Gemini 2.0 Pro sometimes hallucinated cluster topics (e.g., misclassifying a question about slow queries as “Personal Matter”).
Conclusion: When performing NLP with prompts, let the LLM generate its own embeddings — externally generated embeddings seem to confuse the model.
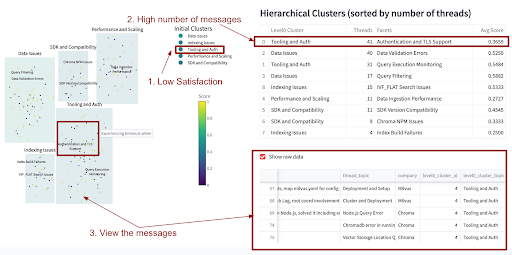
Clustering Across Multiple Discord Servers
Finally, I broadened the analysis to include Discord messages from three different VectorDB vendors. The resulting visualization highlighted common issues — like both Milvus and Chroma facing authentication problems.
Summary
Here’s a summary of the steps I followed to perform semantic clustering using LLM prompts:
- Extract Discord threads.
- Format data into conversation turns with roles (“user”, “assistant”).
- Score sentiment and save as CSV.
- Prompt Google Gemini 2.0 flash for thread summaries.
- Prompt Perplexity Pro or Gemini 2.0 Pro for clustering based on thread summaries using the same CSV.
- Prompt Perplexity Pro or Gemini 2.0 Pro to write Streamlit code to visualize clusters (because I’m not a JS expert 😆).
By following these steps, you can quickly transform raw forum data into actionable insights — what used to take days of coding can now be done in just one afternoon!
References
- Clio: Privacy-Preserving Insights into Real-World AI Use, https://arxiv.org/abs/2412.13678
- Anthropic blog about Clio, https://www.anthropic.com/research/clio
- Milvus Discord Server, last accessed Feb 7, 2025
Chroma Discord Server, last accessed Feb 7, 2025
Qdrant Discord Server, last accessed Feb 7, 2025 - Gemini models, https://ai.google.dev/gemini-api/docs/models/gemini
- Blog about Gemini 2.0 models, https://blog.google/technology/google-deepmind/gemini-model-updates-february-2025/
- Scikit-learn Silhouette Score
- OpenAI Matryoshka embeddings
- Streamlit