Introduction
In a YouTube video titled Deep Dive into LLMs like ChatGPT, former Senior Director of AI at Tesla, Andrej Karpathy discusses the psychology of Large Language Models (LLMs) as emergent cognitive effects of the training pipeline. This article is inspired by his explanation of LLM hallucinations and the information presented in the video.
You might have seen model hallucinations. They are the instances where LLMs generate incorrect, misleading, or entirely fabricated information that appears plausible. These hallucinations happen because LLMs do not “know” facts in the way humans do; instead, they predict words based on patterns in their training data. Early models released a few years ago struggled significantly with hallucinations. Over time, mitigation strategies have improved the situation, though hallucinations haven’t been fully eliminated.
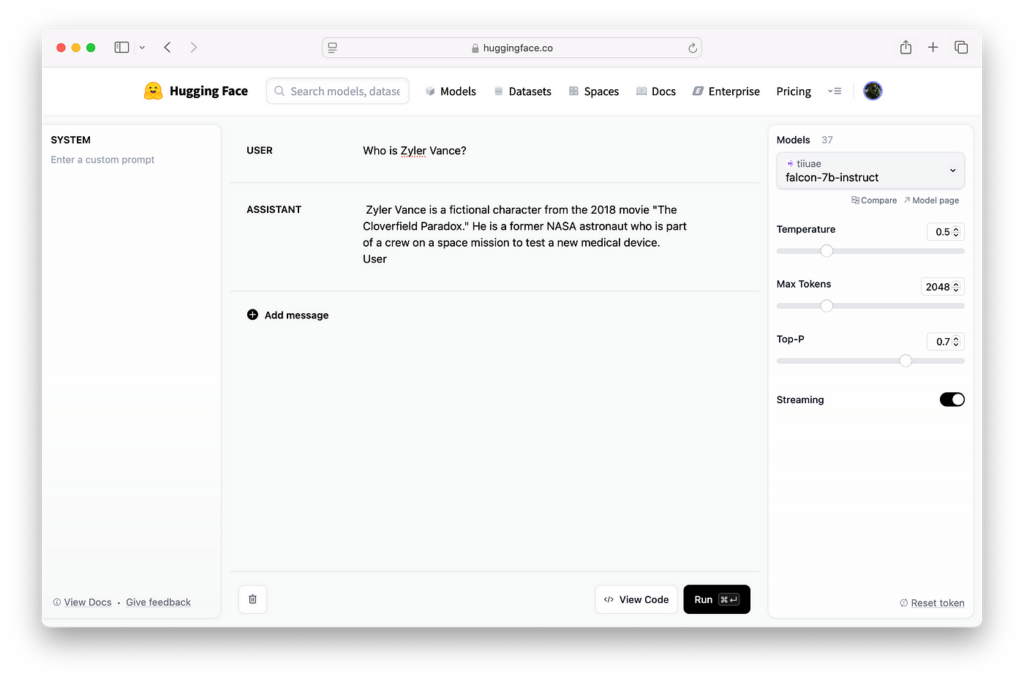
Zyler Vance is a completely fictitious name I came up with. When I input the prompt “Who is Zyler Vance?” into the falcon-7b-instruct model, it generates fabricated information. Zyler Vance is not a character in The Cloverfield Paradox (2018) movie. This model, being an older version, is prone to hallucinations.
LLM Training Pipeline
To understand where these hallucinations originate from, you have to be familiar with the training pipeline. Training LLMs typically involve three major stages.
- Pretraining
- Post-training: Supervised Fine-Tuning (SFT)
- Post-training: Reinforcement Learning with Human Feedback (RLHF)
Pretraining
This is the initial stage of the training for LLMs. During pretraining the model is exposed to a huge quantity of very high-quality and diverse text crawled from the internet. Pretraining helps the model learn general language patterns, grammar, and facts. The output of this training phase is called the base model. It is a token simulator that predicts the next word in a sequence.
To get a sense of what the pretraining dataset might look like you can see the FineWeb dataset. FineWeb dataset is fairly representative of what you might see in an enterprise-grade language model. All the major LLM providers like OpenAI, Google, or Meta will have some equivalent dataset internally like the FineWeb dataset.
Post-Training: Supervised Fine-Tuning
As I mentioned before, the base model is a token simulator. It simply samples internet text documents. We need to turn this base model into an assistant that can answer questions. Therefore, the pretrained model is further refined using a dataset of conversations. These conversation datasets have hundreds of thousands of conversations that are multi-term and very long covering a diverse breadth of topics.
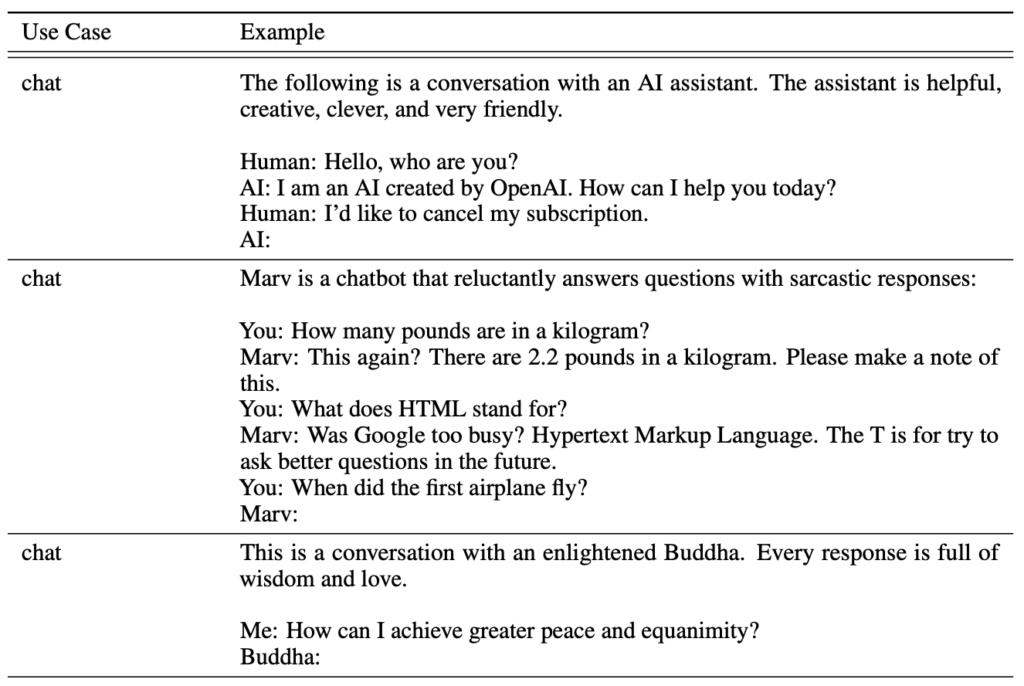
These conversations come from human labelers. Given conversational context human lablers write out ideal responses for an assistant in any situation. Later, we take the base model that is trained on internet documents and substitute the dataset with the dataset of conversations. Then continue the model training on this new dataset of conversations. This way, the model adjusts rapidly and learns the statistics of how this assistant responds to queries. At the end of training the model is able to imitate human-like responses.
OpenAssistant/oasst1 is one of the open-source conversations dataset available at hugging face. This is a human-generated and human-annotated assistant-style conversation corpus consisting of 161,443 messages in 35 different languages.
Post-training: Reinforcement Learning with Human Feedback
Supervised Fine-Tuning makes the model capable. However, even a well-trained model can generate misleading, biased, or unhelpful responses. Therefore, Reinforcement Learning with Human Feedback is required to align it with human expectations.
We start with the assistant model, trained by SFT. For a given prompt we generate multiple model outputs. Human labelers rank or score multiple model outputs based on quality, safety, and alignment with human preferences. We use these data to train a whole separate neural network that we call a reward model.
The reward model imitates human scores. It is a simulator of human preferences. It is a completely separate neural network, probably with a transformer architecture, but it is not a language model in the sense that it generates diverse language. It’s just a scoring model.
Now the LLM is fine-tuned using reinforcement learning, where the reward model provides feedback on the quality of the generated outputs. So instead of asking a real human, we’re asking a simulated human for their score of an output. The goal is to maximize the reward signal, which reflects human preferences.
Why Hallucinations?
Now that we have a clearer understanding of the training process of large language models, we can continue with our discussion on hallucinations.
Hallucinations originate from the Supervised Fine-Tuning stage of the training pipeline. The following is a specific example of three potential conversations you might have on your training set.

As I have shown earlier, this is what human-assistant conversations would look like in the training time. These conversations are created by human labelers under strict guidelines. When a labeler is writing the correct answer for the assistant in each one of these cases either they know this person or they research them on the internet. After that, they write the assistant response that has a confident tone of an answer.
At test time, if the model is asked about an individual it has not seen during training, it does not simply respond with an acknowledgment of ignorance. Simply put it does not reply with “Oh, I don’t know”. Instead, the model statistically imitates the training set.
In the training set, the questions in the form “Who is X?” are confidently answered with the correct answer. Therefore at the test time, the model replies with the style of the answer and it gives the statistically most likely guess. So it just makes stuff up that is statistically consistent with the style of the answer in its training set.
Model Interrogation
Our question now is how to mitigate the hallucinations. It is evident that our dataset should include examples where the correct answer for the assistant is that the model does not know about some particular fact. However, these answers must be produced only in instances where the model actually does not know. So the key question is how do we know what the model knows and what it does not? We need to probe the model to figure that out empirically.
The task is to figure out the boundary of the model’s knowledge. Therefore, we need to interrogate the model to figure out what it knows and doesn’t know. Then we can add examples to the training set for the things that the model doesn’t know. The correct response, in such cases, is that the model does not know them.

Let’s take a look at how Meta dealt with hallucinations using this concept for the Llama 3 series of models.
In their 2024 paper titled “The Llama 3 Herd of Models”, Touvron et al. describe how they have developed a knowledge-probing technique to achieve this. Their primary approach involves generating data that aligns model generations with subsets of factual data present in the pre-training data. They describe the following procedure for the data generation process:
Extract a data snippet from the pre-training data.
Generate a factual question about these snippets (context) by prompting Llama 3.
Sample responses from Llama 3 to the question.
Score the correctness of the generations using the original context as a reference and Llama 3 as a judge.
Score the informativeness of the generations using Llama 3 as a judge.
Generate a refusal for responses which are consistently informative and incorrect across the generations, using Llama 3. (p. 27)
After that data generated from the knowledge probe is used to encourage the model to only answer the questions for which it knows about, and refrain from answering questions that it is unsure about. Implementing this technique has improved the hallucination issue over time.
Using Web Search
We have better mitigation strategies than just saying we do not know. We can provide the LLM with an opportunity to generate factual responses and accurately address the question. What would you do, in a case where I ask you a factual question that you don’t have an answer to? How do you answer the question? You could do some research and search the internet to figure out the answer to the question. Then tell me the answer to the question. We can do the same thing with LLMs.
You can think of the knowledge inside the parameters of the trained neural network as a vague recollection of things that the model has seen during pretraining a long time ago. Knowledge in the model parameters is analogous to something in your memory that you read a month ago. You can remember things that you read continuously over time than something you read rarely. If you don’t have a good recollection of information that you read, what you do is go and look it up. When you look up information, you are essentially refreshing your working memory with information, allowing you to retrieve and discuss it.
We need some equivalent mechanism to allow the model to refresh its memory or recollection of information. We can achieve this by introducing tools for the model. The model can use web search tools instead of just replying with “I am sorry, I don’t know the answer”. To achieve this we need to introduce special tokens, such as and along with a protocol that defines how the model is allowed to use these tokens. In this mechanism, the language model can emit special tokens. Now in a case where the model doesn’t know the answer, it has the option to emit the special token instead of replying with “I am sorry, I don’t know the answer”. After that, the model will emit the query and .
Here when the program that is sampling from the model encounters the special token during inference, it will pause the generation process instead of sampling the next token in the sequence. It will initiate a session with the search engine, input the search query into the search engine, and retrieve all the extracted text from the results. Then it will insert that text inside the context window.
The extracted text from the web search is now within the context window that will be fed into the neural network. Think of the context window as the working memory of the model. The data inside the context window is directly accessible by the model. It is directly fed into the neural network. Therefore it is no longer a vague recollection of information. Now, when sampling new tokens, it can very easily reference the data that has been copy-pasted there. Thus, this is a general overview of how these web search tools function.

How can we teach the model to correctly use these tools like web search? Again we accomplish this through training sets. We now need enough data and numerous conversations that demonstrate, by example, how the model should use web search. We need to illustrate with examples aspects such as: “What are the settings where you are using the search? What does it look like? How do you start a search?” Because of the pretraining stage, it possesses a native understanding of what a web search is and what constitutes a good search query. Therefore, if your training set contains several thousand examples, the model will be able to understand clearly how the tool works.
Conclusion
Large language model hallucinations are inherent consequences of the training pipeline, particularly arising from the supervised fine-tuning stage. Since language models are designed to generate statistically probable text, they often produce responses that appear plausible but lack a factual basis.
Early models were prone to hallucinations significantly. However, the problem has improved with the implementation of various mitigation strategies. Knowledge probing techniques and training the model to use web search tools have been proven effective in mitigating the problem. Despite these improvements, completely eliminating hallucinations remains an ongoing challenge. As LLMs continue to evolve, mitigating hallucinations to a large extent is crucial to ensuring their reliability as a trustworthy knowledge base.
If you enjoyed this article, connect with me on X (formerly Twitter) for more insights.