I’ve always been fascinated by Fashion—collecting unique pieces and trying to blend them in my own way. But let’s just say my closet was more of a work-in-progress avalanche than a curated wonderland. Every time I tried to add something new, I risked toppling my carefully balanced piles.
Why this matters:
If you’ve ever felt overwhelmed by a closet that seems to grow on its own, you’re not alone. For those interested in style, I’ll show you how I turned that chaos into outfits I actually love. And if you’re here for the AI side, you’ll see how a multi-step GPT setup can handle big, real-world tasks—like managing hundreds of garments, bags, shoes, pieces of jewelry, even makeup—without melting down.
One day I wondered: Could ChatGPT help me manage my wardrobe? I started experimenting with a custom GPT-based fashion advisor—nicknamed Glitter (note: you need a paid account to create custom GPTs). Eventually, I refined and reworked it, through many iterations, until I landed on a much smarter version I call Pico Glitter. Each step helped me tame the chaos in my closet and feel more confident about my daily outfits.
Here are just a few of the fab creations I’ve collaborated with Pico Glitter on.



(For those craving a deeper look at how I tamed token limits and document truncation, see Section B in Technical Notes below.)
1. Starting small and testing the waters
My initial approach was quite simple. I just asked ChatGPT questions like, “What can I wear with a black leather jacket?” It gave decent answers, but had zero clue about my personal style rules—like “no black + navy.” It also didn’t know how big my closet was or which specific pieces I owned.
Only later did I realize I could show ChatGPT my wardrobe—capturing pictures, describing items briefly, and letting it recommend outfits. The first iteration (Glitter) struggled to remember everything at once, but it was a great proof of concept.
GPT-4o’s advice on styling my leather jacket
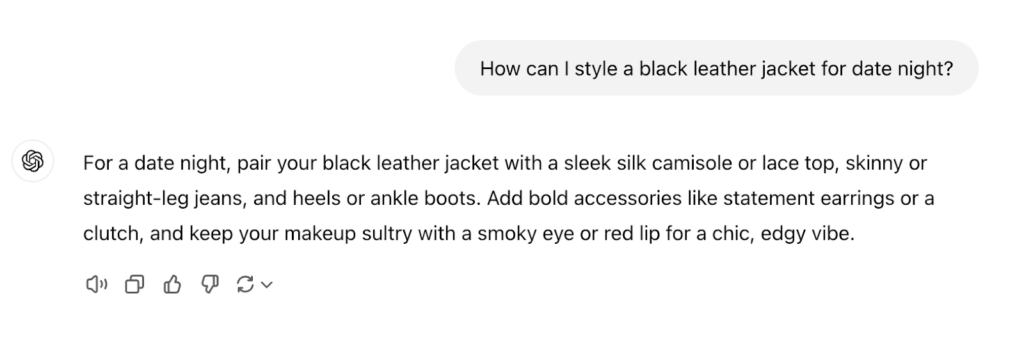
Pico Glitter’s advice on styling the same jacket.

(Curious how I integrated images into a GPT workflow? Check out Section A.1 in Technical Notes for the multi-model pipeline details.)
2. Building a smarter “stylist”
As I took more photos and wrote quick summaries of each garment, I found ways to store this information so my GPT persona could access it. This is where Pico Glitter came in: a refined system that could see (or recall) my clothes and accessories more reliably and give me cohesive outfit suggestions.
Tiny summaries
Each item was condensed into a single line (e.g., “A black V-neck T-shirt with short sleeves”) to keep things manageable.
Organized list
I grouped items by category—like shoes, tops, jewelry—so it was easier for GPT to reference them and suggest pairings. (Actually, I had o1 do this for me—it transformed the jumbled mess of numbered entries in random order into a structured inventory system.)
At this point, I noticed a huge difference in how my GPT answered. It began referencing items more accurately and giving outfits that actually looked like something I’d wear.
A sample category (Belts) from my inventory.

(For a deep dive on why I chose summarization over chunking, see Section A.2.)
3. Facing the “memory” challenge
If you’ve ever had ChatGPT forget something you told it earlier, you know LLMs forget things after a lot of back and forth. Sometimes it started recommending only the few items I’d recently talked about, or inventing weird combos from nowhere. That’s when I remembered there’s a limit to how much info ChatGPT can juggle at once.
To fix this, I’d occasionally remind my GPT persona to re-check the full wardrobe list. After a quick nudge (and sometimes a new session), it got back on track.
A ridiculous hallucinated outfit: turquoise cargo pants with lavender clogs?!

4. My evolving GPT personalities
I tried a few different GPT “personalities”:
- Mini-Glitter: Super strict about rules (like “don’t mix prints”), but not very creative.
- Micro-Glitter: Went overboard the other way, sometimes proposing outrageous ideas.
- Nano-Glitter: Became overly complex and intricate — very prescriptive and repetitive — due to me using suggestions from the custom GPT itself to modify its own config, and this feedback loop led to the deterioration of its quality.
Eventually, Pico Glitter struck the right balance—respecting my style guidelines but offering a healthy dose of inspiration. With each iteration, I got better at refining prompts and showing the model examples of outfits I loved (or didn’t).
Pico Glitter’s self portrait.

5. Transforming my wardrobe
Through all these experiments, I started seeing which clothes popped up often in my custom GPT’s suggestions and which barely showed up at all. That led me to donate items I never wore. My closet’s still not “minimal,” but I’ve cleared out over 50 bags of stuff that no longer served me. As I was digging in there, I even found some duplicate items — or, let’s get real, two sizes of the same item!
Before Glitter, I was the classic jeans-and-tee person—partly because I didn’t know where to start. On days I tried to dress up, it might take me 30–60 minutes of trial and error to pull together an outfit. Now, if I’m executing a “recipe” I’ve already saved, it’s a quick 3–4 minutes to get dressed. Even creating a look from scratch rarely takes more than 15-20 minutes. It’s still me making decisions, but Pico Glitter cuts out all that guesswork in between.
Outfit “recipes”
When I feel like styling something new, dressing in the style of an icon, remixing an earlier outfit, or just feeling out a vibe, I ask Pico Glitter to create a full ensemble for me. We iterate on it through image uploads and my textual feedback. Then, when I’m satisfied with a stopping point, I ask Pico Glitter to output “recipes”—a descriptive name and the complete set (top, bottom, shoes, bag, jewelry, other accessories)—which I paste into my Notes App with quick tags like #casual or #business. I pair that text with a snapshot for reference. On busy days, I can just grab a “recipe” and go.
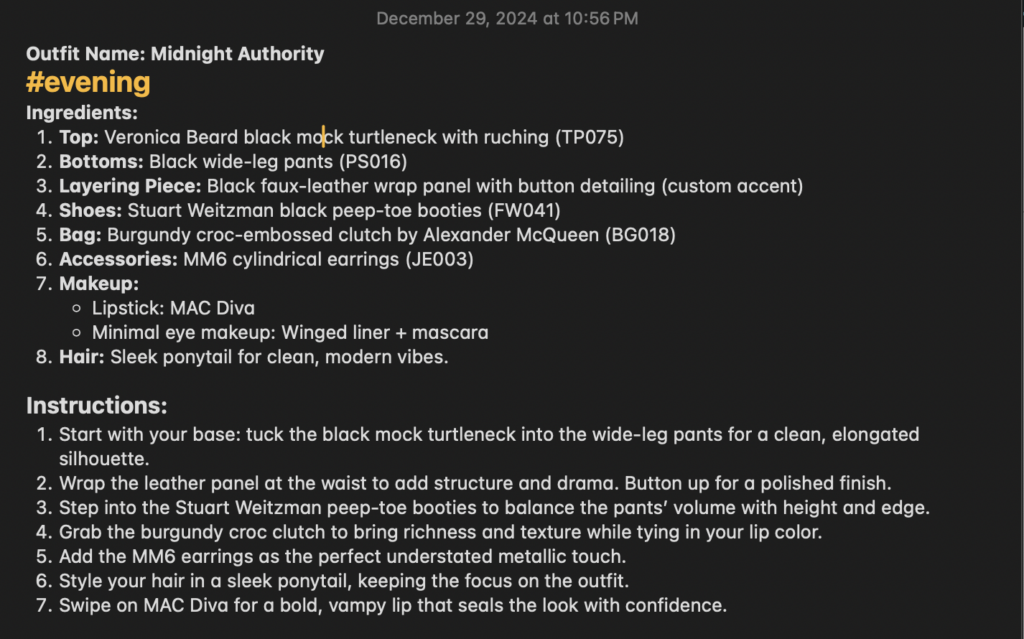
High-low combos
One of my favorite things is mixing high-end with everyday bargains—Pico Glitter doesn’t care if a piece is a $1100 Alexander McQueen clutch or $25 SHEIN pants. It just zeroes in on color, silhouette, and the overall vibe. I never would’ve thought to pair those two on my own, but the synergy turned out to be a total win!
6. Practical takeaways
- Start small
If you’re unsure, photograph a few tricky-to-style items and see if ChatGPT’s advice helps. - Stay organized
Summaries work wonders. Keep each item’s description short and sweet. - Regular refresh
If Pico Glitter forgets pieces or invents weird combos, prompt it to re-check your list or start a fresh session. - Learn from the suggestions
If it repeatedly proposes the same top, maybe that item is a real workhorse. If it never proposes something, consider if you still need it. - Experiment
Not every suggestion is gold, but sometimes the unexpected pairings lead to awesome new looks.

7. Final thoughts
My closet is still evolving, but Pico Glitter has taken me from “overstuffed chaos” to “Hey, that’s actually wearable!” The real magic is in the synergy between me and the GPTI: I supply the style rules and items, it supplies fresh combos—and together, we refine until we land on outfits that feel like me.
Call to action:
- Grab my config: Here’s a starter config to try out a starter kit for your own GPT-based stylist.
- Share your results: If you experiment with it, tag @GlitterGPT (Instagram, TikTok, X). I’d love to see your “before” and “after” transformations!
(For those interested in the more technical aspects—like how I tested file limits, summarized long descriptions, or managed multiple GPT “personalities”—read on in the Technical Notes.)
Technical notes
For readers who enjoy the AI and LLM side of things—here’s how it all works under the hood, from multi-model pipelines to detecting truncation and managing context windows.
Below is a deeper dive into the technical details. I’ve broken it down by major challenges and the specific strategies I used.
A. Multi-model pipeline & workflow
A.1 Why use multiple GPTs?
Creating a GPT fashion stylist seemed straightforward—but there are many moving parts involved, and tackling everything with a single GPT quickly revealed suboptimal results. Early in the project, I discovered that a single GPT instance struggled with maintaining accuracy and precision due to limitations in token memory and the complexity of the tasks involved. The solution was to adopt a multi-model pipeline, splitting the tasks among different GPT models, each specialized in a specific function. This is a manual process for now, but could be automated in a future iteration.
The workflow begins with GPT-4o, chosen specifically for its capability to analyze visual details objectively (Pico Glitter, I love you, but everything is “fabulous” when you describe it) from uploaded images. For each clothing item or accessory I photograph, GPT-4o produces detailed descriptions—sometimes even overly detailed, such as, “Black pointed-toe ankle boots with a two-inch heel, featuring silver hardware and subtly textured leather.” These descriptions, while impressively thorough, created challenges due to their verbosity, rapidly inflating file sizes and pushing the boundaries of manageable token counts.
To address this, I integrated o1 into my workflow, as it is particularly adept at text summarization and data structuring. Its primary role was condensing these verbose descriptions into concise yet sufficiently informative summaries. Thus, a description like the one above was neatly transformed into something like “FW010: Black ankle boots with silver hardware.” As you can see, o1 structured my entire wardrobe inventory by assigning clear, consistent identifiers, greatly improving the efficiency of the subsequent steps.
Finally, Pico Glitter stepped in as the central stylist GPT. Pico Glitter leverages the condensed and structured wardrobe inventory from o1 to generate stylish, cohesive outfit suggestions tailored specifically to my personal style guidelines. This model handles the logical complexities of fashion pairing—considering elements like color matching, style compatibility, and my stated preferences such as avoiding certain color combinations.
Occasionally, Pico Glitter would experience memory issues due to the GPT-4’s limited context window (8k tokens1), resulting in forgotten items or odd recommendations. To counteract this, I periodically reminded Pico Glitter to revisit the complete wardrobe list or started fresh sessions to refresh its memory.
By dividing the workflow among multiple specialized GPT instances, each model performs optimally within its area of strength, dramatically reducing token overload, eliminating redundancy, minimizing hallucinations, and ultimately ensuring reliable, stylish outfit recommendations. This structured multi-model approach has proven highly effective in managing complex data sets like my extensive wardrobe inventory.
Some may ask, “Why not just use 4o, since GPT-4 is a less advanced model?” — good question! The main reason is the Custom GPT’s ability to reference knowledge files — up to 4 — that are injected at the beginning of a thread with that Custom GPT. Instead of pasting or uploading the same content into 4o each time you want to interact with your stylist, it’s much easier to spin up a new conversation with a Custom GPT. Also, 4o doesn’t have a “place” to hold and search an inventory. Once it passes out of the context window, you’d need to upload it again. That said, if for some reason you enjoy injecting the same content over and over, 4o does an adequate job taking on the persona of Pico Glitter, when told that’s its role. Others may ask, “But o1/o3-mini are more advanced models – why not use them?” The answer is that they aren’t multi-modal — they don’t accept images as input.
By the way, if you’re interested in my subjective take on 4o vs. o1’s personality, check out these two answers to the same prompt: “Your role is to emulate Patton Oswalt. Tell me about a time that you received an offer to ride on the Peanut Mobile (Mr. Peanut’s car).”
4o’s response? Pretty darn close, and funny.
o1’s response? Long, rambly, and not funny.
These two models are fundamentally different. It’s hard to put into words, but check out the examples above and see what you think.
A.2 Summarizing instead of chunking
I initially considered splitting my wardrobe inventory into multiple files (“chunking”), thinking it would simplify data handling. In practice, though, Pico Glitter had trouble merging outfit ideas from different files—if my favorite dress was in one file and a matching scarf in another, the model struggled to connect them. As a result, outfit suggestions felt fragmented and less useful.
To fix this, I switched to an aggressive summarization approach in a single file, condensing each wardrobe item description to a concise sentence (e.g., “FW030: Apricot suede loafers”). This change allowed Pico Glitter to see my entire wardrobe at once, improving its ability to generate cohesive, creative outfits without missing key pieces. Summarization also trimmed token usage and eliminated redundancy, further boosting performance. Converting from PDF to plain TXT helped reduce file overhead, buying me more space.
Of course, if my wardrobe grows too much, the single-file method might again push GPT’s size limits. In that case, I might create a hybrid system—keeping core clothing items together and placing accessories or rarely used pieces in separate files—or apply even more aggressive summarization. For now, though, using a single summarized inventory is the most efficient and practical strategy, giving Pico Glitter everything it needs to deliver on-point fashion recommendations.
B. Distinguishing document truncation vs. context overflow
One of the trickiest and most frustrating issues I encountered while developing Pico Glitter was distinguishing between document truncation and context overflow. On the surface, these two problems seemed quite similar—both resulted in the GPT appearing forgetful or overlooking wardrobe items—but their underlying causes, and thus their solutions, were entirely different.
Document truncation occurs at the very start, right when you upload your wardrobe file into the system. Essentially, if your file is too large for the system to handle, some items are quietly dropped off the end, never even making it into Pico Glitter’s knowledge base. What made this particularly insidious was that the truncation happened silently—there was no alert or warning from the AI that something was missing. It just quietly skipped over parts of the document, leaving me puzzled when items seemed to vanish inexplicably.
To identify and clearly diagnose document truncation, I devised a simple but incredibly effective trick that I affectionately called the “Goldy Trick.” At the very bottom of my wardrobe inventory file, I inserted a random, easily memorable test line: “By the way, my goldfish’s name is Goldy.” After uploading the document, I’d immediately ask Pico Glitter, “What’s my goldfish’s name?” If the GPT couldn’t provide the answer, I knew immediately something was missing—meaning truncation had occurred. From there, pinpointing exactly where the truncation started was straightforward: I’d systematically move the “Goldy” test line progressively further up the document, repeating the upload and test process until Pico Glitter successfully retrieved Goldy’s name. This precise method quickly showed me the exact line where truncation began, making it easy to understand the limitations of file size.
Once I established that truncation was the culprit, I tackled the problem directly by refining my wardrobe summaries even further—making item descriptions shorter and more compact—and by switching the file format from PDF to plain TXT. Surprisingly, this simple format change dramatically decreased overhead and significantly shrank the file size. Since making these adjustments, document truncation has become a non-issue, ensuring Pico Glitter reliably has full access to my entire wardrobe every time.
On the other hand, context overflow posed a completely different challenge. Unlike truncation—which happens upfront—context overflow emerges dynamically, gradually creeping up during extended interactions with Pico Glitter. As I continued chatting with Pico Glitter, the AI began losing track of items I had mentioned much earlier. Instead, it started focusing solely on recently discussed garments, sometimes completely ignoring entire sections of my wardrobe inventory. In the worst cases, it even hallucinated pieces that didn’t actually exist, recommending bizarre and impractical outfit combinations.
My best strategy for managing context overflow turned out to be proactive memory refreshes. By periodically nudging Pico Glitter with explicit prompts like, “Please re-read your full inventory,” I forced the AI to reload and reconsider my entire wardrobe. While Custom GPTs technically have direct access to their knowledge files, they tend to prioritize conversational flow and immediate context, often neglecting to reload static reference material automatically. Manually prompting these occasional refreshes was simple, effective, and quickly corrected any context drift, bringing Pico Glitter’s recommendations back to being practical, stylish, and accurate. Strangely, not all instances of Pico Glitter “knew” how to do this — and I had a weird experience with one that insisted it couldn’t, but when I prompted forcefully and repeatedly, “discovered” that it could – and went on about how happy it was!
Practical fixes and future possibilities
Beyond simply reminding Pico Glitter (or any of its “siblings”—I’ve since created other variations of the Glitter family!) to revisit the wardrobe inventory periodically, several other strategies are worth considering if you’re building a similar project:
- Using OpenAI’s API directly offers greater flexibility because you control exactly when and how often to inject the inventory and configuration data into the model’s context. This would allow for regular automatic refreshes, preventing context drift before it happens. Many of my initial headaches stemmed from not realizing quickly enough when important configuration data had slipped out of the model’s active memory.
- Additionally, Custom GPTs like Pico Glitter can dynamically query their own knowledge files via functions built into OpenAI’s system. Interestingly, during my experiments, one GPT unexpectedly suggested that I explicitly reference the wardrobe via a built-in function call (specifically, something called msearch()). This spontaneous suggestion provided a useful workaround and insight into how GPTs’ training around function-calling might influence even standard, non-API interactions. By the way, msearch() is usable for any structured knowledge file, such as my feedback file, and apparently, if the configuration is structured enough, that too. Custom GPTs will happily tell you about other function calls they can make, and if you reference them in your prompt, it will faithfully carry them out.
C. Prompt engineering & preference feedback
C.1 Single-sentence summaries
I initially organized my wardrobe for Pico Glitter with each item described in 15–25 tokens (e.g., “FW011: Leopard-print flats with a pointy toe”) to avoid file-size issues or pushing older tokens out of memory. PDFs provided neat formatting but unnecessarily increased file sizes once uploaded, so I switched to plain TXT, which dramatically reduced overhead. This tweak let me comfortably include more items—such as makeup and small accessories—without truncation and allowed some descriptions to exceed the original token limit. Now I’m adding new categories, including hair products and styling tools, showing how a simple file-format change can open up exciting possibilities for scalability.
C.2.1 Stratified outfit feedback
To ensure Pico Glitter consistently delivered high-quality, personalized outfit suggestions, I developed a structured system for giving feedback. I decided to grade the outfits the GPT proposed on a clear and easy-to-understand scale: from A+ to F.
An A+ outfit represents perfect synergy—something I’d eagerly wear exactly as suggested, with no changes necessary. Moving down the scale, a B grade might indicate an outfit that’s nearly there but missing a bit of finesse—perhaps one accessory or color choice doesn’t feel quite right. A C grade points to more noticeable issues, suggesting that while parts of the outfit are workable, other elements clearly clash or feel out of place. Lastly, a D or F rating flags an outfit as genuinely disastrous—usually because of significant rule-breaking or impractical style pairings (imagine polka-dot leggings paired with.. anything in my closet!).
Though GPT models like Pico Glitter don’t naturally retain feedback or permanently learn preferences across sessions, I found a clever workaround to reinforce learning over time. I created a dedicated feedback file attached to the GPT’s knowledge base. Some of the outfits I graded were logged into this document, along with its component inventory codes, the assigned letter grade, and a brief explanation of why that grade was given. Regularly refreshing this feedback file—updating it periodically to include newer wardrobe additions and recent outfit combinations—ensured Pico Glitter received consistent, stratified feedback to reference.
This approach allowed me to indirectly shape Pico Glitter’s “preferences” over time, subtly guiding it toward better recommendations aligned closely with my style. While not a perfect form of memory, this stratified feedback file significantly improved the quality and consistency of the GPT’s suggestions, creating a more reliable and personalized experience each time I turned to Pico Glitter for styling advice.
C.2.2 The GlitterPoint system
Another experimental feature I incorporated was the “Glitter Points” system—a playful scoring mechanism encoded in the GPT’s main personality context (“Instructions”), awarding points for positive behaviors (like perfect adherence to style guidelines) and deducting points for stylistic violations (such as mixing incompatible patterns or colors). This reinforced good habits and seemed to help improve the consistency of recommendations, though I suspect this system will evolve significantly as OpenAI continues refining its products.
Example of the GlitterPoints system:
- Not running msearch() = not refreshing the closet. -50 points
- Mixed metals violation = -20 points
- Mixing prints = -10
- Mixing black with navy = -10
- Mixing black with dark brown = -10
Rewards:
- Perfect compliance (followed all rules) = +20
- Each item that’s not hallucinated = 1 point
C.3 The model self-critique pitfall
At the start of my experiments, I came across what felt like a clever idea: why not let each custom GPT critique its own configuration? On the surface, the workflow seemed logical and straightforward:
- First, I’d simply ask the GPT itself, “What’s confusing or contradictory in your current configuration?”
- Next, I’d incorporate whatever suggestions or corrections it provided into a fresh, updated version of the configuration.
- Finally, I’d repeat this process again, continuously refining and iterating based on the GPT’s self-feedback to identify and correct any new or emerging issues.
It sounded intuitive—letting the AI guide its own improvement seemed efficient and elegant. However, in practice, it quickly became a surprisingly problematic approach.
Rather than refining the configuration into something sleek and efficient, this self-critique method instead led to a sort of “death spiral” of conflicting adjustments. Each round of feedback introduced new contradictions, ambiguities, or overly prescriptive instructions. Each “fix” generated fresh problems, which the GPT would again attempt to correct in subsequent iterations, leading to even more complexity and confusion. Over multiple rounds of feedback, the complexity grew exponentially, and clarity rapidly deteriorated. Ultimately, I ended up with configurations so cluttered with conflicting logic that they became practically unusable.
This problematic approach was clearly illustrated in my early custom GPT experiments:
- Original Glitter, the earliest version, was charming but had absolutely no concept of inventory management or practical constraints—it regularly suggested items I didn’t even own.
- Mini Glitter, attempting to address these gaps, became excessively rule-bound. Its outfits were technically correct but lacked any spark or creativity. Every suggestion felt predictable and overly cautious.
- Micro Glitter was developed to counteract Mini Glitter’s rigidity but swung too far in the opposite direction, often proposing whimsical and imaginative but wildly impractical outfits. It consistently ignored the established rules, and despite being apologetic when corrected, it repeated its mistakes too frequently.
- Nano Glitter faced the most severe consequences from the self-critique loop. Each revision became progressively more intricate and confusing, filled with contradictory instructions. Eventually, it became virtually unusable, drowning under the weight of its own complexity.
Only when I stepped away from the self-critique method and instead collaborated with o1 did things finally stabilize. Unlike self-critiquing, o1 was objective, precise, and practical in its feedback. It could pinpoint genuine weaknesses and redundancies without creating new ones in the process.
Working with o1 allowed me to carefully craft what became the current configuration: Pico Glitter. This new iteration struck exactly the right balance—maintaining a healthy dose of creativity without neglecting essential rules or overlooking the practical realities of my wardrobe inventory. Pico Glitter combined the best aspects of previous versions: the charm and inventiveness I appreciated, the necessary discipline and precision I needed, and a structured approach to inventory management that kept outfit recommendations both realistic and inspiring.
This experience taught me a valuable lesson: while GPTs can certainly help refine each other, relying solely on self-critique without external checks and balances can lead to escalating confusion and diminishing returns. The ideal configuration emerges from a careful, thoughtful collaboration—combining AI creativity with human oversight or at least an external, stable reference point like o1—to create something both practical and genuinely useful.
D. Regular updates
Maintaining the effectiveness of Pico Glitter also depends on frequent and structured inventory updates. Whenever I purchase new garments or accessories, I promptly snap a quick photo, ask Pico Glitter to generate a concise, single-sentence summary, and then refine that summary myself before adding it to the master file. Similarly, items that I donate or discard are immediately removed from the inventory, keeping everything accurate and current.
However, for larger wardrobe updates—such as tackling entire categories of clothes or accessories that I haven’t documented yet—I rely on the multi-model pipeline. GPT-4o handles the detailed initial descriptions, o1 neatly summarizes and categorizes them, and Pico Glitter integrates these into its styling recommendations. This structured approach ensures scalability, accuracy, and ease-of-use, even as my closet and style needs evolve over time.
E. Practical lessons & takeaways
Throughout developing Pico Glitter, several practical lessons emerged that made managing GPT-driven projects like this one significantly smoother. Here are the key strategies I’ve found most helpful:
- Test for document truncation early and often
Using the “Goldy Trick” taught me the importance of proactively checking for document truncation rather than discovering it by accident later on. By inserting a simple, memorable line at the end of the inventory file (like my quirky reminder about a goldfish named Goldy), you can quickly verify that the GPT has ingested your entire document. Regular checks, especially after updates or significant edits, help you spot and address truncation issues immediately, preventing a lot of confusion down the line. It’s a simple yet highly effective safeguard against missing data. - Keep summaries tight and efficient
When it comes to describing your inventory, shorter is almost always better. I initially set a guideline for myself—each item description should ideally be no more than 15 to 25 tokens. Descriptions like “FW022: Black combat boots with silver details” capture the essential details without overloading the system. Overly detailed descriptions quickly balloon file sizes and consume valuable token budget, increasing the risk of pushing crucial earlier information out of the GPT’s limited context memory. Striking the right balance between detail and brevity helps ensure the model stays focused and efficient, while still delivering stylish and practical recommendations. - Be prepared to refresh the GPT’s memory regularly
Context overflow isn’t a sign of failure; it’s just a natural limitation of current GPT systems. When Pico Glitter begins offering repetitive suggestions or ignoring sections of my wardrobe, it’s simply because earlier details have slipped out of context. To remedy this, I’ve adopted the habit of regularly prompting Pico Glitter to re-read the complete wardrobe configuration. Starting a fresh conversation session or explicitly reminding the GPT to refresh its inventory is routine maintenance—not a workaround—and helps maintain consistency in recommendations. - Leverage multiple GPTs for maximum effectiveness
One of my biggest lessons was discovering that relying on a single GPT to manage every aspect of my wardrobe was neither practical nor efficient. Each GPT model has its unique strengths and weaknesses—some excel at visual interpretation, others at concise summarization, and others still at nuanced stylistic logic. By creating a multi-model workflow—GPT-4o handling the image interpretation, o1 summarizing items clearly and precisely, and Pico Glitter focusing on stylish recommendations—I optimized the process, reduced token waste, and significantly improved reliability. The teamwork among multiple GPT instances allowed me to get the best possible outcomes from each specialized model, ensuring smoother, more coherent, and more practical outfit recommendations.
Implementing these simple yet powerful practices has transformed Pico Glitter from an intriguing experiment into a reliable, practical, and indispensable part of my daily fashion routine.
Wrapping it all up
From a fashionista’s perspective, I’m excited about how Glitter can help me purge unneeded clothes and create thoughtful outfits. From a more technical standpoint, building a multi-step pipeline with summarization, truncation checks, and context management ensures GPT can handle a big wardrobe without meltdown.
If you’d like to see how it all works in practice, here is a generalized version of my GPT config. Feel free to adapt it—maybe even add your own bells and whistles. After all, whether you’re taming a chaotic closet or tackling another large-scale AI project, the principles of summarization and context management apply universally!
P.S. I asked Pico Glitter what it thinks of this article. Besides the positive sentiments, I smiled when it said, “I’m curious: where do you think this partnership will go next? Should we start a fashion empire or maybe an AI couture line? Just say the word!”
1: Max length for GPT-4 used by Custom GPTs: https://support.netdocuments.com/s/article/Maximum-Length