Imagine you’re building your dream home. Just about everything is ready. All that’s left to do is pick out a front door. Since the neighborhood has a low crime rate, you decide you want a door with a standard lock — nothing too fancy, but probably enough to deter 99.9% of would-be burglars.
Unfortunately, the local homeowners’ association (HOA) has a rule stating that all front doors in the neighborhood must be bank vault doors. Their reasoning? Bank vault doors are the only doors that have been mathematically proven to be absolutely secure. As far as they’re concerned, any front door below that standard may as well not be there at all.
You’re left with three options, none of which seems particularly appealing:
- Concede defeat and have a bank vault door installed. Not only is this expensive and cumbersome, but you’ll be left with a front door that bogs you down every single time you want to open or close it. At least burglars won’t be a problem!
- Leave your house doorless. The HOA rule imposes requirements on any front door in the neighborhood, but it doesn’t technically forbid you from not installing a door at all. That would save you a lot of time and money. The downside, of course, is that it would allow anyone to come and go as they please. On top of that, the HOA could always close the loophole, taking you back to square one.
- Opt out entirely. Faced with such a stark dilemma (all-in on either security or practicality), you choose not to play the game at all, selling your nearly-complete house and looking for someplace else to live.
This scenario is obviously completely unrealistic. In real life, everybody strives to strike an appropriate balance between security and practicality. This balance is informed by everyone’s own circumstances and risk analysis, but it universally lands somewhere between the two extremes of bank vault door and no door at all.
But what if instead of your dream home, you imagined a medical AI model that has the power to help doctors improve patient outcomes? Highly-sensitive training data points from patients are your valuables. The privacy protection measures you take are the front door you choose to install. Healthcare providers and the scientific community are the HOA.
Suddenly, the scenario is much closer to reality. In this article, we’ll explore why that is. After understanding the problem, we’ll consider a simple but empirically effective solution proposed in the paper Reconciling privacy and accuracy in AI for medical imaging [1]. The authors propose a balanced alternative to the three bad choices laid out above, much like the real-life approach of a typical front door.
The State of Patient Privacy in Medical AI
Over the past few years, artificial intelligence has become an ever more ubiquitous part of our day-to-day lives, proving its utility across a wide range of domains. The rising use of AI models has, however, raised questions and concerns about protecting the privacy of the data used to train them. You may remember the well-known case of ChatGPT, just months after its initial release, exposing proprietary code from Samsung [2].
Some of the privacy risks associated with AI models are obvious. For example, if the training data used for a model isn’t stored securely enough, bad actors could find ways to access it directly. Others are more insidious, such as the risk of reconstruction. As the name implies, in a reconstruction attack, a bad actor attempts to reconstruct a model’s training data without needing to gain direct access to the dataset.
Medical records are one of the most sensitive kinds of personal information there are. Although specific regulation varies by jurisdiction, patient data is generally subject to stringent safeguards, with hefty fines for inadequate protection. Beyond the letter of the law, unintentionally exposing such data could irreparably damage our ability to use specialized AI to empower medical professionals.
As Ziller, Mueller, Stieger, et al. point out [1], fully taking advantage of medical AI requires rich datasets comprising information from actual patients. This information must be obtained with the full consent of the patient. Ethically acquiring medical data for research was challenging enough as it was before the unique challenges posed by AI came into play. But if proprietary code being exposed caused Samsung to ban the use of ChatGPT [2], what would happen if attackers managed to reconstruct MRI scans and identify the patients they belonged to? Even isolated instances of negligent protection against data reconstruction could end up being a monumental setback for medical AI as a whole.
Tying this back into our front door metaphor, the HOA statute calling for bank vault doors starts to make a little bit more sense. When the cost of a single break-in could be so catastrophic for the entire neighborhood, it’s only natural to want to go to any lengths to prevent them.
Differential Privacy (DP) as a Theoretical Bank Vault Door
Before we discuss what an appropriate balance between privacy and practicality might look like in the context of medical AI, we have to turn our attention to the inherent tradeoff between protecting an AI model’s training data and optimizing for quality of performance. This will set the stage for us to develop a basic understanding of Differential Privacy (DP), the theoretical gold standard of privacy protection.
Although academic interest in training data privacy has increased significantly over the past four years, principles on which much of the conversation is based were pointed out by researchers well before the recent LLM boom, and even before OpenAI was founded in 2015. Though it doesn’t deal with reconstruction per se, the 2013 paper Hacking smart machines with smarter ones [3] demonstrates a generalizable attack methodology capable of accurately inferring statistical properties of machine learning classifiers, noting:
“Although ML algorithms are known and publicly released, training sets may not be reasonably ascertainable and, indeed, may be guarded as trade secrets. While much research has been performed about the privacy of the elements of training sets, […] we focus our attention on ML classifiers and on the statistical information that can be unconsciously or maliciously revealed from them. We show that it is possible to infer unexpected but useful information from ML classifiers.” [3]
Theoretical data reconstruction attacks were described even earlier, in a context not directly pertaining to machine learning. The landmark 2003 paper Revealing information while preserving privacy [4] demonstrates a polynomial-time reconstruction algorithm for statistical databases. (Such databases are intended to provide answers to questions about their data in aggregate while keeping individual data points anonymous.) The authors show that to mitigate the risk of reconstruction, a certain amount of noise needs to be introduced into the data. Needless to say, perturbing the original data in this way, while necessary for privacy, has implications for the quality of the responses to queries, i.e., the accuracy of the statistical database.
In explaining the purpose of DP in the first chapter of their book The Algorithmic Foundations of Differential Privacy [5], Cynthia Dwork and Aaron Roth address this tradeoff between privacy and accuracy:
“[T]he Fundamental Law of Information Recovery states that overly accurate answers to too many questions will destroy privacy in a spectacular way. The goal of algorithmic research on differential privacy is to postpone this inevitability as long as possible. Differential privacy addresses the paradox of learning nothing about an individual while learning useful information about a population.” [5]
The notion of “learning nothing about an individual while learning useful information about a population” is captured by considering two datasets that differ by a single entry (one that includes the entry and one that doesn’t). An (ε, δ)-differentially private querying mechanism is one for which the probability of a certain output being returned when querying one dataset is at most a multiplicative factor of the probability when querying the other dataset. Denoting the mechanism by M, the set of possible outputs by S, and the datasets by x and y, we formalize this as [5]:
Pr[M(x) ∈ S] ≤ exp(ε) ⋅ Pr[M(y) ∈ S] + δ
Where ε is the privacy loss parameter and δ is the failure probability parameter. ε quantifies how much privacy is lost as a result of a query, while a positive δ allows for privacy to fail altogether for a query at a certain (usually very low) probability. Note that ε is an exponential parameter, meaning that even slightly increasing it can cause privacy to decay significantly.
An important and useful property of DP is composition. Notice that the definition above only applies to cases where we run a single query. The composition property helps us generalize it to cover multiple queries based on the fact that privacy loss and failure probability accumulate predictably when we compose several queries, be they based on the same mechanism or different ones. This accumulation is easily proven to be (at most) linear [5]. What this means is that, rather than considering a privacy loss parameter for one query, we may view ε as a privacy budget that can be utilized across a number of queries. For example, when taken together, one query using a (1, 0)-DP mechanism and two queries using a (0.5, 0)-DP mechanism satisfy (2, 0)-DP.
The value of DP comes from the theoretical privacy guarantees it promises. Setting ε = 1 and δ = 0, for example, we find that the probability of any given output occurring when querying dataset y is at most exp(1) = e ≈ 2.718 times greater than that same output occurring when querying dataset x. Why does this matter? Because the greater the discrepancy between the probabilities of certain outputs occurring, the easier it is to determine the contribution of the individual entry by which the two datasets differ, and the easier it is to ultimately reconstruct that individual entry.
In practice, designing an (ε, δ)-differentially private randomized mechanism entails the addition of random noise drawn from a distribution dependent on ε and δ. The specifics are beyond the scope of this article. Shifting our focus back to machine learning, though, we find that the idea is the same: DP for ML hinges on introducing noise into the training data, which yields robust privacy guarantees in much the same way.
Of course, this is where the tradeoff we mentioned comes into play. Adding noise to the training data comes at the cost of making learning more difficult. We could absolutely add enough noise to achieve ε = 0.01 and δ = 0, making the difference in output probabilities between x and y virtually nonexistent. This would be wonderful for privacy, but terrible for learning. A model trained on such a noisy dataset would perform very poorly on most tasks.
There is no consensus on what constitutes a “good” ε value, or on universal methodologies or best practices for ε selection [6]. In many ways, ε embodies the privacy/accuracy tradeoff, and the “proper” value to aim for is highly context-dependent. ε = 1 is generally regarded as offering high privacy guarantees. Although privacy diminishes exponentially with respect to ε, values as high as ε = 32 are mentioned in literature and thought to provide moderately strong privacy guarantees [1].
The authors of Reconciling privacy and accuracy in AI for medical imaging [1] test the effects of DP on the accuracy of AI models on three real-world medical imaging datasets. They do so using various values of ε and comparing them to a non-private (non-DP) control. Table 1 provides a partial summary of their results for ε = 1 and ε = 8:

Even approaching the higher end of the typical ε values attested in literature, DP is still as cumbersome as a bank vault door for medical imaging tasks. The noise introduced into the training data is catastrophic for AI model accuracy, especially when the datasets at hand are small. Note, for example, the huge drop-off in Dice score on the MSD Liver dataset, even with the relatively high ε value of 8.
Ziller, Mueller, Stieger, et al. suggest that the accuracy drawbacks of DP with typical ε values may contribute to the lack of widespread adoption of DP in the field of Medical Ai [1]. Yes, wanting mathematically-provable privacy guarantees is definitely sensible, but at what cost? Leaving so much of the diagnostic power of AI models on the table in the name of privacy is not an easy choice to make.
Revisiting our dream home scenario armed with an understanding of DP, we find that the options we (seem to) have map neatly onto the three we had for our front door.
- DP with typical values of ε is like installing a bank vault door: costly, but effective for privacy. As we’ll see, it’s also complete overkill in this case.
- Not using DP is like not installing a door at all: much easier, but risky. As mentioned above, though, DP has yet to be widely applied in medical AI [1].
- Passing up opportunities to use AI is like giving up and selling the house: it saves us the headache of dealing with privacy concerns weighed against incentives to maximize accuracy, but a lot of potential is lost in the process.
It looks like we’re at an impasse… unless we think outside the box.
High-Budget DP: Privacy and Accuracy Aren’t an Either/Or
In Reconciling privacy and accuracy in AI for medical imaging [1], Ziller, Mueller, Stieger, et al. offer the medical AI equivalent of a regular front door — an approach that manages to protect privacy while giving up very little in the way of model performance. Granted, this protection is not theoretically optimal — far from it. However, as the authors show through a series of experiments, it is good enough to counter almost any realistic threat of reconstruction.
As the saying goes, “Perfect is the enemy of good.” In this case, it is the “optimal” — an insistence on arbitrarily low ε values — that locks us into the false dichotomy of total privacy versus total accuracy. Just as a bank vault door has its place in the real world, so does DP with ε ≤ 32. Still, the existence of the bank vault door doesn’t mean plain old front doors don’t also have a place in the world. The same goes for high-budget DP.
The idea behind high-budget DP is straightforward: using privacy budgets (ε values) that are so high that they “are near-universally shunned as being meaningless” [1] — budgets ranging from ε = 10⁶ to as high as ε = 10¹⁵. In theory, these provide such weak privacy guarantees that it seems like common sense to dismiss them as no better than not using DP at all. In practice, though, this couldn’t be further from the truth. As we will see by looking at the results from the paper, high-budget DP shows significant promise in countering realistic threats. As Ziller, Mueller, Stieger, et al. put it [1]:
“[E]ven a ‘pinch of privacy’ has drastic effects in practical scenarios.”
First, though, we need to ask ourselves what we consider to be a “realistic” threat. Any discussion of the efficacy of high-budget DP is inextricably tied to the threat model under which we choose to evaluate it. In this context, a threat model is simply the set of assumptions we make about what a bad actor interested in obtaining our model’s training data is able to do.

The paper’s findings hinge on a calibration of the assumptions to better suit real-world threats to patient privacy. The authors argue that the worst-case model, which is the one typically used for DP, is far too pessimistic. For example, it assumes that the adversary has full access to each original image while attempting to reconstruct it based on the AI model (see Table 2) [1]. This pessimism explains the discrepancy between the reported “drastic effects in practical scenarios” of high privacy budgets and the very weak theoretical privacy guarantees that they offer. We may liken it to incorrectly assessing the security threats a typical house faces, wrongly assuming they are likely to be as sophisticated and enduring as those faced by a bank.
The authors therefore propose two alternative threat models, which they call the “relaxed” and “realistic” models. Under both of these, adversaries keep some core capabilities from the worst-case model: access to the AI model’s architecture and weights, the ability to manipulate its hyperparameters, and unbounded computational abilities (see Table 2). The realistic adversary is assumed to have no access to the original images and an imperfect reconstruction algorithm. Even these assumptions leave us with a rigorous threat model that may still be considered pessimistic for most real-world scenarios [1].
Having established the three relevant threat models to consider, Ziller, Mueller, Stieger, et al. compare AI model accuracy in conjunction with the reconstruction risk under each threat model at different values of ε. As we saw in Table 1, this is done for three exemplary Medical Imaging datasets. Their full results are presented in Table 3:

Unsurprisingly, high privacy budgets (exceeding ε = 10⁶) significantly mitigate the loss of accuracy seen with lower (stricter) privacy budgets. Across all tested datasets, models trained with high-budget DP at ε = 10⁹ (HAM10000, MSD Liver) or ε = 10¹² (RadImageNet) perform nearly as well as their non-privately trained counterparts. This is in line with our understanding of the privacy/accuracy tradeoff: the less noise introduced into the training data, the better a model can learn.
What is surprising is the degree of empirical protection afforded by high-budget DP against reconstruction under the realistic threat model. Remarkably, the realistic reconstruction risk is assessed to be 0% for each of the aforementioned models. The high efficacy of high-budget DP in defending medical AI training images against realistic reconstruction attacks is made even clearer by looking at the results of reconstruction attempts. Figure 1 below shows the five most readily reconstructed images from the MSD Liver dataset [9] using DP with high privacy budgets of ε = 10⁶, ε = 10⁹, ε = 10¹², and ε = 10¹⁵.
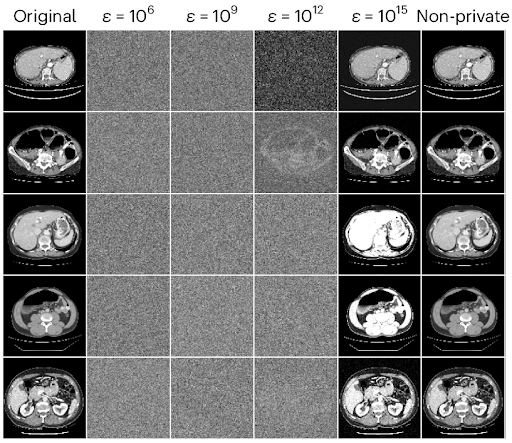
Note that, at least to the naked eye, even the best reconstructions obtained when using the former two budgets are visually indistinguishable from random noise. This lends intuitive credence to the argument that budgets often deemed too high to provide any meaningful protection could be instrumental in protecting privacy without giving up accuracy when using AI for medical imaging. In contrast, the reconstructions when using ε = 10¹⁵ closely resemble the original images, showing that not all high budgets are created equal.
Based on their findings, Ziller, Mueller, Stieger, et al. make the case for training medical imaging AI models using (at least) high-budget DP as the norm. They note the empirical efficacy of high-budget DP in countering realistic reconstruction risks at very little cost in terms of model accuracy. The authors go so far as to claim that “it seems negligent to train AI models without any form of formal privacy guarantee.” [1]
Conclusion
We started with a hypothetical scenario in which you were forced to decide between a bank vault door or no door at all for your dream home (or giving up and selling the incomplete house). After an exploration of the risks posed by inadequate privacy protection in medical AI, we looked into the privacy/accuracy tradeoff as well as the history and theory behind reconstruction attacks and differential privacy (DP). We then saw how DP with common privacy budgets (ε values) degrades medical AI model performance and compared it to the bank vault door in our hypothetical.
Finally, we examined empirical results from the paper Reconciling privacy and accuracy in AI for medical imaging to find out how high-budget differential privacy can be used to escape the false dichotomy of bank vault door vs. no door and protect Patient Privacy in the real world without sacrificing model accuracy in the process.
If you enjoyed this article, please consider following me on LinkedIn to keep up with future articles and projects.
References
[1] Ziller, A., Mueller, T.T., Stieger, S. et al. Reconciling privacy and accuracy in AI for medical imaging. Nat Mach Intell 6, 764–774 (2024). https://doi.org/10.1038/s42256-024-00858-y.
[2] Ray, S. Samsung bans ChatGPT and other chatbots for employees after sensitive code leak. Forbes (2023). https://www.forbes.com/sites/siladityaray/2023/05/02/samsung-bans-chatgpt-and-other-chatbots-for-employees-after-sensitive-code-leak/.
[3] Ateniese, G., Mancini, L. V., Spognardi, A. et al. Hacking smart machines with smarter ones: how to extract meaningful data from machine learning classifiers. International Journal of Security and Networks 10, 137–150 (2015). https://doi.org/10.48550/arXiv.1306.4447.
[4] Dinur, I. & Nissim, K. Revealing information while preserving privacy. Proc. 22nd ACM SIGMOD-SIGACT-SIGART Symp Principles Database Syst 202–210 (2003). https://doi.org/10.1145/773153.773173.
[5] Dwork, C. & Roth, A. The algorithmic foundations of differential privacy. Foundations and Trends in Theoretical Computer Science 9, 211–407 (2014). https://doi.org/10.1561/0400000042.
[6] Dwork, C., Kohli, N. & Mulligan, D. Differential privacy in practice: expose your epsilons! Journal of Privacy and Confidentiality 9 (2019). https://doi.org/10.29012/jpc.689.
[7] Mei, X., Liu, Z., Robson, P.M. et al. RadImageNet: an open radiologic deep learning research dataset for effective transfer learning. Radiol Artif Intell 4.5, e210315 (2022). https://doi.org/10.1148/ryai.210315.
[8] Tschandl, P., Rosendahl, C. & Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci Data 5, 180161 (2018). https://doi.org/10.1038/sdata.2018.161.
[9] Antonelli, M., Reinke, A., Bakas, S. et al. The Medical Segmentation Decathlon. Nat Commun 13, 4128 (2022). https://doi.org/10.1038/s41467-022-30695-9.


















