AI
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

Bitcoin:
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

Datacenter:
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

Energy:
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

The one piece of data that could actually shed light on your job and AI
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here. Within Silicon Valley’s orbit, an AI-fueled jobs apocalypse is spoken about as a given. The mood is so grim that a societal impacts researcher at Anthropic, responding Wednesday to a call for more optimistic visions of AI’s future, said there might be a recession in the near term and a “breakdown of the early-career ladder.” Her less-measured colleague Dario Amodei, the company’s CEO, has called AI “a general labor substitute for humans” that could do all jobs in less than five years. And those ideas are not just coming from Anthropic, of course. These conversations have unsurprisingly left many workers in a panic (and are probably contributing to support for efforts to entirely pause the construction of data centers, some of which gained steam last week). The panic isn’t being helped by lawmakers, none of whom have articulated a coherent plan for what comes next. Even economists who have cautioned that AI has not yet cut jobs and may not result in a cliff ahead are coming around to the idea that it could have a unique and unprecedented impact on how we work.
Alex Imas, based at the University of Chicago, is one of those economists. He shared two things with me when we spoke on Friday morning: a blunt assessment that our tools for predicting what this will look like are pretty abysmal, and a “call to arms” for economists to start collecting the one type of data that could make a plan to address AI in the workforce possible at all. On our abysmal tools: consider the fact that any job is made up of individual tasks. One part of a real estate agent’s job, for example, is to ask clients what sort of property they want to buy. The US government chronicled thousands of these tasks in a massive catalogue first launched in 1998 and updated regularly since then. This was the data that researchers at OpenAI used in December to judge how “exposed” a job is to AI (they found a real estate agent to be 28% exposed, for example). Then in February, Anthropic used this data in its analysis of millions of Claude conversations to see which tasks people are actually using its AI to complete and where the two lists overlapped.
But knowing the AI exposure of tasks leads to an illusory understanding of how much a given job is at risk, Imas says. “Exposure alone is a completely meaningless tool for predicting displacement,” he told me. Sure, it is illustrative in the gloomiest case—for a job in which literally every task could be done by AI with no human direction. If it costs less for an AI model to do all those tasks than what you’re paid—which is not a given, since reasoning models and agentic AI can rack up quite a bill—and it can do them well, the job likely disappears, Imas says. This is the oft-mentioned case of the elevator operator from decades ago; maybe today’s parallel is a customer service agent solely doing phone call triage. But for the vast majority of jobs, the case is not so simple. And the specifics matter, too: Some jobs are likely to have dark days ahead, but knowing how and when this will play out is hard to answer when only looking at exposure. Take writing code, for example. Someone who builds premium dating apps, let’s say, might use AI coding tools to create in one day what used to take three days. That means the worker is more productive. The worker’s employer, spending the same amount of money, can now get more output. So then will the employer want more employees or fewer? This is the question that Imas says should keep any policymaker up at night, because the answer will change depending on the industry. And we are operating in the dark. In this coder’s case, these efficiencies make it possible for dating apps to lower prices. (A skeptic might expect companies to simply pocket the gains, but in a competitive market, they risk being undercut if they do.) These lower prices will always drive some increase in demand for the apps. But how much? If millions more people want it, the company might grow and ultimately hire more engineers to meet this demand. But if demand barely ticks up—maybe the people who don’t use premium dating apps still won’t want them even at a lower price—fewer coders are needed, and layoffs will happen. Repeat this hypothetical across every job with tasks that AI can do, and you have the most pressing economic question of our time: the specifics of price elasticity, or how much demand for something changes when its price changes. And this is the second part of what Imas emphasized last week: We don’t currently have this data across the economy. But we could. We do have the numbers for grocery items like cereal and milk, Imas says, because the University of Chicago partners with supermarkets to get data from their price scanners. But we don’t have such figures for tutors or web developers or dietitians (all jobs found to have “exposure” to AI, by the way). Or at least not in a way that’s been widely compiled or made accessible to researchers; sometimes it’s scattered across private companies or consultancies. “We need, like, a Manhattan Project to collect this,” Imas says. And we don’t need it just for jobs that could obviously be affected by AI now: “Fields that are not exposed now will become exposed in the future, so you just want to track these statistics across the entire economy.” Getting all this information would take time and money, but Imas makes the case that it’s worth it; it would give economists the first realistic look at how our AI-enabled future could unfold and give policymakers a shot at making a plan for it.

Two New England states say no to new data centers
It’s getting harder and harder for governments to ignore the impact that data centers are having on their communities, consuming vast amounts of water and driving up electricity prices, experts say. According to a Pew Research Center analysis, data centers consumed 183 terawatt-hours of electricity in 2024, more than 4% of total U.S. electricity use. That demand is projected to more than double to 426 terawatt-hours by 2030. The impact is significant. In 2023, data centers consumed about 26% of Virginia’s electricity supply, although Virginia is notable for having an extremely dense collection of data centers. Alan Howard, senior analyst for infrastructure at Omdia, says he is not surprised at all. “The amount of national press coverage regarding what is arguably a limited number of data center ‘horror’ stories has many jurisdictions and states spooked over the potential impacts data center projects might have,” he said. It’s an evolution that’s been coming for some time whereby local legislators have embraced the idea that they don’t want to learn the hard way as others already have, he argues. “All that said, it seems unlikely that there will be broad bans on data center development that would cripple the industry. There’s lots of places to go in the U.S. and developers have warmed up to siting projects in places amenable to their needs, although not ideally convenient,” said Howard.
AI for IT stalls as network complexity rises
There are a number of network-related issues that are driving enterprises to delay or abandon their AI projects, according to IDC’s special report on AI in networking. Organizations expect business benefits, including improved IT service levels, to come from using AI across their network infrastructure, according to IDC’s special report on AI in networking.

AI is changing how small online sellers decide what to make
For years Mike McClary sold the Guardian LTE Flashlight, a heavy-duty black model, online through his small outdoor brand. The product, designed for brightness and durability, became one of his most popular items ever. Even after he stopped offering it around 2017, customers kept sending him emails asking where they could buy it. When McClary decided to revisit the Guardian flashlight in 2025, he didn’t begin the way he might have in the past, by combing through supplier listings and sending inquiries to factories. Instead, he opened Accio, an AI sourcing and researching tool on Alibaba.com. For small entrepreneurs in the US, deciding what to sell and where to make it has traditionally been a slow, labor-intensive process that can take months. Now that work is increasingly being done by AI tools like Accio, which help connect businesses with manufacturers in countries including China and India. Business owners and e-commerce experts told MIT Technology Review that these AI tools are making sourcing more accessible and significantly shortening the time it takes to go from product idea to launch. McClary, 51, who runs his business from his Illinois living room, has sold products ranging from leather conditioner to camping lights, including one rechargeable lantern that brought in half a million dollars. Like many small online merchants, he built his business by being extremely scrappy—spotting demand for a product, tweaking existing designs, finding a factory, doing modest marketing, and getting the goods in front of customers fast.
This time, though, he began by telling Accio about the flashlight’s original design, production cost, and profit margin. Then Accio suggested several changes, making it smaller and slightly less bright and switching its charging method to battery power. It also identified a manufacturer in Ningbo, China, that McClary said could cut the manufacturing cost from $17 to about $2.50 per unit. McClary took the process from there, contacting the supplier himself to discuss the revised design. Within a month, the new version of the Guardian flashlight was back up for sale on Amazon and on his brand’s website.
The new factory hunt Although Alibaba is better known for owning Taobao, the biggest shopping site in China, its first business was Alibaba.com, the primary website that lists Chinese factories open for bulk orders. Placing an order with a manufacturer usually requires far more than clicking “Buy.” Sellers often spend days or weeks browsing listings, comparing suppliers’ reviews and manufacturing capacities, asking about minimum order quantities, requesting samples, and negotiating timelines and customization options. But Accio has gained significant momentum by changing how that sourcing gets done. Launched in 2024, Accio exceeded 10 million monthly active users in March 2026, according to the company. That means about one in five Alibaba users consults with AI about product sourcing. Accio’s interface looks a lot like ChatGPT or Claude: Users type a question into an empty box and choose between “fast” and “thinking” modes. But when asked about products, the tool returns more than text, offering charts, links, and visuals and asking follow-up questions to clarify the buyer’s needs. It then narrows the field to one or a handful of suppliers that appear capable of delivering. After that, the human work begins: Users still have to reach out to suppliers themselves and negotiate the details. Zhang Kuo, the president of Alibaba.com, told MIT Technology Review that the tool is built on multiple frontier models, including the company’s own Qwen series, a popular family of open-source large language models. The system is able to pull from the site’s millions of supplier profiles and is trained on 26 years of proprietary transaction data. For tasks like product research and sourcing analysis, the tool “blows it away” compared with general AI tools like ChatGPT, says Richard Kostick, CEO of the beauty brand 100% Pure. Many websites have tried using AI to assist shopping, but Alibaba has been one of the most aggressive. In March, Eddie Wu, CEO of the site’s parent company Alibaba Group, told managers that integrating the company’s core services with Qwen’s AI capabilities is a top priority. During a Chinese New Year promotion of Qwen’s personal shopping AI agent, where the company gave away cash, customers placed 200 million orders, the firm says. Vincenzo Toscano, an e-commerce seller and consultant, recommended Accio to his clients before deciding to try it himself for a new sunglasses brand. He came in with a rough vision: a brand shaped by his Italian heritage, his personal style, and a boutique aesthetic. He says the AI helped turn that concept into something more concrete, suggesting materials, refining the look, and pointing to design ideas that felt current. But the tool has clear limits. McClary, who uses AI tools regularly, says Accio is strongest when it comes to product ideation, but less helpful on marketing questions such as advertising and social media outreach. To use it well, he says, buyers still need to challenge its recommendations, since some can be generic.
The rest of the business As platforms become more AI-driven, manufacturers are adjusting too. Sally Yan, a representative at a makeup packaging company in Wuhan, China, says her firm has started writing more detailed product descriptions and adding information about its equipment and manufacturing experience on Alibaba.com because it suspects those details make its listings more likely to be surfaced by AI. Yan says manufacturers cannot tell whether an inquiry from a customer was generated or guided by AI, and that her firm is not using AI to negotiate pricing or product details. “AI agents are increasingly used by people to assist decision making or even directly making transactions, and in certain situations, they can become extremely useful,” “AI agents are increasingly used by people to assist purchase decisions and even directly making transactions, and with clear data guardrails, they can become extremely useful,” says Jiaxin Pei, a research scientist at the Stanford Institute for Human-Centered AI, “but agents need to act transparently, securely, and in the customer’s best interest.” Pei says developers of these tools should disclose the data they collect and the incentives built into them to ensure that the marketplace remains fair. Zhang, of Alibaba.com, says Accio currently does not include advertising. Suppliers can pay for higher placement in Alibaba.com’s regular search results, but Zhang says Accio is “not integrated” with that system. “We haven’t had a clear answer in terms of how to monetize this tool,” he says. For now, users can pay for additional tokens to continue chatting with the agent after their free queries run out. Sellers say that while AI tools have made it easier to come up with ideas and get a business off the ground, they do not replace the core skills that make someone good at e-commerce. McClary believes that even when sellers have access to the same market information, some are still better at making decisions, acting quickly, and actually delivering on orders. Those differences, he says, still go a long way. Toscano, the brand founder and e-commerce consultant, feels good about officially launching his new brand of sunglasses in just a few months: “We [small business owners] always have to bootstrap a lot of decisions. Deciding what to sell often comes down to an educated guess,” he says, “And we’re now in an era when making those decisions is easier than ever.”

Chevron resumes natural gas production at Leviathan
@import url(‘https://fonts.googleapis.com/css2?family=Inter:[email protected]&display=swap’); a { color: var(–color-primary-main); } .ebm-page__main h1, .ebm-page__main h2, .ebm-page__main h3, .ebm-page__main h4, .ebm-page__main h5, .ebm-page__main h6 { font-family: Inter; } body { line-height: 150%; letter-spacing: 0.025em; font-family: Inter; } button, .ebm-button-wrapper { font-family: Inter; } .label-style { text-transform: uppercase; color: var(–color-grey); font-weight: 600; font-size: 0.75rem; } .caption-style { font-size: 0.75rem; opacity: .6; } #onetrust-pc-sdk [id*=btn-handler], #onetrust-pc-sdk [class*=btn-handler] { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-policy a, #onetrust-pc-sdk a, #ot-pc-content a { color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-pc-sdk .ot-active-menu { border-color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-accept-btn-handler, #onetrust-banner-sdk #onetrust-reject-all-handler, #onetrust-consent-sdk #onetrust-pc-btn-handler.cookie-setting-link { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-consent-sdk .onetrust-pc-btn-handler { color: #c19a06 !important; border-color: #c19a06 !important; } Chevron Mediterranean Ltd. restarted production at the Leviathan natural gas field 130 km offshore Haifa in the eastern Mediterranean after a suspension due to the Iran war, partner NewMed Energy said in a release. The operator had previously received clearance from the Petroleum Commissioner to proceed with preparations to resume operations at the Leviathan platform offshore Israel. Regular production from the reservoir was restarted on Apr. 2. Chevron is operator at Leviathan (39.66%) with partners NewMed Energy (45.34%) and Ratio Energies (15%).

QatarEnergy, ExxonMobil reach first production from Train 1 at Golden Pass
@import url(‘https://fonts.googleapis.com/css2?family=Inter:[email protected]&display=swap’); a { color: var(–color-primary-main); } .ebm-page__main h1, .ebm-page__main h2, .ebm-page__main h3, .ebm-page__main h4, .ebm-page__main h5, .ebm-page__main h6 { font-family: Inter; } body { line-height: 150%; letter-spacing: 0.025em; font-family: Inter; } button, .ebm-button-wrapper { font-family: Inter; } .label-style { text-transform: uppercase; color: var(–color-grey); font-weight: 600; font-size: 0.75rem; } .caption-style { font-size: 0.75rem; opacity: .6; } #onetrust-pc-sdk [id*=btn-handler], #onetrust-pc-sdk [class*=btn-handler] { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-policy a, #onetrust-pc-sdk a, #ot-pc-content a { color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-pc-sdk .ot-active-menu { border-color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-accept-btn-handler, #onetrust-banner-sdk #onetrust-reject-all-handler, #onetrust-consent-sdk #onetrust-pc-btn-handler.cookie-setting-link { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-consent-sdk .onetrust-pc-btn-handler { color: #c19a06 !important; border-color: #c19a06 !important; } Golden Pass LNG, a joint venture between QatarEnergy and ExxonMobil, reached first production of LNG from Train 1 at the export project in Sabine Pass, Tex. With first LNG completed, the joint venture advances work to deliver its first cargo, achieve sustained liquefaction operations, and meet its commercial and strategic objectives, ExxonMobil said in a release Mar. 30. Train 1 is one of three LNG trains comprising the 18-million tonnes/year plant. The start of LNG exports to global customers is expected in this year’s second quarter. QatarEnergy holds 70% interest in Golden Pass LNG, while ExxonMobil holds the remaining 30%.
The one piece of data that could actually shed light on your job and AI
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here. Within Silicon Valley’s orbit, an AI-fueled jobs apocalypse is spoken about as a given. The mood is so grim that a societal impacts researcher at Anthropic, responding Wednesday to a call for more optimistic visions of AI’s future, said there might be a recession in the near term and a “breakdown of the early-career ladder.” Her less-measured colleague Dario Amodei, the company’s CEO, has called AI “a general labor substitute for humans” that could do all jobs in less than five years. And those ideas are not just coming from Anthropic, of course. These conversations have unsurprisingly left many workers in a panic (and are probably contributing to support for efforts to entirely pause the construction of data centers, some of which gained steam last week). The panic isn’t being helped by lawmakers, none of whom have articulated a coherent plan for what comes next. Even economists who have cautioned that AI has not yet cut jobs and may not result in a cliff ahead are coming around to the idea that it could have a unique and unprecedented impact on how we work.
Alex Imas, based at the University of Chicago, is one of those economists. He shared two things with me when we spoke on Friday morning: a blunt assessment that our tools for predicting what this will look like are pretty abysmal, and a “call to arms” for economists to start collecting the one type of data that could make a plan to address AI in the workforce possible at all. On our abysmal tools: consider the fact that any job is made up of individual tasks. One part of a real estate agent’s job, for example, is to ask clients what sort of property they want to buy. The US government chronicled thousands of these tasks in a massive catalogue first launched in 1998 and updated regularly since then. This was the data that researchers at OpenAI used in December to judge how “exposed” a job is to AI (they found a real estate agent to be 28% exposed, for example). Then in February, Anthropic used this data in its analysis of millions of Claude conversations to see which tasks people are actually using its AI to complete and where the two lists overlapped.
But knowing the AI exposure of tasks leads to an illusory understanding of how much a given job is at risk, Imas says. “Exposure alone is a completely meaningless tool for predicting displacement,” he told me. Sure, it is illustrative in the gloomiest case—for a job in which literally every task could be done by AI with no human direction. If it costs less for an AI model to do all those tasks than what you’re paid—which is not a given, since reasoning models and agentic AI can rack up quite a bill—and it can do them well, the job likely disappears, Imas says. This is the oft-mentioned case of the elevator operator from decades ago; maybe today’s parallel is a customer service agent solely doing phone call triage. But for the vast majority of jobs, the case is not so simple. And the specifics matter, too: Some jobs are likely to have dark days ahead, but knowing how and when this will play out is hard to answer when only looking at exposure. Take writing code, for example. Someone who builds premium dating apps, let’s say, might use AI coding tools to create in one day what used to take three days. That means the worker is more productive. The worker’s employer, spending the same amount of money, can now get more output. So then will the employer want more employees or fewer? This is the question that Imas says should keep any policymaker up at night, because the answer will change depending on the industry. And we are operating in the dark. In this coder’s case, these efficiencies make it possible for dating apps to lower prices. (A skeptic might expect companies to simply pocket the gains, but in a competitive market, they risk being undercut if they do.) These lower prices will always drive some increase in demand for the apps. But how much? If millions more people want it, the company might grow and ultimately hire more engineers to meet this demand. But if demand barely ticks up—maybe the people who don’t use premium dating apps still won’t want them even at a lower price—fewer coders are needed, and layoffs will happen. Repeat this hypothetical across every job with tasks that AI can do, and you have the most pressing economic question of our time: the specifics of price elasticity, or how much demand for something changes when its price changes. And this is the second part of what Imas emphasized last week: We don’t currently have this data across the economy. But we could. We do have the numbers for grocery items like cereal and milk, Imas says, because the University of Chicago partners with supermarkets to get data from their price scanners. But we don’t have such figures for tutors or web developers or dietitians (all jobs found to have “exposure” to AI, by the way). Or at least not in a way that’s been widely compiled or made accessible to researchers; sometimes it’s scattered across private companies or consultancies. “We need, like, a Manhattan Project to collect this,” Imas says. And we don’t need it just for jobs that could obviously be affected by AI now: “Fields that are not exposed now will become exposed in the future, so you just want to track these statistics across the entire economy.” Getting all this information would take time and money, but Imas makes the case that it’s worth it; it would give economists the first realistic look at how our AI-enabled future could unfold and give policymakers a shot at making a plan for it.
Two New England states say no to new data centers
It’s getting harder and harder for governments to ignore the impact that data centers are having on their communities, consuming vast amounts of water and driving up electricity prices, experts say. According to a Pew Research Center analysis, data centers consumed 183 terawatt-hours of electricity in 2024, more than 4% of total U.S. electricity use. That demand is projected to more than double to 426 terawatt-hours by 2030. The impact is significant. In 2023, data centers consumed about 26% of Virginia’s electricity supply, although Virginia is notable for having an extremely dense collection of data centers. Alan Howard, senior analyst for infrastructure at Omdia, says he is not surprised at all. “The amount of national press coverage regarding what is arguably a limited number of data center ‘horror’ stories has many jurisdictions and states spooked over the potential impacts data center projects might have,” he said. It’s an evolution that’s been coming for some time whereby local legislators have embraced the idea that they don’t want to learn the hard way as others already have, he argues. “All that said, it seems unlikely that there will be broad bans on data center development that would cripple the industry. There’s lots of places to go in the U.S. and developers have warmed up to siting projects in places amenable to their needs, although not ideally convenient,” said Howard.
AI for IT stalls as network complexity rises
There are a number of network-related issues that are driving enterprises to delay or abandon their AI projects, according to IDC’s special report on AI in networking. Organizations expect business benefits, including improved IT service levels, to come from using AI across their network infrastructure, according to IDC’s special report on AI in networking.
AI is changing how small online sellers decide what to make
For years Mike McClary sold the Guardian LTE Flashlight, a heavy-duty black model, online through his small outdoor brand. The product, designed for brightness and durability, became one of his most popular items ever. Even after he stopped offering it around 2017, customers kept sending him emails asking where they could buy it. When McClary decided to revisit the Guardian flashlight in 2025, he didn’t begin the way he might have in the past, by combing through supplier listings and sending inquiries to factories. Instead, he opened Accio, an AI sourcing and researching tool on Alibaba.com. For small entrepreneurs in the US, deciding what to sell and where to make it has traditionally been a slow, labor-intensive process that can take months. Now that work is increasingly being done by AI tools like Accio, which help connect businesses with manufacturers in countries including China and India. Business owners and e-commerce experts told MIT Technology Review that these AI tools are making sourcing more accessible and significantly shortening the time it takes to go from product idea to launch. McClary, 51, who runs his business from his Illinois living room, has sold products ranging from leather conditioner to camping lights, including one rechargeable lantern that brought in half a million dollars. Like many small online merchants, he built his business by being extremely scrappy—spotting demand for a product, tweaking existing designs, finding a factory, doing modest marketing, and getting the goods in front of customers fast.
This time, though, he began by telling Accio about the flashlight’s original design, production cost, and profit margin. Then Accio suggested several changes, making it smaller and slightly less bright and switching its charging method to battery power. It also identified a manufacturer in Ningbo, China, that McClary said could cut the manufacturing cost from $17 to about $2.50 per unit. McClary took the process from there, contacting the supplier himself to discuss the revised design. Within a month, the new version of the Guardian flashlight was back up for sale on Amazon and on his brand’s website.
The new factory hunt Although Alibaba is better known for owning Taobao, the biggest shopping site in China, its first business was Alibaba.com, the primary website that lists Chinese factories open for bulk orders. Placing an order with a manufacturer usually requires far more than clicking “Buy.” Sellers often spend days or weeks browsing listings, comparing suppliers’ reviews and manufacturing capacities, asking about minimum order quantities, requesting samples, and negotiating timelines and customization options. But Accio has gained significant momentum by changing how that sourcing gets done. Launched in 2024, Accio exceeded 10 million monthly active users in March 2026, according to the company. That means about one in five Alibaba users consults with AI about product sourcing. Accio’s interface looks a lot like ChatGPT or Claude: Users type a question into an empty box and choose between “fast” and “thinking” modes. But when asked about products, the tool returns more than text, offering charts, links, and visuals and asking follow-up questions to clarify the buyer’s needs. It then narrows the field to one or a handful of suppliers that appear capable of delivering. After that, the human work begins: Users still have to reach out to suppliers themselves and negotiate the details. Zhang Kuo, the president of Alibaba.com, told MIT Technology Review that the tool is built on multiple frontier models, including the company’s own Qwen series, a popular family of open-source large language models. The system is able to pull from the site’s millions of supplier profiles and is trained on 26 years of proprietary transaction data. For tasks like product research and sourcing analysis, the tool “blows it away” compared with general AI tools like ChatGPT, says Richard Kostick, CEO of the beauty brand 100% Pure. Many websites have tried using AI to assist shopping, but Alibaba has been one of the most aggressive. In March, Eddie Wu, CEO of the site’s parent company Alibaba Group, told managers that integrating the company’s core services with Qwen’s AI capabilities is a top priority. During a Chinese New Year promotion of Qwen’s personal shopping AI agent, where the company gave away cash, customers placed 200 million orders, the firm says. Vincenzo Toscano, an e-commerce seller and consultant, recommended Accio to his clients before deciding to try it himself for a new sunglasses brand. He came in with a rough vision: a brand shaped by his Italian heritage, his personal style, and a boutique aesthetic. He says the AI helped turn that concept into something more concrete, suggesting materials, refining the look, and pointing to design ideas that felt current. But the tool has clear limits. McClary, who uses AI tools regularly, says Accio is strongest when it comes to product ideation, but less helpful on marketing questions such as advertising and social media outreach. To use it well, he says, buyers still need to challenge its recommendations, since some can be generic.
The rest of the business As platforms become more AI-driven, manufacturers are adjusting too. Sally Yan, a representative at a makeup packaging company in Wuhan, China, says her firm has started writing more detailed product descriptions and adding information about its equipment and manufacturing experience on Alibaba.com because it suspects those details make its listings more likely to be surfaced by AI. Yan says manufacturers cannot tell whether an inquiry from a customer was generated or guided by AI, and that her firm is not using AI to negotiate pricing or product details. “AI agents are increasingly used by people to assist decision making or even directly making transactions, and in certain situations, they can become extremely useful,” “AI agents are increasingly used by people to assist purchase decisions and even directly making transactions, and with clear data guardrails, they can become extremely useful,” says Jiaxin Pei, a research scientist at the Stanford Institute for Human-Centered AI, “but agents need to act transparently, securely, and in the customer’s best interest.” Pei says developers of these tools should disclose the data they collect and the incentives built into them to ensure that the marketplace remains fair. Zhang, of Alibaba.com, says Accio currently does not include advertising. Suppliers can pay for higher placement in Alibaba.com’s regular search results, but Zhang says Accio is “not integrated” with that system. “We haven’t had a clear answer in terms of how to monetize this tool,” he says. For now, users can pay for additional tokens to continue chatting with the agent after their free queries run out. Sellers say that while AI tools have made it easier to come up with ideas and get a business off the ground, they do not replace the core skills that make someone good at e-commerce. McClary believes that even when sellers have access to the same market information, some are still better at making decisions, acting quickly, and actually delivering on orders. Those differences, he says, still go a long way. Toscano, the brand founder and e-commerce consultant, feels good about officially launching his new brand of sunglasses in just a few months: “We [small business owners] always have to bootstrap a lot of decisions. Deciding what to sell often comes down to an educated guess,” he says, “And we’re now in an era when making those decisions is easier than ever.”
Chevron resumes natural gas production at Leviathan
@import url(‘https://fonts.googleapis.com/css2?family=Inter:[email protected]&display=swap’); a { color: var(–color-primary-main); } .ebm-page__main h1, .ebm-page__main h2, .ebm-page__main h3, .ebm-page__main h4, .ebm-page__main h5, .ebm-page__main h6 { font-family: Inter; } body { line-height: 150%; letter-spacing: 0.025em; font-family: Inter; } button, .ebm-button-wrapper { font-family: Inter; } .label-style { text-transform: uppercase; color: var(–color-grey); font-weight: 600; font-size: 0.75rem; } .caption-style { font-size: 0.75rem; opacity: .6; } #onetrust-pc-sdk [id*=btn-handler], #onetrust-pc-sdk [class*=btn-handler] { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-policy a, #onetrust-pc-sdk a, #ot-pc-content a { color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-pc-sdk .ot-active-menu { border-color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-accept-btn-handler, #onetrust-banner-sdk #onetrust-reject-all-handler, #onetrust-consent-sdk #onetrust-pc-btn-handler.cookie-setting-link { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-consent-sdk .onetrust-pc-btn-handler { color: #c19a06 !important; border-color: #c19a06 !important; } Chevron Mediterranean Ltd. restarted production at the Leviathan natural gas field 130 km offshore Haifa in the eastern Mediterranean after a suspension due to the Iran war, partner NewMed Energy said in a release. The operator had previously received clearance from the Petroleum Commissioner to proceed with preparations to resume operations at the Leviathan platform offshore Israel. Regular production from the reservoir was restarted on Apr. 2. Chevron is operator at Leviathan (39.66%) with partners NewMed Energy (45.34%) and Ratio Energies (15%).
QatarEnergy, ExxonMobil reach first production from Train 1 at Golden Pass
@import url(‘https://fonts.googleapis.com/css2?family=Inter:[email protected]&display=swap’); a { color: var(–color-primary-main); } .ebm-page__main h1, .ebm-page__main h2, .ebm-page__main h3, .ebm-page__main h4, .ebm-page__main h5, .ebm-page__main h6 { font-family: Inter; } body { line-height: 150%; letter-spacing: 0.025em; font-family: Inter; } button, .ebm-button-wrapper { font-family: Inter; } .label-style { text-transform: uppercase; color: var(–color-grey); font-weight: 600; font-size: 0.75rem; } .caption-style { font-size: 0.75rem; opacity: .6; } #onetrust-pc-sdk [id*=btn-handler], #onetrust-pc-sdk [class*=btn-handler] { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-policy a, #onetrust-pc-sdk a, #ot-pc-content a { color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-pc-sdk .ot-active-menu { border-color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-accept-btn-handler, #onetrust-banner-sdk #onetrust-reject-all-handler, #onetrust-consent-sdk #onetrust-pc-btn-handler.cookie-setting-link { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-consent-sdk .onetrust-pc-btn-handler { color: #c19a06 !important; border-color: #c19a06 !important; } Golden Pass LNG, a joint venture between QatarEnergy and ExxonMobil, reached first production of LNG from Train 1 at the export project in Sabine Pass, Tex. With first LNG completed, the joint venture advances work to deliver its first cargo, achieve sustained liquefaction operations, and meet its commercial and strategic objectives, ExxonMobil said in a release Mar. 30. Train 1 is one of three LNG trains comprising the 18-million tonnes/year plant. The start of LNG exports to global customers is expected in this year’s second quarter. QatarEnergy holds 70% interest in Golden Pass LNG, while ExxonMobil holds the remaining 30%.

Why California gasoline prices are rising faster than the US average
California’s Middle East crude oil imports California is materially more dependent on Middle Eastern crude than the rest of the US, largely due to refinery configuration and logistics. California refineries are optimized for heavier, sour crude oil. Declining in-state production (e.g., San Joaquin Valley) and no pipeline connectivity to other US producing regions means California regularly imports a meaningful share of its crude slate from the Middle East. Recent California Energy Commission data show that Iraq and Saudi Arabia alone provide 35-40% of total California barrels (roughly equivalent to California crude oil production), plus smaller flows from the UAE and others in the Persian Gulf. For the rest of the US, about 10% of crude oil imports come from Persian Gulf suppliers. As a result, California fuel prices are more exposed to disruptions or price spikes linked to Gulf supply and chokepoints like the Strait of Hormuz than refineries in other parts of the country. Out-of-state refinery constraints California imports roughly 20% of its refined fuels from Asia (a record 128,000 b/d of gasoline/additives in 2025), mostly from South Korea and India. These refiners are cutting back exports, prioritizing their own domestic markets, and scrambling to re-optimize crude slates as Hormuz disruptions squeeze Middle East supply. Shortages of Gulf crude oil are forcing refineries to reduce runs and declare force majeure on product deliveries. Several governments or companies have temporarily suspended clean‑product exports, directly throttling flows of CARB‑grade gasoline and jet to the US West Coast. These refiners also are bidding up alternative crude oil barrels from other regions and paying longer‑haul freight rates, which raises their marginal cost of gasoline and narrows the price window to ship gasoline cargoes to California. Volumes available for California are at risk of shrinking and becoming more sporadic, while the barrels that do
BLM lease sales in Colorado, Nevada, Utah generate $64.8 million
The Bureau of Land Management (BLM) on Mar. 31 leased 136 parcels across 131,121 acres in Colorado, Nevada, and Utah for $64.8 million in total receipts during quarterly oil and gas lease sales. Combined lease bonus bids and rentals are distributed between the federal government and the state where the parcels are located. Specifically, federal lands leased in Utah realized the bulk of the generated income, reaping $56.4 million from 11 parcels on 68,632 acres, BLM said. Meanwhile, in Colorado, BLM leased 68 parcels on 42,532 acres, making $8.1 million. The Nevada lease sale earned nearly $300,000 on 11 parcels on 19,957 acres. Nine companies won multiple leases in the Utah sale: Otter Creek LLC, VR Utah Holdings LLC, UT 100 LLC, Bro Energy LLC, Topaz Energy Resources, R&R Royalty Ltd., Drake Land Services LLC, Kirkwood Oil and Gas LLC, and WEM Mancos LLC. In Colorado, companies winning multiple parcels include Bison IV Properties Colorado LLC, Laramie Energy LLC, Topaz Energy Resources, R&R Royalty Ltd., QB Energy Nominee Corp., Context Energy Co., and SG Interests LLC. National Minerals Trust LLC won all 11 parcels in Nevada. Companies will pay a 12.5% royalty rate on production, BLM said.

Sable Offshore set to resume oil production at second platform offshore California
Sable Offshore Corp. has been given clearance from the US Bureau of Safety and Environmental Enforcement (BSEE) to resume operations at Platform Heritage, part of Sable Offshore’s Santa Ynez Unit (SYU) in federal waters offshore Santa Barbara, Calif. The move follows a completed final pre-restart inspection and a March directive by the US Secretary of Energy for Sable Offshore to restore SYU operations under authorities delegated through the Defense Production Act and certain executive orders. Last month, Sable Offshore restarted operations at SYU and the associated Santa Ynez Pipeline System offshore southern California as part of the directive, cited by Energy Secretary Chris Wright as needed to ensure adequate oil supply to West Coast military installations. The infrastructure had been shut in after a 2015 oil spill. The SYU includes Platforms Heritage, Harmony, and Hondo, all sit 5-9 miles offshore Santa Barbara County in shallow water depths of 900-1,200 ft. The newly cleared Platform Heritage is set to begin production soon, BSEE said. In a release Mar. 30, Sable Offshore said Platform Harmony, which came online in May 2025, is producing about 22,000 b/d of oil (gross). Platform Heritage, the second SYU platform to come online, is expected to produce over 30,000 b/d (gross). Platform Hondo, expected to produce over 10,000 b/d, is expected to be online by the end of this year’s second quarter.
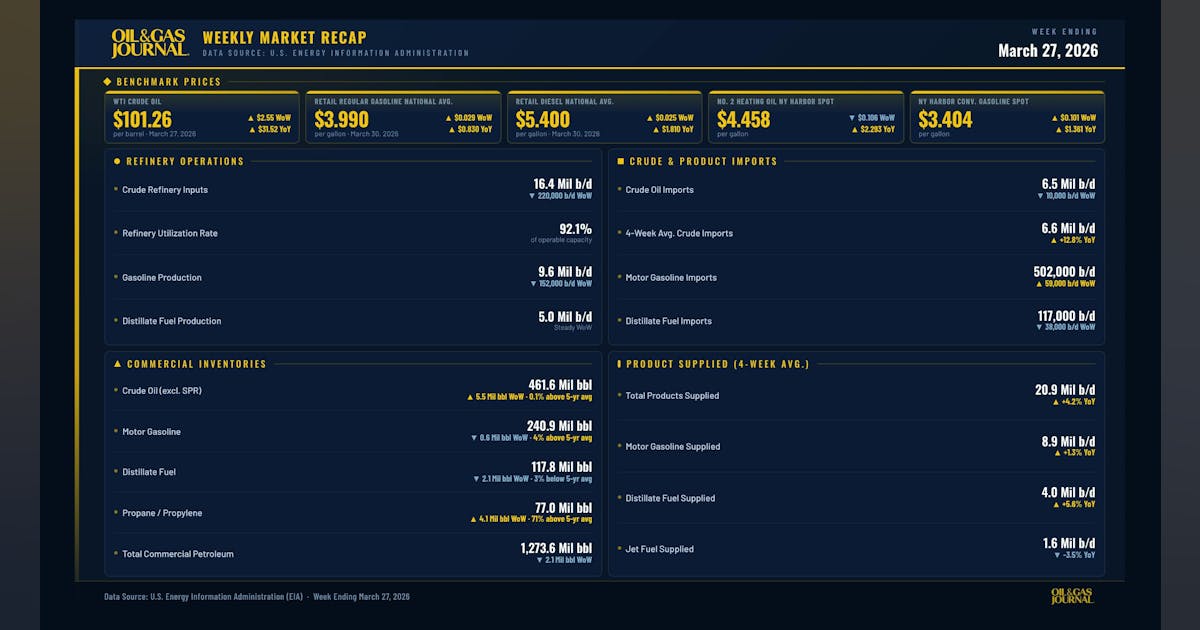
EIA: US oil inventories increase by 5.5 million bbl
US crude oil inventories, excluding those in the Strategic Petroleum Reserve, increased by 5.5 million bbl during the week ended Mar. 27 compared with the previous week’s total, according to the US Energy Information Administration’s (EIA) Petroleum Status Report. At 461.6 million bbl, US crude inventories are about 0.1% above the 5-year average. Total motor gasoline inventories decreased 600,000 bbl last week but are about 4% above the 5-year average. Finished gasoline inventories increased while blending components inventories decreased. Distillate fuel inventories decreased by 2.1 million bbl and are about 3% below the 5-year average for this time of year. Propane-propylene inventories increased by 4.1 million bbl from last week and are 71% above the 5-year average. Total commercial petroleum inventories decreased by 2.1 million bbl. US crude refinery inputs during the week averaged 16.4 million b/d, down 220,000 b/d from the previous week’s average. Refineries operated at 92.1% of their operable capacity. Gasoline production decreased, averaging 9.6 million b/d. Distillate fuel production remained steady, averaging 5.0 million b/d. US crude imports averaged 6.5 million b/d, down 10,000 b/d from the previous week’s average. Over the last 4 weeks, crude imports averaged 6.6 million b/d, up 12.8% from the same 4-week period last year. Total motor gasoline imports, including both finished gasoline and gasoline blending components, averaged 502,000 b/d. Distillate fuel imports averaged 117,000 b/d last week.

Oil, gas industry secures Endangered Species Act exemption in Gulf of Mexico
The oil and gas industry has been granted an exemption from certain requirements under the Endangered Species Act (ESA) after a little-known commission, last convened in 1992, voted Mar. 31 on a matter covering federal oil and gas activities in the US Gulf of Mexico, citing national security concerns. The Endangered Species Committee voted unanimously to allow the exemption, which could make it more difficult for conservation and environmental groups to challenge projects under the ESA and protect endangered species such as the Rice’s whale. The committee is composed of the Secretaries of Interior, Agriculture and the Army, and the heads of the Council of Economic Advisers, Environmental Protection Agency, and National Oceanic and Atmospheric Administration. The meeting, which was live-streamed and lasted about 15 minutes, was convened after the Defense Secretary determined that an exemption was necessary for national security. “This meeting made clear that energy streams in the Gulf of America must not be disrupted or held hostage by ongoing litigation,” said Interior Secretary Doug Burgum in a press release. He said energy production in the Gulf “is indispensable to our nation’s strength, safeguarding our energy independence and preventing reliance on foreign adversaries,” and that “robust development in the Gulf keeps our economy resilient, stabilizes costs for American families and secures the US as a global leader for decades to come.” The exemption would apply to all federal oil and gas exploration, development, and production activities associated with the Bureau of Ocean Energy Management and BSEE Outer Continental Shelf oil and gas program. The Center for Biological Diversity had filed an emergency lawsuit in mid-March to prevent the Endangered Species Committee from conducting the meeting aimed at overriding a May 2025 National Marine Fisheries Service opinion that required mitigation measures such as vessel speed restrictions and monitoring to reduce

Oil prices surge as Iran war escalates, IEA warns of historic supply shock
Global oil markets rallied sharply on Thursday, Apr. 2, after US President Donald Trump signaled that military operations against Iran would continue “well into April,” raising fears of prolonged disruption to one of the world’s most critical energy corridors and triggering a fresh wave of volatility across commodities and financial markets. The renewed advance came just one day after markets had briefly turned more optimistic on hopes that the war might wind down soon. But Trump’s tougher tone shifted sentiment quickly, with investors focusing again on the Strait of Hormuz, the critical waterway that normally carries about one-fifth of the world’s oil and LNG trade. With traffic through the strait still heavily disrupted, the market remains highly sensitive to any sign that the conflict could drag on. Brent crude climbed toward $110/bbl in early trading, reversing earlier losses, as investors rapidly repriced geopolitical risk following Trump’s remarks that US forces would “finish the job” in Iran. Looming energy supply shock The latest market move also comes as the International Energy Agency (IEA) warns the unfolding crisis could evolve into the largest energy supply shock in modern history. Speaking this week, IEA Executive Director Fatih Birol said disruptions tied to the conflict are already mounting and could intensify significantly in April, with Europe among the most exposed regions. “The next month, April, will be much worse than March,” Birol said in an interview with Nicolai Tangen, chief executive officer of Norway’s Norges Bank Investment Management, on Tangen’s “In Good Company” podcast. The reason, Birol explained, is simple logistics. A trickle of cargo ships that entered the Strait before the US-Israel strikes on Iran have been continuing to deliver oil and gas to ports throughout March. “They are still coming to ports, still bringing oil and energy and other things,” he said.

LG rolls out new AI services to help consumers with daily tasks
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More LG kicked off the AI bandwagon today with a new set of AI services to help consumers in their daily tasks at home, in the car and in the office. The aim of LG’s CES 2025 press event was to show how AI will work in a day of someone’s life, with the goal of redefining the concept of space, said William Joowan Cho, CEO of LG Electronics at the event. The presentation showed LG is fully focused on bringing AI into just about all of its products and services. Cho referred to LG’s AI efforts as “affectionate intelligence,” and he said it stands out from other strategies with its human-centered focus. The strategy focuses on three things: connected devices, capable AI agents and integrated services. One of things the company announced was a strategic partnership with Microsoft on AI innovation, where the companies pledged to join forces to shape the future of AI-powered spaces. One of the outcomes is that Microsoft’s Xbox Ultimate Game Pass will appear via Xbox Cloud on LG’s TVs, helping LG catch up with Samsung in offering cloud gaming natively on its TVs. LG Electronics will bring the Xbox App to select LG smart TVs. That means players with LG Smart TVs will be able to explore the Gaming Portal for direct access to hundreds of games in the Game Pass Ultimate catalog, including popular titles such as Call of Duty: Black Ops 6, and upcoming releases like Avowed (launching February 18, 2025). Xbox Game Pass Ultimate members will be able to play games directly from the Xbox app on select LG Smart TVs through cloud gaming. With Xbox Game Pass Ultimate and a compatible Bluetooth-enabled

Big tech must stop passing the cost of its spiking energy needs onto the public
Julianne Malveaux is an MIT-educated economist, author, educator and political commentator who has written extensively about the critical relationship between public policy, corporate accountability and social equity. The rapid expansion of data centers across the U.S. is not only reshaping the digital economy but also threatening to overwhelm our energy infrastructure. These data centers aren’t just heavy on processing power — they’re heavy on our shared energy infrastructure. For Americans, this could mean serious sticker shock when it comes to their energy bills. Across the country, many households are already feeling the pinch as utilities ramp up investments in costly new infrastructure to power these data centers. With costs almost certain to rise as more data centers come online, state policymakers and energy companies must act now to protect consumers. We need new policies that ensure the cost of these projects is carried by the wealthy big tech companies that profit from them, not by regular energy consumers such as family households and small businesses. According to an analysis from consulting firm Bain & Co., data centers could require more than $2 trillion in new energy resources globally, with U.S. demand alone potentially outpacing supply in the next few years. This unprecedented growth is fueled by the expansion of generative AI, cloud computing and other tech innovations that require massive computing power. Bain’s analysis warns that, to meet this energy demand, U.S. utilities may need to boost annual generation capacity by as much as 26% by 2028 — a staggering jump compared to the 5% yearly increases of the past two decades. This poses a threat to energy affordability and reliability for millions of Americans. Bain’s research estimates that capital investments required to meet data center needs could incrementally raise consumer bills by 1% each year through 2032. That increase may

Final 45V hydrogen tax credit guidance draws mixed response
Dive Brief: The final rule for the 45V clean hydrogen production tax credit, which the U.S. Treasury Department released Friday morning, drew mixed responses from industry leaders and environmentalists. Clean hydrogen development within the U.S. ground to a halt following the release of the initial guidance in December 2023, leading industry participants to call for revisions that would enable more projects to qualify for the tax credit. While the final rule makes “significant improvements” to Treasury’s initial proposal, the guidelines remain “extremely complex,” according to the Fuel Cell and Hydrogen Energy Association. FCHEA President and CEO Frank Wolak and other industry leaders said they look forward to working with the Trump administration to refine the rule. Dive Insight: Friday’s release closed what Wolak described as a “long chapter” for the hydrogen industry. But industry reaction to the final rule was decidedly mixed, and it remains to be seen whether the rule — which could be overturned as soon as Trump assumes office — will remain unchanged. “The final 45V rule falls short,” Marty Durbin, president of the U.S. Chamber’s Global Energy Institute, said in a statement. “While the rule provides some of the additional flexibility we sought, … we believe that it still will leave billions of dollars of announced projects in limbo. The incoming Administration will have an opportunity to improve the 45V rules to ensure the industry will attract the investments necessary to scale the hydrogen economy and help the U.S. lead the world in clean manufacturing.” But others in the industry felt the rule would be sufficient for ending hydrogen’s year-long malaise. “With this added clarity, many projects that have been delayed may move forward, which can help unlock billions of dollars in investments across the country,” Kim Hedegaard, CEO of Topsoe’s Power-to-X, said in a statement. Topsoe

Texas, Utah, Last Energy challenge NRC’s ‘overburdensome’ microreactor regulations
Dive Brief: A 69-year-old Nuclear Regulatory Commission rule underpinning U.S. nuclear reactor licensing exceeds the agency’s statutory authority and creates an unreasonable burden for microreactor developers, the states of Texas and Utah and advanced nuclear technology company Last Energy said in a lawsuit filed Dec. 30 in federal court in Texas. The plaintiffs asked the Eastern District of Texas court to exempt Last Energy’s 20-MW reactor design and research reactors located in the plaintiff states from the NRC’s definition of nuclear “utilization facilities,” which subjects all U.S. commercial and research reactors to strict regulatory scrutiny, and order the NRC to develop a more flexible definition for use in future licensing proceedings. Regardless of its merits, the lawsuit underscores the need for “continued discussion around proportional regulatory requirements … that align with the hazards of the reactor and correspond to a safety case,” said Patrick White, research director at the Nuclear Innovation Alliance. Dive Insight: Only three commercial nuclear reactors have been built in the United States in the past 28 years, and none are presently under construction, according to a World Nuclear Association tracker cited in the lawsuit. “Building a new commercial reactor of any size in the United States has become virtually impossible,” the plaintiffs said. “The root cause is not lack of demand or technology — but rather the [NRC], which, despite its name, does not really regulate new nuclear reactor construction so much as ensure that it almost never happens.” More than a dozen advanced nuclear technology developers have engaged the NRC in pre-application activities, which the agency says help standardize the content of advanced reactor applications and expedite NRC review. Last Energy is not among them. The pre-application process can itself stretch for years and must be followed by a formal application that can take two

Qualcomm unveils AI chips for PCs, cars, smart homes and enterprises
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More Qualcomm unveiled AI technologies and collaborations for PCs, cars, smart homes and enterprises at CES 2025. At the big tech trade show in Las Vegas, Qualcomm Technologies showed how it’s using AI capabilities in its chips to drive the transformation of user experiences across diverse device categories, including PCs, automobiles, smart homes and into enterprises. The company unveiled the Snapdragon X platform, the fourth platform in its high-performance PC portfolio, the Snapdragon X Series, bringing industry-leading performance, multi-day battery life, and AI leadership to more of the Windows ecosystem. Qualcomm has talked about how its processors are making headway grabbing share from the x86-based AMD and Intel rivals through better efficiency. Qualcomm’s neural processing unit gets about 45 TOPS, a key benchmark for AI PCs. The Snapdragon X family of AI PC processors. Additionally, Qualcomm Technologies showcased continued traction of the Snapdragon X Series, with over 60 designs in production or development and more than 100 expected by 2026. Snapdragon for vehicles Qualcomm demoed chips that are expanding its automotive collaborations. It is working with Alpine, Amazon, Leapmotor, Mobis, Royal Enfield, and Sony Honda Mobility, who look to Snapdragon Digital Chassis solutions to drive AI-powered in-cabin and advanced driver assistance systems (ADAS). Qualcomm also announced continued traction for its Snapdragon Elite-tier platforms for automotive, highlighting its work with Desay, Garmin, and Panasonic for Snapdragon Cockpit Elite. Throughout the show, Qualcomm will highlight its holistic approach to improving comfort and focusing on safety with demonstrations on the potential of the convergence of AI, multimodal contextual awareness, and cloudbased services. Attendees will also get a first glimpse of the new Snapdragon Ride Platform with integrated automated driving software stack and system definition jointly

Oil, Gas Execs Reveal Where They Expect WTI Oil Price to Land in the Future
Executives from oil and gas firms have revealed where they expect the West Texas Intermediate (WTI) crude oil price to be at various points in the future as part of the fourth quarter Dallas Fed Energy Survey, which was released recently. The average response executives from 131 oil and gas firms gave when asked what they expect the WTI crude oil price to be at the end of 2025 was $71.13 per barrel, the survey showed. The low forecast came in at $53 per barrel, the high forecast was $100 per barrel, and the spot price during the survey was $70.66 per barrel, the survey pointed out. This question was not asked in the previous Dallas Fed Energy Survey, which was released in the third quarter. That survey asked participants what they expect the WTI crude oil price to be at the end of 2024. Executives from 134 oil and gas firms answered this question, offering an average response of $72.66 per barrel, that survey showed. The latest Dallas Fed Energy Survey also asked participants where they expect WTI prices to be in six months, one year, two years, and five years. Executives from 124 oil and gas firms answered this question and gave a mean response of $69 per barrel for the six month mark, $71 per barrel for the year mark, $74 per barrel for the two year mark, and $80 per barrel for the five year mark, the survey showed. Executives from 119 oil and gas firms answered this question in the third quarter Dallas Fed Energy Survey and gave a mean response of $73 per barrel for the six month mark, $76 per barrel for the year mark, $81 per barrel for the two year mark, and $87 per barrel for the five year mark, that

OpenAI acquires TBPN
Fidji Simo shared this message with the company earlier today: I’m excited to share that we’ve acquired TBPN(opens in a new window). This acquisition brings a team with strong editorial instincts, deep audience understanding, and a proven ability to convene influential voices across tech, business, and culture.TBPN has built something pretty special. It’s one of the places where the conversation about AI and builders is actually happening day to day. A lot of you already watch it, and rely on it to stay close to what’s going on.As I’ve been thinking about the future of how we communicate at OpenAI, one thing that’s become clear is that the standard communications playbook just doesn’t apply to us. We’re not a typical company. We’re driving a really big technological shift. And with our mission to ensure artificial general intelligence benefits all of humanity comes a responsibility to help create a space for a real, constructive conversation about the changes AI creates—with builders and people using the technology at the center.That’s exactly what TBPN has built. So rather than trying to recreate that ourselves, it made a lot of sense to bring them in, support what they’re doing, and help them scale—while keeping what makes them special. A core part of this is editorial independence. TBPN will continue to run their programming, choose their guests, and make their own editorial decisions. That’s foundational to their credibility, and it’s something we’re explicitly protecting as part of this agreement.I’m also excited to bring their amazing comms and marketing instincts to the team. They’ve helped many brands market online and because they have a strong pulse on where the industry is going, their comms and marketing ideas have really impressed me. I can’t wait to leverage their talent outside of the show to innovate on how we bring AI to the world in a way that helps people understand the full impact of this technology on their daily lives.TBPN will sit within our Strategy org, reporting to Chris Lehane. Really excited to welcome Jordi, John, Dylan, and the broader team.A statement from TBPN: “Over the past year, we’ve had a front-row seat not just to OpenAI, but to the entire ecosystem, covering the daily news, announcements, and launches in real time. While we’ve been critical of the industry at times, after getting to know Sam and the OpenAI team, what stood out most was their openness to feedback and commitment to getting this right. Moving from commentary to real impact in how this technology is distributed and understood globally is incredibly important to us.”—Jordi Hays, co-founder and co-host of TBPNAbout TBPN

Gemma 4: Byte for byte, the most capable open models
At the edge, our E2B and E4B models redefine on-device utility, prioritizing multimodal capabilities, low-latency processing and seamless ecosystem integration over raw parameter count.Powerful, accessible, openTo power the next generation of pioneering research and products, we’ve sized the Gemma 4 models specifically to run and fine-tune efficiently on hardware — from billions of Android devices worldwide, to laptop GPUs, all the way up to developer workstations and accelerators.By using these highly optimized models, you can fine-tune Gemma 4 to achieve state-of-the-art performance on your specific tasks. We’ve already seen incredible success with this approach; for instance, INSAIT created a pioneering Bulgarian-first language model (BgGPT), and we worked with Yale University on Cell2Sentence-Scale to discover new pathways for cancer therapy, among many others.Here is what makes Gemma 4 our most capable open model family yet:Advanced reasoning: Capable of multi-step planning and deep logic, Gemma 4 demonstrates significant improvements in math and instruction-following benchmarks that require it.Agentic workflows: Native support for function-calling, structured JSON output, and native system instructions enables you to build autonomous agents that can interact with different tools and APIs and execute workflows reliably.Code generation: Gemma 4 supports high-quality offline code, turning your workstation into a local-first AI code assistant.Vision and audio: All models natively process video and images, supporting variable resolutions, and excelling at visual tasks like OCR and chart understanding. Additionally, the E2B and E4B models feature native audio input for speech recognition and understanding.Longer context: Process long-form content seamlessly. The edge models feature a 128K context window, while the larger models offer up to 256K, allowing you to pass repositories or long documents in a single prompt.140+ languages: Natively trained on over 140 languages, Gemma 4 helps developers build inclusive, high-performance applications for a global audience.Versatile models for diverse hardwareWe are releasing the Gemma 4 model weights in sizes tailored for specific hardware and use cases, ensuring you get frontier-class reasoning wherever you need it:26B and 31B models: Frontier intelligence, offline on your personal computersOptimized to provide researchers and developers with state-of-the-art reasoning on accessible hardware, our unquantized bfloat16 weights fit efficiently on a single 80GB NVIDIA H100 GPU. For local setups, quantized versions run natively on consumer GPUs to power your IDEs, coding assistants and agentic workflows. Our 26B Mixture of Experts (MoE) focus on latency, activating only 3.8 billion of its total parameters during inference to deliver exceptionally fast tokens-per-second, while our 31B Dense is maximizing raw quality and provides a powerful foundation for fine-tuning.

The Download: plastic’s problem with fuel prices, and SpaceX’s blockbuster IPO
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology. Fuel prices are soaring. Plastic could be next. As the war in Iran continues, one of the most visible global economic ripple effects has been fossil-fuel prices. But looking ahead, further consequences could be looming for plastics. Plastics are made from petrochemicals, and the supply chain impacts from the conflict are starting to build up. Americans will likely feel the ripples. Read the full story to grasp the unpredictable impacts.
—Casey Crownhart This story is from The Spark, our weekly climate newsletter. Sign up to get it in your inbox every Wednesday.
The must-reads I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology. 1 SpaceX has filed for an IPO It’s set to be the largest ever, targeting a $1.75 trillion valuation. (NYT $) + Which would make Elon Musk the world’s first trillionaire. (Al Jazeera) + But the IPO could hinge on the success of Moon missions. (LA Times $) + And the conflicts of interest are staggering. (The Next Web) + Meanwhile, rivals are rising to challenge SpaceX. (MIT Technology Review) 2 Artemis II is on its way to the Moon NASA successfully launched the four astronauts on its rocket yesterday. (Axios) + The lunar plans could violate international law. (The Verge) + But the potential scientific advances are tremendous. (Nature) + Check out our roundtable on the next era of space exploration. (MIT Technology Review) 3 Iran has struck Amazon’s cloud business in Bahrain again It promised to hit US companies only yesterday. (FT $) + Other targets include Google, Microsoft, Apple, and Nvidia. (CNBC) + AWS data centers in Bahrain were also hit last month. (Reuters $) 4 OpenAI was secretly behind a child safety campaign group It pushed for age verification requirements for AI. (The San Francisco Standard $) + OpenAI had backed the legislation as a compromise measure. (WSJ $) + Coincidentally, Sam Altman heads a company providing age verification. (Engadget) 5 Anthropic is scrambling to limit the Claude Code leak It’s trying to remove 8,000 copies of the exposed code from GitHub. (Gizmodo) + An executive blamed the leak on “process errors.” (Bloomberg $) + Here’s what it reveals about Anthropic’s plans. (Ars Technica) + AI is making online crimes easier—and it could get much worse. (MIT Technology Review) 6 A new Russian “super-app” aims to emulate China’s WeChat And give the Kremlin new surveillance powers. (WSJ $)
7 America’s AI boom is leaving the rest of the world behind And it’s concentrating power and wealth in a handful of companies. (Rest of World) 8 Chinese chipmakers have claimed nearly half the country’s market Nvidia’s lead is shrinking rapidly. (Reuters $) 9 The first quantum computer to break encryption is imminent New research reveals how it could happen. (New Scientist) 10 The world’s oldest tortoise has been embroiled in a crypto scam Reports that Jonathan died at just 194 years old are thankfully false. (Guardian) Quote of the day “Starlink is the only reason this valuation is defensible.” —Shay Boloor, chief market strategist at Futurum Equities, tells Reuters why SpaceX has such high hopes for its IPO. One More Thing These companies are creating food out of thin air Dried cells—it’s what’s for dinner. At least that’s what a new crop of biotech startups, armed with carbon-guzzling bacteria and plenty of capital, are hoping to convince us.
Their claims sound too good to be true: they say they can make food out of thin air. But that’s exactly how certain soil-dwelling bacteria work. Startups are replicating the process to turn abundant carbon dioxide into nutritious “air protein.” They believe it could dramatically lower farming emissions—and even disrupt agriculture altogether. Read the full story.
—Claire L. Evans We can still have nice things A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line.) + Need more Artemis II in your life? This site takes you inside the flight. + Here’s a fascinating look at the recording errors that improved songs. + Good news: the elusive Nightjar bird is making a comeback. + Finally, a master chef has baked clam chowder donuts.

Fuel prices are soaring. Plastic could be next.
As the war in Iran continues to engulf the Middle East and the Strait of Hormuz stays closed, one of the most visible global economic ripple effects has been fossil-fuel prices. In particular, you can’t get away from news about the price of gasoline, which just topped an average of $4 a gallon in the US, its highest level since 2022. But looking ahead, further consequences for the global economy could be looming in plastics. Plastics are made using petrochemicals, and the supply chain impacts of the oil bottleneck near Iran are starting to build up. Plastic production accounts for roughly 5% of global carbon dioxide emissions today. And our current moment shows just how embedded oil and gas products are in our lives. It goes far beyond their use for energy. As I write this, I’m wearing clothes that contain plastic fibers, typing on a plastic keyboard, and looking through the plastic lenses of my glasses. It’s hard to imagine what our world looks like without plastic. And in some ways, moving away from fossil-derived plastic could prove even more complicated than decarbonizing our energy system.
Crude oil prices have been on a roller-coaster in recent weeks, and prices have recently topped $100 a barrel. Crude oil contains a huge range of hydrocarbons, and it’s typically refined by putting it through a distillation unit that separates the raw material into different fractions according to their boiling point. Those fractions then go on to be further processed into everything from jet fuel to asphalt binder. We’ve already seen the price spikes for some materials pulled out of crude oil, like gasoline and jet fuel.
Let’s zoom in on another component, naphtha. It can be added to gasoline and jet fuel to improve performance. It can also be used as a solvent or as a raw material to make plastics. The Middle East currently accounts for about 20% of global naphtha production and supplies about 40% of the market in Asia, where prices are already up by 50% over the last month. We’re starting to see these effects trickle down already. The price of polypropylene (which is made from naphtha and used for food containers, bottle caps, and even automotive parts) is climbing, especially in Asia. Typically, manufacturers have a bit of stock built up, but that’ll be exhausted soon, likely in the coming weeks. The largest supplier of water bottles in India recently announced that it would raise prices by 11% after its packaging costs went up by over 70%, according to reporting from Reuters. Toys could be more expensive this holiday season as manufacturers grapple with supply chain concerns. Americans will likely feel these ripples especially hard if disruptions continue. The average US resident used over 250 kilograms of new plastics in 2019, according to a 2022 report from the Organization for Economic Cooperation and Development. That’s an absolutely massive number—the global average is just 60 kilograms. The effects of higher prices for both fuels and feedstocks could compound and multiply, and alternatives aren’t widely available. Bio-based plastics made with materials like plant sugars exist, but they still make up a vanishingly tiny portion of the market. As of 2025, global plastics production totaled over 431 million metric tons per year. Bio-based and bio-degradable plastics made up about 0.5% of that, a share that could reach 1% by 2030. Bio-based plastics are much more expensive than their fossil-derived counterparts. And many are made using agricultural raw materials, so scaling them up too much could be harmful for the environment and might compete with other industries like food production. Recycling isn’t the easy answer either. Mechanical recycling is the current standard method used for materials like the plastics that make up water bottles and disposable coffee cups. But that degrades the materials over time, so they can’t be used infinitely. Chemical recycling has its own host of issues—the facilities that do it can be highly polluting, and today plastics that go into advanced recycling plants largely don’t actually go into new plastics.
There’s been a lot of talk in recent weeks about how this energy crisis is going to push the world more toward renewable energy. Solar panels, electric vehicles, and batteries could suddenly become more attractive as we face the drastic consequences of a disruption in the global fossil-fuel supply. But when it comes to plastic, the future looks far more complicated. Even though the plastics industry is facing much the same disruptions as the energy sector, there aren’t the same obvious alternatives available for a transition. Our lives are tied up in plastic, with uses ranging from the essential (like medical equipment) to the mundane (my to-go coffee cup). Soon, our economy could feel the effects of just how much we rely on fossil-derived plastics, and how hard it’s going to be to replace them. This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.

The Download: gig workers training humanoids, and better AI benchmarks
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology. The gig workers who are training humanoid robots at home When Zeus, a medical student in Nigeria, returns to his apartment from a long day at the hospital, he straps his iPhone to his forehead and records himself doing chores. Zeus is a data recorder for Micro1, which sells the data he collects to robotics firms. As these companies race to build humanoids, videos from workers like Zeus have become the hottest new way to train them. Micro1 has hired thousands of them in more than 50 countries, including India, Nigeria, and Argentina. The jobs pay well locally, but raise thorny questions around privacy and informed consent. The work can be challenging—and weird. Read the full story.
—Michelle Kim Our readers recently voted humanoid robots the “11th breakthrough” to add to our 2026 list of 10 Breakthrough Technologies. Check out what else officially made the cut.
AI benchmarks are broken. Here’s what we need instead. For decades, AI has been evaluated based on whether it can outperform humans on isolated problems. But it’s seldom used this way in the real world. While AI is assessed in a vacuum, it operates in messy, complex, multi-person environments over time. This misalignment leads us to misunderstand its capabilities, risks, and impacts. We need new benchmarks that assess AI’s performance over longer horizons within human teams, workflows, and organizations. Here’s a proposal for one such approach: Human–AI, Context-Specific Evaluation. —Angela Aristidou, professor at University College London and faculty fellow at the Stanford Digital Economy Lab and the Stanford Human-Centered AI Institute. MIT Technology Review Narrated: can quantum computers now solve health care problems? We’ll soon find out. In a laboratory on the outskirts of Oxford, a quantum computer built from atoms and light awaits its moment. The device is small but powerful—and also very valuable. Infleqtion, the company that owns it, is hoping its abilities will win $5 million at a competition. The prize will go to the quantum computer that can solve real health care problems that “classical” computers cannot. But there can be only one big winner—if there is a winner at all. —Michael Brooks This is our latest story to be turned into an MIT Technology Review Narrated podcast, which we’re publishing each week on Spotify and Apple Podcasts. Just navigate to MIT Technology Review Narrated on either platform, and follow us to get all our new content as it’s released.
The must-reads I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology. 1 OpenAI just closed the biggest funding round in Silicon Valley history It raised $122 billion ahead of its blockbuster IPO, which is expected later this year. (WSJ $) + It’s also prepping a push to “rethink the social contract.” (Vanity Fair $) + Campaigners are urging people to quit ChatGPT. (MIT Technology Review) 2 Iran has threatened to attack 18 US tech companies It’s eyeing their operations in the Middle East. (Politico) + Targets include Nvidia, Apple, Microsoft, and Google. (Engadget) + Iran struck AWS data centers earlier this month. (Reuters $) 3 Artemis II is about to fly humans to the Moon. Here’s the science they’ll do Their experiments will set the stage for future explorers. (Nature) + You can watch the launch attempt today. (Engadget) 4 Putin is trying to take full control of Russia’s internet New outages and blockages are cutting the country off from the world. (NYT $) + Can we repair the internet? (MIT Technology Review) 5 A robotaxi outage in China left passengers stranded on highways Baidu vehicles froze on the streets of Wuhan. (Bloomberg $) + Police are blaming a “system failure.” (Reuters $) 6 US government requests for social media user data are soaring They’ve skyrocketed by 770% in the past decade. (Bloomberg $) + Is the Pentagon allowed to surveil Americans with AI? (MIT Technology Review)
7 Tesla has admitted that humans sometimes drive its robotaxis Remote drivers occasionally control them completely. (Wired $) 8 A satellite-smashing chain reaction could spiral out of control This data visualization captures the dangers of space collisions. (Guardian) + Here’s all the stuff we’ve put into space. (MIT Technology Review)
9 Meta’s smartglasses can turn you into a creep According to one journalist who wore them for a month. (Guardian) 10 A Claude Code leak has exposed plans for a virtual pet We could be getting a Tamagotchi for the GenAI era. (The Verge) Quote of the day “From now on, for every assassination, an American company will be destroyed.” —Iran’s Islamic Revolutionary Guard Corps (IRGC) threatens US tech firms in an affiliated Telegram, per CNBC. One More Thing ACKERMAN + GRUBER How one mine could unlock billions in EV subsidies In a pine farm north of the tiny town of Tamarack, Minnesota, Talon Metals has uncovered one of America’s densest nickel deposits. Now it wants to begin mining the ore.
Products made from the nickel could net more than $26 billion in subsidies through the Inflation Reduction Act (IRA), which is starting to transform the US economy. To understand how, we tallied up the potential tax credits available. Read the full story to find out what we discovered. —James Temple We can still have nice things A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line.) + A selfless group of gluttons tried to taste-test every potato chip in the world. + Get romantic inspiration from these penguins’ engagement pebbles. + Good news: global terrorism has hit a 15-year low. + Enjoy endless new views through these windows around the world.

The gig workers who are training humanoid robots at home
When Zeus, a medical student living in a hilltop city in central Nigeria, returns to his studio apartment from a long day at the hospital, he turns on his ring light, straps his iPhone to his forehead, and starts recording himself. He raises his hands in front of him like a sleepwalker and puts a sheet on his bed. He moves slowly and carefully to make sure his hands stay within the camera frame. Zeus is a data recorder for Micro1, a US company based in Palo Alto, California that collects real-world data to sell to robotics companies. As companies like Tesla, Figure AI, and Agility Robotics race to build humanoids—robots designed to resemble and move like humans in factories and homes—videos recorded by gig workers like Zeus are becoming the hottest new way to train them. Micro1 has hired thousands of contract workers in more than 50 countries, including India, Nigeria, and Argentina, where swathes of tech-savvy young people are looking for jobs. They’re mounting iPhones on their heads and recording themselves folding laundry, washing dishes, and cooking. The job pays well by local standards and is boosting local economies, but it raises thorny questions around privacy and informed consent. And the work can be challenging at times—and weird. Zeus found the job in November, when people started talking about it everywhere on LinkedIn and YouTube. “This would be a real nice opportunity to set a mark and give data that will be used to train robots in the future,” he thought.
Zeus is paid $15 an hour, which is good income in Nigeria’s strained economy with high unemployment rates. But as a bright-eyed student dreaming of becoming a doctor, he finds ironing his clothes for hours every day boring. “I really [do] not like it so much,” he says. “I’m the kind of person that requires … a technical job that requires me to think.”
Zeus, and all the workers interviewed by MIT Technology Review, asked to be referred to only by pseudonyms because they were not authorized to talk about their work. Humanoid robots are notoriously hard to build because manipulating physical objects is a difficult skill to master. But the rise of large language models underlying chatbots like ChatGPT has inspired a paradigm shift in robotics. Just as large language models learned to generate words by being trained on vast troves of text scraped from the internet, many researchers believe that humanoid robots can learn to interact with the world by being trained on massive amounts of movement data. Editor’s note: In a recent poll, MIT Technology Review readers selected humanoid robots as the 11th breakthrough for our 2026 list of 10 Breakthrough Technologies. Robotics requires far more complex data about the physical world, though, and that is much harder to find. Virtual simulations can train robots to perform acrobatics, but not how to grasp and move objects, because simulations struggle to model physics with perfect accuracy. For robots to work in factories and serve as housekeepers, real-world data, however time-consuming and expensive to collect, may be what we need. Investors are pouring money feverishly into solving this challenge, spending over $6 billion on humanoid robots in 2025. And at-home data recording is becoming a booming gig economy around the world. Data companies like Scale AI and Encord are recruiting their own armies of data recorders, while DoorDash pays delivery drivers to film themselves doing chores. And in China, workers in dozens of state-owned robot training centers wear virtual-reality headsets and exoskeletons to teach humanoid robots how to open a microwave and wipe down the table. “There is a lot of demand, and it’s increasing really fast,” says Ali Ansari, CEO of Micro1. He estimates that robotics companies are now spending more than $100 million each year to buy real-world data from his company and others like it. A day in the life Workers at Micro1 are vetted by an AI agent named Zara that conducts interviews and reviews samples of chore videos. Every week, they submit videos of themselves doing chores around their homes, following a list of instructions about things like keeping their hands visible and moving at natural speed. The videos are reviewed by both AI and a human and are either accepted or rejected. They’re then annotated by AI and a team of hundreds of humans who label the actions in the footage. “There is a lot of demand, and it’s increasing really fast.” Ali Ansari, CEO of Micro1 Because this approach to training robots is in its infancy, it’s not clear yet what makes good training data. Still, “you need to give lots and lots of variations for the robot to generalize well for basic navigation and manipulation of the world,” says Ansari.
But many workers say that creating a variety of “chore content” in their tiny homes is a challenge. Zeus, a scrappy student living in a humble studio, struggles to record anything beyond ironing his clothes every day. Arjun, a tutor in Delhi, India, takes an hour to make a 15-minute video because he spends so much time brainstorming new chores. “How much content [can be made] in the home? How much content?” he says. There’s also the sticky question of privacy. Micro1 asks workers not to show their faces to the camera or reveal personal information such as names, phone numbers, and birth dates. Then it uses AI and human reviewers to remove anything that slips through. But even without faces, the videos capture an intimate slice of workers’ lives: the interiors of their homes, their possessions, their routines. And understanding what kind of personal information they might be recording while they’re busy doing chores on camera can be tricky. Reviews of such footage might not filter out sensitive information beyond the most obvious identifiers. For workers with families, keeping private life off camera is a constant negotiation. Arjun, a father of two daughters, has to wrangle his chaotic two-year-old out of frame. “Sometimes it’s very difficult to work because my daughter is small,” he says. Sasha, a banker turned data recorder in Nigeria, tiptoes around when she hangs her laundry outside in a shared residential compound so she won’t record her neighbors, who watch her in bewilderment. “It’s going to take longer than people think.”Ken Goldberg, UC Berkeley While the workers interviewed by MIT Technology Review understand that their data is being used to train robots, none of them know how exactly their data will be used, stored, and shared with third parties, including the robotics companies that Micro1 is selling the data to. For confidentiality reasons, says Ansari, Micro1 doesn’t name its clients or disclose to workers the specific nature of the projects they are contributing to. “It is important that if workers are engaging in this, that they are informed by the companies themselves of the intention … where this kind of technology might go and how that might affect them longer term,” says Yasmine Kotturi, a professor of human-centered computing at the University of Maryland.
Occasionally, some workers say, they’ve seen other workers asking on the company Slack channel if the company could delete their data. Micro1 declined to comment on whether such data is deleted. “People are opting into doing this,” says Ansari. “They could stop the work at any time.”
Hungry for data With thousands of workers doing their chores differently in different homes, some roboticists wonder if the data collected from them is reliable enough to train robots safely. “How we conduct our lives in our homes is not always right from a safety point of view,” says Aaron Prather, a roboticist at ASTM International. “If those folks are teaching those bad habits that could lead to an incident, then that’s not good data.” And the sheer volume of data being collected makes reviewing it for quality control challenging. But Ansari says the company rejects videos showing unsafe ways of performing a task, while clumsy movements can be useful to teach robots what not to do. Then there’s the question of how much of this data we need. Micro1 says it has tens of thousands of hours of footage, while Scale AI announced it had gathered more than 100,000 hours. “It’s going to take a long time to get there,” says Ken Goldberg, a roboticist at the University of California, Berkeley. Large language models were trained on text and images that would take a human 100,000 years to read, and humanoid robots may need even more data, because controlling robotic joints is even more complicated than generating text. “It’s going to take longer than people think,” he says. When Dattu, an engineering student living in a bustling tech hub in India, comes home after a full day of classes at his university, he skips dinner and dashes to his tiny balcony, cramped with potted plants and dumbbells. He straps his iPhone to his forehead and records himself folding the same set of clothes over and over again. His family stares at him quizzically. “It’s like some space technology for them,” he says. When he tells his friends about his job, “they just get astounded by the idea that they can get paid by recording chores.” Juggling his university studies with data recording, as well as other data annotation gigs, takes a toll on him. Still, “it feels like you’re doing something different than the whole world,” he says.
The one piece of data that could actually shed light on your job and AI
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here. Within Silicon Valley’s orbit, an AI-fueled jobs apocalypse is spoken about as a given. The mood is so grim that a societal impacts researcher at Anthropic, responding Wednesday to a call for more optimistic visions of AI’s future, said there might be a recession in the near term and a “breakdown of the early-career ladder.” Her less-measured colleague Dario Amodei, the company’s CEO, has called AI “a general labor substitute for humans” that could do all jobs in less than five years. And those ideas are not just coming from Anthropic, of course. These conversations have unsurprisingly left many workers in a panic (and are probably contributing to support for efforts to entirely pause the construction of data centers, some of which gained steam last week). The panic isn’t being helped by lawmakers, none of whom have articulated a coherent plan for what comes next. Even economists who have cautioned that AI has not yet cut jobs and may not result in a cliff ahead are coming around to the idea that it could have a unique and unprecedented impact on how we work.
Alex Imas, based at the University of Chicago, is one of those economists. He shared two things with me when we spoke on Friday morning: a blunt assessment that our tools for predicting what this will look like are pretty abysmal, and a “call to arms” for economists to start collecting the one type of data that could make a plan to address AI in the workforce possible at all. On our abysmal tools: consider the fact that any job is made up of individual tasks. One part of a real estate agent’s job, for example, is to ask clients what sort of property they want to buy. The US government chronicled thousands of these tasks in a massive catalogue first launched in 1998 and updated regularly since then. This was the data that researchers at OpenAI used in December to judge how “exposed” a job is to AI (they found a real estate agent to be 28% exposed, for example). Then in February, Anthropic used this data in its analysis of millions of Claude conversations to see which tasks people are actually using its AI to complete and where the two lists overlapped.
But knowing the AI exposure of tasks leads to an illusory understanding of how much a given job is at risk, Imas says. “Exposure alone is a completely meaningless tool for predicting displacement,” he told me. Sure, it is illustrative in the gloomiest case—for a job in which literally every task could be done by AI with no human direction. If it costs less for an AI model to do all those tasks than what you’re paid—which is not a given, since reasoning models and agentic AI can rack up quite a bill—and it can do them well, the job likely disappears, Imas says. This is the oft-mentioned case of the elevator operator from decades ago; maybe today’s parallel is a customer service agent solely doing phone call triage. But for the vast majority of jobs, the case is not so simple. And the specifics matter, too: Some jobs are likely to have dark days ahead, but knowing how and when this will play out is hard to answer when only looking at exposure. Take writing code, for example. Someone who builds premium dating apps, let’s say, might use AI coding tools to create in one day what used to take three days. That means the worker is more productive. The worker’s employer, spending the same amount of money, can now get more output. So then will the employer want more employees or fewer? This is the question that Imas says should keep any policymaker up at night, because the answer will change depending on the industry. And we are operating in the dark. In this coder’s case, these efficiencies make it possible for dating apps to lower prices. (A skeptic might expect companies to simply pocket the gains, but in a competitive market, they risk being undercut if they do.) These lower prices will always drive some increase in demand for the apps. But how much? If millions more people want it, the company might grow and ultimately hire more engineers to meet this demand. But if demand barely ticks up—maybe the people who don’t use premium dating apps still won’t want them even at a lower price—fewer coders are needed, and layoffs will happen. Repeat this hypothetical across every job with tasks that AI can do, and you have the most pressing economic question of our time: the specifics of price elasticity, or how much demand for something changes when its price changes. And this is the second part of what Imas emphasized last week: We don’t currently have this data across the economy. But we could. We do have the numbers for grocery items like cereal and milk, Imas says, because the University of Chicago partners with supermarkets to get data from their price scanners. But we don’t have such figures for tutors or web developers or dietitians (all jobs found to have “exposure” to AI, by the way). Or at least not in a way that’s been widely compiled or made accessible to researchers; sometimes it’s scattered across private companies or consultancies. “We need, like, a Manhattan Project to collect this,” Imas says. And we don’t need it just for jobs that could obviously be affected by AI now: “Fields that are not exposed now will become exposed in the future, so you just want to track these statistics across the entire economy.” Getting all this information would take time and money, but Imas makes the case that it’s worth it; it would give economists the first realistic look at how our AI-enabled future could unfold and give policymakers a shot at making a plan for it.
Two New England states say no to new data centers
It’s getting harder and harder for governments to ignore the impact that data centers are having on their communities, consuming vast amounts of water and driving up electricity prices, experts say. According to a Pew Research Center analysis, data centers consumed 183 terawatt-hours of electricity in 2024, more than 4% of total U.S. electricity use. That demand is projected to more than double to 426 terawatt-hours by 2030. The impact is significant. In 2023, data centers consumed about 26% of Virginia’s electricity supply, although Virginia is notable for having an extremely dense collection of data centers. Alan Howard, senior analyst for infrastructure at Omdia, says he is not surprised at all. “The amount of national press coverage regarding what is arguably a limited number of data center ‘horror’ stories has many jurisdictions and states spooked over the potential impacts data center projects might have,” he said. It’s an evolution that’s been coming for some time whereby local legislators have embraced the idea that they don’t want to learn the hard way as others already have, he argues. “All that said, it seems unlikely that there will be broad bans on data center development that would cripple the industry. There’s lots of places to go in the U.S. and developers have warmed up to siting projects in places amenable to their needs, although not ideally convenient,” said Howard.
AI for IT stalls as network complexity rises
There are a number of network-related issues that are driving enterprises to delay or abandon their AI projects, according to IDC’s special report on AI in networking. Organizations expect business benefits, including improved IT service levels, to come from using AI across their network infrastructure, according to IDC’s special report on AI in networking.
AI is changing how small online sellers decide what to make
For years Mike McClary sold the Guardian LTE Flashlight, a heavy-duty black model, online through his small outdoor brand. The product, designed for brightness and durability, became one of his most popular items ever. Even after he stopped offering it around 2017, customers kept sending him emails asking where they could buy it. When McClary decided to revisit the Guardian flashlight in 2025, he didn’t begin the way he might have in the past, by combing through supplier listings and sending inquiries to factories. Instead, he opened Accio, an AI sourcing and researching tool on Alibaba.com. For small entrepreneurs in the US, deciding what to sell and where to make it has traditionally been a slow, labor-intensive process that can take months. Now that work is increasingly being done by AI tools like Accio, which help connect businesses with manufacturers in countries including China and India. Business owners and e-commerce experts told MIT Technology Review that these AI tools are making sourcing more accessible and significantly shortening the time it takes to go from product idea to launch. McClary, 51, who runs his business from his Illinois living room, has sold products ranging from leather conditioner to camping lights, including one rechargeable lantern that brought in half a million dollars. Like many small online merchants, he built his business by being extremely scrappy—spotting demand for a product, tweaking existing designs, finding a factory, doing modest marketing, and getting the goods in front of customers fast.
This time, though, he began by telling Accio about the flashlight’s original design, production cost, and profit margin. Then Accio suggested several changes, making it smaller and slightly less bright and switching its charging method to battery power. It also identified a manufacturer in Ningbo, China, that McClary said could cut the manufacturing cost from $17 to about $2.50 per unit. McClary took the process from there, contacting the supplier himself to discuss the revised design. Within a month, the new version of the Guardian flashlight was back up for sale on Amazon and on his brand’s website.
The new factory hunt Although Alibaba is better known for owning Taobao, the biggest shopping site in China, its first business was Alibaba.com, the primary website that lists Chinese factories open for bulk orders. Placing an order with a manufacturer usually requires far more than clicking “Buy.” Sellers often spend days or weeks browsing listings, comparing suppliers’ reviews and manufacturing capacities, asking about minimum order quantities, requesting samples, and negotiating timelines and customization options. But Accio has gained significant momentum by changing how that sourcing gets done. Launched in 2024, Accio exceeded 10 million monthly active users in March 2026, according to the company. That means about one in five Alibaba users consults with AI about product sourcing. Accio’s interface looks a lot like ChatGPT or Claude: Users type a question into an empty box and choose between “fast” and “thinking” modes. But when asked about products, the tool returns more than text, offering charts, links, and visuals and asking follow-up questions to clarify the buyer’s needs. It then narrows the field to one or a handful of suppliers that appear capable of delivering. After that, the human work begins: Users still have to reach out to suppliers themselves and negotiate the details. Zhang Kuo, the president of Alibaba.com, told MIT Technology Review that the tool is built on multiple frontier models, including the company’s own Qwen series, a popular family of open-source large language models. The system is able to pull from the site’s millions of supplier profiles and is trained on 26 years of proprietary transaction data. For tasks like product research and sourcing analysis, the tool “blows it away” compared with general AI tools like ChatGPT, says Richard Kostick, CEO of the beauty brand 100% Pure. Many websites have tried using AI to assist shopping, but Alibaba has been one of the most aggressive. In March, Eddie Wu, CEO of the site’s parent company Alibaba Group, told managers that integrating the company’s core services with Qwen’s AI capabilities is a top priority. During a Chinese New Year promotion of Qwen’s personal shopping AI agent, where the company gave away cash, customers placed 200 million orders, the firm says. Vincenzo Toscano, an e-commerce seller and consultant, recommended Accio to his clients before deciding to try it himself for a new sunglasses brand. He came in with a rough vision: a brand shaped by his Italian heritage, his personal style, and a boutique aesthetic. He says the AI helped turn that concept into something more concrete, suggesting materials, refining the look, and pointing to design ideas that felt current. But the tool has clear limits. McClary, who uses AI tools regularly, says Accio is strongest when it comes to product ideation, but less helpful on marketing questions such as advertising and social media outreach. To use it well, he says, buyers still need to challenge its recommendations, since some can be generic.
The rest of the business As platforms become more AI-driven, manufacturers are adjusting too. Sally Yan, a representative at a makeup packaging company in Wuhan, China, says her firm has started writing more detailed product descriptions and adding information about its equipment and manufacturing experience on Alibaba.com because it suspects those details make its listings more likely to be surfaced by AI. Yan says manufacturers cannot tell whether an inquiry from a customer was generated or guided by AI, and that her firm is not using AI to negotiate pricing or product details. “AI agents are increasingly used by people to assist decision making or even directly making transactions, and in certain situations, they can become extremely useful,” “AI agents are increasingly used by people to assist purchase decisions and even directly making transactions, and with clear data guardrails, they can become extremely useful,” says Jiaxin Pei, a research scientist at the Stanford Institute for Human-Centered AI, “but agents need to act transparently, securely, and in the customer’s best interest.” Pei says developers of these tools should disclose the data they collect and the incentives built into them to ensure that the marketplace remains fair. Zhang, of Alibaba.com, says Accio currently does not include advertising. Suppliers can pay for higher placement in Alibaba.com’s regular search results, but Zhang says Accio is “not integrated” with that system. “We haven’t had a clear answer in terms of how to monetize this tool,” he says. For now, users can pay for additional tokens to continue chatting with the agent after their free queries run out. Sellers say that while AI tools have made it easier to come up with ideas and get a business off the ground, they do not replace the core skills that make someone good at e-commerce. McClary believes that even when sellers have access to the same market information, some are still better at making decisions, acting quickly, and actually delivering on orders. Those differences, he says, still go a long way. Toscano, the brand founder and e-commerce consultant, feels good about officially launching his new brand of sunglasses in just a few months: “We [small business owners] always have to bootstrap a lot of decisions. Deciding what to sell often comes down to an educated guess,” he says, “And we’re now in an era when making those decisions is easier than ever.”
Chevron resumes natural gas production at Leviathan
@import url(‘https://fonts.googleapis.com/css2?family=Inter:[email protected]&display=swap’); a { color: var(–color-primary-main); } .ebm-page__main h1, .ebm-page__main h2, .ebm-page__main h3, .ebm-page__main h4, .ebm-page__main h5, .ebm-page__main h6 { font-family: Inter; } body { line-height: 150%; letter-spacing: 0.025em; font-family: Inter; } button, .ebm-button-wrapper { font-family: Inter; } .label-style { text-transform: uppercase; color: var(–color-grey); font-weight: 600; font-size: 0.75rem; } .caption-style { font-size: 0.75rem; opacity: .6; } #onetrust-pc-sdk [id*=btn-handler], #onetrust-pc-sdk [class*=btn-handler] { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-policy a, #onetrust-pc-sdk a, #ot-pc-content a { color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-pc-sdk .ot-active-menu { border-color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-accept-btn-handler, #onetrust-banner-sdk #onetrust-reject-all-handler, #onetrust-consent-sdk #onetrust-pc-btn-handler.cookie-setting-link { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-consent-sdk .onetrust-pc-btn-handler { color: #c19a06 !important; border-color: #c19a06 !important; } Chevron Mediterranean Ltd. restarted production at the Leviathan natural gas field 130 km offshore Haifa in the eastern Mediterranean after a suspension due to the Iran war, partner NewMed Energy said in a release. The operator had previously received clearance from the Petroleum Commissioner to proceed with preparations to resume operations at the Leviathan platform offshore Israel. Regular production from the reservoir was restarted on Apr. 2. Chevron is operator at Leviathan (39.66%) with partners NewMed Energy (45.34%) and Ratio Energies (15%).
QatarEnergy, ExxonMobil reach first production from Train 1 at Golden Pass
@import url(‘https://fonts.googleapis.com/css2?family=Inter:[email protected]&display=swap’); a { color: var(–color-primary-main); } .ebm-page__main h1, .ebm-page__main h2, .ebm-page__main h3, .ebm-page__main h4, .ebm-page__main h5, .ebm-page__main h6 { font-family: Inter; } body { line-height: 150%; letter-spacing: 0.025em; font-family: Inter; } button, .ebm-button-wrapper { font-family: Inter; } .label-style { text-transform: uppercase; color: var(–color-grey); font-weight: 600; font-size: 0.75rem; } .caption-style { font-size: 0.75rem; opacity: .6; } #onetrust-pc-sdk [id*=btn-handler], #onetrust-pc-sdk [class*=btn-handler] { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-policy a, #onetrust-pc-sdk a, #ot-pc-content a { color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-pc-sdk .ot-active-menu { border-color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-accept-btn-handler, #onetrust-banner-sdk #onetrust-reject-all-handler, #onetrust-consent-sdk #onetrust-pc-btn-handler.cookie-setting-link { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-consent-sdk .onetrust-pc-btn-handler { color: #c19a06 !important; border-color: #c19a06 !important; } Golden Pass LNG, a joint venture between QatarEnergy and ExxonMobil, reached first production of LNG from Train 1 at the export project in Sabine Pass, Tex. With first LNG completed, the joint venture advances work to deliver its first cargo, achieve sustained liquefaction operations, and meet its commercial and strategic objectives, ExxonMobil said in a release Mar. 30. Train 1 is one of three LNG trains comprising the 18-million tonnes/year plant. The start of LNG exports to global customers is expected in this year’s second quarter. QatarEnergy holds 70% interest in Golden Pass LNG, while ExxonMobil holds the remaining 30%.