Nvidia is rolling out its AI chips to data centers and what it calls AI factories throughout the world, and the company announced today its Blackwell chips are leading the AI benchmarks.
Nvidia and its partners are speeding the training and deployment of next-generation AI applications that use the latest advancements in training and inference.
The Nvida Blackwell architecture is built to meet the heightened performance requirements of these new applications. In the latest round of MLPerf Training — the 12th since the benchmark’s introduction in 2018 — the Nvidia AI platform delivered the highest performance at scale on every benchmark and powered every result submitted on the benchmark’s toughest large language model (LLM)-focused test: Llama 3.1 405B pretraining.

The Nvidia platform was the only one that submitted results on every MLPerf Training v5.0 benchmark — underscoring its exceptional performance and versatility across a wide array of AI workloads, spanning LLMs, recommendation systems, multimodal LLMs, object detection and graph neural networks.
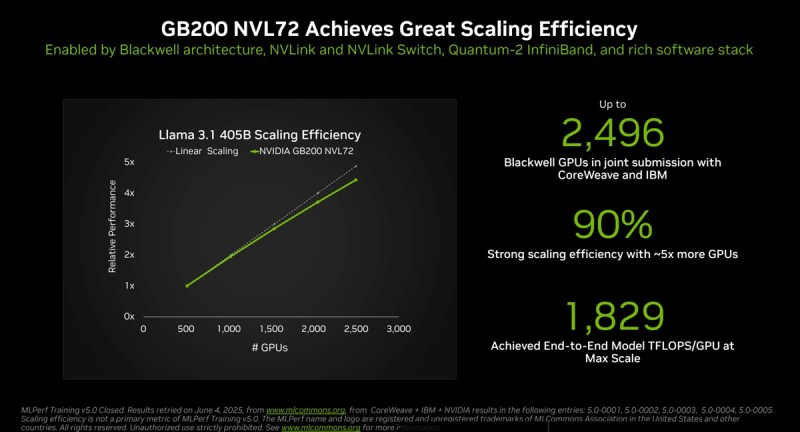
The at-scale submissions used two AI supercomputers powered by the Nvidia Blackwell platform: Tyche, built using Nvidia GB200 NVL72 rack-scale systems, and Nyx, based on Nvidia DGX B200 systems. In addition, Nvidia collaborated with CoreWeave and IBM to submit GB200 NVL72 results using a total of 2,496 Blackwell GPUs and 1,248 Nvidia Grace CPUs.
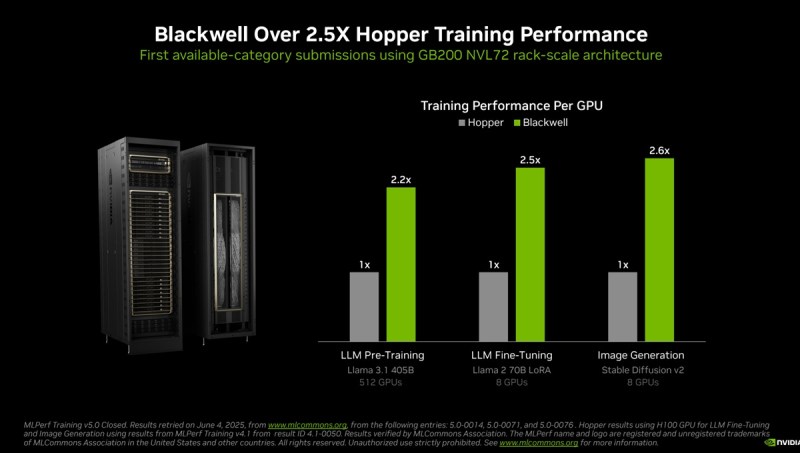
On the new Llama 3.1 405B pretraining benchmark, Blackwell delivered 2.2 times greater performance compared with previous-generation architecture at the same scale.

On the Llama 2 70B LoRA fine-tuning benchmark, Nvidia DGX B200 systems, powered by eight Blackwell GPUs, delivered 2.5 times more performance compared with a submission using the same number of GPUs in the prior round.
These performance leaps highlight advancements in the Blackwell architecture, including high-density liquid-cooled racks, 13.4TB of coherent memory per rack, fifth-generation Nvidia NVLink and Nvidia NVLink Switch interconnect technologies for scale-up and Nvidia Quantum-2 InfiniBand networking for scale-out. Plus, innovations in the Nvidia NeMo Framework software stack raise the bar for next-generation multimodal LLM training, critical for bringing agentic AI applications to market.
These agentic AI-powered applications will one day run in AI factories — the engines of the agentic AI economy. These new applications will produce tokens and valuable intelligence that can be applied to almost every industry and academic domain.
The Nvidia data center platform includes GPUs, CPUs, high-speed fabrics and networking, as well as a vast array of software like Nvidia CUDA-X libraries, the NeMo Framework, Nvidia TensorRT-LLM and Nvidia Dynamo. This highly tuned ensemble of hardware and software technologies empowers organizations to train and deploy models more quickly, dramatically accelerating time to value.
The Nvidia partner ecosystem participated extensively in this MLPerf round. Beyond the submission with CoreWeave and IBM, other compelling submissions were from ASUS, Cisco, Giga Computing, Lambda, Lenovo Quanta Cloud Technology and Supermicro.
First MLPerf Training submissions using GB200 were developed by MLCommons Association with more than 125 members and affiliates. Its time-to-train metric ensures training process produces a model that meets required accuracy. And its standardized benchmark run rules ensure apples-to-apples performance comparisons. The results are peer-reviewed before publication.
The basics on training benchmarks
Dave Salvator is someone I knew when he was part of the tech press. Now he is director of accelerated computing products in the Accelerated Computing Group at Nvidia. In a press briefing, Salvator noted that Nvidia CEO Jensen Huang talks about this notion of the types of scaling laws for AI. They include pre training, where you’re basically teaching the AI model knowledge. That’s starting from zero. It’s a heavy computational lift that is the backbone of AI, Salvator said.
From there, Nvidia moves into post-training scaling. This is where models kind of go to school, and this is a place where you can do things like fine tuning, for instance, where you bring in a different data set to teach a pre-trained model that’s been trained up to a point, to give it additional domain knowledge of your particular data set.

And then lastly, there is time-test scaling or reasoning, or sometimes called long thinking. The other term this goes by is agentic AI. It’s AI that can actually think and reason and problem solve, where you basically ask a question and get a relatively simple answer. Test time scaling and reasoning can actually work on much more complicated tasks and deliver rich analysis.
And then there is also generative AI which can generate content on an as needed basis that can include text summarization translations, but then also visual content and even audio content. There are a lot of types of scaling that go on in the AI world. For the benchmarks, Nvidia focused on pre-training and post-training results.
“That’s where AI begins what we call the investment phase of AI. And then when you get into inferencing and deploying those models and then generating basically those tokens, that’s where you begin to get your return on your investment in AI,” he said.
The MLPerf benchmark is in its 12th round and it dates back to 2018. The consortium backing it has over 125 members and it’s been used for both inference and training tests. The industry sees the benchmarks as robust.
“As I’m sure a lot of you are aware, sometimes performance claims in the world of AI can be a bit of the Wild West. MLPerf seeks to bring some order to that chaos,” Salvator said. “Everyone has to do the same amount of work. Everyone is held to the same standard in terms of convergence. And once results are submitted, those results are then reviewed and vetted by all the other submitters, and people can ask questions and even challenge results.”
The most intuitive metric around training is how long does it take to train an AI model trained to what’s called convergence. That means hitting a specified level of accuracy right. It’s an apples-to-apples comparison, Salvator said, and it takes into account constantly changing workloads.
This year, there’s a new Llama 3.140 5b workload, which replaces the ChatGPT 170 5b workload that was in the benchmark previously. In the benchmarks, Salvator noted Nvidia had a number of records. The Nvidia GB200 NVL72 AI factories are fresh from the fabrication factories. From one generation of chips (Hopper) to the next (Blackwell), Nvidia saw a 2.5 times improvement for image generation results.
“We’re still fairly early in the Blackwell product life cycle, so we fully expect to be getting more performance over time from the Blackwell architecture, as we continue to refine our software optimizations and as new, frankly heavier workloads come into the market,” Salvator said.
He noted Nvidia was the only company to have submitted entries for all benchmarks.
“The great performance we’re achieving comes through a combination of things. It’s our fifth-gen NVLink and NVSwitch up delivering up to 2.66 times more performance, along with other just general architectural goodness in Blackwell, along with just our ongoing software optimizations that make that make that performance possible,” Salvator said.
He added, “Because of Nvidia’s heritage, we have been known for the longest time as those GPU guys. We certainly make great GPUs, but we have gone from being just a chip company to not only being a system company with things like our DGX servers, to now building entire racks and data centers with things like our rack designs, which are now reference designs to help our partners get to market faster, to building entire data centers, which ultimately then build out entire infrastructure, which we then are now referring to as AI factories. It’s really been this really interesting journey.”