Want smarter insights in your inbox? Sign up for our weekly newsletters to get only what matters to enterprise AI, data, and security leaders. Subscribe Now
It’s been a little more than a month since Chinese AI startup DeepSeek, an offshoot of Hong Kong-based High-Flyer Capital Management, released the latest version of its hit open source model DeepSeek, R1-0528.
Like its predecessor, DeepSeek-R1 — which rocked the AI and global business communities with how cheaply it was trained and how well it performed on reasoning tasks, all available to developers and enterprises for free — R1-0528 is already being adapted and remixed by other AI labs and developers, thanks in large part to its permissive Apache 2.0 license.
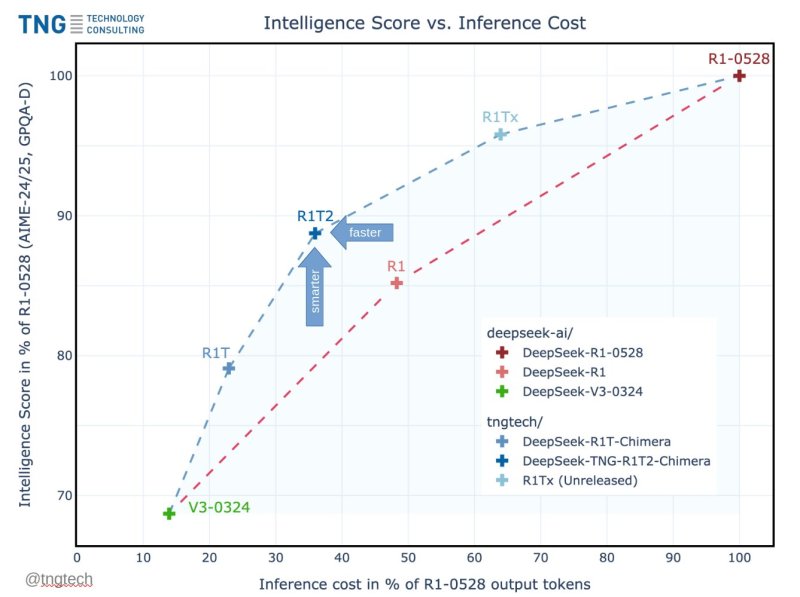
This week, the 24-year-old German firm TNG Technology Consulting GmbH released one such adaptation: DeepSeek-TNG R1T2 Chimera, the latest model in its Chimera large language model (LLM) family. R1T2 delivers a notable boost in efficiency and speed, scoring at upwards of 90% of R1-0528’s intelligence benchmark scores, while generating answers with less than 40% of R1-0528’s output token count.
That means it produces shorter responses, translating directly into faster inference and lower compute costs. On the model card TNG released for its new R1T2 on the AI code sharing community Hugging Face, the company states that it is “about 20% faster than the regular R1” (the one released back in January) “and more than twice as fast as R1-0528” (the May official update from DeepSeek).
Already, the response has been incredibly positive from the AI developer community. “DAMN! DeepSeek R1T2 – 200% faster than R1-0528 & 20% faster than R1,” wrote Vaibhav (VB) Srivastav, a senior leader at Hugging Face, on X. “Significantly better than R1 on GPQA & AIME 24, made via Assembly of Experts with DS V3, R1 & R1-0528 — and it’s MIT-licensed, available on Hugging Face.”
This gain is made possible by TNG’s Assembly-of-Experts (AoE) method — a technique for building LLMs by selectively merging the weight tensors (internal parameters) from multiple pre-trained models that TNG described in a paper published in May on arXiv, the non-peer reviewed open access online journal.
A successor to the original R1T Chimera, R1T2 introduces a new “Tri-Mind” configuration that integrates three parent models: DeepSeek-R1-0528, DeepSeek-R1, and DeepSeek-V3-0324. The result is a model engineered to maintain high reasoning capability while significantly reducing inference cost.
R1T2 is constructed without further fine-tuning or retraining. It inherits the reasoning strength of R1-0528, the structured thought patterns of R1, and the concise, instruction-oriented behavior of V3-0324 — delivering a more efficient, yet capable model for enterprise and research use.
How Assembly-of-Experts (AoE) Differs from Mixture-of-Experts (MoE)
Mixture-of-Experts (MoE) is an architectural design in which different components, or “experts,” are conditionally activated per input. In MoE LLMs like DeepSeek-V3 or Mixtral, only a subset of the model’s expert layers (e.g., 8 out of 256) are active during any given token’s forward pass. This allows very large models to achieve higher parameter counts and specialization while keeping inference costs manageable — because only a fraction of the network is evaluated per token.
Assembly-of-Experts (AoE) is a model merging technique, not an architecture. It’s used to create a new model from multiple pre-trained MoE models by selectively interpolating their weight tensors.
The “experts” in AoE refer to the model components being merged — typically the routed expert tensors within MoE layers — not experts dynamically activated at runtime.
TNG’s implementation of AoE focuses primarily on merging routed expert tensors — the part of a model most responsible for specialized reasoning — while often retaining the more efficient shared and attention layers from faster models like V3-0324. This approach enables the resulting Chimera models to inherit reasoning strength without replicating the verbosity or latency of the strongest parent models.
Performance and Speed: What the Benchmarks Actually Show
According to benchmark comparisons presented by TNG, R1T2 achieves between 90% and 92% of the reasoning performance of its most intelligent parent, DeepSeek-R1-0528, as measured by AIME-24, AIME-25, and GPQA-Diamond test sets.
However, unlike DeepSeek-R1-0528 — which tends to produce long, detailed answers due to its extended chain-of-thought reasoning — R1T2 is designed to be much more concise. It delivers similarly intelligent responses while using significantly fewer words.
Rather than focusing on raw processing time or tokens-per-second, TNG measures “speed” in terms of output token count per answer — a practical proxy for both cost and latency. According to benchmarks shared by TNG, R1T2 generates responses using approximately 40% of the tokens required by R1-0528.
That translates to a 60% reduction in output length, which directly reduces inference time and compute load, speeding up responses by 2X, or 200%.
When compared to the original DeepSeek-R1, R1T2 is also around 20% more concise on average, offering meaningful gains in efficiency for high-throughput or cost-sensitive deployments.
This efficiency does not come at the cost of intelligence. As shown in the benchmark chart presented in TNG’s technical paper, R1T2 sits in a desirable zone on the intelligence vs. output cost curve. It preserves reasoning quality while minimizing verbosity — an outcome critical to enterprise applications where inference speed, throughput, and cost all matter.
Deployment Considerations and Availability
R1T2 is released under a permissive MIT License and is available now on Hugging Face, meaning it is open source and available to be used and built into commercial applications.
TNG notes that while the model is well-suited for general reasoning tasks, it is not currently recommended for use cases requiring function calling or tool use, due to limitations inherited from its DeepSeek-R1 lineage. These may be addressed in future updates.
The company also advises European users to assess compliance with the EU AI Act, which comes into effect on August 2, 2025.
Enterprises operating in the EU should review relevant provisions or consider halting model use after that date if requirements cannot be met.
However, U.S. companies operating domestically and servicing U.S.-based users, or those of other nations, are not subject to the terms of the EU AI Act, which should give them considerable flexibility when using and deploying this free, speedy open source reasoning model. If they service users in the E.U., some provisions of the EU Act will still apply.
TNG has already made prior Chimera variants available through platforms like OpenRouter and Chutes, where they reportedly processed billions of tokens daily. The release of R1T2 represents a further evolution in this public availability effort.
About TNG Technology Consulting GmbH
Founded in January 2001, TNG Technology Consulting GmbH is based in Bavaria, Germany, and employs over 900 people, with a high concentration of PhDs and technical specialists.
The company focuses on software development, artificial intelligence, and DevOps/cloud services, serving major enterprise clients across industries such as telecommunications, insurance, automotive, e-commerce, and logistics.
TNG operates as a values-based consulting partnership. Its unique structure, grounded in operational research and self-management principles, supports a culture of technical innovation.
It actively contributes to open-source communities and research, as demonstrated through public releases like R1T2 and the publication of its Assembly-of-Experts methodology.
What It Means for Enterprise Technical Decision-Makers
For CTOs, AI platform owners, engineering leads, and IT procurement teams, R1T2 introduces tangible benefits and strategic options:
- Lower Inference Costs: With fewer output tokens per task, R1T2 reduces GPU time and energy consumption, translating directly into infrastructure savings — especially important in high-throughput or real-time environments.
- High Reasoning Quality Without Overhead: It preserves much of the reasoning power of top-tier models like R1-0528, but without their long-windedness. This is ideal for structured tasks (math, programming, logic) where concise answers are preferable.
- Open and Modifiable: The MIT License allows full deployment control and customization, enabling private hosting, model alignment, or further training within regulated or air-gapped environments.
- Emerging Modularity: The AoE approach suggests a future where models are built modularly, allowing enterprises to assemble specialized variants by recombining strengths of existing models, rather than retraining from scratch.
- Caveats: Enterprises relying on function-calling, tool use, or advanced agent orchestration should note current limitations, though future Chimera updates may address these gaps.
TNG encourages researchers, developers, and enterprise users to explore the model, test its behavior, and provide feedback. The R1T2 Chimera is available at huggingface.co/tngtech/DeepSeek-TNG-R1T2-Chimera, and technical inquiries can be directed to [email protected].
For technical background and benchmark methodology, TNG’s research paper is available at arXiv:2506.14794.