The first Gemma model launched early last year and has since grown into a thriving Gemmaverse of over 160 million collective downloads. This ecosystem includes our family of over a dozen specialized models for everything from safeguarding to medical applications and, most inspiringly, the countless innovations from the community. From innovators like Roboflow building enterprise computer vision to the Institute of Science Tokyo creating highly-capable Japanese Gemma variants, your work has shown us the path forward.
Building on this incredible momentum, we’re excited to announce the full release of Gemma 3n. While last month’s preview offered a glimpse, today unlocks the full power of this mobile-first architecture. Gemma 3n is designed for the developer community that helped shape Gemma. It’s supported by your favorite tools including Hugging Face Transformers, llama.cpp, Google AI Edge, Ollama, MLX, and many others, enabling you to fine-tune and deploy for your specific on-device applications with ease. This post is the developer deep dive: we’ll explore some of the innovations behind Gemma 3n, share new benchmark results, and show you how to start building today.
What’s new in Gemma 3n?
Gemma 3n represents a major advancement for on-device AI, bringing powerful multimodal capabilities to edge devices with performance previously only seen in last year’s cloud-based frontier models.
Achieving this leap in on-device performance required rethinking the model from the ground up. The foundation is Gemma 3n’s unique mobile-first architecture, and it all starts with MatFormer.
MatFormer: One model, many sizes
At the core of Gemma 3n is the MatFormer (🪆Matryoshka Transformer) architecture, a novel nested transformer built for elastic inference. Think of it like Matryoshka dolls: a larger model contains smaller, fully functional versions of itself. This approach extends the concept of Matryoshka Representation Learning from just embeddings to all transformer components.
During the MatFormer training of the 4B effective parameter (E4B) model, a 2B effective parameter (E2B) sub-model is simultaneously optimized within it, as shown in the figure above. This provides developers two powerful capabilities and use cases today:
1: Pre-extracted models: You can directly download and use either the main E4B model for the highest capabilities, or the standalone E2B sub-model which we have already extracted for you, offering up to 2x faster inference.
2: Custom sizes with Mix-n-Match: For more granular control tailored to specific hardware constraints, you can create a spectrum of custom-sized models between E2B and E4B using a method we call Mix-n-Match. This technique allows you to precisely slice the E4B model’s parameters, primarily by adjusting the feed forward network hidden dimension per layer (from 8192 to 16384) and selectively skipping some layers. We are releasing the MatFormer Lab, a tool that shows how to retrieve these optimal models, which were identified by evaluating various settings on benchmarks like MMLU.
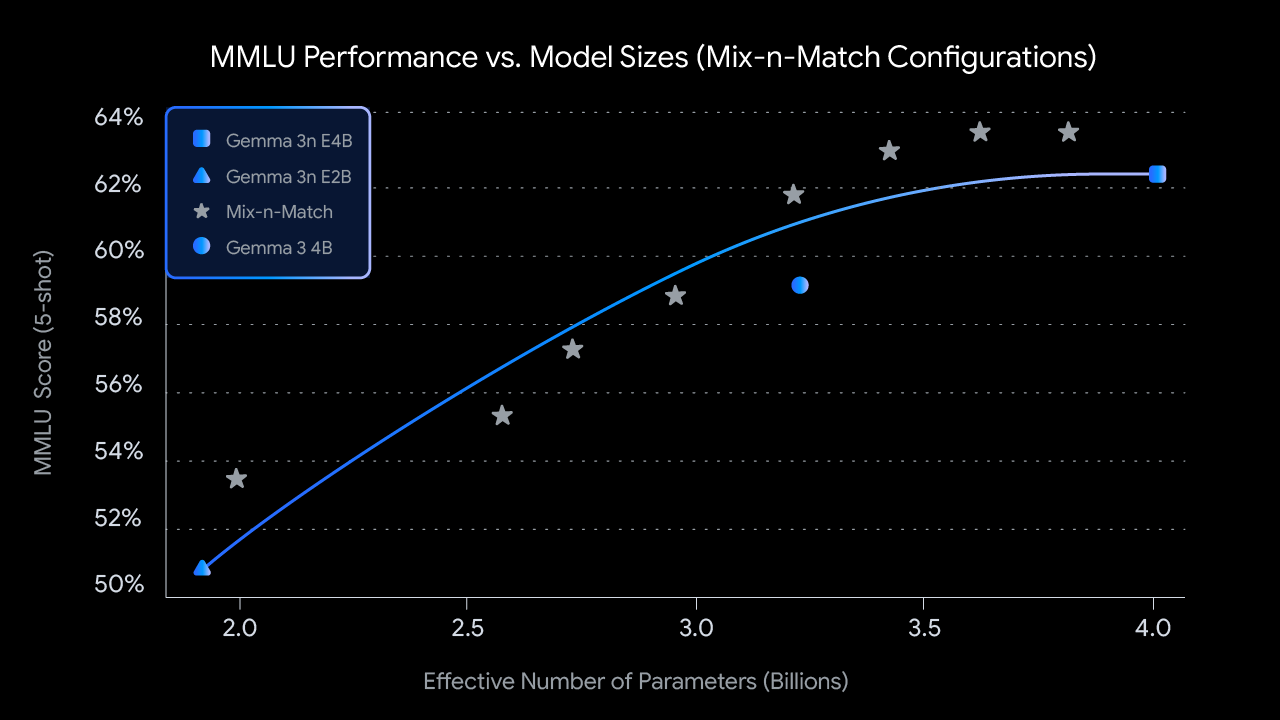
MMLU scores for the pre-trained Gemma 3n checkpoints at different model sizes (using Mix-n-Match)
Looking ahead, the MatFormer architecture also paves the way for elastic execution. While not part of today’s launched implementations, this capability allows a single deployed E4B model to dynamically switch between E4B and E2B inference paths on the fly, enabling real-time optimization of performance and memory usage based on the current task and device load.
Per-Layer Embeddings (PLE): Unlocking more memory efficiency
Gemma 3n models incorporate Per-Layer Embeddings (PLE). This innovation is tailored for on-device deployment as it dramatically improves model quality without increasing the high-speed memory footprint required on your device’s accelerator (GPU/TPU).
While the Gemma 3n E2B and E4B models have a total parameter count of 5B and 8B respectively, PLE allows a significant portion of these parameters (the embeddings associated with each layer) to be loaded and computed efficiently on the CPU. This means only the core transformer weights (approximately 2B for E2B and 4B for E4B) need to sit in the typically more constrained accelerator memory (VRAM).

With Per-Layer Embeddings, you can use Gemma 3n E2B while only having ~2B parameters loaded in your accelerator.
KV Cache sharing: Faster long-context processing
Processing long inputs, such as the sequences derived from audio and video streams, is essential for many advanced on-device multimodal applications. Gemma 3n introduces KV Cache Sharing, a feature designed to significantly accelerate time-to-first-token for streaming response applications.
KV Cache Sharing optimizes how the model handles the initial input processing stage (often called the “prefill” phase). The keys and values of the middle layer from local and global attention are directly shared with all the top layers, delivering a notable 2x improvement on prefill performance compared to Gemma 3 4B. This means the model can ingest and understand lengthy prompt sequences much faster than before.
Audio understanding: Introducing speech to text and translation
Gemma 3n uses an advanced audio encoder based on the Universal Speech Model (USM). The encoder generates a token for every 160ms of audio (about 6 tokens per second), which are then integrated as input to the language model, providing a granular representation of the sound context.
This integrated audio capability unlocks key features for on-device development, including:
- Automatic Speech Recognition (ASR): Enable high-quality speech-to-text transcription directly on the device.
- Automatic Speech Translation (AST): Translate spoken language into text in another language.
We’ve observed particularly strong AST results for translation between English and Spanish, French, Italian, and Portuguese, offering great potential for developers targeting applications in these languages. For tasks like speech translation, leveraging Chain-of-Thought prompting can significantly enhance results. Here’s an example:
user
Transcribe the following speech segment in Spanish, then translate it into English:
modelPlain text
At launch time, the Gemma 3n encoder is implemented to process audio clips up to 30 seconds. However, this is not a fundamental limitation. The underlying audio encoder is a streaming encoder, capable of processing arbitrarily long audios with additional long form audio training. Follow-up implementations will unlock low-latency, long streaming applications.
MobileNet-V5: New state-of-the-art vision encoder
Alongside its integrated audio capabilities, Gemma 3n features a new, highly efficient vision encoder, MobileNet-V5-300M, delivering state-of-the-art performance for multimodal tasks on edge devices.
Designed for flexibility and power on constrained hardware, MobileNet-V5 gives developers:
- Multiple input resolutions: Natively supports resolutions of 256×256, 512×512, and 768×768 pixels, allowing you to balance performance and detail for your specific applications.
- Broad visual understanding: Co-trained on extensive multimodal datasets, it excels at a wide range of image and video comprehension tasks.
- High throughput: Processes up to 60 frames per second on a Google Pixel, enabling real-time, on-device video analysis and interactive experiences.
This level of performance is achieved with multiple architectural innovations, including:
- An advanced foundation of MobileNet-V4 blocks (including Universal Inverted Bottlenecks and Mobile MQA).
- A significantly scaled up architecture, featuring a hybrid, deep pyramid model that is 10x larger than the biggest MobileNet-V4 variant.
- A novel Multi-Scale Fusion VLM adapter that enhances the quality of tokens for better accuracy and efficiency.
Benefiting from novel architectural designs and advanced distillation techniques, MobileNet-V5-300M substantially outperforms the baseline SoViT in Gemma 3 (trained with SigLip, no distillation). On a Google Pixel Edge TPU, it delivers a 13x speedup with quantization (6.5x without), requires 46% fewer parameters, and has a 4x smaller memory footprint, all while providing significantly higher accuracy on vision-language tasks
We’re excited to share more about the work behind this model. Look out for our upcoming MobileNet-V5 technical report, which will deep dive into the model architecture, data scaling strategies, and advanced distillation techniques.
Making Gemma 3n accessible from day one has been a priority. We’re proud to partner with many incredible open source developers to ensure broad support across popular tools and platforms, including contributions from teams behind AMD, Axolotl, Docker, Hugging Face, llama.cpp, LMStudio, MLX, NVIDIA, Ollama, RedHat, SGLang, Unsloth, and vLLM.
But this ecosystem is just the beginning. The true power of this technology is in what you will build with it. That’s why we’re launching the Gemma 3n Impact Challenge. Your mission: use Gemma 3n’s unique on-device, offline, and multimodal capabilities to build a product for a better world. With $150,000 in prizes, we’re looking for a compelling video story and a “wow” factor demo that shows real-world impact. Join the challenge and help build a better future.
Get started with Gemma 3n today
Ready to explore the potential of Gemma 3n today? Here’s how:
- Experiment directly: Use Google AI Studio to try Gemma 3n in just a couple of clicks. Gemma models can also be deployed directly to Cloud Run from AI Studio.
- Learn & integrate: Dive into our comprehensive documentation to quickly integrate Gemma into your projects or start with our inference and fine-tuning guides.