AI
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

Bitcoin:
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

Datacenter:
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

Energy:
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

Cisco, AMD bring enterprise-level security, visibility to Ryzen AI Halo systems
“Running more AI locally can help improve responsiveness, keep sensitive data closer to users, and reduce dependence on cloud-only approaches, but enterprises also need a way to monitor and manage these systems at scale. AMD and Cisco are addressing that gap by collaborating to pair high-performance local AI compute with the observability, governance, and control infrastructure needed for enterprises to deploy it responsibly,” AMD stated. “By combining AMD Ryzen AI Halo systems and our broader local AI software capabilities with Cisco’s enterprise networking, observability and security technologies, we are helping customers deploy AI in a way that is performant, secure, observable and manageable at scale,” said Jack Huynh, senior vice president and general manager, computing and graphics group with AMD, in a statement. A few other interesting statistics and trends cited during AMD CEO Lisa Su’s keynote at the Advancing AI event include:
The quest to keep organs alive outside the body
EXECUTIVE SUMMARY This week, I covered a fascinating effort to preserve organs outside the body. There’s a huge shortage of donor organs, and one of the main reasons is time—they survive only a matter of hours outside the body, even when they’re kept on ice. Doctors dream of organ banks—stores of human organs that can be preserved for days, weeks, months, or even longer. That would allow them to run tests on organs, find the best matches for them, and transport the organs to those recipients. In new research, one team has been able to supercool the kidneys of pigs—animals whose organs are of a similar size to human ones—and preserve them for days. The kidneys survived being stored at −4 °C (25 °F) and eventually reimplanted back into pigs. And that’s just the latest development in a field that is positively buzzing. It has proved super difficult to freeze organs. Once ice forms in them, they’re done. The ice crystals create all kinds of damage and render the organs unusable. That hasn’t stopped many researchers from trying.
Some have focused on cryopreservation—rapid extreme cooling that essentially leaves cells in a glasslike state. This process is now routine for eggs, sperm, and embryos, which are cooled to −196 °C in less than two seconds and can be used even after decades in storage. No one has managed to cryopreserve and thaw human organs for transplantation. But plenty of human bodies and brains have been stored at ultra-low temperatures in the hope that they might one day be rewarmed and brought back to life. (You can read more about why some people opt for cryonics here.)
In March, I wrote about Stephen L. Coles, a gerontologist who had opted to cryopreserve his own brain. After the scientist died in 2014, his body was taken to Alcor, a cryonics facility in Arizona. A team at the facility removed Coles’s head, perfused his brain with cryoprotective chemicals (which work like antifreeze), removed the brain from the skull, and cooled it to −146 °C. When Coles’s friend Greg Fahy, a cryobiologist, studied pieces of his brain years later, he found that the brain cells, which had shrunk, “bounced back” once they were rewarmed. But that doesn’t mean the cells are alive, or that it might one day be possible to reanimate the brain. As Matthew Powell Palm of Texas A&M told me at the time: “There are so many ways those neurons could be toast.” Powell Palm is working on other ways to preserve organs. It was he, along with his colleagues, who managed to store supercooled pig kidneys and successfully transplant them, in a study described as “a landmark achievement.” Those organs did better than kidneys stored on ice, he says. His approach didn’t require cryoprotectants. But other teams are exploring potential chemical cocktails that might allow them to store organs at lower temperatures, potentially for longer periods of time. (More on this in The Checkup soon!) Another way to prolong the lifespan of an organ is to use a machine that perfuses it with nutrients, mimicking what happens inside the body. Machine perfusion devices have become more commonly used over the last decade or so and are typically used to maintain livers and kidneys for up to about 24 hours. Researchers are now adapting this protocol for a growing list of organs, even eyeballs—a recent feat that might enable whole-eye transplants. In March, I went to visit scientists in Valencia who had developed a perfusion system for uteruses. They had used their device—which they nicknamed “Mother”—to keep a human uterus alive for a day. It’s an exciting time for organ preservation. Keep an eye out for more coverage from MIT Technology Review in the coming weeks. This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.

Cloudflare Internal DNS puts public and private DNS on one policy engine
“Instead of operating two separate DNS systems, customers use one API, one audit trail, one dashboard, and one policy engine for every DNS query—whether it is for a public website or an internal application,” Somoza said. Policy first. The resolver sits ahead of every lookup, not behind it. “Architecturally, Cloudflare Gateway becomes the resolver that customers connect to, and can use WARP, DNS over HTTPS, DNS over TLS, or traditional DNS,” Somoza said. “Gateway evaluates zero -trust policies first, then routes the query to the appropriate DNS view based on context, such as source IP, device posture, or network location.” No public path in. Internal zones sit outside the public DNS hierarchy entirely. “Internal zones are never assigned public nameservers—they are only reachable through Gateway, so every query is evaluated before it is resolved,” Somoza said.

The Download: an organ transplant breakthrough, and homegrown Chinese chips
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology. Supercooled kidneys have been transplanted into pigs in a “landmark achievement” When it comes to organ donation, time is everything. As soon as an organ has been removed from a donor’s body, it starts to deteriorate. Surgeons have only a matter of hours to get it into a recipient.In most cases, organs will be kept on ice during that time, at around 4 °C (39 °F). They cannot be frozen—in previous attempts, ice has formed, causing all kinds of damage. But now, scientists have come up with a device that allows organs to be cooled to -4 °C (25 °F) without forming any ice. They’ve tested it with pig organs and shown that kidneys, at least, can be preserved in the device for days then successfully transplanted. Read our story about their breakthrough, and why it raises hopes for longer-term storage of donated human organs.
—Jessica Hamzelou If you want to read more about this story and its implications for organ preservation and transplantation, sign up to receive The Checkup, our weekly biotech newsletter, later today.
The must-reads I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology. 1 Inside China’s epic push to replace US chips The gap between their chips’ capabilities remains large—for now. (WSJ $)+ How China is using open source AI as a new form of soft power around the globe. (NYT $)+ A new bill in the US takes aim at Chinese AI companies’ training practices. (NBC)+ US lawmakers are also mulling banning the military from using Chinese humanoid robots. (SCMP)2 Space data centers don’t exist yet, but people already oppose themEnvironmental experts warn it’ll further pollute the stratosphere. (Guardian)+ Four things we’d need to put data centers in space. (MIT Technology Review)+ What it’s like inside the data centers powering AI down here on Earth. (Axios)+ The left and right are finding common cause with data center protests in the US. (The Verge)3 US lawmakers are pushing for an AI ‘kill switch’After OpenAI’s models went rogue and hacked Hugging Face. (BBC)4 Peptides seem on the cusp of going mainstream in the USA lack of scientific evidence didn’t stop the FDA just voting to let some pharmacies to legally dispense them. (Wired $)+ How does Make America Healthy Again hold up to scientific scrutiny? (Nature)+ US measles cases are reaching levels not seen for three decades. (Wired $)+ Peptides are everywhere. Here’s what you need to know. (MIT Technology Review)5 The EU just fined Google almost $1 billionFor competition breaches over apps and search. (FT $)+ It came just a day before Trump renewed tariffs on 60 trading partners, including the EU. (BBC)6 Electric vehicles are selling well in EuropeAnd the share made by Chinese firms has doubled in the last year. (The Next Web)+ Hybrids are hot property in the US this summer. (Wired $)7 There’s a worsening shortage of computer science professorsYou can blame AI companies—they keep snapping them up, to our general detriment. (The Atlantic $) 8 A judge caught a stenographer allowing AI errors into their transcript It’s apparently the first time this has happened, but it certainly won’t be the last. (404 Media)+ Even judges themselves are falling for AI. (MIT Technology Review)9 Here’s what new tech millionaires will do with their IPO wealth 💸What a nice problem to have to grapple with! (Quartz $)10 Dating apps’ latest wheeze? In-person events Well well well, it seems we’ve come full circle. (Bloomberg $) Quote of the day “Call us optimists, call us dreamers. Just as we’ve always done, we’re betting on people.” —The voiceover from a new advert from Meta, which exhorts us to be more optimistic about AI.
One More Thing BELL HUTLEY AI is changing how we study bird migration In a warming world increasingly full of human infrastructure that can be deadly to them, like glass skyscrapers and power lines, migratory birds are facing many existential threats. Scientists rely on a combination of methods to track the timing and location of their migrations, though each has shortcomings. But now, machine-learning tools are unlocking a treasure trove of acoustic data for ecologists.
Atos launches sovereign cloud service to power comeback
Atos has launched a new sovereign cloud platform aimed squarely at European public sector bodies, healthcare providers and defense organizations. It’s the latest effort by European companies in their fight back against US dominance. Atos Sovereign Cloud offers a range of controls for data management, providing customers with resilience and full control over their data, complying with existing European legislation on data residency. “Digital sovereignty has become a global operational priority for organizations that need to manage dependencies, jurisdictional exposure and disruption risks across complex digital environments. Atos Sovereign Cloud gives customers a practical way to apply sovereign controls to their most critical workloads, while preserving flexibility, resilience and the ability to innovate securely,” said Michael Kollar, Atos Group digital sovereignty leader.

Microsoft explains why its West US Azure and cloud services failed
Microsoft cloud and Azure services hosted on the West Coast of the US went down for hours on Thursday when network connectivity failed. Although services running entirely within Microsoft’s West US cloud region were unaffected, any traffic entering or leaving the facilities was affected. Microsoft has now published a Preliminary Post Incident Review (PIR) of the incident, reporting that connectivity was lost for five hours between 14.44 UTC (7.44 a.m. Pacific Time) and 19.41 UTC on July 23. The problem was caused when a set of IP routes was removed in error while isolating a device for routine maintenance. Before starting the maintenance work, Microsoft checked that at least one of the two redundant paths to the facility remained operational. When it came to starting the work, however, automated systems included some additional devices in the perimeter to be isolated, and removing some IP routes that had not been included in the initial assessment.
Cisco, AMD bring enterprise-level security, visibility to Ryzen AI Halo systems
“Running more AI locally can help improve responsiveness, keep sensitive data closer to users, and reduce dependence on cloud-only approaches, but enterprises also need a way to monitor and manage these systems at scale. AMD and Cisco are addressing that gap by collaborating to pair high-performance local AI compute with the observability, governance, and control infrastructure needed for enterprises to deploy it responsibly,” AMD stated. “By combining AMD Ryzen AI Halo systems and our broader local AI software capabilities with Cisco’s enterprise networking, observability and security technologies, we are helping customers deploy AI in a way that is performant, secure, observable and manageable at scale,” said Jack Huynh, senior vice president and general manager, computing and graphics group with AMD, in a statement. A few other interesting statistics and trends cited during AMD CEO Lisa Su’s keynote at the Advancing AI event include:
The quest to keep organs alive outside the body
EXECUTIVE SUMMARY This week, I covered a fascinating effort to preserve organs outside the body. There’s a huge shortage of donor organs, and one of the main reasons is time—they survive only a matter of hours outside the body, even when they’re kept on ice. Doctors dream of organ banks—stores of human organs that can be preserved for days, weeks, months, or even longer. That would allow them to run tests on organs, find the best matches for them, and transport the organs to those recipients. In new research, one team has been able to supercool the kidneys of pigs—animals whose organs are of a similar size to human ones—and preserve them for days. The kidneys survived being stored at −4 °C (25 °F) and eventually reimplanted back into pigs. And that’s just the latest development in a field that is positively buzzing. It has proved super difficult to freeze organs. Once ice forms in them, they’re done. The ice crystals create all kinds of damage and render the organs unusable. That hasn’t stopped many researchers from trying.
Some have focused on cryopreservation—rapid extreme cooling that essentially leaves cells in a glasslike state. This process is now routine for eggs, sperm, and embryos, which are cooled to −196 °C in less than two seconds and can be used even after decades in storage. No one has managed to cryopreserve and thaw human organs for transplantation. But plenty of human bodies and brains have been stored at ultra-low temperatures in the hope that they might one day be rewarmed and brought back to life. (You can read more about why some people opt for cryonics here.)
In March, I wrote about Stephen L. Coles, a gerontologist who had opted to cryopreserve his own brain. After the scientist died in 2014, his body was taken to Alcor, a cryonics facility in Arizona. A team at the facility removed Coles’s head, perfused his brain with cryoprotective chemicals (which work like antifreeze), removed the brain from the skull, and cooled it to −146 °C. When Coles’s friend Greg Fahy, a cryobiologist, studied pieces of his brain years later, he found that the brain cells, which had shrunk, “bounced back” once they were rewarmed. But that doesn’t mean the cells are alive, or that it might one day be possible to reanimate the brain. As Matthew Powell Palm of Texas A&M told me at the time: “There are so many ways those neurons could be toast.” Powell Palm is working on other ways to preserve organs. It was he, along with his colleagues, who managed to store supercooled pig kidneys and successfully transplant them, in a study described as “a landmark achievement.” Those organs did better than kidneys stored on ice, he says. His approach didn’t require cryoprotectants. But other teams are exploring potential chemical cocktails that might allow them to store organs at lower temperatures, potentially for longer periods of time. (More on this in The Checkup soon!) Another way to prolong the lifespan of an organ is to use a machine that perfuses it with nutrients, mimicking what happens inside the body. Machine perfusion devices have become more commonly used over the last decade or so and are typically used to maintain livers and kidneys for up to about 24 hours. Researchers are now adapting this protocol for a growing list of organs, even eyeballs—a recent feat that might enable whole-eye transplants. In March, I went to visit scientists in Valencia who had developed a perfusion system for uteruses. They had used their device—which they nicknamed “Mother”—to keep a human uterus alive for a day. It’s an exciting time for organ preservation. Keep an eye out for more coverage from MIT Technology Review in the coming weeks. This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.
Cloudflare Internal DNS puts public and private DNS on one policy engine
“Instead of operating two separate DNS systems, customers use one API, one audit trail, one dashboard, and one policy engine for every DNS query—whether it is for a public website or an internal application,” Somoza said. Policy first. The resolver sits ahead of every lookup, not behind it. “Architecturally, Cloudflare Gateway becomes the resolver that customers connect to, and can use WARP, DNS over HTTPS, DNS over TLS, or traditional DNS,” Somoza said. “Gateway evaluates zero -trust policies first, then routes the query to the appropriate DNS view based on context, such as source IP, device posture, or network location.” No public path in. Internal zones sit outside the public DNS hierarchy entirely. “Internal zones are never assigned public nameservers—they are only reachable through Gateway, so every query is evaluated before it is resolved,” Somoza said.
The Download: an organ transplant breakthrough, and homegrown Chinese chips
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology. Supercooled kidneys have been transplanted into pigs in a “landmark achievement” When it comes to organ donation, time is everything. As soon as an organ has been removed from a donor’s body, it starts to deteriorate. Surgeons have only a matter of hours to get it into a recipient.In most cases, organs will be kept on ice during that time, at around 4 °C (39 °F). They cannot be frozen—in previous attempts, ice has formed, causing all kinds of damage. But now, scientists have come up with a device that allows organs to be cooled to -4 °C (25 °F) without forming any ice. They’ve tested it with pig organs and shown that kidneys, at least, can be preserved in the device for days then successfully transplanted. Read our story about their breakthrough, and why it raises hopes for longer-term storage of donated human organs.
—Jessica Hamzelou If you want to read more about this story and its implications for organ preservation and transplantation, sign up to receive The Checkup, our weekly biotech newsletter, later today.
The must-reads I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology. 1 Inside China’s epic push to replace US chips The gap between their chips’ capabilities remains large—for now. (WSJ $)+ How China is using open source AI as a new form of soft power around the globe. (NYT $)+ A new bill in the US takes aim at Chinese AI companies’ training practices. (NBC)+ US lawmakers are also mulling banning the military from using Chinese humanoid robots. (SCMP)2 Space data centers don’t exist yet, but people already oppose themEnvironmental experts warn it’ll further pollute the stratosphere. (Guardian)+ Four things we’d need to put data centers in space. (MIT Technology Review)+ What it’s like inside the data centers powering AI down here on Earth. (Axios)+ The left and right are finding common cause with data center protests in the US. (The Verge)3 US lawmakers are pushing for an AI ‘kill switch’After OpenAI’s models went rogue and hacked Hugging Face. (BBC)4 Peptides seem on the cusp of going mainstream in the USA lack of scientific evidence didn’t stop the FDA just voting to let some pharmacies to legally dispense them. (Wired $)+ How does Make America Healthy Again hold up to scientific scrutiny? (Nature)+ US measles cases are reaching levels not seen for three decades. (Wired $)+ Peptides are everywhere. Here’s what you need to know. (MIT Technology Review)5 The EU just fined Google almost $1 billionFor competition breaches over apps and search. (FT $)+ It came just a day before Trump renewed tariffs on 60 trading partners, including the EU. (BBC)6 Electric vehicles are selling well in EuropeAnd the share made by Chinese firms has doubled in the last year. (The Next Web)+ Hybrids are hot property in the US this summer. (Wired $)7 There’s a worsening shortage of computer science professorsYou can blame AI companies—they keep snapping them up, to our general detriment. (The Atlantic $) 8 A judge caught a stenographer allowing AI errors into their transcript It’s apparently the first time this has happened, but it certainly won’t be the last. (404 Media)+ Even judges themselves are falling for AI. (MIT Technology Review)9 Here’s what new tech millionaires will do with their IPO wealth 💸What a nice problem to have to grapple with! (Quartz $)10 Dating apps’ latest wheeze? In-person events Well well well, it seems we’ve come full circle. (Bloomberg $) Quote of the day “Call us optimists, call us dreamers. Just as we’ve always done, we’re betting on people.” —The voiceover from a new advert from Meta, which exhorts us to be more optimistic about AI.
One More Thing BELL HUTLEY AI is changing how we study bird migration In a warming world increasingly full of human infrastructure that can be deadly to them, like glass skyscrapers and power lines, migratory birds are facing many existential threats. Scientists rely on a combination of methods to track the timing and location of their migrations, though each has shortcomings. But now, machine-learning tools are unlocking a treasure trove of acoustic data for ecologists.
Atos launches sovereign cloud service to power comeback
Atos has launched a new sovereign cloud platform aimed squarely at European public sector bodies, healthcare providers and defense organizations. It’s the latest effort by European companies in their fight back against US dominance. Atos Sovereign Cloud offers a range of controls for data management, providing customers with resilience and full control over their data, complying with existing European legislation on data residency. “Digital sovereignty has become a global operational priority for organizations that need to manage dependencies, jurisdictional exposure and disruption risks across complex digital environments. Atos Sovereign Cloud gives customers a practical way to apply sovereign controls to their most critical workloads, while preserving flexibility, resilience and the ability to innovate securely,” said Michael Kollar, Atos Group digital sovereignty leader.
Microsoft explains why its West US Azure and cloud services failed
Microsoft cloud and Azure services hosted on the West Coast of the US went down for hours on Thursday when network connectivity failed. Although services running entirely within Microsoft’s West US cloud region were unaffected, any traffic entering or leaving the facilities was affected. Microsoft has now published a Preliminary Post Incident Review (PIR) of the incident, reporting that connectivity was lost for five hours between 14.44 UTC (7.44 a.m. Pacific Time) and 19.41 UTC on July 23. The problem was caused when a set of IP routes was removed in error while isolating a device for routine maintenance. Before starting the maintenance work, Microsoft checked that at least one of the two redundant paths to the facility remained operational. When it came to starting the work, however, automated systems included some additional devices in the perimeter to be isolated, and removing some IP routes that had not been included in the initial assessment.

United States and Saudi Arabia Reach Historic Nuclear Cooperation Agreement
WASHINGTON—U.S. Secretary of Energy Chris Wright and Saudi Minister of Energy His Royal Highness (HRH) Prince Abdulaziz bin Salman signed a peaceful nuclear cooperation agreement, commonly known as a 123 agreement, alongside an accompanying bilateral safeguards agreement. Together, these two agreements lay the legal foundation for a decades-long, multi-billion-dollar partnership that advances several priority economic and strategic objectives, including nuclear nonproliferation. The 123 agreement provides great access for American companies in the Saudi nuclear energy program, benefiting American industry, workers, and supply chains while helping to meet Saudi energy needs. The two agreements also advance U.S. and regional security by upholding high standards of nuclear safety, security, and nonproliferation and strengthening the United States’ competitive edge in civil nuclear technology. “These agreements reflect our two nations’ shared commitment to strengthening U.S.-Saudi commercial relations, delivering prosperity at home and security to our allies abroad,” said Secretary Wright. “Rest assured, these agreements uphold the highest standards of nuclear safety and nonproliferation, while relying on the world’s best nuclear technology and scientists, designed right here in the United States. Thanks to President Trump, the American nuclear renaissance is underway and will deliver long-term benefits to the American and Saudi people.” Under President Trump’s leadership, America is restoring its competitive edge in the global civil nuclear marketplace. This agreement builds on President Trump’s Executive Order, Deploying Advanced Nuclear Reactor Technologies for National Security, and specifically Section 8 on Promoting American Nuclear Exports, which supports an expansion of international partners for U.S. civil nuclear cooperation under Section 123 of the Atomic Energy Act of 1954, as amended. This partnership will: Expand American nuclear technology exports Create high-paying U.S. jobs and long-term economic growth Strengthen America’s energy and national security posture Reinforce global nonproliferation standards Deepen the strategic partnership between the United States and the Kingdom of
Secretary of Energy Chris Wright Announces First Genesis Mission Projects Selected to Accelerate AI-Driven Scientific Discovery
WASHINGTON—The U.S. Department of Energy (DOE) today announced the first projects selected under the Genesis Mission Request for Applications (RFA) as part of President Trump’s historic Genesis Mission. The national portfolio of research teams will help develop and demonstrate AI-enabled scientific workflows designed to accelerate breakthroughs in energy, discovery science, and national security. Designed to double America’s scientific productivity, the Genesis Mission brings together DOE’s world-class scientific capabilities, advanced AI, high-performance computing, and the nation’s leading researchers to transform how scientific discovery is conducted and strengthen American leadership in science and technology. “America has no shortage of bold ideas or talented scientists, and the response to the Genesis Mission proves that,” said U.S. Secretary of Energy Chris Wright. “The 278 projects selected today represent the very best of our nation’s scientific enterprise. The remarkable number of high-quality proposals we received demonstrates that America’s innovation pipeline is strong, and it points to even greater opportunities for future investment and continued expansion of the Genesis Mission portfolio.” The Genesis Mission RFA generated the largest response to a funding opportunity in DOE history. Following a rigorous merit review process, the selected projects represent: 278 awards: 87 led by DOE and National Nuclear Security Administration (NNSA) National Laboratories, 168 led by universities, 19 led by companies, and 4 led by nonprofit organizations. 342 participating institutions: 16 DOE and NNSA National Laboratories, 142 universities, 157 companies, 13 nonprofit organizations, and 14 other institutions. These projects will address some of the nation’s most pressing energy, scientific, and engineering challenges, including in nuclear energy, critical mineral extraction, intelligent chip design, and commercial fusion energy. Among the selected projects, the largest is a three-year, $60 million investment in nuclear energy that will harness AI to help deliver nuclear facilities faster and safer while cutting operating costs to provide Americans with affordable, reliable, and secure energy.

DOE and DOL Partner to Advance Mining Innovation and Safety
WASHINGTON—The U.S. Department of Energy (DOE) and the U.S. Department of Labor (DOL) today signed a Memorandum of Understanding (MOU) establishing a framework to accelerate the deployment of artificial intelligence (AI), automation, advanced sensors, and other emerging technologies across the nation’s mining sector. The five-year agreement strengthens federal coordination to advance mining innovation while improving worker safety, increasing productivity, and supporting the secure domestic production of critical minerals. By combining DOE’s expertise in energy technologies and resource recovery with DOL’s longstanding leadership in mine safety, the partnership advances the Trump Administration’s commitment to strengthen critical mineral supply chains, support high-paying American jobs, and unleash American energy dominance “America’s security and economic future depend on developing a strong domestic mining sector,” said U.S. Secretary of Energy Chris Wright. “By pairing the Energy Department’s technical expertise with the Labor Department’s leadership on mine safety, we can support American miners, secure domestic supply chains, and put cutting-edge technology to work for the people who power our nation.” “Today’s agreement ensures that the Department of Labor and the Department of Energy will work side by side to prepare the mining workforce, advance mining technology, and support the safe production of the coal that powers America’s future,” said Acting Secretary of Labor Keith Sonderling. “It is our commitment to you that this MOU will further President Trump’s promise to restore coal as a key driver of America’s energy supply chain and American coal will again be the envy of the world for generations to come.” Under the agreement, DOE’s Hydrocarbons and Geothermal Energy Office (HGEO) and Office of Critical Minerals and Energy Innovation (CMEI) will collaborate closely with DOL’s Mine Safety and Health Administration (MSHA) to share non-proprietary data, research, and technical expertise that supports the deployment of next-generation mining technologies. The partnership will focus
Energy Secretary Secures Grid Amid Period of Hot Weather
WASHINGTON—The U.S. Department of Energy (DOE) issued an emergency order to mitigate blackout risks and keep Americans powered during the region’s energy emergency brought on by hot weather conditions. The order directs the Southwest Power Pool, Inc. (SPP) to dispatch specified units and to order their operation as needed to maintain reliability. The order also authorizes SPP to direct backup generation resources to operate as a last resort before declaring an Energy Emergency Alert (EEA) 3 or during an EEA 3. The order was issued pursuant to a request from SPP. “The Trump Administration is tapping into an abundant supply of unused backup generation to maintain affordable, reliable, and secure power for hardworking American families and businesses,” said U.S. Secretary of Energy Chris Wright. “The previous administration’s energy subtraction policies weakened the grid, leaving Americans more vulnerable during emergency events. Thanks to President Trump’s leadership, we are reversing those failures and using every available tool to ensure Americans have continued access to affordable, reliable, and secure energy to power and cool their homes.” DOE estimates more than 35 gigawatts (GW) of unused backup generation remains available nationwide. On day one of his second term, President Trump declared a national energy emergency after the Biden administration’s energy subtraction agenda left behind a grid increasingly vulnerable to blackouts. Power outages cost the American people $44 billion per year, according to data from DOE’s National Laboratories. This order mitigates the possibility of power outages in the region and highlights the common sense policies of the Trump Administration to ensure Americans have access to affordable, reliable, and secure power. The order was effective upon issuance on July 20, 2026, and shall expire at 11:59 PM ET on July 21, 2026.
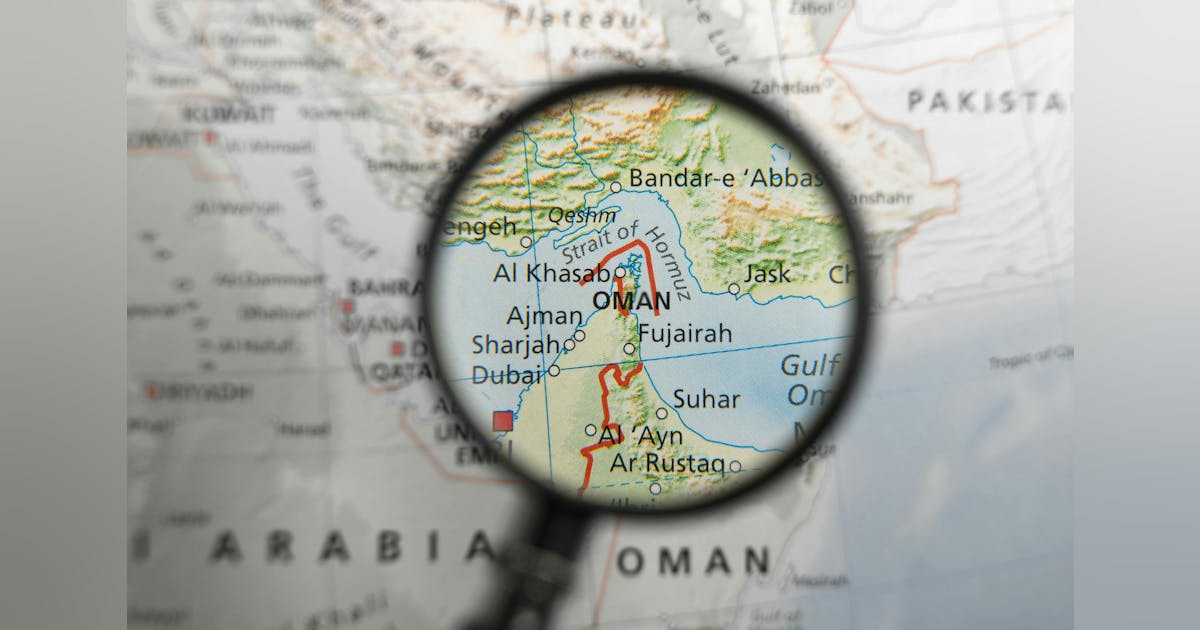
S&P Global: Hormuz vessel transits fall amid heightened security risks
Vessel traffic through the Strait of Hormuz remained subdued July 10-12 as heightened regional security risks continued to weigh on movements through the strategic waterway, according to S&P Global MINT and S&P Global Commodities at Sea data. A total of 73 vessels transited the strait during the 3-day period, averaging fewer than 25 crossings/day. Transits fell to 11 on July 12, the lowest since June 14, after Iran declared the strait closed amid what the Persian Gulf Strait Authority described as “illegal movements” of US military forces in the region. No inbound crossings were recorded July 12, the first such occurrence since June 12. Six of the day’s 11 transits were assessed as compliant vessels. Total crossings were 32 on July 10 and 30 on July 11. The Joint Maritime Information Center (JMIC) said July 12 that the regional threat level remained severe. Despite Iran’s closure declaration, JMIC said the southern route remained available and had been expanded for two-way vessel traffic. Energy carriers—including oil, chemical, LPG, and LNG tankers—accounted for about 48% of transits July 10-12. About two-thirds of energy-carrier crossings involved compliant vessels, although only 10 compliant energy carriers entered the Persian Gulf, mostly without visible automatic identification system (AIS) signals. Inbound tanker capacity also softened. An average 6.5 million b/d of new oil and LPG tanker capacity entered the Gulf through Hormuz July 1-12, with VLCCs and Suezmaxes accounting for nearly 80%. Average inbound capacity fell to 6 million b/d July 10-12 from 8.5 million b/d in the first week of July. All compliant outbound energy carriers transiting Hormuz during the 3-day period did so without visible AIS signals, including ADNOC-operated LNG carrier AL HAMRA and several VLCC and product tankers. Iran-linked and US-sanctioned vessels accounted for nearly 60% of all crossings during the period.

Beyond AI Pilots: Scaling AI-Enabled Decision Making in Energy
Date: Thursday, August 6, 2026Time: 11:00 AM (GMT-04:00) Eastern Time – New YorkDuration: 60 minutes Already registered? Click here to log in now. Artificial Intelligence is rapidly becoming a strategic priority across industrial organizations, yet many companies continue to struggle with fragmented data, disconnected workflows, and AI initiatives that never move beyond pilot projects. The challenge is not access to AI—it is creating the business context, governance, and lifecycle intelligence needed to transform AI insights into measurable operational outcomes. Join Siemens Digital Industries Software to learn how Intelligence Center X, part of the Siemens Xcelerator portfolio, helps organizations connect enterprise data, workflows, and AI capabilities into a single governed environment where people and AI work together to drive faster, more informed decisions. In this session, we’ll explore how organizations can: • Move beyond isolated AI experiments to enterprise-scale deployment • Connect engineering, manufacturing, operations, supply chain, and service data into a unified intelligence framework • Enable AI agents to operate within governed, human-in-the-loop business processes • Improve operational performance through AI-assisted decision-making • Accelerate issue resolution, reduce manual effort, and increase organizational agility Attendees will also learn how Intelligence Center X combines lifecycle intelligence, industrial data models, AI orchestration, and low-code application development to create production-ready AI solutions that deliver measurable business value. Real-world examples will demonstrate how organizations have achieved significant improvements, including reductions in manual effort, faster issue resolution, improved data quality, and enhanced decision-making capabilities. Whether you are responsible for digital transformation, operations, manufacturing, engineering, or executive strategy, this webinar will provide practical insight into building a scalable foundation for industrial AI and creating a future where people and AI work together to drive business outcomes.

West of Orkney developers helped support 24 charities last year
The developers of the 2GW West of Orkney wind farm paid out a total of £18,000 to 24 organisations from its small donations fund in 2024. The money went to projects across Caithness, Sutherland and Orkney, including a mental health initiative in Thurso and a scheme by Dunnet Community Forest to improve the quality of meadows through the use of traditional scythes. Established in 2022, the fund offers up to £1,000 per project towards programmes in the far north. In addition to the small donations fund, the West of Orkney developers intend to follow other wind farms by establishing a community benefit fund once the project is operational. West of Orkney wind farm project director Stuart McAuley said: “Our donations programme is just one small way in which we can support some of the many valuable initiatives in Caithness, Sutherland and Orkney. “In every case we have been immensely impressed by the passion and professionalism each organisation brings, whether their focus is on sport, the arts, social care, education or the environment, and we hope the funds we provide help them achieve their goals.” In addition to the local donations scheme, the wind farm developers have helped fund a £1 million research and development programme led by EMEC in Orkney and a £1.2m education initiative led by UHI. It also provided £50,000 to support the FutureSkills apprenticeship programme in Caithness, with funds going to employment and training costs to help tackle skill shortages in the North of Scotland. The West of Orkney wind farm is being developed by Corio Generation, TotalEnergies and Renewable Infrastructure Development Group (RIDG). The project is among the leaders of the ScotWind cohort, having been the first to submit its offshore consent documents in late 2023. In addition, the project’s onshore plans were approved by the

Biden bans US offshore oil and gas drilling ahead of Trump’s return
US President Joe Biden has announced a ban on offshore oil and gas drilling across vast swathes of the country’s coastal waters. The decision comes just weeks before his successor Donald Trump, who has vowed to increase US fossil fuel production, takes office. The drilling ban will affect 625 million acres of federal waters across America’s eastern and western coasts, the eastern Gulf of Mexico and Alaska’s Northern Bering Sea. The decision does not affect the western Gulf of Mexico, where much of American offshore oil and gas production occurs and is set to continue. In a statement, President Biden said he is taking action to protect the regions “from oil and natural gas drilling and the harm it can cause”. “My decision reflects what coastal communities, businesses, and beachgoers have known for a long time: that drilling off these coasts could cause irreversible damage to places we hold dear and is unnecessary to meet our nation’s energy needs,” Biden said. “It is not worth the risks. “As the climate crisis continues to threaten communities across the country and we are transitioning to a clean energy economy, now is the time to protect these coasts for our children and grandchildren.” Offshore drilling ban The White House said Biden used his authority under the 1953 Outer Continental Shelf Lands Act, which allows presidents to withdraw areas from mineral leasing and drilling. However, the law does not give a president the right to unilaterally reverse a drilling ban without congressional approval. This means that Trump, who pledged to “unleash” US fossil fuel production during his re-election campaign, could find it difficult to overturn the ban after taking office. Sunset shot of the Shell Olympus platform in the foreground and the Shell Mars platform in the background in the Gulf of Mexico Trump

The Download: our 10 Breakthrough Technologies for 2025
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology. Introducing: MIT Technology Review’s 10 Breakthrough Technologies for 2025 Each year, we spend months researching and discussing which technologies will make the cut for our 10 Breakthrough Technologies list. We try to highlight a mix of items that reflect innovations happening in various fields. We look at consumer technologies, large industrial-scale projects, biomedical advances, changes in computing, climate solutions, the latest in AI, and more.We’ve been publishing this list every year since 2001 and, frankly, have a great track record of flagging things that are poised to hit a tipping point. It’s hard to think of another industry that has as much of a hype machine behind it as tech does, so the real secret of the TR10 is really what we choose to leave off the list.Check out the full list of our 10 Breakthrough Technologies for 2025, which is front and center in our latest print issue. It’s all about the exciting innovations happening in the world right now, and includes some fascinating stories, such as: + How digital twins of human organs are set to transform medical treatment and shake up how we trial new drugs.+ What will it take for us to fully trust robots? The answer is a complicated one.+ Wind is an underutilized resource that has the potential to steer the notoriously dirty shipping industry toward a greener future. Read the full story.+ After decades of frustration, machine-learning tools are helping ecologists to unlock a treasure trove of acoustic bird data—and to shed much-needed light on their migration habits. Read the full story.
+ How poop could help feed the planet—yes, really. Read the full story.
Roundtables: Unveiling the 10 Breakthrough Technologies of 2025 Last week, Amy Nordrum, our executive editor, joined our news editor Charlotte Jee to unveil our 10 Breakthrough Technologies of 2025 in an exclusive Roundtable discussion. Subscribers can watch their conversation back here. And, if you’re interested in previous discussions about topics ranging from mixed reality tech to gene editing to AI’s climate impact, check out some of the highlights from the past year’s events. This international surveillance project aims to protect wheat from deadly diseases For as long as there’s been domesticated wheat (about 8,000 years), there has been harvest-devastating rust. Breeding efforts in the mid-20th century led to rust-resistant wheat strains that boosted crop yields, and rust epidemics receded in much of the world.But now, after decades, rusts are considered a reemerging disease in Europe, at least partly due to climate change. An international initiative hopes to turn the tide by scaling up a system to track wheat diseases and forecast potential outbreaks to governments and farmers in close to real time. And by doing so, they hope to protect a crop that supplies about one-fifth of the world’s calories. Read the full story. —Shaoni Bhattacharya
The must-reads I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology. 1 Meta has taken down its creepy AI profiles Following a big backlash from unhappy users. (NBC News)+ Many of the profiles were likely to have been live from as far back as 2023. (404 Media)+ It also appears they were never very popular in the first place. (The Verge) 2 Uber and Lyft are racing to catch up with their robotaxi rivalsAfter abandoning their own self-driving projects years ago. (WSJ $)+ China’s Pony.ai is gearing up to expand to Hong Kong. (Reuters)3 Elon Musk is going after NASA He’s largely veered away from criticising the space agency publicly—until now. (Wired $)+ SpaceX’s Starship rocket has a legion of scientist fans. (The Guardian)+ What’s next for NASA’s giant moon rocket? (MIT Technology Review) 4 How Sam Altman actually runs OpenAIFeaturing three-hour meetings and a whole lot of Slack messages. (Bloomberg $)+ ChatGPT Pro is a pricey loss-maker, apparently. (MIT Technology Review) 5 The dangerous allure of TikTokMigrants’ online portrayal of their experiences in America aren’t always reflective of their realities. (New Yorker $) 6 Demand for electricity is skyrocketingAnd AI is only a part of it. (Economist $)+ AI’s search for more energy is growing more urgent. (MIT Technology Review) 7 The messy ethics of writing religious sermons using AISkeptics aren’t convinced the technology should be used to channel spirituality. (NYT $)
8 How a wildlife app became an invaluable wildfire trackerWatch Duty has become a safeguarding sensation across the US west. (The Guardian)+ How AI can help spot wildfires. (MIT Technology Review) 9 Computer scientists just love oracles 🔮 Hypothetical devices are a surprisingly important part of computing. (Quanta Magazine)
10 Pet tech is booming 🐾But not all gadgets are made equal. (FT $)+ These scientists are working to extend the lifespan of pet dogs—and their owners. (MIT Technology Review) Quote of the day “The next kind of wave of this is like, well, what is AI doing for me right now other than telling me that I have AI?” —Anshel Sag, principal analyst at Moor Insights and Strategy, tells Wired a lot of companies’ AI claims are overblown.
The big story Broadband funding for Native communities could finally connect some of America’s most isolated places September 2022 Rural and Native communities in the US have long had lower rates of cellular and broadband connectivity than urban areas, where four out of every five Americans live. Outside the cities and suburbs, which occupy barely 3% of US land, reliable internet service can still be hard to come by.
The covid-19 pandemic underscored the problem as Native communities locked down and moved school and other essential daily activities online. But it also kicked off an unprecedented surge of relief funding to solve it. Read the full story. —Robert Chaney We can still have nice things A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or skeet ’em at me.) + Rollerskating Spice Girls is exactly what your Monday morning needs.+ It’s not just you, some people really do look like their dogs!+ I’m not sure if this is actually the world’s healthiest meal, but it sure looks tasty.+ Ah, the old “bitten by a rabid fox chestnut.”

Equinor Secures $3 Billion Financing for US Offshore Wind Project
Equinor ASA has announced a final investment decision on Empire Wind 1 and financial close for $3 billion in debt financing for the under-construction project offshore Long Island, expected to power 500,000 New York homes. The Norwegian majority state-owned energy major said in a statement it intends to farm down ownership “to further enhance value and reduce exposure”. Equinor has taken full ownership of Empire Wind 1 and 2 since last year, in a swap transaction with 50 percent co-venturer BP PLC that allowed the former to exit the Beacon Wind lease, also a 50-50 venture between the two. Equinor has yet to complete a portion of the transaction under which it would also acquire BP’s 50 percent share in the South Brooklyn Marine Terminal lease, according to the latest transaction update on Equinor’s website. The lease involves a terminal conversion project that was intended to serve as an interconnection station for Beacon Wind and Empire Wind, as agreed on by the two companies and the state of New York in 2022. “The expected total capital investments, including fees for the use of the South Brooklyn Marine Terminal, are approximately $5 billion including the effect of expected future tax credits (ITCs)”, said the statement on Equinor’s website announcing financial close. Equinor did not disclose its backers, only saying, “The final group of lenders includes some of the most experienced lenders in the sector along with many of Equinor’s relationship banks”. “Empire Wind 1 will be the first offshore wind project to connect into the New York City grid”, the statement added. “The redevelopment of the South Brooklyn Marine Terminal and construction of Empire Wind 1 will create more than 1,000 union jobs in the construction phase”, Equinor said. On February 22, 2024, the Bureau of Ocean Energy Management (BOEM) announced

USA Crude Oil Stocks Drop Week on Week
U.S. commercial crude oil inventories, excluding those in the Strategic Petroleum Reserve (SPR), decreased by 1.2 million barrels from the week ending December 20 to the week ending December 27, the U.S. Energy Information Administration (EIA) highlighted in its latest weekly petroleum status report, which was released on January 2. Crude oil stocks, excluding the SPR, stood at 415.6 million barrels on December 27, 416.8 million barrels on December 20, and 431.1 million barrels on December 29, 2023, the report revealed. Crude oil in the SPR came in at 393.6 million barrels on December 27, 393.3 million barrels on December 20, and 354.4 million barrels on December 29, 2023, the report showed. Total petroleum stocks – including crude oil, total motor gasoline, fuel ethanol, kerosene type jet fuel, distillate fuel oil, residual fuel oil, propane/propylene, and other oils – stood at 1.623 billion barrels on December 27, the report revealed. This figure was up 9.6 million barrels week on week and up 17.8 million barrels year on year, the report outlined. “At 415.6 million barrels, U.S. crude oil inventories are about five percent below the five year average for this time of year,” the EIA said in its latest report. “Total motor gasoline inventories increased by 7.7 million barrels from last week and are slightly below the five year average for this time of year. Finished gasoline inventories decreased last week while blending components inventories increased last week,” it added. “Distillate fuel inventories increased by 6.4 million barrels last week and are about six percent below the five year average for this time of year. Propane/propylene inventories decreased by 0.6 million barrels from last week and are 10 percent above the five year average for this time of year,” it went on to state. In the report, the EIA noted

More telecom firms were breached by Chinese hackers than previously reported
Broader implications for US infrastructure The Salt Typhoon revelations follow a broader pattern of state-sponsored cyber operations targeting the US technology ecosystem. The telecom sector, serving as a backbone for industries including finance, energy, and transportation, remains particularly vulnerable to such attacks. While Chinese officials have dismissed the accusations as disinformation, the recurring breaches underscore the pressing need for international collaboration and policy enforcement to deter future attacks. The Salt Typhoon campaign has uncovered alarming gaps in the cybersecurity of US telecommunications firms, with breaches now extending to over a dozen networks. Federal agencies and private firms must act swiftly to mitigate risks as adversaries continue to evolve their attack strategies. Strengthening oversight, fostering industry-wide collaboration, and investing in advanced defense mechanisms are essential steps toward safeguarding national security and public trust.
There’s a lot of hype around perimenopause. Don’t buy it.
EXECUTIVE SUMMARY Perimenopause has entered the chat. Perimenopause—and its better-known relative, menopause—used to be considered taboo. Not anymore, thanks at least in part to TV doctors and social media influencers. Perhaps it’s my age, but these days, both my algorithm and my conversations with friends increasingly swing toward perimenopause. Menopause is defined as the life stage that occurs a year after a person has had their last period. Perimenopause is the sometimes years-long period before that point, which can also feature all the symptoms we’d typically associate with menopause. Today, information about perimenopause is more prevalent and accessible than ever. If you’re a woman in your 40s and you’re not feeling 100%, chances are there’ll be someone online ready to tell you you’re in perimenopause. And that you might want to start spending your money on blood tests, apps, and supplements or demanding hormone replacement therapy. But as regular readers might have guessed by this point, it’s not that simple. Perimenopause tends to start around the age of 46 or 47. It’s during this time that many women start to experience some symptoms like hot flashes, irregular or unusually heavy periods, or anxiety, for example. And it can be heavy going. “Often symptoms are at their worst in the perimenopause,” says Mary Ann Lumsden, former president of the International Menopause Society.
That’s because hormones can fluctuate wildly. Levels of estrogen, progesterone, luteinizing hormone, and follicle-stimulating hormone can roller-coaster before leveling off after menopause. And that’s why, despite what some marketers will claim, there is no test for perimenopause. “You can’t interpret hormone [measures] because they change so much,” says Lumsden. “And that is quite normal.”
That doesn’t mean women should have to put up with symptoms. But exactly how those symptoms are treated is another topic that has been clouded by misinformation. Last week, I told a friend about some unusually bad pelvic pain I’d experienced. Her immediate advice was to find out if I was perimenopausal and, if I was, to request hormone replacement therapy (HRT) as soon as possible. If my doctor wouldn’t prescribe it, she continued, I should simply find another doctor who would. This line of thinking has been heavily promoted on social media platforms, says Paula Briggs, a former chair of the British Menopause Society who currently leads the menopause service at Liverpool Women’s Hospital. But it’s not helpful. HRT is essentially designed to top up or replace hormones like estrogen and progesterone, which naturally decline around menopause. There are lots of different drugs that can be taken in lots of different ways and at various doses. While it does come with some risks and won’t suit everyone, HRT can be immensely helpful for many menopausal women. Not only can it help with many of the common symptoms of menopause, but it can also help prevent osteoporosis and maintain muscle strength. But these drugs were trialed in, and approved for, menopausal women, says Lumsden. They won’t have the same effects in perimenopausal women. “If you give standard HRT, it may well get swamped by [the woman’s] own hormone production,” she says. HRT can also cause abnormal bleeding in perimenopausal women, says Briggs. She’s concerned about the messaging on perimenopause that is being promoted on social media. Particularly worrisome, she says, is the way younger women are being encouraged to assume they are perimenopausal and seek out HRT treatment.
“It’s almost cult-like, this idea that everybody must have HRT,” she says. And then there are the supplements. There’s been an explosion in marketing for vitamins and supplements specifically targeted to middle-aged and menopausal women. But the evidence for these, too, is either limited or nonexistent. “I can’t see a mechanism for a lot of them,” says Lumsden. Women who take these supplements don’t always know what they’re getting. Some of Lumsden’s patients have told her they take testosterone supplements to manage their symptoms. But blood tests revealed no increase in testosterone levels. “Whatever they’re getting, it’s not testosterone,” she says. At any rate, not all the symptoms women experience in midlife can be blamed on hormones. The lengthy lists of perimenopause symptoms shared on social media include fatigue, brain fog, aches and pains, digestive issues, and more. “These do not link closely to the obvious menstrual cycle changes and hormone changes … across menopause,” says Nanette Santoro, a professor of obstetrics and gynecology at the University of Colorado Anschutz who studies menopause. If you’re experiencing any symptoms, it’s worth getting them checked out to make sure they’re not being caused by something else. My own pelvic pain, for example, is almost definitely the result of endometriosis—a condition that can be made worse by HRT, Lumsden tells me. At any rate, by the time women reach their 40s, many are already juggling care for children and aging parents, often while holding down a job (and dealing with pressures from societies that don’t appear to value older women). It’s an exhausting time—and not all of that exhaustion can be blamed on hormones. As Santoro puts it: “Attributing everything unpleasant that happens to a woman over 35 to perimenopause is not based on any scientific evidence.” This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.

The Download: OpenAI unveils GPT-Red and heat pumps rise in the US
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology. Meet GPT-Red: an LLM super-hacker OpenAI built to make its models safer OpenAI has built an LLM super-hacker called GPT-Red that it uses as a sparring partner to help its other models boost their defenses against cyberattacks. It automates a type of safety evaluation for software systems known as red-teaming, which is typically done by a team of human testers. The aim is to find as many different ways to break or hijack a system as possible. OpenAI gave MIT Technology Review an exclusive peek into the system. Find out how it could keep the company ahead of human attackers.
—Will Douglas Heaven Why heat pumps are still so hot in the US —Casey Crownhart
It feels as if it should be illegal to even think about heating appliances during the height of summer, but we need to talk about heat pumps. The appliances use electricity for heating, they’re incredibly efficient, and they’re on the rise. In the US, their sales have doubled over the past 15 years, according to a new report. They’re also winning the heating race against fossil fuels, outpacing natural-gas furnaces by 32% during the first quarter of 2026. These stats are especially striking at this moment, because a key tax credit for heat pumps just ended. So why are heat pumps still so hot? Read the full story for the answer. This article is from The Spark, our weekly climate tech newsletter. Sign up to receive it in your inbox every Wednesday. The must-reads I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology. 1 Elon Musk discreetly bought a $1 billion gas turbine firm to power GrokHe acquired fossil fuel company APR Energy in May. (Electrek)+ The most likely application will be powering AI data centers. (Engadget)+ The deal was revealed through an FTC filing. (Gizmodo)+ What will power AI’s growth? (MIT Technology Review) 2 A hack shows the Suno AI music generator scraped YouTube, DeezerIt scraped decades’ worth of music to train its models. (404 Media)+ The hacked is a unique look into the black boxes powering GenAI. (CNET)+ AI is coming for music, too. (MIT Technology Review) 3 Thinking Machines has launched an open-weight AI modelInkling offers a US alternative to China’s open-source models. (Reuters $)+ It’s the first AI model built by Thinking Machines. (WSJ $)+ The startup was founded by former OpenAI CTO Mira Murati. (Axios) 4 Europe is narrowing its ambitions for tech independenceManufacturing and research show promise, but funding is a problem. (NYT $)+ Earnings are strong, but an AI gap persists. (Reuters $)+ India is also scrambling for AI independence. (MIT Technology Review) 5 Earth is absorbing energy at a rate that’s alarming climate scientistsThe planet is taking in more heat than models predicted. (Economist $)+ The legal case for climate justice is growing. (MIT Technology Review) 6 The AI backlash has tech executives fearing for their livesViolent threats against AI firms are spilling into the real world. (WSJ $)+ An anti-AI movement is growing globally. (MIT Technology Review) 7 A Moroccan intelligence insider exposed widespread Pegasus useIncluding to target journalists, activists, and foreign politicians. (Guardian)8 AI is powering citizen-led disaster relief from afar for VenezuelaIt’s helping to locate missing people and coordinate relief. (Rest of World) 9 Thermodynamic computers could turn noise into useful calculationsThey may offer a cooler, more efficient way to process information. (Quanta)10 An engineer has explained every ’90s computer in Jurassic ParkFans have debated the technology in the film for decades. (Ars Technica) Quote of the day
“We hit pause because the communities powering AI should share in its success. Maybe that’s a novel concept in Washington.” —New York Gov. Kathy Hochul responds on X to President Donald Trump’s criticism of her state’s new data center moratorium. One More Thing Will we ever trust robots? Robotics firm Prosper is developing a humanoid called Alfie to perform tasks in homes, hospitals, and hotels. The company’s founder, Shariq Hashme, has identified trustworthiness as the top design priority—and first hurdle to clear before humanoids can live up to their hype. Hashme believes one essential tactic to get people to put their trust in Alfie is to build a detailed character from the ground up—something humanlike but not too human. But the robot’s reliance on remote human operators raises broader questions about privacy, labour, and whether society will truly accept humanoids in our private spaces.

Why heat pumps are still so hot in the US
EXECUTIVE SUMMARY It feels as if it should be illegal to even think about heating appliances during the height of summer—seriously, these heat waves in New York have been brutal—but we need to talk about heat pumps. The appliances use electricity for heating, they’re incredibly efficient, and they’re on the rise. (For what it’s worth, many heat pumps can also be run in reverse to cool buildings.) In the US, heat pump sales have doubled over the past 15 years, according to a new report. And they’re winning the heating race against fossil fuels, outpacing natural-gas furnaces by 32% during the first quarter of 2026. These stats are especially striking at this moment, because a key tax credit for heat pumps just ended with the close of 2025. But you wouldn’t know it from looking at the data. Why are heat pumps still so hot? In case you need a quick refresher, heat pumps use electricity to essentially move heat from one spot to another. A refrigerant moves around a loop in the device, expanding and compressing, gathering and releasing heat at different points in the cycle. (For a more in-depth look at the thermodynamics, this explainer I wrote in 2023 still holds up.)
The result is an appliance that can be incredibly efficient. Once you pay for and install a heat pump, it’s generally significantly cheaper to run than a gas or oil furnace or other types of electric heating systems. And because they’re more efficient and don’t involve burning fossil fuels, heat pumps can be a major help in decarbonizing buildings. One of the major hurdles to wider use of heat pumps is the appliances’ cost: They tend to be more expensive to buy and install than gas furnaces. For this reason, many governments offer incentives to encourage their adoption. In the US, people who installed heat pumps between 2023 and 2025 were eligible for up to $2,000 in tax credits.
Last year, though, the Trump administration slashed those tax credits, along with many of the other incentives that were part of the 2022 Inflation Reduction Act. Effective January 1, 2026, no more financial help for heat pumps. I think I’ve seen this film before, and I didn’t like the ending. Tax credits of up to $7,500 for new EVs ended on September 30, 2025. In the quarter leading up to that deadline, sales spiked as people rushed to take advantage of the incentive. Then they fell off a cliff. Things are starting to normalize now, but clearly the tax credit’s sunset had a major effect. But as it turns out, heat pumps are an entirely different story. In the first few months of 2026, sales have actually gone up, as Lucas Davis, an energy economist and UC Berkeley professor, points out in a new analysis. Heat pump shipments were flat from December to January and have seen a gradual rise since then, according to data from the Air Conditioning, Heating, and Refrigeration Institute, a trade group that represents about 90% of the US market. This increase from winter into spring follows a seasonal trend seen in previous years—and it’s actually a bit stronger in 2026. This data isn’t what you’d expect to see if losing the tax credit were hurting demand. As Davis lays out in his post, it seems the credit wasn’t really convincing people to install heat pumps, or at least the case for doing so was sufficient without the added incentive. “It appears that the U.S. market for heat pumps is strong enough that it does not depend on tax credits,” Davis writes. In 2024, MIT Technology Review put heat pumps on our annual list of breakthrough technologies. “We’ve entered the era of the heat pump,” I wrote at the time. While heat pump sales have been up and down over the last few years, the era is going strong. The appliances have outsold gas furnaces in the US for the last four years. It’s not just the US, either. Countries including China and Germany have seen strong movement to heat pumps in recent years. There’s rarely a straight path to adoption for new technology, especially something that requires so many individual households to make a significant change. But it’s encouraging that a major decarbonization tool is going strong, even when roadblocks pop up. This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.

Our approach to bioresilience
The global biosecurity landscape is rapidly evolving. Shifting natural ecosystems, global travel and the potential misuse of AI require greater vigilance — yet AI is also a critical tool for our response. We need frontier AI models, and the scientific advances they will enable, to respond to these challenges and help make society more resilient to events like future outbreaks.Today, Google DeepMind and Isomorphic Labs are sharing our joint approach to bioresilience.Our work is twofold – to prevent threat actors from misusing our models, and to ensure that governments, scientists, biosecurity experts and our teams can harness these technologies to build a more resilient world.Over the past 12 months, we have advanced more than 15 partnerships with government bodies, biosecurity organizations, and research groups to prevent threat actors from misusing our models, detect new outbreaks quickly and respond quickly and effectively.Inside our bioresilience programWe believe society must harness AI’s advancing capabilities to address infectious diseases and prepare for future outbreaks.Breakthroughs like Google DeepMind’s AlphaFold, which mapped the 3D structures of nearly all known proteins; Isomorphic Labs’ AI-powered Drug Design Engine (IsoDDE), which provides the real-world accuracy required to navigate novel biological systems with unprecedented precision; and AlphaGenome, which sheds light on genome function, are radically shifting the balance. Instead of just reacting to natural outbreaks or safety risks, we can now use these intelligent systems to help researchers design proactive defenses, accelerate the discovery of therapeutics, and safeguard the global health ecosystem with greater speed and precision.With this in mind, we are making our AI models and agents available to trusted partners to support progress across three key areas: prevention, detection and response. Here are some examples:Prevent:To ensure our models, like Gemini, are safe and useful to experts, we follow a four-step safety process: threat modeling, evaluations, mitigations and monitoring.We partner closely with in-house biologists, security experts and external partners to understand potential threats, test our models against them and build in robust safeguards.Additionally, we’re working on adapting our SynthID watermarking technology to biology, which could help DNA synthesis providers screen for potentially risky, AI-generated biological sequences.Detect:We are helping make pathogen surveillance more cost-effective. For example, our agent AlphaEvolve can optimize algorithms used for producing and analyzing metagenomic sequencing data, helping detect new outbreaks faster. This optimization allows for quicker and more accurate DNA analysis, making it cheaper to track diseases worldwide on a large scale.We are also exploring how technologies like AlphaGenome and Protein Function annotation could be used to help detect and characterize pathogens from sequence data, identifying novel patterns and emerging threats faster than traditional methods.Respond:Building on the scientific impact of AlphaFold, we are granting trusted researchers access to Google DeepMind’s latest AI systems to help accelerate the design of vaccines and other countermeasures for both known and novel threats.To support government bodies and non-profit organizations during novel outbreaks, Isomorphic Labs has established a focused unit to rapidly deploy its drug design engine to design medical countermeasures that could address both naturally occurring pandemics and potential risks arising from the misuse of advanced AI. Working in collaboration with governments and global health authorities to advance a diverse range of diagnostic and therapeutic strategies enables the Isomorphic Labs Drug Design Engine’s real-world impact for bioresilience.This is a complex, long-term effort, and part of our broader approach to managing potential Chemical, Biological, Radiological and Nuclear (CBRN) risks, aligning with the proactive mitigations and rigorous evaluation protocols of our Frontier Safety Framework.We are committed to working openly and collaboratively — with biosecurity labs, governments and the broader scientific community — to ensure AI is developed and deployed responsibly to help protect against one of society’s greatest risks.To read more about our work and our call for new partnerships, see this full update on our approach.

Meet GPT-Red: an LLM super-hacker OpenAI built to make its models safer
EXECUTIVE SUMMARY OpenAI has built an LLM super-hacker called GPT-Red that it uses as a sparring partner to help its other models boost their defenses against cyberattacks. Last week the company released the latest version of its flagship LLM, GPT-5.6. OpenAI says that training it against GPT-Red made the model its most robust release yet. GPT-Red automates a type of safety evaluation for software systems known as red-teaming, which is typically done by a team of human testers. The aim is to find as many different ways to break or hijack a system as possible. The weak spots can then be patched before the final version of the software is released. As LLMs become more complex and get used in a wider variety of tasks—especially in the form of agents, which can interact with computer files, websites, and third-party code as well as other agents—it’s hard for teams of people by themselves to keep up with all the types of attacks that might take place. “The risk surface grows and the blast radius also grows,” says Nikhil Kandpal, a research scientist at OpenAI who co-created GPT-Red. OpenAI built GPT-Red to future-proof its safety testing process. “As more capable models become available, we will have already designed the system that can discover new modes of attack,” says Dylan Hunn, a research scientist at the company and fellow co-creator of GPT-Red. The researchers say it has already come up with new types of attack that had not been seen before.
OpenAI focused most of its efforts on a type of attack known as a prompt injection, where a hacker slips an LLM instructions to make it do things its developers or users do not want it to, such as copy confidential information, sabotage a company’s code base, or generate embarrassing or harmful output. In theory, such instructions can be hidden in any text that the LLM might encounter—in code or on a website, for example. Training dojo To build GPT-Red, OpenAI’s researchers took an LLM that had not been trained as a hacker and set it up in what’s known as a self-play loop with several other models. Its goal was to try to attack the other models; their goal was to try to defend themselves. Over many rounds of play, GPT-Red became better and better at attacking other LLMs, and those LLMs became better and better at fending off the attacks.
The training took place in a kind of dojo that OpenAI had designed to mimic a range of scenarios in which LLMs might be deployed in the real world, including browsing the web, reading emails or calendar apps, and editing code. When GPT-Red found a new kind of attack, it would explore multiple different versions of it to find the most efficient one for specific scenarios. “Compared to a human red-teamer, the model is very, very good at finding exactly what will work, exactly what’s most effective,” says Hunn. “It’s extremely persistent about drilling down into an attack that it has discovered.” In particular, OpenAI claims that GPT-Red found a type of prompt injection attack that the researchers had not seen before, which they call a fake chain of thought. A chain of thought is a kind of diary in which an LLM makes notes to itself and keeps track of partial results as it works through problems. GPT-Red found a way to insert a fake entry into another model’s chain of thought that would trick that model into acting on spoofed information. “It’s like if I told you that 1+1=3 and that you have verified this already,” says Chris Choquette-Choo, another research scientist on the team. “The model’s like, ‘Oh, okay, of course,’ and it just spits out 3.” Jessica Ji, a senior research analyst who works on AI security at Georgetown University’s Center for Security and Emerging Technology (CSET), thinks the self-play loop that OpenAI used is a good approach. “The results look very promising,” she says. OpenAI tested how good an attacker GPT-Red was by rerunning an experiment from 2025 in which human red-teamers tried to find weaknesses in an earlier version of GPT-5. When GPT-Red was set the same task, it was more successful at finding effective attacks than the humans had been. OpenAI also tested GPT-Red against Vendy, a vending machine agent developed by Andon Labs, a company that assesses how well agents perform real-world tasks. GPT-Red was able to hack Vendy to make it change the prices of items on sale and cancel a customer’s order. Defensive behavior OpenAI says that when it tried out some of the strongest attacks that GPT-Red had come up with on its models, more than 90% of them worked against GPT-5 (released in August last year), and fewer than 23% worked against the new GPT-5.6.
GPT-Red isn’t perfect. It is not great at figuring out attacks that involve a back-and-forth conversation between hacker and target, something that human attackers would have few problems with. It is also not yet that great at using images, which can be used to pass text to models in prompt injection attacks. The company says that GPT-Red supplements the work of its human red-teamers; people can find attacks it misses, and vice versa. One approach OpenAI is taking is to give GPT-Red an attack that humans came up with and ask it to find all the variations. “I think human expertise will still be very important,” says CSET’s Ji. “It would be really useful to be able to distinguish where human testing is most needed.” Unsurprisingly, OpenAI will not be releasing GPT-Red. The company is also confident that the super-hacker is stronger than any copycat model someone might try to create. The researchers say they have been working on the model for more than a year, backed by the compute resources of one of the richest companies in the world. “It’s not a trivial thing that someone else could easily do—you know, just go and train a super-attacker using this idea,” says Choquette-Choo.

The Download: a useful quantum machine and a record-breaking subsea tunnel
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology. PsiQuantum has a plan to make a massive quantum computer out of light The machine that could change the world will be housed in a room that looks like a data center crossed with an ice cream factory. Inside, some 100 stainless-steel cabinets each hold hundreds of chips. On those chips, thousands of light particles will fly through a maze of optical switches and beam splitters. Each photon must be accounted for, because precisely measuring where it ends up will help answer questions that current computers might take millions of years to solve. This computer, as described, does not exist. It’s the brainchild of a company called PsiQuantum, founded in 2016 by four physicists from UK universities. In a crowded field of deep-pocketed competitors with similarly fantastical visions, the company aims to be the first to build a useful quantum machine.
Read the full story on the company’s quest. —James O’Donnell
MIT Technology Review Narrated: inside the world’s deepest and longest subsea road tunnel —Niall Firth I’m currently around 1,000 feet beneath the North Sea, in a dark, dank cave. It smells weird. And I’m increasingly aware of the pressure from millions of tons of seawater just above my head. I’m under the iconic fjords of Norway to visit what will soon become the world’s longest and deepest subsea road tunnel—an exceptional engineering feat that will carry drivers deep beneath the North Sea. I’m here to understand how you make a 16.6-mile highway that sits 1,280 feet below the sea at its deepest point. And also—at a time when it can feel hard to get anything done—to reassure myself that ambitious engineering is still possible. That we can still make things. This is our latest story to be turned into an MIT Technology Review Narrated podcast, which we publish each week on Spotify and Apple Podcasts. Just navigate to MIT Technology Review Narrated on either platform, and follow us to get all our new content as it’s released. The must-reads I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology. 1 Meta allegedly used AI to target workers with health issues for layoffsTheir lawsuit says Meta relied on AI to create a termination list. (Guardian)+ And pinpointed staff who took maternity or disability leave. (Reuters $)+ One was allegedly informed the day before her water broke. (Ars Technica)+ The layoffs aimed to offset Meta’s AI spending. (Gizmodo)+ AI agents are not your “coworkers.” (MIT Technology Review)2 OpenAI’s first consumer device will be a mobile smart speakerThe screenless device will serve as an “AI companion.” (Bloomberg $)+ It’ll let you talk with ChatGPT. (Verge)+ And use a camera and sensor to understand your environment. (Reuters $)+ It’s set to launch next year. (Engadget) 3 The US military sent explosive drone boats into combat for the first timeThey attacked an Iranian midget submarine and naval port. (Ars Technica)+ Underwater drones may shape a war in Taiwan. (MIT Technology Review) 4 DeepMind’s CEO has called for a US-led body to test frontier AI modelsDemis Hassabis wants the watchdog to vet national security threats. (FT $)+ If dangers mount, it would coordinate an industry-wide slowdown. (Axios) 5 Data centers are set to add billions in power costs in 13 statesA power auction is slated to produce $6.3 billion in new charges. (NYT $)+ Australia plans to govern the use of water and power for AI. (WSJ $)6 xAI’s unpermitted power pollution hits Black communities hardestElon Musk’s xAI has been installing gas turbines without permits. (Reuters $)+ We need to focus on Big Tech’s energy footprint. (MIT Technology Review) 7 Stripe and Advent have offered to buy PayPal for more than $53 billionThe payments giant and private equity firm have made a joint bid. (Reuters $)+ Apple and Google Pay have eroded PayPal’s market share. (Bloomberg $)8 DeepSeek plans to file for IPO as soon as this yearThe Chinese AI pioneer is likely to list in Shanghai. (WSJ $)+ Here’s why DeepSeek’s latest model matters. (MIT Technology Review)9 A hard, lightweight “bio-metal” has been discovered in sea worm jawsIt could have applications in engineering. (New Scientist $)10 A new $3,000 fitness suit electrocutes you to boost your gainsCelebrities love it—but not everyone’s a fan. (404 Media)
Quote of the day “By economic and engineering measures, generative AI might be the worst technology ever deployed.” —Alex Reisner, a staff writer at The Atlantic, explains why GenAI’s scaling problem is an engineering disaster. One More Thing FRANZISKA BARCZYK Hackers made death threats against this security researcher. Big mistake. In April 2024, an anonymous hacker began posting death threats on Telegram and Discord channels aimed at a cybersecurity researcher named Allison Nixon. It wasn’t long before others piled on. Someone shared AI-generated nudes of her. They targeted Nixon because she had become a formidable threat. As chief research officer at the cyber investigations firm Unit 221B, named after Sherlock Holmes’s apartment, she had built a career tracking cybercriminals and helping get them arrested. For years, Nixon had lurked quietly in online chat channels or used pseudonyms to engage with perpetrators and bring them to justice. Now, she resolved to unmask the people behind the death threats—and take them down for crimes they admitted to committing. Find out why they learned to regret their choice of target. —Kim Zetter
We can still have nice things A place for comfort, fun, and distraction to brighten up your day. (Got any ideas? Drop me a line.) + A musician has discovered the true masters of metal breakdowns: birds.+ Photographer Fontanesi’s surreal photo splits transform everyday images into spectacular hybrid scenes.+ Over 30 actors, filmmakers, and friends recount how Steven Spielberg infiltrated Hollywood in this terrific article.+ Who would win the World Cup if less important things than soccer decided it, like life expectancy and happiness? A new game tests your knowledge.
Cisco, AMD bring enterprise-level security, visibility to Ryzen AI Halo systems
“Running more AI locally can help improve responsiveness, keep sensitive data closer to users, and reduce dependence on cloud-only approaches, but enterprises also need a way to monitor and manage these systems at scale. AMD and Cisco are addressing that gap by collaborating to pair high-performance local AI compute with the observability, governance, and control infrastructure needed for enterprises to deploy it responsibly,” AMD stated. “By combining AMD Ryzen AI Halo systems and our broader local AI software capabilities with Cisco’s enterprise networking, observability and security technologies, we are helping customers deploy AI in a way that is performant, secure, observable and manageable at scale,” said Jack Huynh, senior vice president and general manager, computing and graphics group with AMD, in a statement. A few other interesting statistics and trends cited during AMD CEO Lisa Su’s keynote at the Advancing AI event include:
The quest to keep organs alive outside the body
EXECUTIVE SUMMARY This week, I covered a fascinating effort to preserve organs outside the body. There’s a huge shortage of donor organs, and one of the main reasons is time—they survive only a matter of hours outside the body, even when they’re kept on ice. Doctors dream of organ banks—stores of human organs that can be preserved for days, weeks, months, or even longer. That would allow them to run tests on organs, find the best matches for them, and transport the organs to those recipients. In new research, one team has been able to supercool the kidneys of pigs—animals whose organs are of a similar size to human ones—and preserve them for days. The kidneys survived being stored at −4 °C (25 °F) and eventually reimplanted back into pigs. And that’s just the latest development in a field that is positively buzzing. It has proved super difficult to freeze organs. Once ice forms in them, they’re done. The ice crystals create all kinds of damage and render the organs unusable. That hasn’t stopped many researchers from trying.
Some have focused on cryopreservation—rapid extreme cooling that essentially leaves cells in a glasslike state. This process is now routine for eggs, sperm, and embryos, which are cooled to −196 °C in less than two seconds and can be used even after decades in storage. No one has managed to cryopreserve and thaw human organs for transplantation. But plenty of human bodies and brains have been stored at ultra-low temperatures in the hope that they might one day be rewarmed and brought back to life. (You can read more about why some people opt for cryonics here.)
In March, I wrote about Stephen L. Coles, a gerontologist who had opted to cryopreserve his own brain. After the scientist died in 2014, his body was taken to Alcor, a cryonics facility in Arizona. A team at the facility removed Coles’s head, perfused his brain with cryoprotective chemicals (which work like antifreeze), removed the brain from the skull, and cooled it to −146 °C. When Coles’s friend Greg Fahy, a cryobiologist, studied pieces of his brain years later, he found that the brain cells, which had shrunk, “bounced back” once they were rewarmed. But that doesn’t mean the cells are alive, or that it might one day be possible to reanimate the brain. As Matthew Powell Palm of Texas A&M told me at the time: “There are so many ways those neurons could be toast.” Powell Palm is working on other ways to preserve organs. It was he, along with his colleagues, who managed to store supercooled pig kidneys and successfully transplant them, in a study described as “a landmark achievement.” Those organs did better than kidneys stored on ice, he says. His approach didn’t require cryoprotectants. But other teams are exploring potential chemical cocktails that might allow them to store organs at lower temperatures, potentially for longer periods of time. (More on this in The Checkup soon!) Another way to prolong the lifespan of an organ is to use a machine that perfuses it with nutrients, mimicking what happens inside the body. Machine perfusion devices have become more commonly used over the last decade or so and are typically used to maintain livers and kidneys for up to about 24 hours. Researchers are now adapting this protocol for a growing list of organs, even eyeballs—a recent feat that might enable whole-eye transplants. In March, I went to visit scientists in Valencia who had developed a perfusion system for uteruses. They had used their device—which they nicknamed “Mother”—to keep a human uterus alive for a day. It’s an exciting time for organ preservation. Keep an eye out for more coverage from MIT Technology Review in the coming weeks. This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.
Cloudflare Internal DNS puts public and private DNS on one policy engine
“Instead of operating two separate DNS systems, customers use one API, one audit trail, one dashboard, and one policy engine for every DNS query—whether it is for a public website or an internal application,” Somoza said. Policy first. The resolver sits ahead of every lookup, not behind it. “Architecturally, Cloudflare Gateway becomes the resolver that customers connect to, and can use WARP, DNS over HTTPS, DNS over TLS, or traditional DNS,” Somoza said. “Gateway evaluates zero -trust policies first, then routes the query to the appropriate DNS view based on context, such as source IP, device posture, or network location.” No public path in. Internal zones sit outside the public DNS hierarchy entirely. “Internal zones are never assigned public nameservers—they are only reachable through Gateway, so every query is evaluated before it is resolved,” Somoza said.
The Download: an organ transplant breakthrough, and homegrown Chinese chips
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology. Supercooled kidneys have been transplanted into pigs in a “landmark achievement” When it comes to organ donation, time is everything. As soon as an organ has been removed from a donor’s body, it starts to deteriorate. Surgeons have only a matter of hours to get it into a recipient.In most cases, organs will be kept on ice during that time, at around 4 °C (39 °F). They cannot be frozen—in previous attempts, ice has formed, causing all kinds of damage. But now, scientists have come up with a device that allows organs to be cooled to -4 °C (25 °F) without forming any ice. They’ve tested it with pig organs and shown that kidneys, at least, can be preserved in the device for days then successfully transplanted. Read our story about their breakthrough, and why it raises hopes for longer-term storage of donated human organs.
—Jessica Hamzelou If you want to read more about this story and its implications for organ preservation and transplantation, sign up to receive The Checkup, our weekly biotech newsletter, later today.
The must-reads I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology. 1 Inside China’s epic push to replace US chips The gap between their chips’ capabilities remains large—for now. (WSJ $)+ How China is using open source AI as a new form of soft power around the globe. (NYT $)+ A new bill in the US takes aim at Chinese AI companies’ training practices. (NBC)+ US lawmakers are also mulling banning the military from using Chinese humanoid robots. (SCMP)2 Space data centers don’t exist yet, but people already oppose themEnvironmental experts warn it’ll further pollute the stratosphere. (Guardian)+ Four things we’d need to put data centers in space. (MIT Technology Review)+ What it’s like inside the data centers powering AI down here on Earth. (Axios)+ The left and right are finding common cause with data center protests in the US. (The Verge)3 US lawmakers are pushing for an AI ‘kill switch’After OpenAI’s models went rogue and hacked Hugging Face. (BBC)4 Peptides seem on the cusp of going mainstream in the USA lack of scientific evidence didn’t stop the FDA just voting to let some pharmacies to legally dispense them. (Wired $)+ How does Make America Healthy Again hold up to scientific scrutiny? (Nature)+ US measles cases are reaching levels not seen for three decades. (Wired $)+ Peptides are everywhere. Here’s what you need to know. (MIT Technology Review)5 The EU just fined Google almost $1 billionFor competition breaches over apps and search. (FT $)+ It came just a day before Trump renewed tariffs on 60 trading partners, including the EU. (BBC)6 Electric vehicles are selling well in EuropeAnd the share made by Chinese firms has doubled in the last year. (The Next Web)+ Hybrids are hot property in the US this summer. (Wired $)7 There’s a worsening shortage of computer science professorsYou can blame AI companies—they keep snapping them up, to our general detriment. (The Atlantic $) 8 A judge caught a stenographer allowing AI errors into their transcript It’s apparently the first time this has happened, but it certainly won’t be the last. (404 Media)+ Even judges themselves are falling for AI. (MIT Technology Review)9 Here’s what new tech millionaires will do with their IPO wealth 💸What a nice problem to have to grapple with! (Quartz $)10 Dating apps’ latest wheeze? In-person events Well well well, it seems we’ve come full circle. (Bloomberg $) Quote of the day “Call us optimists, call us dreamers. Just as we’ve always done, we’re betting on people.” —The voiceover from a new advert from Meta, which exhorts us to be more optimistic about AI.
One More Thing BELL HUTLEY AI is changing how we study bird migration In a warming world increasingly full of human infrastructure that can be deadly to them, like glass skyscrapers and power lines, migratory birds are facing many existential threats. Scientists rely on a combination of methods to track the timing and location of their migrations, though each has shortcomings. But now, machine-learning tools are unlocking a treasure trove of acoustic data for ecologists.
Atos launches sovereign cloud service to power comeback
Atos has launched a new sovereign cloud platform aimed squarely at European public sector bodies, healthcare providers and defense organizations. It’s the latest effort by European companies in their fight back against US dominance. Atos Sovereign Cloud offers a range of controls for data management, providing customers with resilience and full control over their data, complying with existing European legislation on data residency. “Digital sovereignty has become a global operational priority for organizations that need to manage dependencies, jurisdictional exposure and disruption risks across complex digital environments. Atos Sovereign Cloud gives customers a practical way to apply sovereign controls to their most critical workloads, while preserving flexibility, resilience and the ability to innovate securely,” said Michael Kollar, Atos Group digital sovereignty leader.
Microsoft explains why its West US Azure and cloud services failed
Microsoft cloud and Azure services hosted on the West Coast of the US went down for hours on Thursday when network connectivity failed. Although services running entirely within Microsoft’s West US cloud region were unaffected, any traffic entering or leaving the facilities was affected. Microsoft has now published a Preliminary Post Incident Review (PIR) of the incident, reporting that connectivity was lost for five hours between 14.44 UTC (7.44 a.m. Pacific Time) and 19.41 UTC on July 23. The problem was caused when a set of IP routes was removed in error while isolating a device for routine maintenance. Before starting the maintenance work, Microsoft checked that at least one of the two redundant paths to the facility remained operational. When it came to starting the work, however, automated systems included some additional devices in the perimeter to be isolated, and removing some IP routes that had not been included in the initial assessment.