Stable Diffusion 1.5/2.0/2.1/XL 1.0, DALL-E, Imagen… In the past years, Diffusion Models have showcased stunning quality in image generation. However, while producing great quality on generic concepts, these struggle to generate high quality for more specialised queries, for example generating images in a specific style, that was not frequently seen in the training dataset.
We could retrain the whole model on vast number of images, explaining the concepts needed to address the issue from scratch. However, this doesn’t sound practical. First, we need a large set of images for the idea, and second, it is simply too expensive and time-consuming.
There are solutions, however, that, given a handful of images and an hour of fine-tuning at worst, would enable diffusion models to produce reasonable quality on the new concepts.
Below, I cover approaches like Dreambooth, Lora, Hyper-networks, Textual Inversion, IP-Adapters and ControlNets widely used to customize and condition diffusion models. The idea behind all these methods is to memorise a new concept we are trying to learn, however, each technique approaches it differently.
Diffusion architecture
Before diving into various methods that help to condition diffusion models, let’s first recap what diffusion models are.
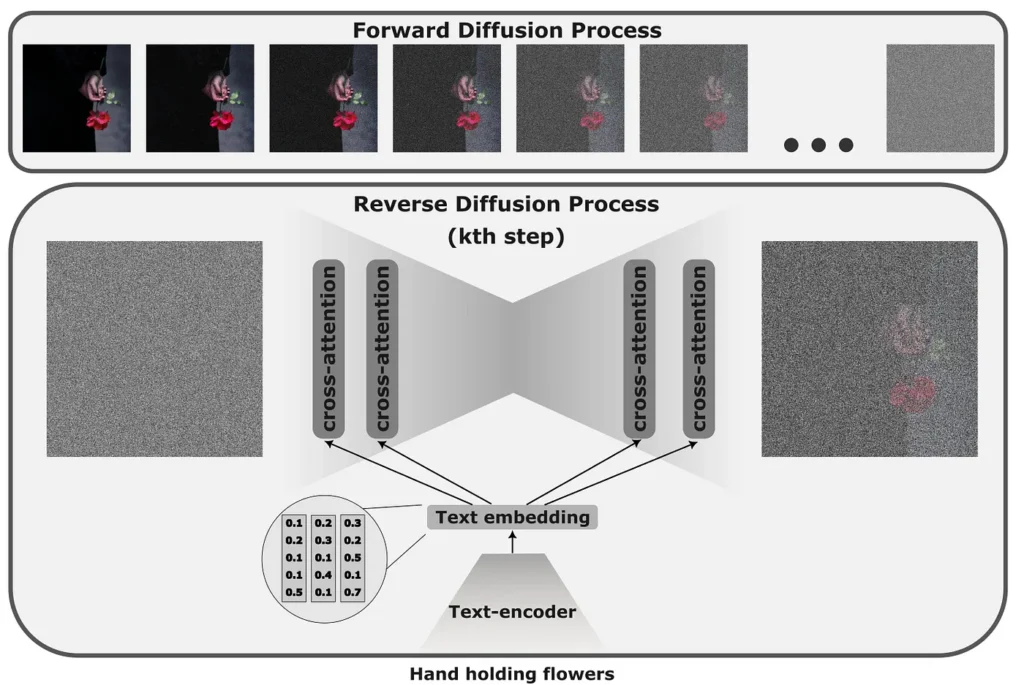
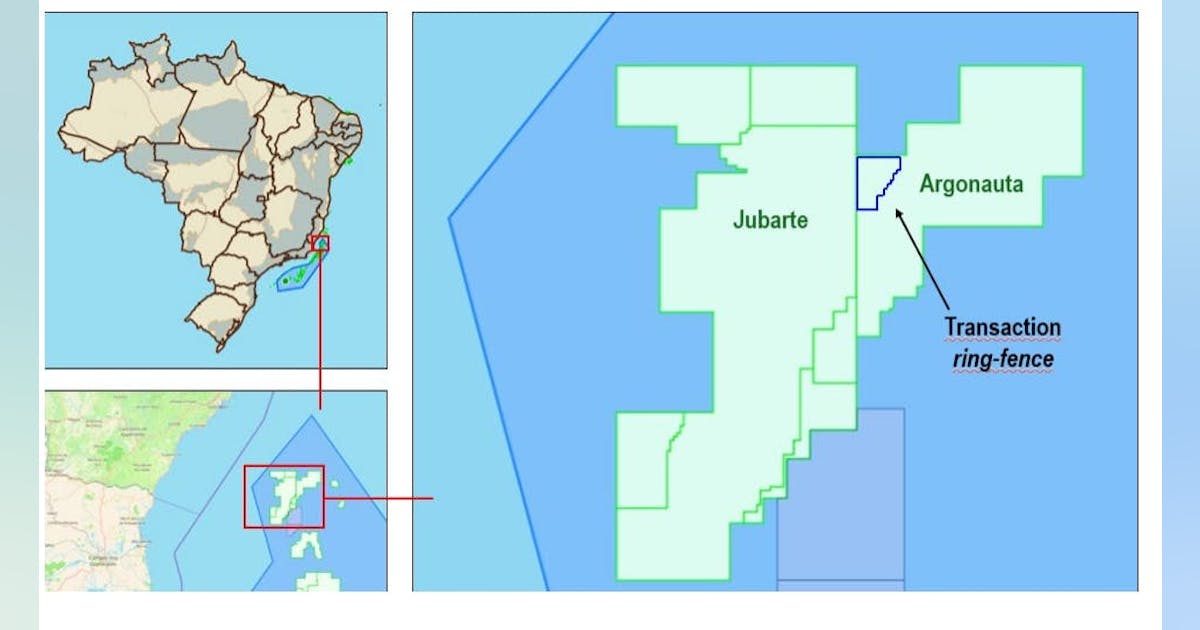
The original idea of diffusion models is to train a model to reconstruct a coherent image from noise. In the training stage, we gradually add small amounts of Gaussian noise (forward process) and then reconstruct the image iteratively by optimizing the model to predict the noise, subtracting which we would get closer to the target image (reverse process).
The original idea of image corruption has evolved into a more practical and lightweight architecture in which images are first compressed to a latent space, and all manipulation with added noise is performed in low dimensional space.
To add textual information to the diffusion model, we first pass it through a text-encoder (typically CLIP) to produce latent embedding, that is then injected into the model with cross-attention layers.
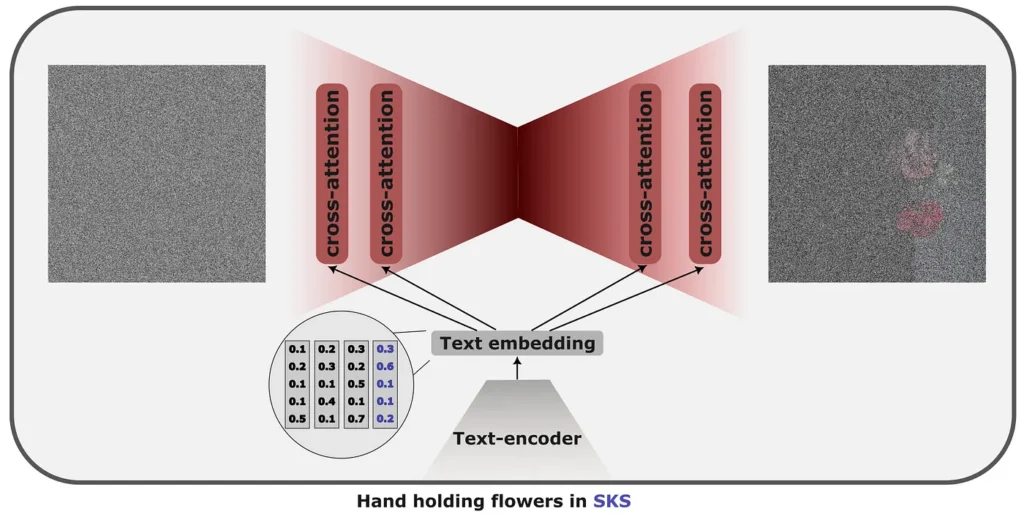
The idea is to take a rare word; typically, an {SKS} word is used and then teach the model to map the word {SKS} to a feature we would like to learn. That might, for example, be a style that the model has never seen, like van Gogh. We would show a dozen of his paintings and fine-tune to the phrase “A painting of boots in the {SKS} style”. We could similarly personalise the generation, for example, learn how to generate images of a particular person, for example “{SKS} in the mountains” on a set of one’s selfies.
To maintain the information learned in the pre-training stage, Dreambooth encourages the model not to deviate too much from the original, pre-trained version by adding text-image pairs generated by the original model to the fine-tuning set.
When to use and when not
Dreambooth produces the best quality across all methods; however, the technique could impact already learnt concepts since the whole model is updated. The training schedule also limits the number of concepts the model can understand. Training is time-consuming, taking 1–2 hours. If we decide to introduce several new concepts at a time, we would need to store two model checkpoints, which wastes a lot of space.
Textual Inversion, paper, code
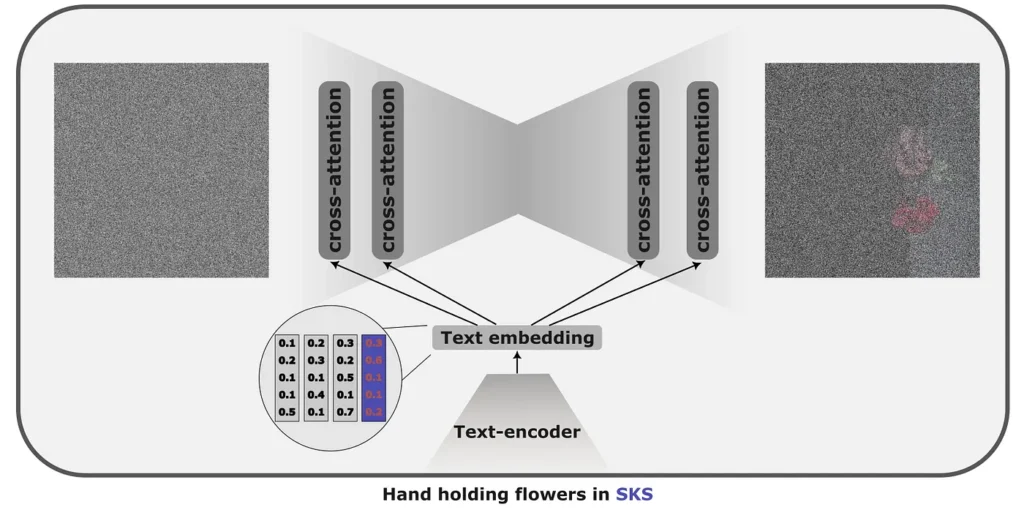
The assumption behind the textual inversion is that the knowledge stored in the latent space of the diffusion models is vast. Hence, the style or the condition we want to reproduce with the Diffusion model is already known to it, but we just don’t have the token to access it. Thus, instead of fine-tuning the model to reproduce the desired output when fed with rare words “in the {SKS} style”, we are optimizing for a textual embedding that would result in the desired output.
When to use and when not
It takes very little space, as only the token will be stored. It is also relatively quick to train, with an average training time of 20–30 minutes. However, it comes with its shortcomings — as we are fine-tuning a specific vector that guides the model to produce a particular style, it won’t generalise beyond this style.
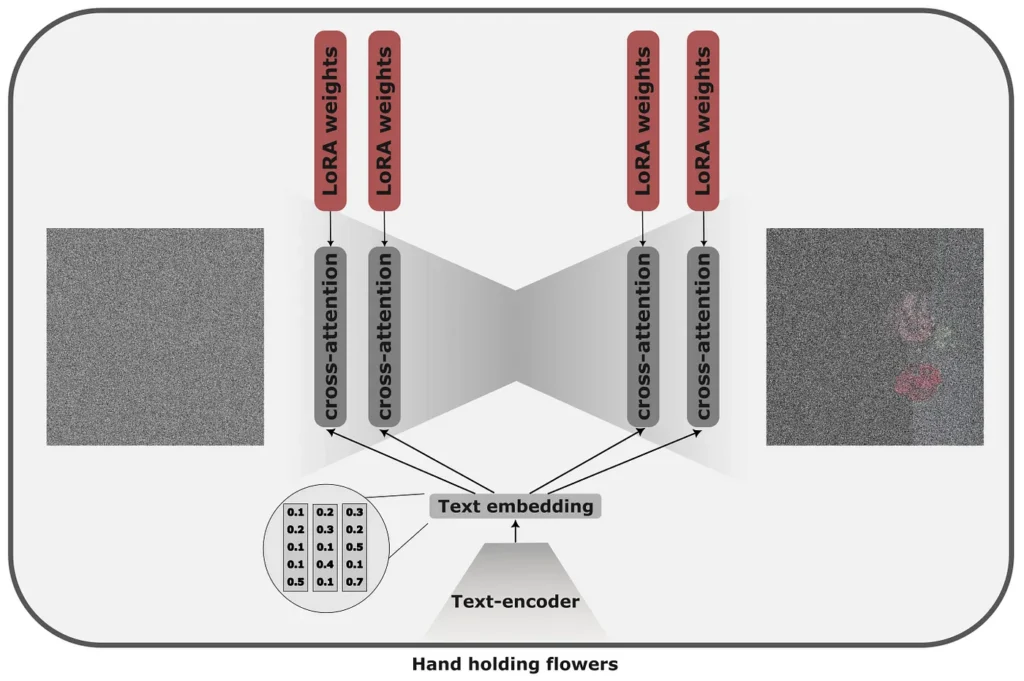
Low-Rank Adaptions (LoRA) were proposed for Large Language Models and were first adapted to the diffusion model by Simo Ryu. The original idea of LoRAs is that instead of fine-tuning the whole model, which can be rather costly, we can blend a fraction of new weights that would be fine-tuned for the task with a similar rare token approach into the original model.
In diffusion models, rank decomposition is applied to cross-attention layers and is responsible for merging prompt and image information. The weight matrices WO, WQ, WK, and WV in these layers have LoRA applied.
When to use and when not
LoRAs take very little time to train (5–15 minutes) — we are updating a handful of parameters compared to the whole model, and unlike Dreambooth, they take much less space. However, small-in-size models fine-tuned with LoRAs prove worse quality compared to DreamBooth.
Hyper-networks, paper, code
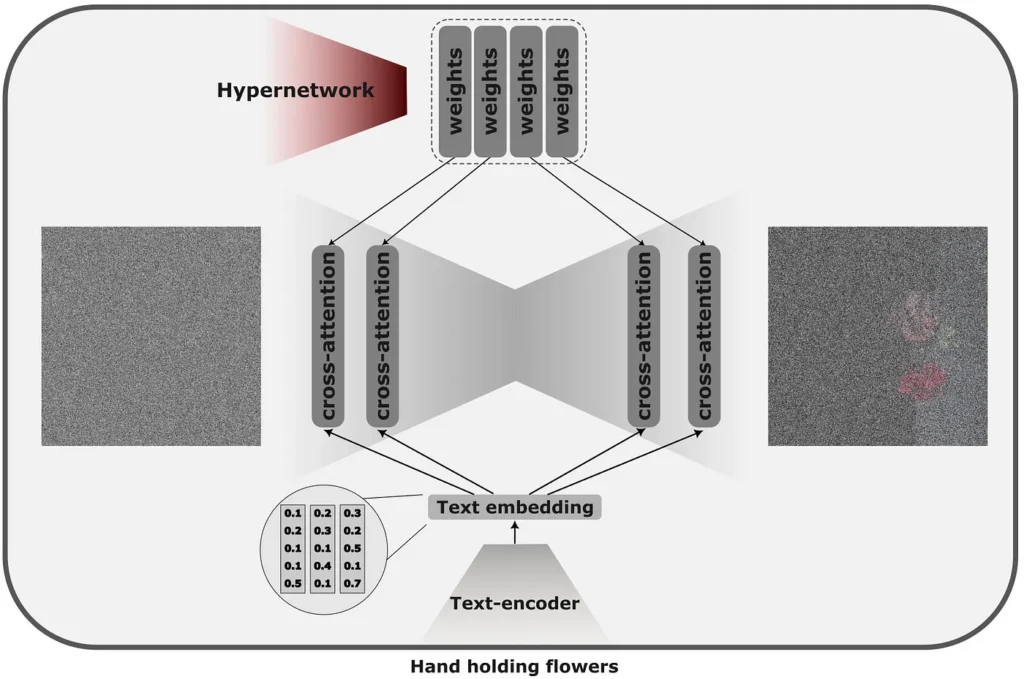
Hyper-networks are, in some sense, extensions to LoRAs. Instead of learning the relatively small embeddings that would alter the model’s output directly, we train a separate network capable of predicting the weights for these newly injected embeddings.
Having the model predict the embeddings for a specific concept we can teach the hypernetwork several concepts — reusing the same model for multiple tasks.
When to use and not
Hypernetworks, not specialising in a single style, but instead capable to produce plethora generally do not result in as good quality as the other methods and can take significant time to train. On the pros side, they can store many more concepts than other single-concept fine-tuning methods.
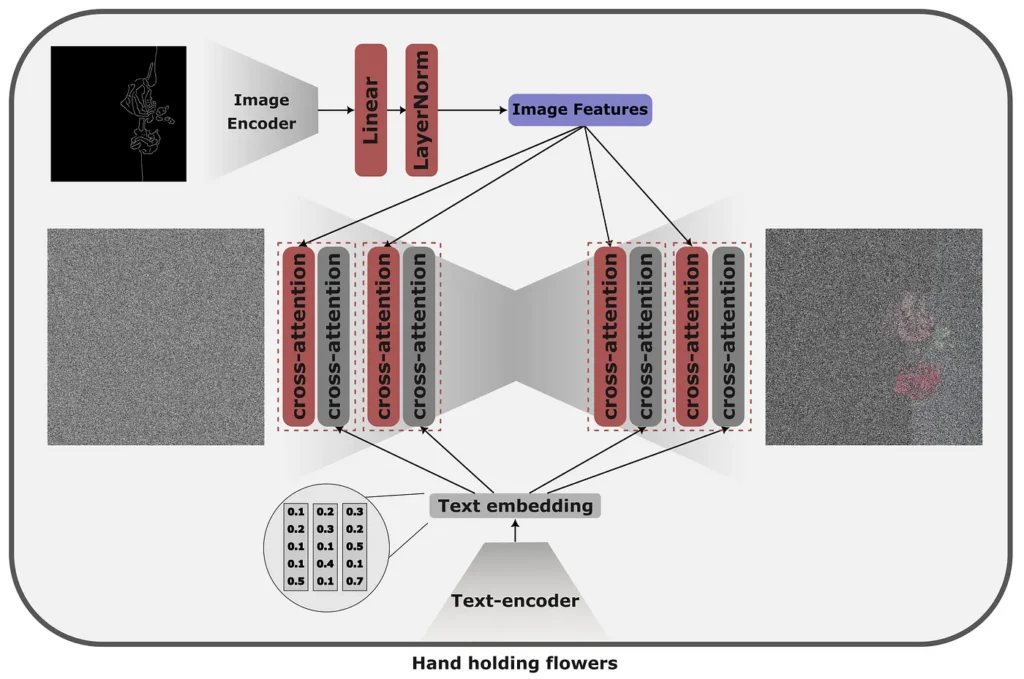
Instead of controlling image generation with text prompts, IP adapters propose a method to control the generation with an image without any changes to the underlying model.
The core idea behind the IP adapter is a decoupled cross-attention mechanism that allows the combination of source images with text and generated image features. This is achieved by adding a separate cross-attention layer, allowing the model to learn image-specific features.
When to use and not
IP adapters are lightweight, adaptable and fast. However, their performance is highly dependent on the quality and diversity of the training data. IP adapters generally tend to work better with supplying stylistic attributes (e.g. with an image of Mark Chagall’s paintings) that we would like to see in the generated image and could struggle with providing control for exact details, such as pose.
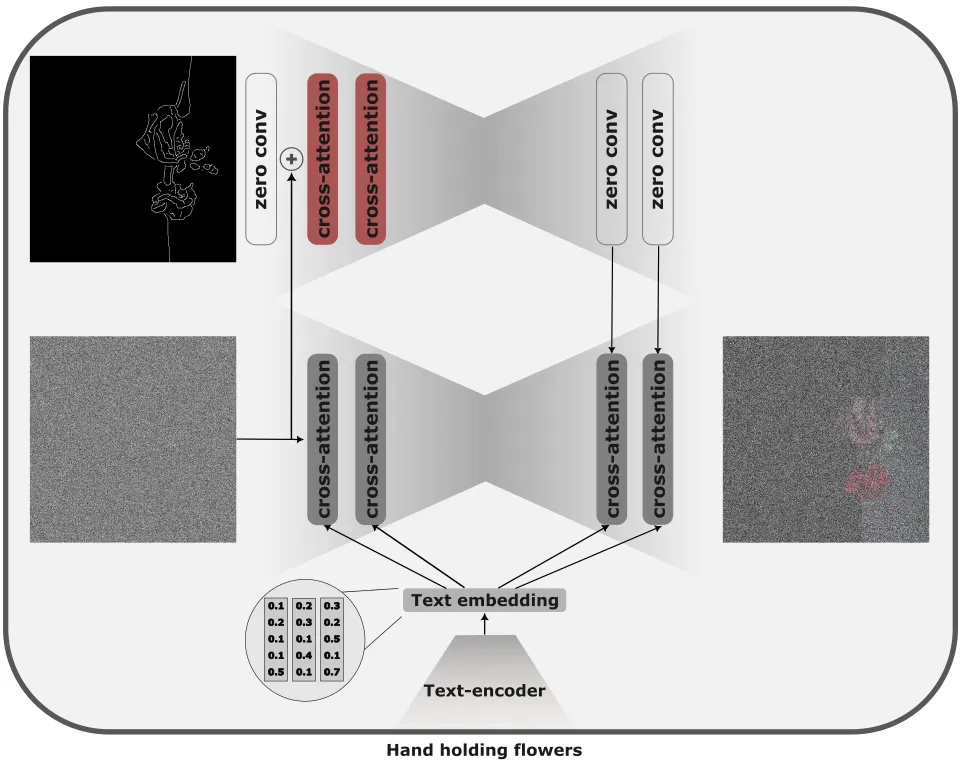
ControlNet paper proposes a way to extend the input of the text-to-image model to any modality, allowing for fine-grained control of the generated image.
In the original formulation, ControlNet is an encoder of the pre-trained diffusion model that takes, as an input, the prompt, noise and control data (e.g. depth-map, landmarks, etc.). To guide the generation, the intermediate levels of the ControlNet are then added to the activations of the frozen diffusion model.
The injection is achieved through zero-convolutions, where the weights and biases of 1×1 convolutions are initialized as zeros and gradually learn meaningful transformations during training. This is similar to how LoRAs are trained — intialised with 0’s they begin learning from the identity function.
When to use and not
ControlNets are preferable when we want to control the output structure, for example, through landmarks, depth maps, or edge maps. Due to the need to update the whole model weights, training could be time-consuming; however, these methods also allow for the best fine-grained control through rigid control signals.
Summary
- DreamBooth: Full fine-tuning of models for custom subjects of styles, high control level; however, it takes long time to train and are fit for one purpose only.
- Textual Inversion: Embedding-based learning for new concepts, low level of control, however, fast to train.
- LoRA: Lightweight fine-tuning of models for new styles/characters, medium level of control, while quick to train
- Hypernetworks: Separate model to predict LoRA weights for a given control request. Lower control level for more styles. Takes time to train.
- IP-Adapter: Soft style/content guidance via reference images, medium level of stylistic control, lightweight and efficient.
- ControlNet: Control via pose, depth, and edges is very precise; however, it takes longer time to train.
Best practice: For the best results, the combination of IP-adapter, with its softer stylistic guidance and ControlNet for pose and object arrangement, would produce the best results.
If you want to go into more details on diffusion, check out this article, that I have found very well written accessible to any level of machine learning and math. If you want to have an intuitive explanation of the Math with cool commentary check out this video or this video.
For looking up information on ControlNets, I found this explanation very helpful, this article and this article could be a good intro as well.
Liked the author? Stay connected!
Have I missed anything? Do not hesitate to leave a note, comment or message me directly on LinkedIn or Twitter!
The opinions in this blog are my own and not attributable to or on behalf of Snap.