Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
The release of OpenAI GPT-4.5 has been somewhat disappointing, with many pointing out its insane price point (about 10 to 20X more expensive than Claude 3.7 Sonnet and 15 to 30X more costly than GPT-4o).
However, given that this is OpenAI’s largest and most powerful non-reasoning model, it is worth considering its strengths and the areas where it shines.
Better knowledge and alignment
There is little detail about the model’s architecture or training corpus, but we have a rough estimate that it has been trained with 10X more compute. And, the model was so large that OpenAI needed to spread training across multiple data centers to finish in a reasonable time.
Bigger models have a larger capacity for learning world knowledge and the nuances of human language (given that they have access to high-quality training data). This is evident in some of the metrics presented by the OpenAI team. For example, GPT-4.5 has a record-high ranking on PersonQA, a benchmark that evaluates hallucinations in AI models.
Practical experiments also show that GPT-4.5 is better than other general-purpose models at remaining true to facts and following user instructions.
Users have pointed out that GPT-4.5’s responses feel more natural and context-aware than previous models. Its ability to follow tone and style guidelines has also improved.
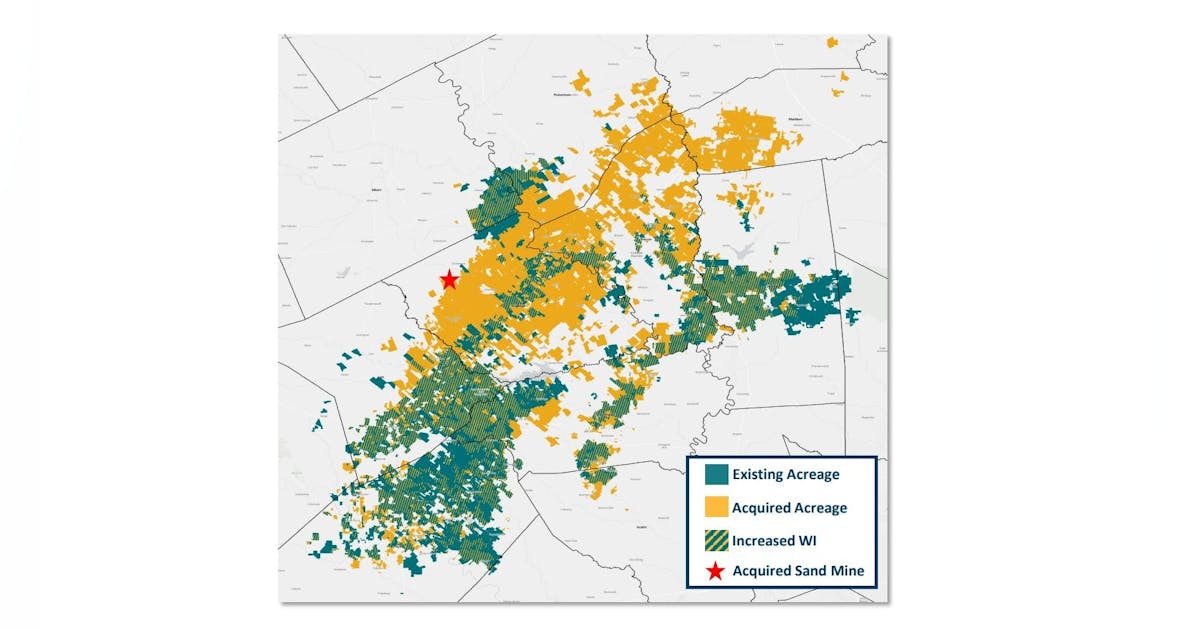
After the release of GPT-4.5, AI scientist and OpenAI co-founder Andrej Karpathy, who had early access to the model, said he “expect[ed] to see an improvement in tasks that are not reasoning-heavy, and I would say those are tasks that are more EQ (as opposed to IQ) related and bottlenecked by e.g. world knowledge, creativity, analogy making, general understanding, humor, etc.”
However, evaluating writing quality is also very subjective. In a survey that Karpathy ran on different prompts, most people preferred the responses of GPT-4o over GPT-4.5. He wrote on X: “Either the high-taste testers are noticing the new and unique structure but the low-taste ones are overwhelming the poll. Or we’re just hallucinating things. Or these examples are just not that great. Or it’s actually pretty close and this is way too small sample size. Or all of the above.”
Better document processing
In its experiments, Box, which has integrated GPT-4.5 into its Box AI Studio product, wrote that GPT-4.5 is “particularly potent for enterprise use-cases, where accuracy and integrity are mission critical… our testing shows that GPT-4.5 is one of the best models available both in terms of our eval scores and also its ability to handle many of the hardest AI questions that we have come across.”
In its internal evaluations, Box found GPT-4.5 to be more accurate on enterprise document question-answering tasks — outperforming the original GPT-4 by about 4 percentage points on their test set.
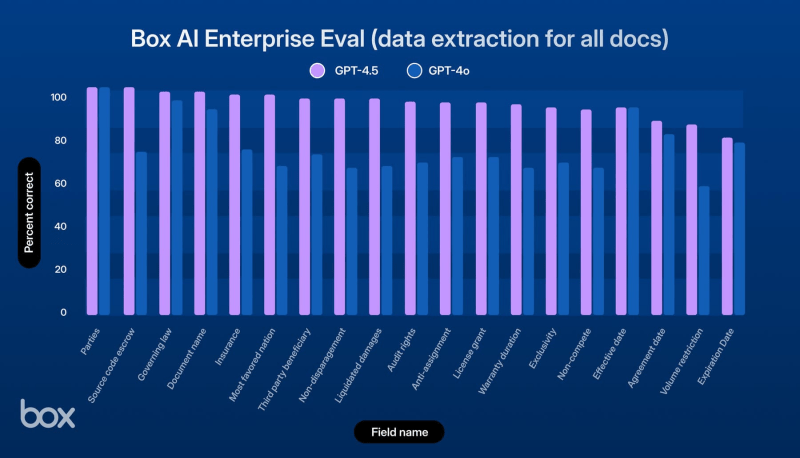
Box’s tests also indicated that GPT-4.5 excelled at math questions embedded in business documents, which older GPT models often struggled with. For example, it was better at answering questions about financial documents that required reasoning over data and performing calculations.
GPT-4.5 also showed improved performance at extracting information from unstructured data. In a test that involved extracting fields from hundreds of legal documents, GPT-4.5 was 19% more accurate than GPT-4o.
Planning, coding, evaluating results
Given its improved world knowledge, GPT-4.5 can also be a suitable model for creating high-level plans for complex tasks. Broken-down steps can then be handed over to smaller but more efficient models to elaborate and execute.
According to Constellation Research, “In initial testing, GPT-4.5 seems to show strong capabilities in agentic planning and execution, including multi-step coding workflows and complex task automation.”
GPT-4.5 can also be useful in coding tasks that require internal and contextual knowledge. GitHub now provides limited access to the model in its Copilot coding assistant and notes that GPT-4.5 “performs effectively with creative prompts and provides reliable responses to obscure knowledge queries.”
Given its deeper world knowledge, GPT-4.5 is also suitable for “LLM-as-a-Judge” tasks, where a strong model evaluates the output of smaller models. For example, a model such as GPT-4o or o3 can generate one or several responses, reason over the solution and pass the final answer to GPT-4.5 for revision and refinement.
Is it worth the price?
Given the huge costs of GPT-4.5, though, it is very hard to justify many of the use cases. But that doesn’t mean it will remain that way. One of the constant trends we have seen in recent years is the plummeting costs of inference, and if this trend applies to GPT-4.5, it is worth experimenting with it and finding ways to put its power to use in enterprise applications.
It is also worth noting that this new model can become the basis for future reasoning models. Per Karpathy: “Keep in mind that that GPT4.5 was only trained with pretraining, supervised finetuning and RLHF [reinforcement learning from human feedback], so this is not yet a reasoning model. Therefore, this model release does not push forward model capability in cases where reasoning is critical (math, code, etc.)… Presumably, OpenAI will now be looking to further train with reinforcement learning on top of GPT-4.5 model to allow it to think, and push model capability in these domains.”