Originally published on HuggingFace
TL;DR
We present LettuceDetect, a lightweight hallucination detector for Retrieval-Augmented Generation (RAG) pipelines. It is an encoder-based model built on ModernBERT, released under the MIT license with ready-to-use Python packages and pretrained models.
- What: LettuceDetect is a token-level detector that flags unsupported segments in LLM answers. 🥬
- How: Trained on RAGTruth (18k examples), leveraging ModernBERT for context lengths up to 4k tokens. 🚀
- Why: It addresses (1) the context-window limits in prior encoder-only models, and (2) the high compute costs of LLM-based detectors. ⚖️
- Highlights:
- Beats prior encoder-based models (e.g., Luna) on RAGTruth. ✅
- Surpasses fine-tuned Llama-2-13B [2] at a fraction of the size, and is highly efficient at inference. ⚡️
- Entirely open-source with an MIT license. 🔓
LettuceDetect keeps your RAG framework fresh by spotting rotten parts of your LLM’s outputs. 😊
Quick links
Why LettuceDetect?
Large Language Models (LLMs) have made considerable advancements in NLP tasks, like GPT-4 [4], the Llama-3 models [5], or Mistral [6] (and many more). Despite the success of LLMs, Hallucinations remain a key obstacle deploying LLMs in high-stakes scenarios (such as in healthcare or legal) [7,8].
Retrieval-Augmented Generation (RAG) attempts to mitigate hallucinations by grounding an LLM’s responses in retrieved documents, providing external knowledge that the model can reference [9]. But even though RAG is a powerful method to reduce hallucinations, LLMs still suffer from hallucinations in these settings [1]. Hallucinations are information in the output that is nonsensical, factually incorrect, or inconsistent with the retrieved context [8]. Ji et al. [10] categorizes hallucinations into:
- Intrinsic hallucinations: Stemming from the model’s preexisting internal knowledge.
- Extrinsic hallucinations: Occurring when the answer conflicts with the context or references provided
While RAG approaches can mitigate intrinsic hallucinations, they are not immune to extrinsic hallucinations. Sun et al. [11] showed that models tend to prioritize their intrinsic knowledge over the external context. As LLMs remain prone to hallucinations, their applications in critical domains e.g. medical or legal, can be still flawed.
Current solutions for hallucination detection
Current solutions for hallucination detection can be categorized into different categories based on the approach they take:
- Prompt-based detectors These methods (e.g., RAGAS, Trulens, ARES) typically leverage zero-shot or few-shot prompts to detect hallucinations. They often rely on large LLMs (like GPT-4) and employ strategies such as SelfCheckGPT [12], LM vs. LM [13], or Chainpoll [14]. While often effective, they can be computationally expensive due to repeated LLM calls.
- Fine-tuned LLM detectors Large models (e.g., Llama-2, Llama-3) can be fine-tuned for hallucination detection [1,15]. This can yield high accuracy (as shown by the RAGTruth authors using Llama-2-13B or the RAG-HAT work on Llama-3-8B) but is resource-intensive to train and deploy. Inference costs also tend to be high due to their size and slower speeds.
- Encoder-based detectors Models like Luna [2] rely on a BERT-style encoder (often limited to 512 tokens) for token-level classification. These methods are generally more efficient than running a full LLM at inference but are constrained by short context windows and attention mechanisms optimized for smaller inputs.
ModernBERT for long context
ModernBERT [3] is a drop-in replacement for BERT and is a state-of-the-art encoder-only transformers architecture that incorporates several modern design improvements over the original BERT model such as it uses Rotary Positional Embeddings (RoPe) to handle sequences of up to 8,192 tokens, unpadding optimization to eliminate wasted computation on padding tokens, and GeGLU activation layers for enhanced expressiveness and alternating attention for more efficient attention computation.
LettuceDetect capitalizes on ModernBERT’s extended context window to build a token-level classifier for hallucination detection. This approach sidesteps many limitations of older BERT-based models (e.g., short context bounds) and avoids the inference overhead of large LLM-based detectors. Our experiments show that LettuceDetect outperforms other encoder-based systems while remaining competitive with fine-tuned LLM detectors at a fraction of their computational cost.
Data
RAGTruth is the first large-scale open-source (MIT License) benchmark specifically designed to evaluate hallucination detection in Retrieval-Augmented Generation (RAG) settings. It contains 18,000 annotated examples spanning multiple tasks:
- Question answering (QA): Sampled from the MS MARCO dataset, where up to three documents are retrieved for each question, and an LLM is prompted to produce an answer.
- Data-to-text generation: Based on the Yelp Open Dataset, where LLMs generate reviews for sampled businesses.
- News summarization: Uses random documents from CNN/DailyMail, prompting LLMs to provide summaries.
Each example in RAGTruth includes:
- A question and prompt,
- One or more reference passages or context documents,
- An LLM-generated response,
- Human annotations at the span level indicating whether any part of the answer is factually unsupported or contradictory to the reference passages.
Below is an illustrative sample from RAGTruth, showing an instance of hallucination:
QUESTION
How to explain quartiles?
REFERENCE
Passage 2:
Second quartile (Q2) which is more commonly known as median splits the data in half (50%).
Median divides the data into a lower half and an upper half.
Third quartile (Q3), also known as upper quartile, splits lowest 75% (or highest 25%) of data.
(…)
RESPONSE
The first quartile (Q1) splits the lowest 25% of the data, while the second quartile (Q2) splits the data into two equal halves, with the median being the middle value of the lower half. Finally, the third quartile (Q3) splits the highest 75% of the data.
(…)
ANNOTATION
- Span: “highest 75%”
- Type: Evident Conflict
- Reason:
- Original text: “lowest 75% (or highest 25%)”
- Generative text: “highest 75%”
This example showcases a RAGTruth annotation involving specific spans in the answer that conflict with the reference passages, providing both the type of hallucination (e.g., Evident Conflict) and a human-readable rationale. Our method only uses binary annotations and does not use the type of hallucination annotations.
Method
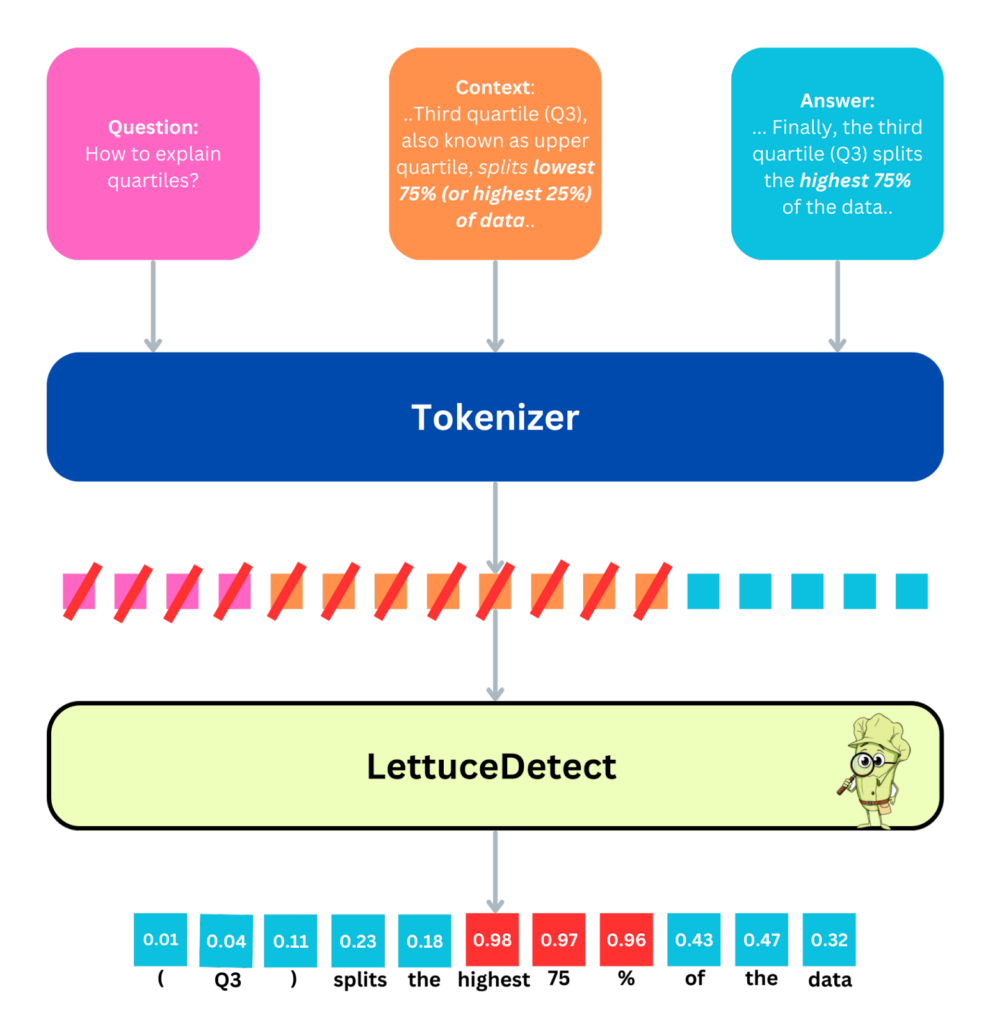
A high-level depiction of LettuceDetect. Here, an example Question, Context, and Answer triplet is processed. First, the text is tokenized, after which LettuceDetect performs token-level classification. Tokens from both the question and context are masked (indicated by the red line in the figure) to exclude them from the loss function. Each token in the answer receives a probability indicating whether it is hallucinated or supported. For span-level detection, we merge consecutive tokens with hallucination probabilities above 0.5 into a single predicted span.
We train ModernBERT-base and ModernBERT-large variants as token-classification models on the RAGTruth dataset. The input to the model is a concatenation of Context, Question, and Answer segments, with specialized tokens ([CLS]) (for the context) and ([SEP]) (as separators). We limit the sequence length to 4,096 tokens for computational feasibility, though ModernBERT can theoretically handle up to 8,192 tokens.
Tokenization and data processing
- Tokenizer: We employ AutoTokenizer from the Transformers library to handle subword Tokenization, inserting [CLS] and [SEP] appropriately.
- Labeling:
- Context/question tokens are masked (i.e., assigned a label of -100 in PyTorch) so that they do not contribute to the loss.
- Each answer token receives a label of 0 (supported) or 1 (hallucinated).
Model architecture
Our models build on Hugging Face’s AutoModelForTokenClassification, using ModernBERT as the encoder and a classification head on top. Unlike some previous encoder-based approaches (e.g., ones pre-trained on NLI tasks), our method uses only ModernBERT with no additional pretraining stage.
Training configuration
- Optimizer: AdamW, with a learning rate of 1 * 10^-5 and weight decay of 0.01.
- Hardware: Single NVIDIA A100 GPU.
- Epochs: 6 total training epochs.
- Batching:
- Batch size of 8,
- Data loading with PyTorch DataLoader (shuffling enabled),
- Dynamic padding via DataCollatorForTokenClassification to handle variable-length sequences efficiently.
During training, we monitor token-level F1 scores on a validation split, saving checkpoints using the safetensors format. Once training is complete, we upload the best-performing models to Hugging Face for public access.
At inference time, the model outputs a probability of hallucination for each token in the answer. We aggregate consecutive tokens exceeding a 0.5 threshold to produce span-level predictions, indicating exactly which segments of the answer are likely to be hallucinated. The figure above illustrates this workflow.
Next, we provide a more detailed evaluation of the model’s performance.
Results
We evaluate our models on the RAGTruth test set across all task types (Question Answering, Data-to-Text, and Summarization). For each example, RAGTruth includes manually annotated spans indicating hallucinated content.
Example-level results
We first assess the example-level question: Does the generated answer contain any hallucination at all? Our large model (lettucedetect-large-v1) attains an overall F1 score of 79.22%, surpassing:
- GPT-4 (63.4%),
- Luna (65.4%) (the previous state of the art encoder-based model),
- Fine-tuned Llama-2-13B (78.7%) as presented in the RAGTruth paper.
It is second only to the fine-tuned Llama-3-8B from the RAG-HAT paper [15] (83.9%), but LettuceDetect is significantly smaller and faster to run. Meanwhile, our base model (lettucedetect-base-v1) remains highly competitive while using fewer parameters.

Above is a comparison table illustrating how LettuceDetect aligns against both prompt-based methods (e.g., GPT-4) and alternative encoder-based solutions (e.g., Luna). Overall, lettucedetect-large-v1 and lettucedect-base-v1 are very performant models, while being very effective in inference settings.
Span-level results
Beyond detecting if an answer contains hallucinations, we also examine LettuceDetect’s ability to identify the exact spans of unsupported content. Here, LettuceDetect achieves state-of-the-art results among models that have reported span-level performance, substantially outperforming the fine-tuned Llama-2-13B model from the RAGTruth paper [1] and other baselines.

Most methods, like RAG-HAT [15], do not report span-level metrics, so we do not compare to them here.
Inference efficiency
Both lettucedetect-base-v1 and lettucedetect-large-v1 require fewer parameters than typical LLM-based detectors (e.g., GPT-4 or Llama-3-8B) and can process 30–60 examples per second on a single NVIDIA A100 GPU. This makes them practical for industrial workloads, real-time user-facing systems, and resource-constrained environments.
Overall, these results show that LettuceDetect has a good balance: it achieves near state-of-the-art accuracy at a fraction of the size and cost compared to large LLM-based judges, while offering precise, token-level hallucination detection.
Get going
Install the package:
pip install lettucedetectThen, you can use the package as follows:
from lettucedetect.models.inference import HallucinationDetector
# For a transformer-based approach:
detector = HallucinationDetector(
method="transformer", model_path="KRLabsOrg/lettucedect-base-modernbert-en-v1"
)
contexts = ["France is a country in Europe. The capital of France is Paris. The population of France is 67 million.",]
question = "What is the capital of France? What is the population of France?"
answer = "The capital of France is Paris. The population of France is 69 million."
# Get span-level predictions indicating which parts of the answer are considered hallucinated.
predictions = detector.predict(context=contexts, question=question, answer=answer, output_format="spans")
print("Predictions:", predictions)
# Predictions: [{'start': 31, 'end': 71, 'confidence': 0.9944414496421814, 'text': ' The population of France is 69 million.'}]Conclusion
We introduced LettuceDetect, a lightweight and efficient framework for hallucination detection in RAG systems. By utilizing ModernBERT’s extended context capabilities, our models achieve strong performance on the RAGTruth benchmark while retaining high inference efficiency. This work lays the groundwork for future research directions, such as expanding to additional datasets, supporting multiple languages, and exploring more advanced architectures. Even at this stage, LettuceDetect demonstrates that effective hallucination detection can be achieved using lean, purpose-built encoder-based models.
Citation
If you find this work useful, please cite it as follows:
@misc{Kovacs:2025,
title={LettuceDetect: A Hallucination Detection Framework for RAG Applications},
author={Ádám Kovács and Gábor Recski},
year={2025},
eprint={2502.17125},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2502.17125},
}Also, if you use our code, please don’t forget to give us a star ⭐ on our GitHub repository here.
References
[1] Niu et al., 2024, RAGTruth: A Dataset for Hallucination Detection in Retrieval-Augmented Generation
[3] ModernBERT: A Modern BERT Model for Long-Context Processing
[4] GPT-4 report
[5] Llama-3 report
[6] Mistral 7B
[7] Kaddour et al., 2023, Challenges and Applications of Large Language Models
[9] Gao et al., 2024, Retrieval-Augmented Generation for Large Language Models: A Survey
[10] Ji et al., 2023, Survey of Hallucination in Natural Language Generation
[13] Cohen et al., 2023, LM vs LM: Detecting Factual Errors via Cross Examination
[14] Friel et al., 2023, Chainpoll: A high efficacy method for LLM hallucination detection