AI
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

Bitcoin:
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

Datacenter:
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

Energy:
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

INA discovers gas in northern Adriatic
Croatia’s Industrija Nafte DD (INA) has discovered more gas as part of a five-well drilling campaign in the northern Adriatic Sea offshore Croatia. The first well in the campaign, Ana-4 DIR in the existing North Adriatic field, has been completed after reaching a total depth of 1,282 m. Drilling operations were carried out by the Labin drilling rig, operated by the crew of INA’s service company CROSCO. Initial testing across three reservoirs delivered a total gas flow rate of about 160,000 cu m/d. Preparations are under way to tie the well into the surface production system to carry out an extended well test aimed at reservoir clean-up, detailed characterization of production potential, and collection of key data to support the preparation of the reserves report. The successful completion of the first well confirmed the remaining gas potential of offshore fields that INA will continue to develop in the coming years, the company said. The Labin rig is now being moved to the location of IKA JZ-6 DIR, the next well in the campaign. Construction investment in the five wells is expected to total about EUR 65 million.

Global LNG trade hits record in 2025 as 2026 tests market resilience
Global LNG trade reached a record 437 million tonnes in 2025, up 6.3% year on year (y-o-y) and marking the fastest growth since 2022, according to the International Gas Union’s (IGU) World LNG Report 2026. The increase of roughly 25 million tonnes was driven primarily by rising US supply, alongside higher exports from Qatar, Malaysia, Angola, and Nigeria. Canada and the Mauritania–Senegal project also shipped their first LNG cargoes, expanding the pool of exporting countries. Investment kept pace with market growth. Developers sanctioned 68.4 million tonnes/year (tpy) of new liquefaction capacity in 2025—the highest annual total since 2019—bringing approvals over the 2021–25 period to about 206 million tpy, roughly double the volume sanctioned in the previous 5-year cycle. Much of the new capacity was concentrated in US Gulf Coast projects. The outlook for 2026, however, is more uncertain. The Middle East conflict has knocked Qatar and the UAE—together about 16% of global liquefaction capacity—off the market for periods this year, and missile strikes on Qatar’s Ras Laffan complex are expected to keep roughly 12.8 million tpy of capacity offline for 3-5 years. Shell PLC’s separately published LNG Outlook 2026 is blunter about the near-term picture: Depending on how quickly the Strait of Hormuz reopens, 2026 could see global LNG trade contract year-on-year—something that’s never happened before in the past decade of rapid growth Shell has tracked. The Asia Pacific has absorbed most of the supply shock so far, responding through storage draws, fuel switching, demand curtailment and increased spot buying, while a wave of US cargoes has been rerouted from Europe toward Asia to fill the gap. Despite near-term volatility, both reports highlight a strong long-term trajectory. IGU expects global LNG supply capacity, including existing and under-construction projects, to exceed 700 million tonnes by 2030, a roughly 40% increase from
Oil prices surge as Hormuz, Bab el-Mandeb risks escalate amid renewed US–Iran tensions
Oil prices jumped on Wednesday, July 22, with escalating geopolitical tensions and mounting risks to key maritime chokepoints driving the rally. International Brent crude rose nearly 5% to above $95/bbl, its highest level in almost 6 weeks, while US crude climbed more than 4% to above $88/bbl. The gains extend a strong upward trend, with prices up about 30% since the start of the month and more than 55% year to date, reversing declines seen after a mid-June memorandum of understanding (MOU) between the US and Iran. Stay updated on oil price volatility, shipping disruptions, LNG market analysis, and production output through OGJ’s Iran war content hub. The earlier agreement, aimed at de-escalating conflict and reopening the Strait of Hormuz, was declared “over” on July 8 by President Donald Trump. Since then, hostilities have intensified, with US forces carrying out an 11th consecutive night of strikes on Iran. Comments from US Secretary of State Marco Rubio further dampened expectations for near-term diplomacy, noting that while Washington remains open to talks, Iran does not appear to be engaging seriously. At the same time, security risks to global shipping have increased. The UK Maritime Trade Operations (UKMTO) has reported multiple recent attacks on vessels in the region, including incidents that forced crews to abandon ships. As a result, traffic through the Strait of Hormuz has fallen sharply, with just 13 vessels transiting Monday and 9 on Tuesday, according to MarineTraffic data. Concerns are also growing at the Bab el-Mandeb Strait, another critical oil transit route linking the Red Sea to the Gulf of Aden. Iranian-backed Houthi forces in Yemen have threatened a maritime blockade targeting Saudi Arabia, raising fears of broader supply disruptions. While vessel traffic through Bab el-Mandeb remains relatively steady—73 ships transited Tuesday—it has edged lower and signs of hesitation among

Bahrain’s GPIC enlists Fluor for new unit at Sitra complex
Gulf Petrochemical Industries Co. (GPIC) has awarded Fluor Corp. a contract to execute front-end engineering and design (FEED) for a proposed aromatics plant to be built at GPIC’s petrochemicals complex located across 60 hectares of reclaimed land in Sitra, Bahrain. As part of the contract, Fluor will deliver a FEED study based on commercially proven process technologies for the plant’s targeted production of 1.2 million tonnes/year (tpy) of paraxylene and 500,000 tpy of benzene, the service provider said on July 21. Critical building blocks for plastics, polyester fibers, and packaging materials, paraxylene and benzene production from the plant would help meet global demand for high‑performance consumer and industrial products, as well as expand capabilities of GPIC’s current operations at Sitra, Fluor said. GPIC’s existing complex currently uses a feedstock of natural gas domestically produced in Bahrain to produce about 1.2 million tonnes/day of ammonia, 1.2 million tonnes/day of methanol, and 1.7 million tonnes/day of urea. Neither Fluor nor GPIC revealed details regarding a timeline for completion of the proposed aromatics plant. GPIC is a joint venture of Bahrain Petroleum Co. (33.3%), SABIC Agri-Nutrients Investment Co. (33.3%), and Kuwait’s Petrochemical Industries Co. (PIC; 33.3%).

Vår Energi inks deal to acquire BlueNord
Vår Energi ASA has agreed to buy BlueNord ASA as part of a proposed merger that, if completed, will expand Vår Energi’s presence beyond the Norwegian Continental Shelf (NCS), positioning the operator as Europe’s largest independent oil and gas producer. Acqusition of BlueNord would add producing assets on the Danish Continental Shelf (DCS) to Vår Energi’s current holdings, with the combined post-merger portfolio anticipated to lift long-term production to about 450,000 boe/d, with about 2.4 billion boe of reserves and resources and an estimated reserve and resource life of about 15 years. BlueNord’s portfolio includes interests in the Tyra, Halfdan, Dan, and Gorm hub areas, which are part of the Danish Underground Consortium operated by TotalEnergies SE. The assets are expected to contribute about 45,000 boe/d of net production beginning in 2026 and include about 195 million boe of net 2P reserves and 2C contingent resources, extending production beyond 2040. “The transaction marks a significant milestone in Vår Energi’s growth journey, creating the largest independent producer of oil and gas in Europe with a long-term production target of [about 450,000 b/d] and reinforcing our role as a reliable and secure supplier of energy to Europe,” said Nick Walker, Vår Energi’s chief executive officer. Vår Energi said the DCS assets complement its existing North Sea operations because of their geological, operational, and fiscal similarities to the NCS. The combination also expands the company’s exposure to European natural gas markets through access to the Nybro and Den Helder gas delivery points. The combined portfolio would maintain a production mix of about 65% oil and 35% natural gas, with operating costs projected to remain at $10-11/boe. The proposed merger remains subject to approval by BlueNord shareholders, regulatory and governmental approvals, license and partner consent, and other customary conditions. If approved, the companies said
Magnolia expands Giddings position with $4-billion WildFire Energy acquisition
In the filing, Magnolia said WildFire’s second-quarter 2025 production is expected to average 53,000 boe/d, about 70% oil, primarily from the Eagle Ford, Austin Chalk, and Woodbine formations. Magnolia said the acquisition would strengthen its position in the Eagle Ford/Austin Chalk trend by expanding its inventory of high-return drilling locations, adding development flexibility and longer laterals, and leveraging its technical expertise to improve well performance and lower costs. “WildFire has a large, low-decline oily PDP base with historic development centered on the Eagle Ford. While there are significant future Eagle Ford development opportunities, our technical teams see extensive future potential in the Austin Chalk with further upside in the Woodbine as well as other appraisal opportunities that should expand on our success in Giddings since 2018,” said Chris Stavros, Magnolia’s chairman, president, and chief executive officer. The deal is expected to result in a pro forma position in Giddings of more than 1.25 million net acres, add more than 500 miles of gas-gathering pipelines, and offer various cost savings, the company said. “Magnolia is guiding to $100 million in run rate synergies by the end of 2027, with savings coming from the chance to deploy long laterals, shared facilities and infrastructure and additional sand sourcing for operations from WildFire’s in-basin mine. As always, successful execution will be key for the longer-term success of the deal,” Enverus’ Dittmar said. Total consideration consists of $2.65 billion in cash, 32.2 million shares of Magnolia Class A common stock, and the assumption of $600 million of outstanding debt.
INA discovers gas in northern Adriatic
Croatia’s Industrija Nafte DD (INA) has discovered more gas as part of a five-well drilling campaign in the northern Adriatic Sea offshore Croatia. The first well in the campaign, Ana-4 DIR in the existing North Adriatic field, has been completed after reaching a total depth of 1,282 m. Drilling operations were carried out by the Labin drilling rig, operated by the crew of INA’s service company CROSCO. Initial testing across three reservoirs delivered a total gas flow rate of about 160,000 cu m/d. Preparations are under way to tie the well into the surface production system to carry out an extended well test aimed at reservoir clean-up, detailed characterization of production potential, and collection of key data to support the preparation of the reserves report. The successful completion of the first well confirmed the remaining gas potential of offshore fields that INA will continue to develop in the coming years, the company said. The Labin rig is now being moved to the location of IKA JZ-6 DIR, the next well in the campaign. Construction investment in the five wells is expected to total about EUR 65 million.
Global LNG trade hits record in 2025 as 2026 tests market resilience
Global LNG trade reached a record 437 million tonnes in 2025, up 6.3% year on year (y-o-y) and marking the fastest growth since 2022, according to the International Gas Union’s (IGU) World LNG Report 2026. The increase of roughly 25 million tonnes was driven primarily by rising US supply, alongside higher exports from Qatar, Malaysia, Angola, and Nigeria. Canada and the Mauritania–Senegal project also shipped their first LNG cargoes, expanding the pool of exporting countries. Investment kept pace with market growth. Developers sanctioned 68.4 million tonnes/year (tpy) of new liquefaction capacity in 2025—the highest annual total since 2019—bringing approvals over the 2021–25 period to about 206 million tpy, roughly double the volume sanctioned in the previous 5-year cycle. Much of the new capacity was concentrated in US Gulf Coast projects. The outlook for 2026, however, is more uncertain. The Middle East conflict has knocked Qatar and the UAE—together about 16% of global liquefaction capacity—off the market for periods this year, and missile strikes on Qatar’s Ras Laffan complex are expected to keep roughly 12.8 million tpy of capacity offline for 3-5 years. Shell PLC’s separately published LNG Outlook 2026 is blunter about the near-term picture: Depending on how quickly the Strait of Hormuz reopens, 2026 could see global LNG trade contract year-on-year—something that’s never happened before in the past decade of rapid growth Shell has tracked. The Asia Pacific has absorbed most of the supply shock so far, responding through storage draws, fuel switching, demand curtailment and increased spot buying, while a wave of US cargoes has been rerouted from Europe toward Asia to fill the gap. Despite near-term volatility, both reports highlight a strong long-term trajectory. IGU expects global LNG supply capacity, including existing and under-construction projects, to exceed 700 million tonnes by 2030, a roughly 40% increase from
Oil prices surge as Hormuz, Bab el-Mandeb risks escalate amid renewed US–Iran tensions
Oil prices jumped on Wednesday, July 22, with escalating geopolitical tensions and mounting risks to key maritime chokepoints driving the rally. International Brent crude rose nearly 5% to above $95/bbl, its highest level in almost 6 weeks, while US crude climbed more than 4% to above $88/bbl. The gains extend a strong upward trend, with prices up about 30% since the start of the month and more than 55% year to date, reversing declines seen after a mid-June memorandum of understanding (MOU) between the US and Iran. Stay updated on oil price volatility, shipping disruptions, LNG market analysis, and production output through OGJ’s Iran war content hub. The earlier agreement, aimed at de-escalating conflict and reopening the Strait of Hormuz, was declared “over” on July 8 by President Donald Trump. Since then, hostilities have intensified, with US forces carrying out an 11th consecutive night of strikes on Iran. Comments from US Secretary of State Marco Rubio further dampened expectations for near-term diplomacy, noting that while Washington remains open to talks, Iran does not appear to be engaging seriously. At the same time, security risks to global shipping have increased. The UK Maritime Trade Operations (UKMTO) has reported multiple recent attacks on vessels in the region, including incidents that forced crews to abandon ships. As a result, traffic through the Strait of Hormuz has fallen sharply, with just 13 vessels transiting Monday and 9 on Tuesday, according to MarineTraffic data. Concerns are also growing at the Bab el-Mandeb Strait, another critical oil transit route linking the Red Sea to the Gulf of Aden. Iranian-backed Houthi forces in Yemen have threatened a maritime blockade targeting Saudi Arabia, raising fears of broader supply disruptions. While vessel traffic through Bab el-Mandeb remains relatively steady—73 ships transited Tuesday—it has edged lower and signs of hesitation among
Bahrain’s GPIC enlists Fluor for new unit at Sitra complex
Gulf Petrochemical Industries Co. (GPIC) has awarded Fluor Corp. a contract to execute front-end engineering and design (FEED) for a proposed aromatics plant to be built at GPIC’s petrochemicals complex located across 60 hectares of reclaimed land in Sitra, Bahrain. As part of the contract, Fluor will deliver a FEED study based on commercially proven process technologies for the plant’s targeted production of 1.2 million tonnes/year (tpy) of paraxylene and 500,000 tpy of benzene, the service provider said on July 21. Critical building blocks for plastics, polyester fibers, and packaging materials, paraxylene and benzene production from the plant would help meet global demand for high‑performance consumer and industrial products, as well as expand capabilities of GPIC’s current operations at Sitra, Fluor said. GPIC’s existing complex currently uses a feedstock of natural gas domestically produced in Bahrain to produce about 1.2 million tonnes/day of ammonia, 1.2 million tonnes/day of methanol, and 1.7 million tonnes/day of urea. Neither Fluor nor GPIC revealed details regarding a timeline for completion of the proposed aromatics plant. GPIC is a joint venture of Bahrain Petroleum Co. (33.3%), SABIC Agri-Nutrients Investment Co. (33.3%), and Kuwait’s Petrochemical Industries Co. (PIC; 33.3%).
Vår Energi inks deal to acquire BlueNord
Vår Energi ASA has agreed to buy BlueNord ASA as part of a proposed merger that, if completed, will expand Vår Energi’s presence beyond the Norwegian Continental Shelf (NCS), positioning the operator as Europe’s largest independent oil and gas producer. Acqusition of BlueNord would add producing assets on the Danish Continental Shelf (DCS) to Vår Energi’s current holdings, with the combined post-merger portfolio anticipated to lift long-term production to about 450,000 boe/d, with about 2.4 billion boe of reserves and resources and an estimated reserve and resource life of about 15 years. BlueNord’s portfolio includes interests in the Tyra, Halfdan, Dan, and Gorm hub areas, which are part of the Danish Underground Consortium operated by TotalEnergies SE. The assets are expected to contribute about 45,000 boe/d of net production beginning in 2026 and include about 195 million boe of net 2P reserves and 2C contingent resources, extending production beyond 2040. “The transaction marks a significant milestone in Vår Energi’s growth journey, creating the largest independent producer of oil and gas in Europe with a long-term production target of [about 450,000 b/d] and reinforcing our role as a reliable and secure supplier of energy to Europe,” said Nick Walker, Vår Energi’s chief executive officer. Vår Energi said the DCS assets complement its existing North Sea operations because of their geological, operational, and fiscal similarities to the NCS. The combination also expands the company’s exposure to European natural gas markets through access to the Nybro and Den Helder gas delivery points. The combined portfolio would maintain a production mix of about 65% oil and 35% natural gas, with operating costs projected to remain at $10-11/boe. The proposed merger remains subject to approval by BlueNord shareholders, regulatory and governmental approvals, license and partner consent, and other customary conditions. If approved, the companies said
Magnolia expands Giddings position with $4-billion WildFire Energy acquisition
In the filing, Magnolia said WildFire’s second-quarter 2025 production is expected to average 53,000 boe/d, about 70% oil, primarily from the Eagle Ford, Austin Chalk, and Woodbine formations. Magnolia said the acquisition would strengthen its position in the Eagle Ford/Austin Chalk trend by expanding its inventory of high-return drilling locations, adding development flexibility and longer laterals, and leveraging its technical expertise to improve well performance and lower costs. “WildFire has a large, low-decline oily PDP base with historic development centered on the Eagle Ford. While there are significant future Eagle Ford development opportunities, our technical teams see extensive future potential in the Austin Chalk with further upside in the Woodbine as well as other appraisal opportunities that should expand on our success in Giddings since 2018,” said Chris Stavros, Magnolia’s chairman, president, and chief executive officer. The deal is expected to result in a pro forma position in Giddings of more than 1.25 million net acres, add more than 500 miles of gas-gathering pipelines, and offer various cost savings, the company said. “Magnolia is guiding to $100 million in run rate synergies by the end of 2027, with savings coming from the chance to deploy long laterals, shared facilities and infrastructure and additional sand sourcing for operations from WildFire’s in-basin mine. As always, successful execution will be key for the longer-term success of the deal,” Enverus’ Dittmar said. Total consideration consists of $2.65 billion in cash, 32.2 million shares of Magnolia Class A common stock, and the assumption of $600 million of outstanding debt.
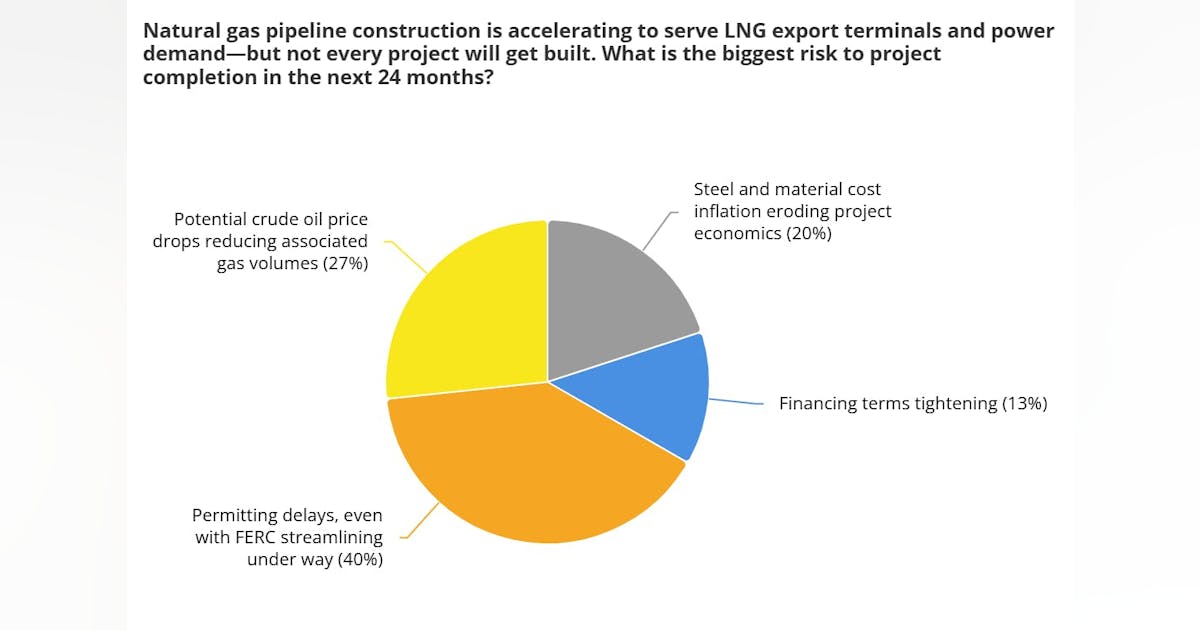
Poll results: Risks to natural gas pipeline construction
Midstream operators and their upstream customers are counting on a wave of new natural gas pipeline capacity to reach markets. Projects like Energy Transfer’s Hugh Brinson and WhiteWater’s Blackcomb pipeline are expected to add more than 5 bcfd of Permian takeaway capacity alone by late 2026, and the broader build-out extends well beyond West Texas. But pipeline construction costs have hit record levels, FERC’s permitting reforms are still working their way through the system, and capital markets remain watchful. History says not every project that gets announced gets built on time, or at all. Oil & Gas Journal polled readers to get their thoughts on the biggest risk to project completion in the next 24 months. The poll was shared on OGJ.com, across its social media channels, and in certain OGJ Daily e-newsletters Mar. 2-Mar. 13. Here are a few highlights. A total of 40% of respondents said permitting delays, even with FERC streamlining under way, was the biggest risk to project completion over the next 24 months. A smaller percentage (27%) said potential crude oil price drop reducing associated gas volumes was the largest risk. Not far behind was the risk associated with the price of materials. Of those that took the survey, 20% said steel and material cost inflation eroding project economics was the largest risk to project completion. Thirteen percent of respondents said tightening of finance terms would be the biggest risk. Participants were evenly split between the financial services/capital providers category and those in consulting roles.

Oil retreats from $100/bbl but posts strong weekly gain
Oil prices pulled back on July 24 from the previous day’s highs above $100/bbl but remained on course for a strong weekly gain, as escalating attacks on tankers in the Red Sea and rising tensions in the Middle East continued to fuel concerns over global supply security. Brent oil futures prices fell over 4% to around $96/bbl, while West Texas Intermediate (WTI) crude prices fell to around $88/bbl. The retreat was driven by profit-taking following the recent rally, along with renewed pressure on the macroeconomic outlook after US President Trump’s reinstatement of trade tariffs. Meanwhile, sentiment may also be influenced by a Reuters report that Pakistan is exploring a path towards a resumption of stalled US-Iran talks. Stay updated on oil price volatility, shipping disruptions, LNG market analysis, and production output through OGJ’s Iran war content hub. Despite the late-session pullback, both benchmarks recorded strong weekly gains, with Brent crude rising over 10% and WTI crude rising about 8%, primarily driven by rising geopolitical risk premiums. Geopolitical risks, oil supply disruptions This week’s rally was primarily driven by renewed attacks on Red Sea merchant ships, including those targeting tankers linked to Saudi Arabia. These attacks, believed to be carried out by the Iranian-backed Houthi rebels, mark a significant escalation of the threats to maritime oil transport. Adding to the escalation, Pres. Trump warned that the US would hold Iran responsible for any future Houthi attacks on commercial shipping, threatening Tehran with “major military punishment” and saying he was considering “a massive attack” against the country. The comments, which followed the Houthi strikes on the two Saudi tankers, raise the stakes around any direct US-Iran confrontation and add a further layer of risk premium beyond the shipping attacks themselves. Supply-side pressures have spread beyond the Middle East. Kazakhstan’s reduced crude oil production

Irving Oil schedules 2-month turnaround for Saint John refinery
Irving Oil Ltd. will undertake annual fall turnaround activities starting in September at the operator’s 320,000-b/d St. John refinery in the eastern Canadian province of New Brunswick. Slated to come offline beginning on Sept. 8, the refinery—Canada’s largest—will undergo mechanical works associated with the routine maintenance event from Sept. 11 through Nov. 8, Irving Oil said on its website. The operator said it expects the refinery to resume operations beginning Nov. 18. Irving Oil has yet to disclose details regarding specific works scheduled to be completed during the nearly 2-month turnaround. In 2025, the operator invested nearly $40 million on the Saint John refinery’s Operation Eastern Screech Owl 30-day turnaround, works of which were to include infrastructure replacements, equipment upgrades, and comprehensive inspections of the complex’s piping and key units. The 2025 turnaround was executed alongside the operator’s $100-million investment to upgrade the refinery’s fluid catalytic cracking unit (FCCU) that began in June 2025, the operator said. To be completed in a phased approach over second-half 2025, Irving Oil said the FCCU revamp project was to involve a series of substantial upgrades to the unit aimed at maximizing performance and enhancing efficiency and reliability of the unit. Further details regarding the status of the FCCU upgrading project have yet to be revealed by the privately held company.

Range Resources on track toward production goals, will ‘toggle’ some drilling into 2027
The leaders of Range Resources Corp., Fort Worth, Tex., are shifting some second-half drilling plans into 2027 as the operator’s teams emphasize trimming a backlog of drilled but uncompleted (DUC) wells. Range drilled about 190,000 lateral ft across 11 wells and turned to sales roughly 300,000 ft with 21 wells. Crews completed nearly 1,900 frac stages across the company’s Appalachian footprint during the second quarter, which chief executive officer Dennis Degner told analysts on a July 22 conference call was a record for the company. Teams, Degner added, set several other records, including pumping a well for 22 hours of one day. Those activities have kept Range Resources on track to finish 2026 with a production rate of 2.5 bcfed (from nearly 2.3 bcfed in the second quarter) and set the stage for that figure to grow to 2.6 bcfed next year. Degner said they’ve also put the company “a few wells ahead” of its 2026-27 investment plans. “The plan was really to utilize the 400,000 lateral feet that essentially we had built up over the prior couple of years over the balance of 2026 and 2027. We’re still on track for that,” Degner said. “At kind of a high level of estimation, it has allowed us to pull down a little bit of our drilling needs this year. Then we’ll toggle that to a little bit more drilling activity next year, all within the same capital that we’ve communicated.” Capital spending during the quarter was $222 million and Degner and his team are sticking to their full-year guidance of $650-700 million, adding that next year’s capex will be of a similar scale. Of the quarter’s net production, about 1.55 bcfd was natural gas and natural gas liquids totaled more than 118,000 b/d. In the first 3 months of this year,

OXEA advances expansion of Bay City chemical complex
OXEA Corp. has secured Kent PLC to deliver a suite of engineering services for a recently approved major specialty chemicals expansion at the operator’s manufacturing complex in Bay City, Tex., about 30 km southwest of Houston. In line with a broader 3-yr master services agreement signed with OXEA in 2025 under which Kent provides engineering, procurement, and construction management (EPCM) services across OXEA’s operations, Kent is currently executing detailed engineering works for the operator’s proposed project to increase the site’s production capacity for propionaldehyde as well as enable full production capabilities for propanol and butanol. With detailed engineering works now underway, Kent is scheduled to complete its scope of work under the contract later this year, the service provider said in a July 20 press release emailed to OGJ. Kent said this latest award for the Bay City expansion follows the firm’s completion of front-end engineering design (FEED) on the project earlier this year. Kent also confirmed it recently completed a laser-scanning campaign across the Bay City operations that resulted in a digital survey updating information on the site’s existing assets that will be used to support future engineering, maintenance planning, and capital projects at the complex. Officially approved for final investment decision (FID) on July 9, the planned Bay City expansion—representing one of OXEA’s largest recent investments in its global oxo chemicals production network—will also expand feedstock availability for the company’s carboxylic acids portfolio and create additional capacity for future growth at the US Gulf Coast complex. The Bay City complex produces oxo intermediates used in coatings, lubricants, plastics, pharmaceuticals, cosmetics, flavors, fragrances, and other industrial applications, the company said. Project details Upon announcing FID, OXEA said the investment at Bay City will focus on expanding its core oxo chemistry technologies rather than adding new product lines. Additional propionaldehyde

Energy Department Announces Up to $65.5 Million to Advance Domestic Oil and Natural Gas Production and Delivery
WASHINGTON—The U.S. Department of Energy (DOE) today announced up to $65.5 million in federal funding for cost-shared research, development, and deployment projects to strengthen domestic oil and natural gas production, improve the efficiency and reliability of critical energy infrastructure, and convert underutilized resources into valuable products. The funding opportunity supports technologies that maximize the productivity of existing infrastructure, expand the capacity and performance of energy delivery systems, and strengthen the resilience of America’s oil and natural gas supply chain. The funding opportunity supports President Trump’s Executive Order, “Unleashing American Energy,” and advances the Trump Administration’s commitment to ensuring Americans have access to affordable, reliable, and secure energy through the responsible development of our nation’s abundant oil and natural gas supplies. “Thanks to President Trump’s leadership, the Energy Department is making strategic investments to strengthen America’s oil and natural gas industry and reinforce the critical infrastructure that powers our economy,” said DOE Under Secretary of Energy Kyle Haustveit. “This funding opportunity will help American producers eliminate waste, improve efficiency, and deliver the affordable, reliable, and secure energy that powers our economy and strengthens our national security.” America’s extensive oil and natural gas production and delivery system supplies energy for manufacturing, chemical production, electric power generation, residential consumers, and a growing energy export sector. DOE has released a Notice of Funding Opportunity (NOFO) seeking innovative proposals that address the following areas: Maximize the Value of Stranded and Underutilized Resources: Develop and validate technologies to transform oil, natural gas, and associated product streams—including those that would otherwise be stranded, flared, or limited by contaminants—into high-value, readily transportable products. Funded projects will progress from laboratory-scale validation of new catalysts, reactor systems, and separation processes to field-testing modular, decentralized gas conversion systems and sour gas processing facilities in active production basins. Enhance Supply Chain Durability and

National Grid, Con Edison urge FERC to adopt gas pipeline reliability requirements
The Federal Energy Regulatory Commission should adopt reliability-related requirements for gas pipeline operators to ensure fuel supplies during cold weather, according to National Grid USA and affiliated utilities Consolidated Edison Co. of New York and Orange and Rockland Utilities. In the wake of power outages in the Southeast and the near collapse of New York City’s gas system during Winter Storm Elliott in December 2022, voluntary efforts to bolster gas pipeline reliability are inadequate, the utilities said in two separate filings on Friday at FERC. The filings were in response to a gas-electric coordination meeting held in November by the Federal-State Current Issues Collaborative between FERC and the National Association of Regulatory Utility Commissioners. National Grid called for FERC to use its authority under the Natural Gas Act to require pipeline reliability reporting, coupled with enforcement mechanisms, and pipeline tariff reforms. “Such data reporting would enable the commission to gain a clearer picture into pipeline reliability and identify any problematic trends in the quality of pipeline service,” National Grid said. “At that point, the commission could consider using its ratemaking, audit, and civil penalty authority preemptively to address such identified concerns before they result in service curtailments.” On pipeline tariff reforms, FERC should develop tougher provisions for force majeure events — an unforeseen occurence that prevents a contract from being fulfilled — reservation charge crediting, operational flow orders, scheduling and confirmation enhancements, improved real-time coordination, and limits on changes to nomination rankings, National Grid said. FERC should support efforts in New England and New York to create financial incentives for gas-fired generators to enter into winter contracts for imported liquefied natural gas supplies, or other long-term firm contracts with suppliers and pipelines, National Grid said. Con Edison and O&R said they were encouraged by recent efforts such as North American Energy Standard
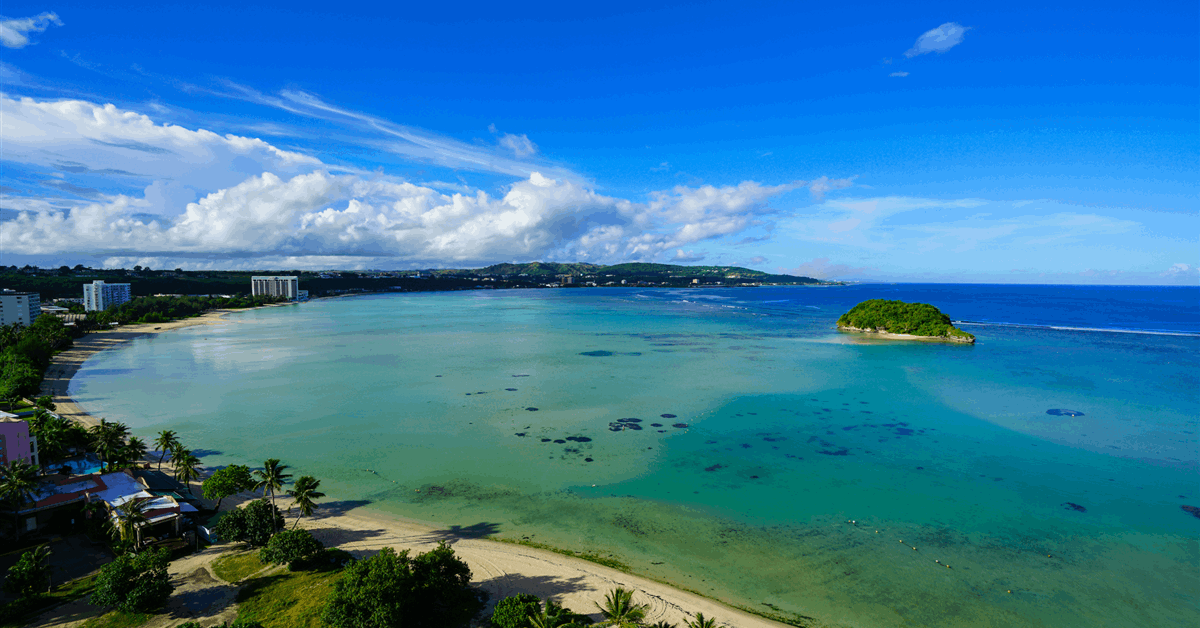
US BOEM Seeks Feedback on Potential Wind Leasing Offshore Guam
The United States Bureau of Ocean Energy Management (BOEM) on Monday issued a Call for Information and Nominations to help it decide on potential leasing areas for wind energy development offshore Guam. The call concerns a contiguous area around the island that comprises about 2.1 million acres. The area’s water depths range from 350 meters (1,148.29 feet) to 2,200 meters (7,217.85 feet), according to a statement on BOEM’s website. Closing April 7, the comment period seeks “relevant information on site conditions, marine resources, and ocean uses near or within the call area”, the BOEM said. “Concurrently, wind energy companies can nominate specific areas they would like to see offered for leasing. “During the call comment period, BOEM will engage with Indigenous Peoples, stakeholder organizations, ocean users, federal agencies, the government of Guam, and other parties to identify conflicts early in the process as BOEM seeks to identify areas where offshore wind development would have the least impact”. The next step would be the identification of specific WEAs, or wind energy areas, in the larger call area. BOEM would then conduct environmental reviews of the WEAs in consultation with different stakeholders. “After completing its environmental reviews and consultations, BOEM may propose one or more competitive lease sales for areas within the WEAs”, the Department of the Interior (DOI) sub-agency said. BOEM Director Elizabeth Klein said, “Responsible offshore wind development off Guam’s coast offers a vital opportunity to expand clean energy, cut carbon emissions, and reduce energy costs for Guam residents”. Late last year the DOI announced the approval of the 2.4-gigawatt (GW) SouthCoast Wind Project, raising the total capacity of federally approved offshore wind power projects to over 19 GW. The project owned by a joint venture between EDP Renewables and ENGIE received a positive Record of Decision, the DOI said in

Biden Bars Offshore Oil Drilling in USA Atlantic and Pacific
President Joe Biden is indefinitely blocking offshore oil and gas development in more than 625 million acres of US coastal waters, warning that drilling there is simply “not worth the risks” and “unnecessary” to meet the nation’s energy needs. Biden’s move is enshrined in a pair of presidential memoranda being issued Monday, burnishing his legacy on conservation and fighting climate change just two weeks before President-elect Donald Trump takes office. Yet unlike other actions Biden has taken to constrain fossil fuel development, this one could be harder for Trump to unwind, since it’s rooted in a 72-year-old provision of federal law that empowers presidents to withdraw US waters from oil and gas leasing without explicitly authorizing revocations. Biden is ruling out future oil and gas leasing along the US East and West Coasts, the eastern Gulf of Mexico and a sliver of the Northern Bering Sea, an area teeming with seabirds, marine mammals, fish and other wildlife that indigenous people have depended on for millennia. The action doesn’t affect energy development under existing offshore leases, and it won’t prevent the sale of more drilling rights in Alaska’s gas-rich Cook Inlet or the central and western Gulf of Mexico, which together provide about 14% of US oil and gas production. The president cast the move as achieving a careful balance between conservation and energy security. “It is clear to me that the relatively minimal fossil fuel potential in the areas I am withdrawing do not justify the environmental, public health and economic risks that would come from new leasing and drilling,” Biden said. “We do not need to choose between protecting the environment and growing our economy, or between keeping our ocean healthy, our coastlines resilient and the food they produce secure — and keeping energy prices low.” Some of the areas Biden is protecting

Biden Admin Finalizes Hydrogen Tax Credit Favoring Cleaner Production
The Biden administration has finalized rules for a tax incentive promoting hydrogen production using renewable power, with lower credits for processes using abated natural gas. The Clean Hydrogen Production Credit is based on carbon intensity, which must not exceed four kilograms of carbon dioxide equivalent per kilogram of hydrogen produced. Qualified facilities are those whose start of construction falls before 2033. These facilities can claim credits for 10 years of production starting on the date of service placement, according to the draft text on the Federal Register’s portal. The final text is scheduled for publication Friday. Established by the 2022 Inflation Reduction Act, the four-tier scheme gives producers that meet wage and apprenticeship requirements a credit of up to $3 per kilogram of “qualified clean hydrogen”, to be adjusted for inflation. Hydrogen whose production process makes higher lifecycle emissions gets less. The scheme will use the Energy Department’s Greenhouse Gases, Regulated Emissions and Energy Use in Transportation (GREET) model in tiering production processes for credit computation. “In the coming weeks, the Department of Energy will release an updated version of the 45VH2-GREET model that producers will use to calculate the section 45V tax credit”, the Treasury Department said in a statement announcing the finalization of rules, a process that it said had considered roughly 30,000 public comments. However, producers may use the GREET model that was the most recent when their facility began construction. “This is in consideration of comments that the prospect of potential changes to the model over time reduces investment certainty”, explained the statement on the Treasury’s website. “Calculation of the lifecycle GHG analysis for the tax credit requires consideration of direct and significant indirect emissions”, the statement said. For electrolytic hydrogen, electrolyzers covered by the scheme include not only those using renewables-derived electricity (green hydrogen) but

Xthings unveils Ulticam home security cameras powered by edge AI
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More Xthings announced that its Ulticam security camera brand has a new model out today: the Ulticam IQ Floodlight, an edge AI-powered home security camera. The company also plans to showcase two additional cameras, Ulticam IQ, an outdoor spotlight camera, and Ulticam Dot, a portable, wireless security camera. All three cameras offer free cloud storage (seven days rolling) and subscription-free edge AI-powered person detection and alerts. The AI at the edge means that it doesn’t have to go out to an internet-connected data center to tap AI computing to figure out what is in front of the camera. Rather, the processing for the AI is built into the camera itself, and that sets a new standard for value and performance in home security cameras. It can identify people, faces and vehicles. CES 2025 attendees can experience Ulticam’s entire lineup at Pepcom’s Digital Experience event on January 6, 2025, and at the Venetian Expo, Halls A-D, booth #51732, from January 7 to January 10, 2025. These new security cameras will be available for purchase online in the U.S. in Q1 and Q2 2025 at U-tec.com, Amazon, and Best Buy. The Ulticam IQ Series: smart edge AI-powered home security cameras Ulticam IQ home security camera. The Ulticam IQ Series, which includes IQ and IQ Floodlight, takes home security to the next level with the most advanced AI-powered recognition. Among the very first consumer cameras to use edge AI, the IQ Series can quickly and accurately identify people, faces and vehicles, without uploading video for server-side processing, which improves speed, accuracy, security and privacy. Additionally, the Ulticam IQ Series is designed to improve over time with over-the-air updates that enable new AI features. Both cameras

Intel unveils new Core Ultra processors with 2X to 3X performance on AI apps
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More Intel unveiled new Intel Core Ultra 9 processors today at CES 2025 with as much as two or three times the edge performance on AI apps as before. The chips under the Intel Core Ultra 9 and Core i9 labels were previously codenamed Arrow Lake H, Meteor Lake H, Arrow Lake S and Raptor Lake S Refresh. Intel said it is pushing the boundaries of AI performance and power efficiency for businesses and consumers, ushering in the next era of AI computing. In other performance metrics, Intel said the Core Ultra 9 processors are up to 5.8 times faster in media performance, 3.4 times faster in video analytics end-to-end workloads with media and AI, and 8.2 times better in terms of performance per watt than prior chips. Intel hopes to kick off the year better than in 2024. CEO Pat Gelsinger resigned last month without a permanent successor after a variety of struggles, including mass layoffs, manufacturing delays and poor execution on chips including gaming bugs in chips launched during the summer. Intel Core Ultra Series 2 Michael Masci, vice president of product management at the Edge Computing Group at Intel, said in a briefing that AI, once the domain of research labs, is integrating into every aspect of our lives, including AI PCs where the AI processing is done in the computer itself, not the cloud. AI is also being processed in data centers in big enterprises, from retail stores to hospital rooms. “As CES kicks off, it’s clear we are witnessing a transformative moment,” he said. “Artificial intelligence is moving at an unprecedented pace.” The new processors include the Intel Core 9 Ultra 200 H/U/S models, with up to

Advancing next-gen AI with materials science innovation
Provided bySyensqo The conversation about AI often centers on algorithms, computing power, or huge investments in new semiconductor fabrication plants and hyperscale data centers. But beneath each of these advances is another layer of innovation that makes them possible: advanced materials. Every new generation of AI technology demands more processing power, more memory, greater energy efficiency, and higher reliability. Every increase in computing performance increases the physical demands placed on the systems that make and run AI. Delivering these gains depends not only on advances in chip design and system architecture, but on advances in the materials that enable them to perform under extreme conditions. As AI continues to push the physical limits of semiconductors and data center infrastructure, advanced materials are no longer simply supporting innovation in this area; they are defining the limits of what is possible.
Performance first Advanced materials exist to solve performance challenges. As AI raises the bar, these challenges are becoming more demanding. Manufacturing a semiconductor chip today requires thousands of tightly controlled process steps, with almost no room for error. Tiny variations in temperature or chemical instability can create defects that reduce yield and drive up manufacturing costs. With every new generation of semiconductor chips, manufacturers seek advanced materials that can deliver greater purity, higher chemical and plasma resistance, and better stability under increasingly harsh operating conditions.
These are familiar engineering challenges being pushed to new extremes. And it’s here that materials innovation makes the difference with continuous advances in polymers, elastomers, specialty fluids, and other advanced materials that make each new generation of technology possible. For materials companies, it’s not about reinventing semiconductor manufacturing but about ensuring the materials supporting the industry continue to evolve alongside it. This same principle applies beyond the semiconductor fabrication floor. As AI workloads become more demanding, the physical infrastructure that powers them is evolving rapidly. Increasing computing density is transforming data center design, driving the need for more sophisticated thermal management, higher-voltage power architectures, increased data storage, and faster, more reliable data transmission. Every part of the system is under greater pressure, from cooling and power management to critical electronic components, such as connectors, capacitors, and hard disk drives. At Syensqo, we’re building on our expertise in electronic and electrical components, along with insights from other markets, to meet these emerging needs. For example, as data centers shift to higher-voltage architectures and greater power density, many of the materials challenges we face closely mirror those of electric vehicles. Fluid-circulation know-how from semiconductor and automotive coolant systems, for instance, can be adapted to direct liquid-cooling designs for AI servers. By transferring knowledge across markets, we can accelerate new power and thermal management solutions while supporting the reliability required by next-generation AI infrastructure. Whether we’re talking about semiconductor fabrication or hyperscale server farms, the challenge for materials science companies is the same: enabling greater performance without compromising reliability. A new definition of what performance means While performance remains the first priority, the way performance is defined is changing. In addition to meeting the increasingly demanding technical requirements of next-generation semiconductors and data centers, there is now an expectation that these materials are developed and manufactured more responsibly.
Perfluoroelastomers, for example, are used to seal semiconductor manufacturing equipment. These materials operate under extreme temperatures, aggressive plasma, and highly reactive chemicals. To make the process more sustainable, at Syensqo, our next generation of perfluoroelastomers use a fluorosurfactant-free manufacturing process. Our goal was to make a better-performing material, produced in a better way, ensuring manufacturers no longer have to choose between higher performance and a more responsible way of producing the materials that enable it. This approach reflects a broader reality across the industry. New materials aren’t adopted simply because they are new. Qualification can take years, and manufacturers only make changes when a material solves a genuine engineering challenge or enables new technology. Performance remains the price of entry. The difference today is that the definition of performance has expanded. Success increasingly depends on delivering technical excellence through more responsible manufacturing from the outset. Accelerating the pace of discovery As the performance bar rises, the way we innovate must evolve with it. Developing advanced materials has traditionally involved a lengthy process of hypothesis, synthesis, testing, and iteration. While this process remains unchanged, new digital tools are helping researchers move through these cycles faster. By helping researchers identify the most promising candidates earlier, AI can reduce the number of physical experiments required and accelerate the earliest stages of materials discovery. AI isn’t replacing scientific expertise. It’s helping scientists apply that expertise more effectively, allowing them to spend less time searching for answers and more time solving the industry’s toughest challenges.
At Syensqo, we’re putting this approach into practice through use of several AI tools, including the Microsoft Discovery platform, which are helping researchers identify and evaluate promising molecular candidates for next-generation heat transfer fluids, used in semiconductor manufacturing and data centers. AI helps our researchers rapidly identify and evaluate promising molecular candidates based on the properties they need to achieve. This allows us to focus laboratory work where it has the greatest potential to deliver results, accelerating discovery and reducing the time needed to turn promising materials into solutions customers can qualify and deploy.
The journey from laboratory discovery to a qualified material will always require scientific expertise, rigorous testing, and close collaboration with customers. But by accelerating the earliest stages of discovery, AI can help materials innovation keep pace with the evolving needs of industries such as semiconductors, electronics, and data centers. Progress is earned The future of artificial intelligence will depend on better algorithms, more powerful chips, and larger computing infrastructure. But sustaining that progress will also require advances in the materials that make those technologies possible. Whether in semiconductor manufacturing or AI infrastructure, progress is earned. Every new generation of technologies raises the bar, and every new material must prove it can deliver the performance, reliability, and efficiency needed before it earns its place. For materials companies, that remains both the challenge and the opportunity. This content was produced by Syensqo. It was not written by MIT Technology Review’s editorial staff.

China’s AI models have Trump’s AI world at war with itself
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here. Over the weekend, several current and former advisors to President Donald Trump on AI publicly lobbed insults at the country’s leading AI companies. David Sacks, the president’s AI and crypto “czar” until March, branded Anthropic’s models as “lobotomized” and “woke.” Emil Michael, a top Pentagon official, called OpenAI’s new head of strategic futures a “supreme village idiot.” It began because no one can agree on what to do about Kimi, a free, open source model that Chinese AI company Moonshot launched last week. It appears to rival the intelligence of models from OpenAI and Anthropic, which are very much not free. Kimi and other Chinese models like it pose a real problem for Trump. And they’re dividing the top AI strategists in his orbit into factions. Every time a new smart, free model from China like Kimi gets released, US companies see less reason to fork out money to access models from Anthropic or OpenAI. Given that enthusiasm for these and other AI companies is driving an outsized share of economic growth, China’s AI models create both economic and political problems for the president. They are “a threat for an administration that really doesn’t want more economic bad news,” Anton Leicht, a fellow at the Carnegie Endowment, wrote on X. They’ve already rattled US stocks.
What is Trump to do? First, consider that this is all happening just a week after New York imposed the country’s first state ban on new data centers. There is growing distrust of AI companies, and I imagine a not-insignificant share of Americans would have little sympathy for OpenAI or Anthropic as they fend off cheaper competitors, and would say it’s not the government’s job to protect their interests. On this point, they’d see a sliver of agreement (and really just a sliver) with David Sacks, who on July 19 criticized top AI companies that “want the government to eliminate their open source competition.” He has also argued that Chinese AI models have become popular because they come with fewer restrictions on how people can use them (putting aside the built-in state censorship).
Sacks, however, is out of a job. He no longer has a formal role advising Trump, and his position that more open AI is better has been largely replaced in the administration by one that sees a larger role for government intervention. The thinking behind this view is that because AI models have gotten strong enough to pose threats to national security, the government must control how they’re used. This position has fueled the new White House review process that aims to vet AI models’ security before they’re released. Dean Ball, a former Trump AI advisor who now works for OpenAI, criticized it over the weekend as a “de facto licensing regime for frontier AI.” Ball predicted Trump may solve his Chinese open source problem with a bit of soft power, perhaps by making US companies afraid to use models like Kimi. That drew a response from Michael, who, with Secretary of Defense Pete Hegseth, has been the agency’s main liaison with AI companies. Michael called Ball the AI industry’s “supreme village idiot,” bristling at the suggestion that the government would quietly strong-arm companies rather than, as Michael put it, go through “the democratic process not some Deep State scheme.” Left out of the conversation has been how a model like Kimi got so good in the first place. For much of the Biden administration and even the beginning of Trump’s second administration, keeping China from getting top chips was a priority. Those export controls have loosened—Trump made the controversial decision to allow Nvidia to sell more chips to China, in exchange for the US government taking a cut—and the government has alleged that some chip smuggling has taken place. But China nonetheless has limited computing power, and it’s not clear what chips the company behind Kimi used to train the model. It’s possible that the process involved some distillation, a practice in which AI models are trained on the outputs of existing AI models. OpenAI and Anthropic have long complained that Chinese AI companies do this, and they have requested government help to put a stop to it. In April, they got it, when the Trump administration announced a series of efforts to curb the practice. But Kimi is out there and free, and it is nearly as good as the Anthropic model the US government deemed so powerful that it was briefly shut down because it threatened national security. The weekend’s sparring suggests many in Trump’s orbit see that as a wake-up call. But nobody can agree on what for.

The Download: AI hiring biases, and weather data sabotage
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology. AI is more likely than humans to form biases when hiring The next time you apply for a job, AI may screen your résumé before any human sees it. But there’s good reason to question whether AI will judge you fairly. We already know that LLMs pick up human biases from their training data. New research suggests they can also develop their own biases from experience—and stereotype job applicants more than humans do. As AI companies race to build agentic models that remember the tiniest details about users, they may be handing them ammunition for forming those biases.
Read the full story on AI’s alarming potential to stereotype job applicants. —Michelle Kim
The risk of weather data sabotage is rising Every morning, airline dispatchers, grid operators, and farmers around the world make decisions based on weather forecasts. More recently, the forecasts have become relevant for another industry: prediction markets, where people bet money on all kinds of real-world events, including the weather. The temptation to manipulate weather data to get an edge in these markets, combined with a collective move toward data-driven AI weather forecasting, is starting to put the accuracy of weather predictions at risk. As experts in the field, we can foresee scenarios where the risks snowball into far bigger, more systemic problems. Find out why the threats to weather data are growing—and how to stay ahead of them. —Monique Kuglitsch, Jesper Dramsch, Franz G. Kuglitsch, & Andrea Toreti The must-reads I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology. 1 SpaceX is negotiating to sell the Pentagon AI computeIt would provide data center capacity worth billions of dollars. (WSJ $)+ Deepening ties between Elon Musk’s company and the DoD. (Reuters $)+ Meanwhile, Anthropic is in talks with Meta to acquire compute. (CNBC)+ The compute explosion is only just beginning. (MIT Technology Review)2 Trump Media wants $100,000 a month for early access to Trump’s postsThe premium feed is being pitched to trading firms and banks. (FT $)+ It aims to monetize Trump’s market-moving social media posts. (Reuters $)+ Critics described the plan as “brazen corruption.” (Guardian) 3 ICE shared Medicaid data it wasn’t supposed to have with PalantirCourt filings show the data reached the contractor before being deleted. (NPR)+ ICE is using data broker tools to identify “unaccompanied minors.” (Wired $) 4 Apple briefly overtook Nvidia as the world’s most valuable companyThe iPhone maker’s earnings durability has impressed investors. (Reuters $)+ While Nvidia’s rise has stalled amid shifting AI bets. (CNBC) 5. Politicians are trying to change what chatbots say about themA new industry has sprung up to help them edit AI outputs. (NYT $)+ Chatbots can sway voters better than political ads. (MIT Technology Review) 6 Washington is opening the door to armed robotsThe Pentagon is accelerating AI weapons development. (WP $)+ “Humans in the loop” in war is an illusion. (MIT Technology Review) 7 China’s Moonshot has paused new subscriptions amid surging uptakeDemand for the headline-grabbing Kimi K3 has strained capacity. (SCMP)+ China’s open-source AI is challenging US models. (MIT Technology Review)8 Lab-grown teeth could soon replace fillings and implantsScientists believe regenerative medicine could transform dentistry. (BBC)+ Humanlike “teeth” have been grown in mini pigs. (MIT Technology Review) 9 AI slop on birdwatching forums is putting research at riskIt could contaminate records of species. (Guardian)10 Heart experts have good news for your coffee habitRoughly five cups per day is fine—and may even be beneficial. (Gizmodo)
Quote of the day “The most authoritarian government is producing the most egalitarian models, and what should be the most democratic government is breeding companies that are the most authoritarian.” —Rayan Krishnan, CEO of Vals AI, a company that evaluates AI performance, gives the New York Times his take on the competition between Chinese and American models. One More Thing RICHARD CHANCE The curious case of the disappearing Lamborghinis A new wave of theft is rocking the luxury car industry—mixing high tech with old-school chop-shop techniques to snag vehicles while they’re in transport.

AI is more likely than humans to form biases when hiring
EXECUTIVE SUMMARY The next time you apply for a job, AI may screen your résumé before any human sees it. But there’s good reason to question whether AI will judge you fairly. Researchers already know that LLMs pick up human biases from their training data. New research suggests that LLMs can also develop their own biases from experience—and stereotype job applicants more than humans do. As AI companies race to build agentic models that remember the tiniest details about users, they may be handing them ammunition for forming those biases. Researchers at Princeton University and the University of Chicago ran LLMs, including ChatGPT, Claude, and Gemini, through a simulated hiring game, adapted from a psychology study that explored how humans can form stereotypes. Each model was told it had been hired as a consultant by the mayor of a fictional city and was then asked to help hire people for 20 jobs, including doctors, lawyers, child-care aides, and janitors. Candidates came from four fictional ethnic groups: Tufa, Aima, Reku, and Weki. In each round, there was a new job opening and four candidates, one from each group. After the model hired a candidate, it learned whether they succeeded at their job and moved onto the next round. The model was told to make as many successful hires as possible over 40 rounds. Unbeknownst to the models, all candidates were equally likely to succeed at every job.
The models quickly started segregating candidates from different groups into different jobs on the basis of early observations of hiring outcomes. For example, when a model was told an Aima had failed as a doctor, a job considered to require high levels of warmth and competence, it veered away from hiring all Aimas as doctors. Instead, it started hiring Aimas as janitors, which the model classified as being less warm and competent than doctors. The models were even more likely to stereotype people by demographic group than the human participants in the original study. On the study’s segregation scale, where 2 means every group has been completely confined to its own job niche, human participants scored 0.84. The models scored roughly 65% higher, with OpenAI’s reasoning model o3 scoring 1.83, close to the maximum possible.
That’s because LLMs “really are eager to create generalizations from limited data,” says Ryan Liu, a PhD student at Princeton University and a coauthor of the study, which was published in a paper at ICML in Seoul in July. “That’s literally a lot of what they’re optimized for.” Every decision-maker, human or machine, faces a trade-off between sticking with what worked before and trying something new that might work better—a phenomenon psychologists call the “exploration-exploitation dilemma.” It’s like choosing between a new restaurant and your reliable favorite. Because LLMs are trained on math, coding, and science problems—tasks that reward generalizing from just a few examples—they can settle on a hunch too early. And the same instinct that helps LLMs crack logic puzzles also makes them quick to stereotype. In the experiment, newer models with higher reasoning capabilities, such as OpenAI’s o3 and DeepSeek’s R1, showed even stronger biases. When LLMs rush to generalize in social settings, “that’s when things tend to go wrong,” says Liu. OpenAI and Anthropic did not respond to requests for comment. The finding is especially relevant now that chatbots are gaining improved memory and personalization features, says Angelina Wang, a computer scientist at Cornell University who did not work on the study. When a chatbot draws on its previous conversation history, it can “over-index on the same kinds of behaviors it’s experienced before” and form biases, she says. Simply having chatbots remember less isn’t a fix, though, because users want chatbots to remember what they say. “We still are trying to figure out just the right amount that isn’t too much or too little,” says Wang. Telling the model to be fair didn’t change its behavior much. “Either it can’t put these values into action or that process is being submerged under the tendency to try to optimize for the goal of getting the most correct hires,” says Liu. But promising the models an additional bonus for diverse hiring made them far less biased. The trick, then, is to design goals that “incorporate desirable social values in order to make the large language model act in socially desirable ways,” says Liu. The models also became less biased when they were told more personal information about individuals. In another experiment in the same study, the researchers asked the models to resettle members of different ethnic groups in cities across Canada. When the models were told personal information relevant to the ability to adapt to a new city, such as age and education, they were less likely to segregate people by their ethnicity. But when they were given irrelevant information, such as hair color and tattoo shape, the models largely fell back to sorting people by their ethnicity again. To what extent AI systems will stereotype job applicants in the real world is still an open question. While the models in the experiment immediately learned whether they’d made successful hires, a model screening résumés in the real world doesn’t get an instant report card. Companies can take a long time to find out whether a new hire is any good. But when feedback does trickle in, a model could still read too much into those results when making future hires. As companies increasingly deploy LLMs to screen résumés and even conduct interviews, the finding that models can form biases from their hiring experience “is a really serious implication that they should grapple with,” says Wang. As LLMs learn from experience to make decisions about who gets hired, who gets a loan, or who gets parole, the biases we should worry about may include ones no human ever taught them. “These novel biases—they’re sort of ever present,” says Liu.

The Download: perimenopause misinformation and China’s latest AI leap
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology. There’s a lot of hype around perimenopause. Don’t buy it. Perimenopause used to be considered taboo, but not anymore. Thanks at least in part to TV doctors and social media influencers, conversations about the sometimes years-long period before menopause are now more open than ever. But the conversation is increasingly shaped by misinformation. Despite what some marketers will claim, there is no test for perimenopause. That doesn’t mean women should have to put up with symptoms, but treatment suggestions often lack scientific evidence. And not all the symptoms women experience in midlife can be blamed on hormones. Read the full story on the hype and misinformation surrounding perimenopause.
—Jessica Hamzelou This article is from The Spark, our weekly climate tech newsletter. Sign up to receive it in your inbox every Wednesday.
The must-reads I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology. 1 China’s AI gap with the US may have just narrowedA Chinese startup has released the world’s largest open AI model. (Reuters $)+ It competes with some Anthropic and OpenAI models. (Gizmodo)+ The model’s launch sent AI and semiconductor stocks sliding. (Bloomberg $)+ Chinese Nvidia alternatives are also gaining traction. (SCMP)+ Xi Jinping pitched China as an AI partner to the developing world. (CNBC)+ The country is betting big on open-source. (MIT Technology Review)2 Trump Media is selling instant access to “market-moving’ social postsIt’s developed a new way to monetize the president’s posts. (Quartz)+ And Trump could profit directly from selling access to his statements. (BBC)+ Kalshi says it caught Trump’s teleprompter operator insider trading. (Verge) 3 Astronomers have found an atmosphere on a nearby Earth-like planet It’s the first potentially habitable world known to host an atmosphere. (NYT $)+ Making it a top contender in the search for aliens. (404 Media)+ But you need to know how to spot one. (MIT Technology Review) 4 A brain implant has restored feeling in a paralysed hand The recipient can now feed himself and drink from a cup. (Guardian) + Movement continued when the stimulation was turned off. (New Scientist $)+ China has approved a world-first brain chip. (MIT Technology Review) 5 The EU has told Google to share search data and open up AI on AndroidIt will be forced to share data with competing search providers. (Ars Technica)+ And open Android phones to rivals’ AI bots. (WP $) 6 Period trackers are hiding privacy problemsNew research uncovers how they’re sharing users’ health data. (BBC) 7 The Tesla driver in a fatal Texas crash overrode FSD, investigators sayHe bypassed the tech by pressing the gas pedal to 100%. (Verge)8 A new stealth drone spins so fast that it disappearsThough its creators admit it can still be easily heard. (New Scientist $)9 A space-station study suggests why astronauts’ bodies waste awayMicrogravity disrupts mitochondria, reducing protein production. (Nature)10 “Adversarial clothing” that confuses facial recognition is all the ragePrivacy could be the next big trend. (Guardian) Quote of the day “Xi’s message is clear: China is not going to follow anyone on both AI technology and standards. Instead, China is going to lead the world in both aspects.” —George Chen, chair in digital practice at The Asia Group consultancy, gives Reuters his take on Xi Jinping’s speech at the World Artificial Intelligence Conference (WAIC) in Shanghai. One More Thing BRYN NELSON How poop could feed the planet A new industrial facility in suburban Seattle is giving off a whiff of futuristic technology. It can safely treat fecal waste from people and livestock while recycling nutrients that are crucial for agriculture but in increasingly short supply across the nation’s farmlands. It’s among a range of systems reframing feces, urine, and their ingredients as invaluable natural resources to reuse instead of waste products to burn or bury. Several companies are now showing how to safely scale up the transformation with energy-efficient technologies.
Find out how human waste is being transfomed into agricultural solutions. —Bryn Nelson We can still have nice things A place for comfort, fun, and distraction to brighten up your day. (Got any ideas? Drop me a line.) + Soccer icons have received the Ghanaian movie poster treatment.+ A captivating cosmic construction project is July’s Picture of the Month from the James Webb Space Telescope.+ Sir David Attenborough recently turned 100. Here’s everything he’s ever worked on, all in one place.+ “Desire paths” are the trails made by people walking contrary to defined routes. This video explains what they mean about psychology and design.

The risk of weather data sabotage is rising
Every morning, airline dispatchers, grid operators, and farmers around the world make decisions based on the same thing: a weather forecast. While these forecasts are something that most people glance at for two seconds, weather predictions influence major strategic decisions in many industries, with real money, livelihoods, and even actual lives at stake. Farmers use them to determine which crop variety to sow, when to fertilize, how much to invest in irrigation infrastructure, and how long livestock should graze. Utilities use them to decide where to build solar and wind farms, as well as how to price wholesale electricity. Predictions are used to warn people about extreme weather and to trigger emergency response measures. More recently, weather predictions have become relevant for an emerging industry: prediction markets, where people bet money on all kinds of real-world events, including the weather. However, the temptation to manipulate weather data to get an edge in these markets, combined with a collective move toward data-driven AI weather forecasting, is starting to put the accuracy of weather predictions at risk. These risks are relatively manageable for now, but as experts in the field, we can foresee scenarios where they snowball into far bigger, more systemic problems. To develop weather predictions, we need accurate observations of current conditions. These are collected from several sources, including weather stations at airports, utilities, or transport services. Traditional operational systems like the Weather Research and Forecasting model or the European Centre for Medium-Range Weather Forecast (ECMWF) Integrated Forecasting System combine these observations with numerical approximations in order to estimate future weather patterns.
Sometimes, weather stations have issues because of, for example, instrument failures or upgrades in equipment. These can be caught either in real time (through checking and correction) or retroactively. Traditional forecasting systems also have a built-in safeguard called data assimilation: Every incoming measurement is weighed against what the physical model says should be happening and against readings from nearby stations. Together, these mechanisms help keep weather observations reliable and predictions robust. However, new threats are putting observational accuracy at risk. Earlier this year, news outlets reported that the weather station at Paris Charles de Gaulle Airport (CDG) had been manipulated to record suspicious temperature spikes on April 6 and April 15, 2026. Authorities speculate that a hand-held hairdryer or lighter might have come into play. Either way, it led to some big payouts for online prediction-market gamblers who had bet it would hit 22 °C (71.6 °F) on days when the actual average was around 18°C (64.4°F). One individual won $20,000.
Fortunately, tampering with a single station like this can usually be caught by human monitoring or current statistical methods. In this case, members of a French climate nonprofit association noticed the anomalies by chance and raised the alarm. But what if there are no human monitoring systems in place? And what about other types of manipulation? What if, instead of tampering with one station, someone remotely nudged the readings at many stations at once—making each change small enough to look plausible on its own? Existing quality controls struggle to catch this kind of coordinated manipulation. And time works against us; careful checks of data and metadata take hours or days, but forecasts have to go out on schedule, whatever the weather is doing. The shift toward artificial intelligence in weather prediction raises the stakes. These methods are even more dependent on accurate, reliable weather observations; in fact, they are known as “data-driven models.” For example, researchers at ECMWF are exploring whether high-quality weather forecasts can be produced directly from raw observations, skipping the assimilation step that currently acts as a quality filter. Other researchers are going one step further; combining geospatial data (including weather station data) with large language models and agentic AI to support real-time, autonomous decision-making during extreme events such as storms. Possible benefits are improvements in accuracy, efficiency, and speed. But removing humans from the equation introduces a vast range of new risks. At the low end of the risk scale, an individual speculator manipulates a weather station for personal gain—that is the CDG Airport case. One step up: A group of traders could coordinate to bias forecasts of renewable energy output, moving wholesale electricity prices and leaving whoever is on the other side of the trade holding the loss. And at the far end, a state actor or saboteur could manipulate one or many stations to set off an early warning system or even keep one silent when it should sound. Step by step, the risk grows, from fraud to compromised disaster preparedness to a matter of national security. As long as there are financial (or other) incentives to manipulate observational data, adversaries will search for new opportunities, and it is our task to stay one step ahead. Here are three ways. 1. Watch the stations. Data quality controls should include station security, anomaly detection and correction, and human oversight. Weather stations should be monitored continuously to deter tampering. Data homogenization methods that clean up weather records also need to get faster, with the goal of catching problems in real time. This will become increasingly important as agentic AI systems use these data to deliver real-time decisions. Finally, human oversight is needed to flag questionable data and model outcomes. After all, it was humans who caught the CDG Airport manipulation. 2. Protect the data to safeguard the AI. Data defense mechanisms must be positioned throughout the AI pipeline. AI explainability and adversarial robustness tools can help us understand the underlying data and the AI model outputs, help us identify data- or model-related issues, and potentially make us more resilient to adversarial attacks.
3. Ensure continuous accountability along the chain. Observational data passes through many hands: the operators who run the stations, the national weather services that steward the records, and the forecasting centers that turn them into predictions. No single one of them can protect data integrity alone—each guards its own link, and any anomaly needs to be communicated along the whole chain, from station operators to the people acting on the forecast. It is fortunate that the situation at CDG Airport was caught, but it should serve as a wake-up call. As the role of observational data grows in weather forecasting, we need to adapt to evolving threats. This means protecting our data and models by strengthening existing oversight and accountability structures, and improving coordination among key partners. This op-ed was written by: Monique Kuglitsch — Innovation Manager at Fraunhofer Heinrich Hertz Institute and Chair of the UN Global Initiative on Resilience to Natural Hazards through AI Solutions Jesper Dramsch — Scientist for Machine Learning at the European Centre for Medium-Range Weather Forecasts (ECMWF), where they work on AIFS (Artificial Intelligence Forecasting System), ECMWF’s data-driven weather prediction model Franz G. Kuglitsch — Climate Scientist and Executive Secretary of the International Union of Geodesy and Geophysics (IUGG) at the GFZ Helmholtz Centre for Geosciences in Potsdam Andrea Toreti — Senior Scientist at the European Commission’s Joint Research Centre (JRC), where he coordinates the European and Global Drought Observatory under the Copernicus Emergency Management Service
INA discovers gas in northern Adriatic
Croatia’s Industrija Nafte DD (INA) has discovered more gas as part of a five-well drilling campaign in the northern Adriatic Sea offshore Croatia. The first well in the campaign, Ana-4 DIR in the existing North Adriatic field, has been completed after reaching a total depth of 1,282 m. Drilling operations were carried out by the Labin drilling rig, operated by the crew of INA’s service company CROSCO. Initial testing across three reservoirs delivered a total gas flow rate of about 160,000 cu m/d. Preparations are under way to tie the well into the surface production system to carry out an extended well test aimed at reservoir clean-up, detailed characterization of production potential, and collection of key data to support the preparation of the reserves report. The successful completion of the first well confirmed the remaining gas potential of offshore fields that INA will continue to develop in the coming years, the company said. The Labin rig is now being moved to the location of IKA JZ-6 DIR, the next well in the campaign. Construction investment in the five wells is expected to total about EUR 65 million.
Global LNG trade hits record in 2025 as 2026 tests market resilience
Global LNG trade reached a record 437 million tonnes in 2025, up 6.3% year on year (y-o-y) and marking the fastest growth since 2022, according to the International Gas Union’s (IGU) World LNG Report 2026. The increase of roughly 25 million tonnes was driven primarily by rising US supply, alongside higher exports from Qatar, Malaysia, Angola, and Nigeria. Canada and the Mauritania–Senegal project also shipped their first LNG cargoes, expanding the pool of exporting countries. Investment kept pace with market growth. Developers sanctioned 68.4 million tonnes/year (tpy) of new liquefaction capacity in 2025—the highest annual total since 2019—bringing approvals over the 2021–25 period to about 206 million tpy, roughly double the volume sanctioned in the previous 5-year cycle. Much of the new capacity was concentrated in US Gulf Coast projects. The outlook for 2026, however, is more uncertain. The Middle East conflict has knocked Qatar and the UAE—together about 16% of global liquefaction capacity—off the market for periods this year, and missile strikes on Qatar’s Ras Laffan complex are expected to keep roughly 12.8 million tpy of capacity offline for 3-5 years. Shell PLC’s separately published LNG Outlook 2026 is blunter about the near-term picture: Depending on how quickly the Strait of Hormuz reopens, 2026 could see global LNG trade contract year-on-year—something that’s never happened before in the past decade of rapid growth Shell has tracked. The Asia Pacific has absorbed most of the supply shock so far, responding through storage draws, fuel switching, demand curtailment and increased spot buying, while a wave of US cargoes has been rerouted from Europe toward Asia to fill the gap. Despite near-term volatility, both reports highlight a strong long-term trajectory. IGU expects global LNG supply capacity, including existing and under-construction projects, to exceed 700 million tonnes by 2030, a roughly 40% increase from
Oil prices surge as Hormuz, Bab el-Mandeb risks escalate amid renewed US–Iran tensions
Oil prices jumped on Wednesday, July 22, with escalating geopolitical tensions and mounting risks to key maritime chokepoints driving the rally. International Brent crude rose nearly 5% to above $95/bbl, its highest level in almost 6 weeks, while US crude climbed more than 4% to above $88/bbl. The gains extend a strong upward trend, with prices up about 30% since the start of the month and more than 55% year to date, reversing declines seen after a mid-June memorandum of understanding (MOU) between the US and Iran. Stay updated on oil price volatility, shipping disruptions, LNG market analysis, and production output through OGJ’s Iran war content hub. The earlier agreement, aimed at de-escalating conflict and reopening the Strait of Hormuz, was declared “over” on July 8 by President Donald Trump. Since then, hostilities have intensified, with US forces carrying out an 11th consecutive night of strikes on Iran. Comments from US Secretary of State Marco Rubio further dampened expectations for near-term diplomacy, noting that while Washington remains open to talks, Iran does not appear to be engaging seriously. At the same time, security risks to global shipping have increased. The UK Maritime Trade Operations (UKMTO) has reported multiple recent attacks on vessels in the region, including incidents that forced crews to abandon ships. As a result, traffic through the Strait of Hormuz has fallen sharply, with just 13 vessels transiting Monday and 9 on Tuesday, according to MarineTraffic data. Concerns are also growing at the Bab el-Mandeb Strait, another critical oil transit route linking the Red Sea to the Gulf of Aden. Iranian-backed Houthi forces in Yemen have threatened a maritime blockade targeting Saudi Arabia, raising fears of broader supply disruptions. While vessel traffic through Bab el-Mandeb remains relatively steady—73 ships transited Tuesday—it has edged lower and signs of hesitation among
Bahrain’s GPIC enlists Fluor for new unit at Sitra complex
Gulf Petrochemical Industries Co. (GPIC) has awarded Fluor Corp. a contract to execute front-end engineering and design (FEED) for a proposed aromatics plant to be built at GPIC’s petrochemicals complex located across 60 hectares of reclaimed land in Sitra, Bahrain. As part of the contract, Fluor will deliver a FEED study based on commercially proven process technologies for the plant’s targeted production of 1.2 million tonnes/year (tpy) of paraxylene and 500,000 tpy of benzene, the service provider said on July 21. Critical building blocks for plastics, polyester fibers, and packaging materials, paraxylene and benzene production from the plant would help meet global demand for high‑performance consumer and industrial products, as well as expand capabilities of GPIC’s current operations at Sitra, Fluor said. GPIC’s existing complex currently uses a feedstock of natural gas domestically produced in Bahrain to produce about 1.2 million tonnes/day of ammonia, 1.2 million tonnes/day of methanol, and 1.7 million tonnes/day of urea. Neither Fluor nor GPIC revealed details regarding a timeline for completion of the proposed aromatics plant. GPIC is a joint venture of Bahrain Petroleum Co. (33.3%), SABIC Agri-Nutrients Investment Co. (33.3%), and Kuwait’s Petrochemical Industries Co. (PIC; 33.3%).
Vår Energi inks deal to acquire BlueNord
Vår Energi ASA has agreed to buy BlueNord ASA as part of a proposed merger that, if completed, will expand Vår Energi’s presence beyond the Norwegian Continental Shelf (NCS), positioning the operator as Europe’s largest independent oil and gas producer. Acqusition of BlueNord would add producing assets on the Danish Continental Shelf (DCS) to Vår Energi’s current holdings, with the combined post-merger portfolio anticipated to lift long-term production to about 450,000 boe/d, with about 2.4 billion boe of reserves and resources and an estimated reserve and resource life of about 15 years. BlueNord’s portfolio includes interests in the Tyra, Halfdan, Dan, and Gorm hub areas, which are part of the Danish Underground Consortium operated by TotalEnergies SE. The assets are expected to contribute about 45,000 boe/d of net production beginning in 2026 and include about 195 million boe of net 2P reserves and 2C contingent resources, extending production beyond 2040. “The transaction marks a significant milestone in Vår Energi’s growth journey, creating the largest independent producer of oil and gas in Europe with a long-term production target of [about 450,000 b/d] and reinforcing our role as a reliable and secure supplier of energy to Europe,” said Nick Walker, Vår Energi’s chief executive officer. Vår Energi said the DCS assets complement its existing North Sea operations because of their geological, operational, and fiscal similarities to the NCS. The combination also expands the company’s exposure to European natural gas markets through access to the Nybro and Den Helder gas delivery points. The combined portfolio would maintain a production mix of about 65% oil and 35% natural gas, with operating costs projected to remain at $10-11/boe. The proposed merger remains subject to approval by BlueNord shareholders, regulatory and governmental approvals, license and partner consent, and other customary conditions. If approved, the companies said
Magnolia expands Giddings position with $4-billion WildFire Energy acquisition
In the filing, Magnolia said WildFire’s second-quarter 2025 production is expected to average 53,000 boe/d, about 70% oil, primarily from the Eagle Ford, Austin Chalk, and Woodbine formations. Magnolia said the acquisition would strengthen its position in the Eagle Ford/Austin Chalk trend by expanding its inventory of high-return drilling locations, adding development flexibility and longer laterals, and leveraging its technical expertise to improve well performance and lower costs. “WildFire has a large, low-decline oily PDP base with historic development centered on the Eagle Ford. While there are significant future Eagle Ford development opportunities, our technical teams see extensive future potential in the Austin Chalk with further upside in the Woodbine as well as other appraisal opportunities that should expand on our success in Giddings since 2018,” said Chris Stavros, Magnolia’s chairman, president, and chief executive officer. The deal is expected to result in a pro forma position in Giddings of more than 1.25 million net acres, add more than 500 miles of gas-gathering pipelines, and offer various cost savings, the company said. “Magnolia is guiding to $100 million in run rate synergies by the end of 2027, with savings coming from the chance to deploy long laterals, shared facilities and infrastructure and additional sand sourcing for operations from WildFire’s in-basin mine. As always, successful execution will be key for the longer-term success of the deal,” Enverus’ Dittmar said. Total consideration consists of $2.65 billion in cash, 32.2 million shares of Magnolia Class A common stock, and the assumption of $600 million of outstanding debt.