AI
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

Bitcoin:
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

Datacenter:
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

Energy:
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

SUSE bets automated migration can break VMware’s grip on virtualization
CSCS, part of Switzerland’s ETH domain of research organizations, receives government funding and must spend it wisely. “We could spend more money on VMware or on developing new technology,” Conciatore said. The organization chose the latter. CSCS Associate Director Dr. Maria Grazia Giuffreda told the SUSEcon audience that the shift has freed up engineering capacity. “Because of SUSE Virtualization, we reduced the amount of time managing infrastructure by 70%,” she said. “You are freeing the time of very excellent engineers to take on new challenges rather than routine and boring work.” Conciatore noted, however, that CSCS didn’t abandon VMware. “We’re not leaving completely,” he said. “The main thing is, we didn’t expand VMware in the last few years, and started buying alternatives.” The bigger picture For enterprises still weighing their options, the decision may come down to how deeply they are embedded in the VMware network, Nadkarni said. “It’s not just VMware, but the whole ecosystem of tools tied into the VMware way of doing things. That’s what Broadcom is exploiting.” CSCS had an advantage, Conciatore said: Its automation treated physical and virtual machines the same way, making it easier to decouple. Not every enterprise will have that flexibility. “SUSE is pushing this as a VMware alternative because they have something that works,” he said. “Currently, the fact that we are not vendor-locked is very important.”

AI at MIT
At MIT, AI has become so pervasive that you can almost find your way into it without meaning to. Take Sili Deng, an associate professor of mechanical engineering. Deng says she still doesn’t know whether she’d have gone all in on artificial intelligence had it not been for the covid pandemic. She had joined the faculty in 2019 and was in the process of setting up her lab to study combustion kinetics, emissions reduction, and flame synthesis of energy materials when covid hit, putting a halt to all lab renovations. Because she needed to start from scratch, she challenged herself and her postdocs to try machine learning “and see, with the fundamental knowledge we have on the combustion side, what are the gaps that we think machine learning could [fill].” Under her leadership, Deng’s Energy and Nanotechnology Group used AI to develop a “digital twin” that mirrors the performance of an energy/flow device—a digital replica of a physical system. Eventually, this model should be able to predict and control the workings of fuel combustion systems in real time. Unlike Deng, who came to AI through the slings and arrows of outrageous fortune, Zachary Cordero, an associate professor of aero-astro, began using AI thanks to a colleague’s expertise. In 2024 John Hart, head of the Department of Mechanical Engineering, suggested that Cordero, who develops novel materials and structures for emerging aerospace applications, meet with Faez Ahmed, an associate professor of mechanical engineering and an expert in machine learning and optimization for engineering design. Cordero says he hadn’t previously been pursuing AI-related research: “This is all totally new to me.” Working with Ahmed and other collaborators on a project sponsored by the US Defense Advanced Research Projects Agency (DARPA), Cordero developed an AI tool that can optimize the material composition of what’s known as a blisk—a bladed disk that’s a key component in jet and rocket turbine engines. Their work aims to improve engine performance and longevity and could lead to more reliable reusable rocket engines for heavy-lift launch vehicles. Cordero says the AI system augmented human intuition—even “on problems where it’s almost impossible to have intuition.” Professor Ju Li posits that if AI is given autonomy to do experiments, to try different things and fail and learn from that, it could evolve into something very similar to human intelligence. Stories like these abound at MIT. In every department, in almost every lab on campus, AI technologies such as machine learning, large language models, and neural networks are transforming research—turbocharging existing methods, opening previously unexplored or inaccessible pathways, and creating novel opportunities in drug development, computing, energy technologies, manufacturing, robotics, neuroscience, metallurgy, and even wildlife preservation. “I cannot think of a single group meeting that we have where we’re not talking about these tools,” says Angela Koehler, the Charles W. and Jennifer C. Johnson Professor of Biological Engineering and faculty lead of the MIT Health and Life Sciences Collaborative (MIT HEALS). Her research group uses AI models to develop drug candidates designed to attach to molecular targets previously considered “undruggable,” such as transcription factors, RNA-binding proteins, or cytokines. “I would say 90% of the thesis committees I’m on involve a significant AI component,” she says. “And that definitely was not the case five years ago.” “Artificial intelligence is everywhere on campus,” says Ian Waitz, MIT’s vice president for research and the Jerome C. Hunsaker Professor of Aero-Astro. “Any field with a tremendous amount of complexity will benefit from it. Life sciences. Materials science. Anyone who does any kind of image analysis uses these tools now. I don’t know of a single research field here at MIT that hasn’t been impacted by AI.”
AI isn’t exactly new at MIT Though Deng and Cordero may have come to it through happenstance or clever matchmaking, most developments in AI at MIT don’t arise that way. Nor is the interest in it new. More than 70 years ago, in 1954, computer researcher Belmont G. Farley and physicist Wesley A. Clark ran the world’s first computer simulation of a neural network at MIT. Interest in neural network technology—now better known as deep learning—waxed and waned over the next decades. Ju Li, PhD ’00, the Carl Richard Soderberg Professor of Power Engineering (as well as a professor of nuclear science and engineering and materials science and engineering), remembers taking a course on neural networks during Independent Activities Period (IAP) in 1995, when he was a graduate student. “It was not a deep network—just a few layers,” recalls Li, who researches materials used in nuclear energy, batteries, electrolyzers, and energy-efficient computing. He characterizes it as essentially a regression tool that they used to fit curves. But over the past few years, activity in AI has exploded globally, fueled by powerful new models and an enormous increase in the computing power of chips; the resulting proliferation and evolution of data centers has in turn sparked more activity. Today, neural networks can have more than a thousand layers. Backed by massive investments in AI in both the public and private spheres, AI researchers have created a suite of tools that can scan almost immeasurable quantities and types of data; interface with sensors, robotics, and other mechanical devices; and communicate with human researchers in natural language.
RACHEL WU VIA MIT NEWS OFFICE “Many of the tools that we developed in the lab— they’re very broadly used in the pharmaceutical industry. And they’re really making significant impact.” Regina Barzilay Regina Barzilay has been working on AI since she came to MIT in 2003. Today, she’s the School of Engineering Distinguished Professor for AI and Health and AI faculty lead of the MIT Abdul Latif Jameel Clinic for Machine Learning in Health. But she says that if anyone had told her even 10 years ago where the field would be now and what kinds of things she’d be working on, she “absolutely” wouldn’t have believed it. AI applications for drug discovery and development, one of Barzilay’s areas of expertise, have been particularly prolific and successful at MIT. Giovanni Traverso’s lab, for example, has used AI to design nanoparticles that can deliver RNA vaccines and other therapies more efficiently than previous systems. Researchers at CSAIL (the Computer Science & Artificial Intelligence Laboratory, where Barzilay is a principal investigator) have used AI models to explain how a narrow-spectrum antibiotic specifically targets harmful microbes in people with Crohn’s disease. The Jameel Clinic has helped build models that can predict which flu vaccine will be most effective in a given year. “Many of the tools that we developed in the lab—they’re very broadly used in the pharmaceutical industry,” she explains. “And they’re really making significant impact.” She says there’s not even a question anymore about whether they make a difference. They’ve become standard tools because they work every day. One such tool is Boltz, an open-source AI model developed by a group at the Jameel Clinic and initially released in November 2024 as Boltz-1. Inspired by DeepMind’s AlphaFold2—a model that earned Demis Hassabis and John Jumper the 2024 Nobel Prize in chemistry—Boltz-1 helps scientists predict the 3D structures of proteins and other biological molecules. The Jameel Clinic researchers soon followed up with Boltz-2, which in addition to predicting molecular structure can also predict affinity—the strength with which a protein binds with a small molecule. Assays to measure affinity, a vital measure in drug development, are among the most importantperformed in biology and chemistry labs. In October 2025, the Jameel Clinic released its latest iteration, BoltzGen—a generative AI model capable of designing custom proteins that could bind with a wide range of biomolecular targets. Molecular binders already play important roles in fields including therapeutics, diagnostics, and biotechnology. BoltzGen is the first advanced, large-scale model that considers every single atom in the potential new protein and every atom in its target molecule, providing greater accuracy. Hannes Stärk, the fourth-year PhD student at CSAIL who built BoltzGen, says the model works because it actually learns—drawing inferences from the data it is trained with and then producing novel ideas inspired by that data. With machine learning, you want the model to generalize from the data you use to train it, says Stärk, who created BoltzGen over seven months, often working up to 12 hours a day. “Because otherwise,” he says, “your solution is already in your training data.” Stärk has also assembled a network of over 30 scientists both within and beyond MIT to explore the design and applications of molecular binders for use in drug development, metabolomics, and structural biology as well as in treating cancer, autoimmune diseases, and genetic diseases. “It’s nice to have one model that can do all of this,” he says. Training across all these areas also makes the model better at generalizing. Beyond drug discovery As labs working in drug development continue to reap benefits from AI, other researchers across the Institute are busy applying existing AI tools or, more often, developing their own models for use in myriad disciplines and applications. A cross-disciplinary group involving the Department of Electrical Engineering and Computer Science (EECS), CSAIL, and Mass General Hospital has launched MultiverSeg, a tool that quickly annotates areas of interest in medical images and could help scientists develop new treatments and map disease progression. MIT researchers are also designing and running AI-directed automated laboratories to accelerate and refine the process of discovering new components for sustainable materials and solar panels. And Ahmed’s MechE group is developing AI models to do such things as help automakers design high-performance vehicles or determine whether a large shipping vessel can be considered seaworthy. Ahmed also teaches a course titled AI and Machine Learning for Engineering Design. First offered in 2021, it attracts not only mechanical, civil, and environmental engineers but students from aero-astro, Sloan, and more. MIT TECHNOLOGY REVIEW “The goal is to tap into diverse types of raw data and turn that into “something that helps us understand what is putting species at risk.” Sara Beery Meanwhile, Priya Donti, an assistant professor of EECS and a PI at the Laboratory for Information & Decision Systems (LIDS), has developed AI-enabled optimization approaches to help schedule power generation resources on power grids. The machine-learning tools her group builds will help utility operators respond to many inevitable grid issues. “The big challenge is that on a power grid, you need to maintain this exact balance between the amount of power you’re producing and putting into the grid and the amount that you’re taking out on the other side,” she explains. “When you have a lot of variation from solar, wind, and other sources of power whose output varies based on the weather, you have to coordinate the grid much more tightly in order to maintain that balance.” Information about the physics of how power grids work is embedded in Donti’s AI model, so it functions and reacts much as a real grid would. MIT researchers are even applying AI tools to explore and analyze the natural world. Sara Beery, an assistant professor of EECS who specializes in AI and decision-making, develops AI methods that discover and dig into ecological data collected by a wide range of remote sensing technologies to analyze and predict how species and ecosystems are changing around the globe. These technologies enable Beery and her colleagues to gather data on a far greater number of endangered species than ever before, and at an unprecedented scale. Historically, most ecological research has focused on collecting incredibly rich data about single species in really small regions, she says, but “we’ve realized that’s not sufficient.” Information gleaned from, say, a small part of one river ecosystem will not help us understand or prevent what she calls “the exponential increase in species extinction rates that we’re currently facing.” Already, Beery says, “we’re using multimodal AI to enable experts to quickly search massive repositories of image data, to discover data points that were previously very difficult to find.” But she says the goal is to be able to readily tap into diverse types of raw data—from satellite and bioacoustic sensor data to camera images and DNA—and “actually turn that into some sort of scientific insight, something that helps us understand what is putting species at risk.”
Mens et manus in AI While some MIT researchers have successfully used AI to help invent technologies ranging from novel cancer therapies to safer high-performance automobiles, others are also using machine learning and other AI tools to help determine whether these technologies perform as promised—or can be produced successfully and economically at scale. Connor Coley, SM ’16, PhD ’19, an associate professor of chemical engineering and EECS, designs new molecules—and recipes for making new molecules, primarily small organic molecules—for potential use by pharmaceutical, agricultural, and other chemical companies. Coley, a former MIT Technology Review Innovators Under 35 honoree, has developed a “genetic” algorithm that uses biologically inspired processes including selection and mutation. This tool encodes potential polymer blends drawn from a large database of polymers into what is effectively a digital chromosome, which the algorithm then improves to generate the most promising material combinations. Working at the intersection of chemistry and computer science, Coley believes AI could one day help his lab discover polymer blends that would lead to improved battery electrolytes and tailored nanoparticles for safer drug delivery. He and his lab also work to develop machine-learning tools that streamline the discovery and production processes. “If you want AI to be the brain behind some of the science you’re doing, you need the hands as well,” says Coley, who was one of the first MIT faculty members hired into the MIT Schwarzman College of Computing. He and his group have coupled a robotic liquid-handling platform with an optimization algorithm. In the project designed to look for optimal polymer blends, the autonomous system not only chooses which polymer solutions to test but also performs the physical testing. The system, which can generate and test 700 new polymer blends in a day, has identified one that performed 18% better than any of its components. Systems with a similar level of autonomy could also have a big impact on early-stage drug discovery. One effect, he observes, should be to reduce the time it takes to advance a drug from the lab into clinical trials. But the real question, he says, is “What might we be able to do that we just couldn’t do with any reasonable amount of resources previously?” Alexander Siemenn, PhD ’25, also uses AI both to search for new materials and to control robots that test the physical properties of those materials. For his doctoral thesis, Siemenn built from scratch a fully autonomous AI-driven robotic laboratory to discover and test sustainable high-performance materials for solar panels. The system incorporates computer vision, machine learning, and an optimization algorithm and runs 24 hours a day. “We are pairing conventional methods [of measurement] that have been almost entirely manual to this point with the AI methods,” says Siemenn. “The goal is to be able to not just improve their accuracy but also make them fast and autonomous.” Hits and near misses Institute labs are also encountering some of the first real borders of the brave new AI-enhanced world. Many researchers at MIT and elsewhere agree that most of the “low-hanging fruit” has already been collected. That includes AI’s contributions to managing massive data sets and accelerating existing discovery and testing processes, at times to near light speed. Beyond those immediate gains, though, results vary—even in drug development, which has seen some of the most spectacular achievements of AI. “There are some areas where you would assume we should be doing much better here and we are not,” observes Barzilay. “The reason we cannot cure neurodegenerative diseases like Alzheimer’s or very advanced cancer is because we don’t really understand fully—on the molecular level—the disease itself, the drivers, and how to control it.” And AI still hasn’t made what she calls “a significant transformation” in terms of understanding those underlying disease mechanisms. “There are some helper tools,” she says, but AI hasn’t provided a profoundly new understanding of any disease—“So this is a place that we would hope to see more.” MIT TECHNOLOGY REVIEW “In AI, scaling is synergistic and good. In chemistry and materials, scaling is kind of a scary beast that you need to beat in order to make an impact.” Rafael Gómez-Bombarelli Limits in materials science are also emerging, particularly in translating digital solutions proposed by AI into objects made of atoms and molecules. Rafael Gómez-Bombarelli, an associate professor of materials science and engineering, develops physics-based machine-learning simulations to accelerate the discovery cycle for sustainable polymers and materials for use in energy, health care, and batteries. While physics-based simulations in themselves have been an unmitigated success, he says, results have been spottier when it comes to manufacturing the materials themselves; many of the solutions generated by these simulators fail in the physical world. “It turns out these simulators don’t capture lots of things that are important,” he says. “They operate on the atomically resolved problems for nanosecond-timescale questions. But many, many [materials] problems don’t happen in nanoseconds, don’t involve just a few ten thousands of atoms.” And they often involve physics more complicated than current AI models account for. What’s more, when the goal might be to produce millions of tons of a new material, scaling errors can be disastrous. “In AI, scaling is synergistic and good,” Gómez-Bombarelli says. “In chemistry and materials, scaling is kind of a scary beast that you need to beat in order to make an impact.”
New methods, new insights While AI has already produced myriad results and surprises, researchers at MIT believe much of its potential is still waiting to be discovered. And they are eager to search for high-impact applications. Ila Fiete, a professor of brain and cognitive sciences, builds AI tools and mathematical models to expand our knowledge of how the brain develops and reshapes its neural connections. Her work, she believes, can help us understand how we form memories or perceive ourselves in space—and that, in turn, can lead to improvements in AI. Many features of AI, including parallel computing in neural networks, were inspired by the human brain. “AI has [helped] and will continue to help us do more science and better science,” she says. “But neuroscientists believe there is a lot about how humans and other biological intelligences learn and solve problems that is better in some dimensions than current AI models. And by learning better how that works, we can actually inform better AI architectures.” Li agrees that certain elements of human intelligence and learning could benefit AI and help it solve some of our world’s most pressing and complex problems, including global poverty and climate change. “Large language models today have read tens of millions of papers and books,” he says, adding that they are “much more interdisciplinary than any of us.” Yet he notes that scientific literature is strongly biased toward success. “The day-to-day experience in the lab is 95% frustration, and I think it’s the failure cases which build character,” he says. He posits that if AI is given autonomy to do experiments, to try different things and fail and learn from that, it could evolve into something very similar to human intelligence. Researchers at MIT believe that as AI continues to evolve, expand, and proliferate, the Institute has a special duty to channel these technologies toward useful, attainable ends. “Right now, in the AI world there is a lot of hype and fluff,” says Ahmed, who is developing generative AI tools to help tackle complex engineering and design problems. “The digital world is overflowing with stuff,” he says, and there’s a lot happening on the AI front with images, text, and video. “But the physical world is still less affected, and we are seeing a lot more happening at the intersection of physical and AI at MIT.” AI’s future includes potential triumphs and potential pitfalls. Researchers still worry about “hallucinations”—results spit out of AI models that make no sense in the real world. They worry, as well, that some practitioners will rely too heavily on AI tools, omitting key insights and safeguards that keep an experiment or production facility on track. And they worry about overpromising—unrealistically presenting AI as a magical solution to all problems great and small. “It’s impossible to predict how good these models are going to get,” says MechE’s Hart. “Where they are going to shine and where they are going to limit.” But instead of sensing danger, Hart sees opportunity, especially at MIT: “We have the learned expertise and experience that allows us to frame the right questions and use these tools in the right way.” The challenge for the MITs of the world, he says, is to figure out how to use AI tools to create faster, better solutions and navigate more complex problems than we ever could before.

Caring for service dogs
Brenda Schafer Kennedy, SM ’93, knows that sometimes the best medicine comes with four legs and fur. Kennedy is the chief veterinary and research officer for Canine Companions, a California-based, nationwide organization that provides assistance dogs at no cost to children, veterans, and adults with disabilities. “The need is enormous: One in four people in the US has a disability. We have so many people who could benefit from these dogs,” Kennedy says. While service dogs might be best known for guiding the blind, Canine Companions trains dogs to do such things as open doors for wheelchair users or alert deaf people to doorbells, fire alarms, and other key sounds. Its psychiatric service dogs help veterans suffering from post-traumatic stress disorder—waking them from nightmares, for example. To date, it’s paired more than 7,000 dogs with people in need. It’s critical to ensure that every service dog placed is healthy, and Kennedy—a veterinarian—spearheads the organization’s efforts to breed dogs with that in mind. “We wouldn’t place a dog that might have a life-shortening or a significant medical issue that a person might have to manage,” she says.
Kennedy also takes the lead in developing tech to support Canine Companions’ work. She is a co-inventor of CanineAlert, a patented device that sends a signal to a dog’s collar so the dog can interrupt a nightmare when its owner’s heart rate spikes. The technology may soon expand to address daytime anxiety episodes. “These dogs can really be not only life-transforming in terms of providing people with independence, but critically essential and even life-saving,” she says.
An animal lover since childhood, Kennedy earned her undergraduate degree from Northwestern University before coming to MIT for her master’s in biology. “I found incredible mentors at MIT,” she says, noting that she particularly enjoyed working with Professor Hazel Sive, whose lab studied African clawed frogs. The research was fascinating, but Kennedy wanted to work in hands-on medicine, so she obtained her veterinary degree from Tufts University. She then spent 16 years in private practice. Today, she is delighted to combine animal care with research at Canine Companions. “I had a passion for doing something really mission-oriented,” she says. “I love the idea of helping people through the human-canine bond.” In additional to providing service, dogs also offer something elemental, Kennedy says: “Dogs add unconditional love to the mix. They support emotional and mental health for people and can be bridges to the community.”

The new word in home construction could be “plastics”
Single-use plastics are a persistent source of environmental pollution, and the need to house a growing global population puts increasing pressure on resources such as timber. MIT engineers have an idea that could make a dent in both problems at once. In a recent study, a team led by mechanical engineering professor David Hardt, SM ’74, PhD ’79, and lecturer and research scientist AJ Perez ’13, MEng ’14, PhD ’23, laid out a plan for using recycled plastic to 3D-print construction-grade beams, trusses, and other structures that could one day offer lighter, more sustainable alternatives to traditional wood-based framing. Although some companies are working on using large-scale additive manufacturing to create walls, they’re mainly using concrete or clay, whose production typically has a large negative environmental impact. These engineers are among the first to explore printing structural framing elements—and to do so using recycled plastic. The design they came up with is similar in shape to the traditional wooden trusses that support flooring, with beams that connect in a pattern resembling a ladder with diagonal rungs. To test it, they obtained pellets made of recycled PET polymers and glass fibers from an aerospace materials company and fed them into a room-size 3D printer as “ink.” When they printed four long trusses with this material and configured them into a conventional plywood-topped floor frame, the result had a load-bearing capacity of over 4,000 pounds, far exceeding key building standards set by the US Department of Housing and Urban Development. The plastic-printed trusses weigh about 13 pounds each, light enough to transport without a flatbed truck. An industrial printer can crank one out in under 13 minutes. Crucially, the researchers are developing the process to work with “dirty” plastic that hasn’t been cleaned or preprocessed. In addition to floor trusses, they are working on printing other elements and combining them into a full frame for a modest-size house.
“We’ve estimated that the world needs about 1 billion new homes by 2050. If we try to make that many homes using wood, we would need to clear-cut the equivalent of the Amazon rainforest three times over,” says Perez. “The key here is: We recycle dirty plastic into building products for homes that are lighter, more durable, and sustainable.” The researchers envision that one day, trash like used bottles and food containers could be sent directly into a shredder, turned into pellets, and fed into a large-scale additive manufacturing machine to become structural composite construction components. At the construction site, the elements could be quickly fitted into a lightweight yet sturdy home frame. “The idea is to bring shipping containers close to where you know you’ll have a lot of plastic, like next to a football stadium,” Perez says. “Then you could use off-the-shelf shredding technology and feed that dirty shredded plastic into a large-scale additive manufacturing system, which could exist in micro-factories, just like bottling centers, around the world. You could print the parts for entire buildings that would be light enough to transport on a moped or pickup truck to where homes are most needed.”
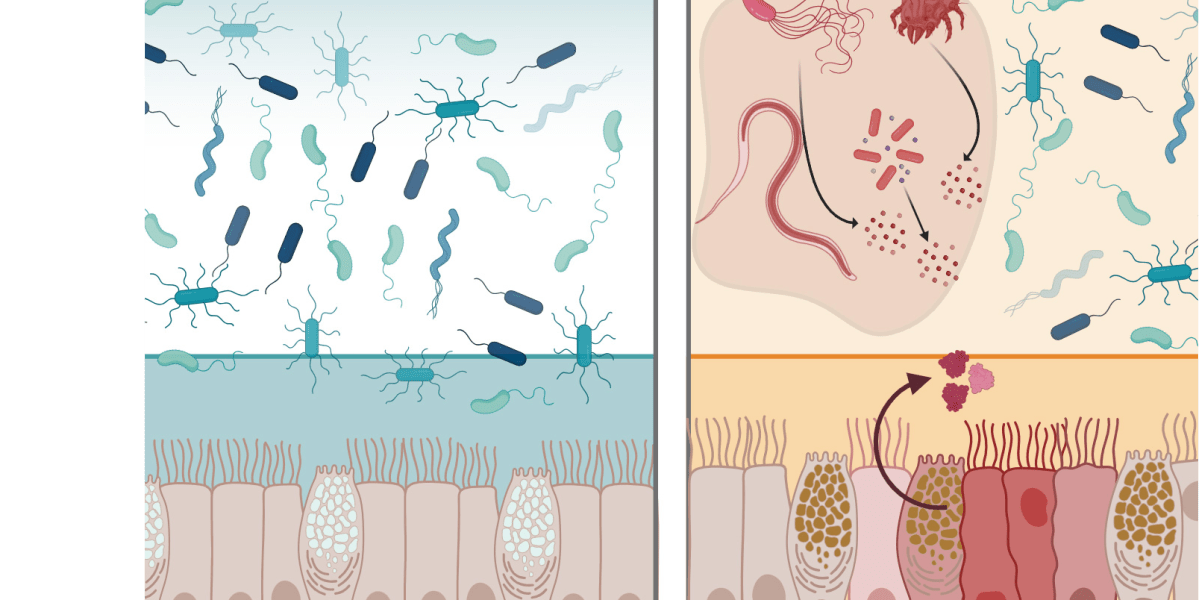
A natural protein may protect the GI tract from infection
Embedded in the body’s mucosal surfaces, proteins called lectins bind to sugars found on cell surfaces. A team led by MIT chemistry professor Laura Kiessling has found that one such protein, intelectin-2, both helps fortify the mucosal barrier and offers broad-spectrum protection against harmful bacteria found in the GI tract. Intelectin-2 binds to a sugar molecule called galactose that is found on bacterial membranes, the team found, trapping the bacteria and hindering their growth; the trapped microbes eventually disintegrate, suggesting that the protein is able to kill them by disrupting their cell membranes. It also helps strengthen the intestine’s protective lining by binding to the galactose in the mucins that make up mucus. “What’s remarkable is that intelectin-2 operates in two complementary ways. It helps stabilize the mucus layer, and if that barrier is compromised, it can directly neutralize or restrain bacteria that begin to escape,” says Kiessling, who conducted the study with colleagues including Amanda Dugan, a former MIT postdoc and research scientist, and Deepsing Syangtan, PhD ’24. Because intelectin-2 can neutralize or eliminate pathogens such as Staphylococcus aureus and Klebsiella pneumoniae, which are often difficult to treat with antibiotics, it could someday be adapted as an antimicrobial agent, the researchers say. Restoring desirable levels of intelectin-2 could also help people with disorders such as inflammatory bowel disease, who may have either too little of it (potentially weakening the mucus barrier) or too much (killing off beneficial gut bacteria). “Harnessing human lectins as tools to combat antimicrobial resistance opens up a fundamentally new strategy that draws on our own innate immune defenses,” Kiessling says. “Taking advantage of proteins that the body already uses to protect itself against pathogens is compelling and a direction that we are pursuing.”
Inventor recalls eye imaging breakthrough
If you’ve been to an eye doctor and had an image taken of the inside of your eye, chances are good it was done with optical coherence tomography (OCT)—a technology invented by clinician-scientist David Huang ’85, SM ’89, PhD ’93, and now used in 40 million procedures per year. OCT is a noninvasive technique used to produce detailed images of complicated biological tissues such as the retina and the plaques that can build up in coronary arteries. It maps the time-of-flight of light waves reflected from tissue and paints a high-resolution picture of internal structures. “It uses infrared light that’s barely visible compared to the bright flash of fundus photography [another common method of eye imaging] and provides a lot more information—three-dimensional rather than two-dimensional information—at higher resolution,” Huang says. The discovery earned him and his co-inventors slots in the National Inventors Hall of Fame in 2025 as well as the Lasker Award and the National Medals of Technology and Innovation in 2023. Huang didn’t expect to change the paradigm of eye imaging when he began studying electrical engineering as an undergraduate at MIT, but he was interested in using an engineering mindset to contribute to medical advancements. That, he thought, could be his way to follow in the footsteps of his father, who was a family practitioner.
OCT emerged from his work as an MD-PhD student in the Harvard-MIT Program in Health Sciences and Technology. While studying ultrafast lasers at MIT under James Fujimoto ’79, SM ’81, PhD ’84, the Elihu Thomson Professor of Electrical Engineering, Huang was tasked with using the lasers to improve various ophthalmological tasks, including measuring the thickness of the cornea and retina. Huang thought an approach known as interferometry, which could measure the time of flight down to one quadrillionth of a second, could improve thickness measurements to micrometer resolution. Huang’s experiments revealed that the technique was able to detect very faint signals arising from fine internal structures within the retina. Fujimoto and Huang realized the potential for inventing a new type of imaging and enlisted the help of Eric Swanson, SM ’84, who was using interferometry for intersatellite communications at Lincoln Laboratory, to develop an OCT machine for biological applications. Huang tested the new machine on several types of tissues accessed through Harvard Medical School and found it particularly successful in imaging retinal and coronary artery samples. He and his colleagues published their initial findings in Science in 1991, establishing OCT as a new imaging modality.
“Because of our ability to form collaborations with medical doctors and the more advanced technologies that were easily accessible at Lincoln Lab and MIT, we were able to make this new imaging technology take off when other people who were exploring around the same area were not able to demonstrate imaging results,” he says. After the groundbreaking invention, Huang finished his academic and medical training as an ophthalmologist while Fujimoto and Swanson formed a startup company to ensure that the device got into medical offices. Over the next decades, Huang has continued to refine OCT for various applications. Today, as the director of research at Oregon Health and Science University’s Casey Eye Institute, he leads research groups exploring new ways to use OCT in techniques such as OCT angiography (imaging blood flow down to the capillary level) and OCT optoretinography (mapping the light response in retinal photoreceptor cells). In addition to conducting research, he also sees patients and is the cofounder of GoCheck Kids, a digital platform for pediatric eye screening. Huang credits his knack for innovation to his position at the nexus of diverse fields. “It’s hard for a pure medical doctor or a pure laser engineer to realize that there is an opportunity to invent a new device that solves a real problem in the clinic,” he says. “But it’s really easy when you have knowledge on both sides.”
SUSE bets automated migration can break VMware’s grip on virtualization
CSCS, part of Switzerland’s ETH domain of research organizations, receives government funding and must spend it wisely. “We could spend more money on VMware or on developing new technology,” Conciatore said. The organization chose the latter. CSCS Associate Director Dr. Maria Grazia Giuffreda told the SUSEcon audience that the shift has freed up engineering capacity. “Because of SUSE Virtualization, we reduced the amount of time managing infrastructure by 70%,” she said. “You are freeing the time of very excellent engineers to take on new challenges rather than routine and boring work.” Conciatore noted, however, that CSCS didn’t abandon VMware. “We’re not leaving completely,” he said. “The main thing is, we didn’t expand VMware in the last few years, and started buying alternatives.” The bigger picture For enterprises still weighing their options, the decision may come down to how deeply they are embedded in the VMware network, Nadkarni said. “It’s not just VMware, but the whole ecosystem of tools tied into the VMware way of doing things. That’s what Broadcom is exploiting.” CSCS had an advantage, Conciatore said: Its automation treated physical and virtual machines the same way, making it easier to decouple. Not every enterprise will have that flexibility. “SUSE is pushing this as a VMware alternative because they have something that works,” he said. “Currently, the fact that we are not vendor-locked is very important.”
AI at MIT
At MIT, AI has become so pervasive that you can almost find your way into it without meaning to. Take Sili Deng, an associate professor of mechanical engineering. Deng says she still doesn’t know whether she’d have gone all in on artificial intelligence had it not been for the covid pandemic. She had joined the faculty in 2019 and was in the process of setting up her lab to study combustion kinetics, emissions reduction, and flame synthesis of energy materials when covid hit, putting a halt to all lab renovations. Because she needed to start from scratch, she challenged herself and her postdocs to try machine learning “and see, with the fundamental knowledge we have on the combustion side, what are the gaps that we think machine learning could [fill].” Under her leadership, Deng’s Energy and Nanotechnology Group used AI to develop a “digital twin” that mirrors the performance of an energy/flow device—a digital replica of a physical system. Eventually, this model should be able to predict and control the workings of fuel combustion systems in real time. Unlike Deng, who came to AI through the slings and arrows of outrageous fortune, Zachary Cordero, an associate professor of aero-astro, began using AI thanks to a colleague’s expertise. In 2024 John Hart, head of the Department of Mechanical Engineering, suggested that Cordero, who develops novel materials and structures for emerging aerospace applications, meet with Faez Ahmed, an associate professor of mechanical engineering and an expert in machine learning and optimization for engineering design. Cordero says he hadn’t previously been pursuing AI-related research: “This is all totally new to me.” Working with Ahmed and other collaborators on a project sponsored by the US Defense Advanced Research Projects Agency (DARPA), Cordero developed an AI tool that can optimize the material composition of what’s known as a blisk—a bladed disk that’s a key component in jet and rocket turbine engines. Their work aims to improve engine performance and longevity and could lead to more reliable reusable rocket engines for heavy-lift launch vehicles. Cordero says the AI system augmented human intuition—even “on problems where it’s almost impossible to have intuition.” Professor Ju Li posits that if AI is given autonomy to do experiments, to try different things and fail and learn from that, it could evolve into something very similar to human intelligence. Stories like these abound at MIT. In every department, in almost every lab on campus, AI technologies such as machine learning, large language models, and neural networks are transforming research—turbocharging existing methods, opening previously unexplored or inaccessible pathways, and creating novel opportunities in drug development, computing, energy technologies, manufacturing, robotics, neuroscience, metallurgy, and even wildlife preservation. “I cannot think of a single group meeting that we have where we’re not talking about these tools,” says Angela Koehler, the Charles W. and Jennifer C. Johnson Professor of Biological Engineering and faculty lead of the MIT Health and Life Sciences Collaborative (MIT HEALS). Her research group uses AI models to develop drug candidates designed to attach to molecular targets previously considered “undruggable,” such as transcription factors, RNA-binding proteins, or cytokines. “I would say 90% of the thesis committees I’m on involve a significant AI component,” she says. “And that definitely was not the case five years ago.” “Artificial intelligence is everywhere on campus,” says Ian Waitz, MIT’s vice president for research and the Jerome C. Hunsaker Professor of Aero-Astro. “Any field with a tremendous amount of complexity will benefit from it. Life sciences. Materials science. Anyone who does any kind of image analysis uses these tools now. I don’t know of a single research field here at MIT that hasn’t been impacted by AI.”
AI isn’t exactly new at MIT Though Deng and Cordero may have come to it through happenstance or clever matchmaking, most developments in AI at MIT don’t arise that way. Nor is the interest in it new. More than 70 years ago, in 1954, computer researcher Belmont G. Farley and physicist Wesley A. Clark ran the world’s first computer simulation of a neural network at MIT. Interest in neural network technology—now better known as deep learning—waxed and waned over the next decades. Ju Li, PhD ’00, the Carl Richard Soderberg Professor of Power Engineering (as well as a professor of nuclear science and engineering and materials science and engineering), remembers taking a course on neural networks during Independent Activities Period (IAP) in 1995, when he was a graduate student. “It was not a deep network—just a few layers,” recalls Li, who researches materials used in nuclear energy, batteries, electrolyzers, and energy-efficient computing. He characterizes it as essentially a regression tool that they used to fit curves. But over the past few years, activity in AI has exploded globally, fueled by powerful new models and an enormous increase in the computing power of chips; the resulting proliferation and evolution of data centers has in turn sparked more activity. Today, neural networks can have more than a thousand layers. Backed by massive investments in AI in both the public and private spheres, AI researchers have created a suite of tools that can scan almost immeasurable quantities and types of data; interface with sensors, robotics, and other mechanical devices; and communicate with human researchers in natural language.
RACHEL WU VIA MIT NEWS OFFICE “Many of the tools that we developed in the lab— they’re very broadly used in the pharmaceutical industry. And they’re really making significant impact.” Regina Barzilay Regina Barzilay has been working on AI since she came to MIT in 2003. Today, she’s the School of Engineering Distinguished Professor for AI and Health and AI faculty lead of the MIT Abdul Latif Jameel Clinic for Machine Learning in Health. But she says that if anyone had told her even 10 years ago where the field would be now and what kinds of things she’d be working on, she “absolutely” wouldn’t have believed it. AI applications for drug discovery and development, one of Barzilay’s areas of expertise, have been particularly prolific and successful at MIT. Giovanni Traverso’s lab, for example, has used AI to design nanoparticles that can deliver RNA vaccines and other therapies more efficiently than previous systems. Researchers at CSAIL (the Computer Science & Artificial Intelligence Laboratory, where Barzilay is a principal investigator) have used AI models to explain how a narrow-spectrum antibiotic specifically targets harmful microbes in people with Crohn’s disease. The Jameel Clinic has helped build models that can predict which flu vaccine will be most effective in a given year. “Many of the tools that we developed in the lab—they’re very broadly used in the pharmaceutical industry,” she explains. “And they’re really making significant impact.” She says there’s not even a question anymore about whether they make a difference. They’ve become standard tools because they work every day. One such tool is Boltz, an open-source AI model developed by a group at the Jameel Clinic and initially released in November 2024 as Boltz-1. Inspired by DeepMind’s AlphaFold2—a model that earned Demis Hassabis and John Jumper the 2024 Nobel Prize in chemistry—Boltz-1 helps scientists predict the 3D structures of proteins and other biological molecules. The Jameel Clinic researchers soon followed up with Boltz-2, which in addition to predicting molecular structure can also predict affinity—the strength with which a protein binds with a small molecule. Assays to measure affinity, a vital measure in drug development, are among the most importantperformed in biology and chemistry labs. In October 2025, the Jameel Clinic released its latest iteration, BoltzGen—a generative AI model capable of designing custom proteins that could bind with a wide range of biomolecular targets. Molecular binders already play important roles in fields including therapeutics, diagnostics, and biotechnology. BoltzGen is the first advanced, large-scale model that considers every single atom in the potential new protein and every atom in its target molecule, providing greater accuracy. Hannes Stärk, the fourth-year PhD student at CSAIL who built BoltzGen, says the model works because it actually learns—drawing inferences from the data it is trained with and then producing novel ideas inspired by that data. With machine learning, you want the model to generalize from the data you use to train it, says Stärk, who created BoltzGen over seven months, often working up to 12 hours a day. “Because otherwise,” he says, “your solution is already in your training data.” Stärk has also assembled a network of over 30 scientists both within and beyond MIT to explore the design and applications of molecular binders for use in drug development, metabolomics, and structural biology as well as in treating cancer, autoimmune diseases, and genetic diseases. “It’s nice to have one model that can do all of this,” he says. Training across all these areas also makes the model better at generalizing. Beyond drug discovery As labs working in drug development continue to reap benefits from AI, other researchers across the Institute are busy applying existing AI tools or, more often, developing their own models for use in myriad disciplines and applications. A cross-disciplinary group involving the Department of Electrical Engineering and Computer Science (EECS), CSAIL, and Mass General Hospital has launched MultiverSeg, a tool that quickly annotates areas of interest in medical images and could help scientists develop new treatments and map disease progression. MIT researchers are also designing and running AI-directed automated laboratories to accelerate and refine the process of discovering new components for sustainable materials and solar panels. And Ahmed’s MechE group is developing AI models to do such things as help automakers design high-performance vehicles or determine whether a large shipping vessel can be considered seaworthy. Ahmed also teaches a course titled AI and Machine Learning for Engineering Design. First offered in 2021, it attracts not only mechanical, civil, and environmental engineers but students from aero-astro, Sloan, and more. MIT TECHNOLOGY REVIEW “The goal is to tap into diverse types of raw data and turn that into “something that helps us understand what is putting species at risk.” Sara Beery Meanwhile, Priya Donti, an assistant professor of EECS and a PI at the Laboratory for Information & Decision Systems (LIDS), has developed AI-enabled optimization approaches to help schedule power generation resources on power grids. The machine-learning tools her group builds will help utility operators respond to many inevitable grid issues. “The big challenge is that on a power grid, you need to maintain this exact balance between the amount of power you’re producing and putting into the grid and the amount that you’re taking out on the other side,” she explains. “When you have a lot of variation from solar, wind, and other sources of power whose output varies based on the weather, you have to coordinate the grid much more tightly in order to maintain that balance.” Information about the physics of how power grids work is embedded in Donti’s AI model, so it functions and reacts much as a real grid would. MIT researchers are even applying AI tools to explore and analyze the natural world. Sara Beery, an assistant professor of EECS who specializes in AI and decision-making, develops AI methods that discover and dig into ecological data collected by a wide range of remote sensing technologies to analyze and predict how species and ecosystems are changing around the globe. These technologies enable Beery and her colleagues to gather data on a far greater number of endangered species than ever before, and at an unprecedented scale. Historically, most ecological research has focused on collecting incredibly rich data about single species in really small regions, she says, but “we’ve realized that’s not sufficient.” Information gleaned from, say, a small part of one river ecosystem will not help us understand or prevent what she calls “the exponential increase in species extinction rates that we’re currently facing.” Already, Beery says, “we’re using multimodal AI to enable experts to quickly search massive repositories of image data, to discover data points that were previously very difficult to find.” But she says the goal is to be able to readily tap into diverse types of raw data—from satellite and bioacoustic sensor data to camera images and DNA—and “actually turn that into some sort of scientific insight, something that helps us understand what is putting species at risk.”
Mens et manus in AI While some MIT researchers have successfully used AI to help invent technologies ranging from novel cancer therapies to safer high-performance automobiles, others are also using machine learning and other AI tools to help determine whether these technologies perform as promised—or can be produced successfully and economically at scale. Connor Coley, SM ’16, PhD ’19, an associate professor of chemical engineering and EECS, designs new molecules—and recipes for making new molecules, primarily small organic molecules—for potential use by pharmaceutical, agricultural, and other chemical companies. Coley, a former MIT Technology Review Innovators Under 35 honoree, has developed a “genetic” algorithm that uses biologically inspired processes including selection and mutation. This tool encodes potential polymer blends drawn from a large database of polymers into what is effectively a digital chromosome, which the algorithm then improves to generate the most promising material combinations. Working at the intersection of chemistry and computer science, Coley believes AI could one day help his lab discover polymer blends that would lead to improved battery electrolytes and tailored nanoparticles for safer drug delivery. He and his lab also work to develop machine-learning tools that streamline the discovery and production processes. “If you want AI to be the brain behind some of the science you’re doing, you need the hands as well,” says Coley, who was one of the first MIT faculty members hired into the MIT Schwarzman College of Computing. He and his group have coupled a robotic liquid-handling platform with an optimization algorithm. In the project designed to look for optimal polymer blends, the autonomous system not only chooses which polymer solutions to test but also performs the physical testing. The system, which can generate and test 700 new polymer blends in a day, has identified one that performed 18% better than any of its components. Systems with a similar level of autonomy could also have a big impact on early-stage drug discovery. One effect, he observes, should be to reduce the time it takes to advance a drug from the lab into clinical trials. But the real question, he says, is “What might we be able to do that we just couldn’t do with any reasonable amount of resources previously?” Alexander Siemenn, PhD ’25, also uses AI both to search for new materials and to control robots that test the physical properties of those materials. For his doctoral thesis, Siemenn built from scratch a fully autonomous AI-driven robotic laboratory to discover and test sustainable high-performance materials for solar panels. The system incorporates computer vision, machine learning, and an optimization algorithm and runs 24 hours a day. “We are pairing conventional methods [of measurement] that have been almost entirely manual to this point with the AI methods,” says Siemenn. “The goal is to be able to not just improve their accuracy but also make them fast and autonomous.” Hits and near misses Institute labs are also encountering some of the first real borders of the brave new AI-enhanced world. Many researchers at MIT and elsewhere agree that most of the “low-hanging fruit” has already been collected. That includes AI’s contributions to managing massive data sets and accelerating existing discovery and testing processes, at times to near light speed. Beyond those immediate gains, though, results vary—even in drug development, which has seen some of the most spectacular achievements of AI. “There are some areas where you would assume we should be doing much better here and we are not,” observes Barzilay. “The reason we cannot cure neurodegenerative diseases like Alzheimer’s or very advanced cancer is because we don’t really understand fully—on the molecular level—the disease itself, the drivers, and how to control it.” And AI still hasn’t made what she calls “a significant transformation” in terms of understanding those underlying disease mechanisms. “There are some helper tools,” she says, but AI hasn’t provided a profoundly new understanding of any disease—“So this is a place that we would hope to see more.” MIT TECHNOLOGY REVIEW “In AI, scaling is synergistic and good. In chemistry and materials, scaling is kind of a scary beast that you need to beat in order to make an impact.” Rafael Gómez-Bombarelli Limits in materials science are also emerging, particularly in translating digital solutions proposed by AI into objects made of atoms and molecules. Rafael Gómez-Bombarelli, an associate professor of materials science and engineering, develops physics-based machine-learning simulations to accelerate the discovery cycle for sustainable polymers and materials for use in energy, health care, and batteries. While physics-based simulations in themselves have been an unmitigated success, he says, results have been spottier when it comes to manufacturing the materials themselves; many of the solutions generated by these simulators fail in the physical world. “It turns out these simulators don’t capture lots of things that are important,” he says. “They operate on the atomically resolved problems for nanosecond-timescale questions. But many, many [materials] problems don’t happen in nanoseconds, don’t involve just a few ten thousands of atoms.” And they often involve physics more complicated than current AI models account for. What’s more, when the goal might be to produce millions of tons of a new material, scaling errors can be disastrous. “In AI, scaling is synergistic and good,” Gómez-Bombarelli says. “In chemistry and materials, scaling is kind of a scary beast that you need to beat in order to make an impact.”
New methods, new insights While AI has already produced myriad results and surprises, researchers at MIT believe much of its potential is still waiting to be discovered. And they are eager to search for high-impact applications. Ila Fiete, a professor of brain and cognitive sciences, builds AI tools and mathematical models to expand our knowledge of how the brain develops and reshapes its neural connections. Her work, she believes, can help us understand how we form memories or perceive ourselves in space—and that, in turn, can lead to improvements in AI. Many features of AI, including parallel computing in neural networks, were inspired by the human brain. “AI has [helped] and will continue to help us do more science and better science,” she says. “But neuroscientists believe there is a lot about how humans and other biological intelligences learn and solve problems that is better in some dimensions than current AI models. And by learning better how that works, we can actually inform better AI architectures.” Li agrees that certain elements of human intelligence and learning could benefit AI and help it solve some of our world’s most pressing and complex problems, including global poverty and climate change. “Large language models today have read tens of millions of papers and books,” he says, adding that they are “much more interdisciplinary than any of us.” Yet he notes that scientific literature is strongly biased toward success. “The day-to-day experience in the lab is 95% frustration, and I think it’s the failure cases which build character,” he says. He posits that if AI is given autonomy to do experiments, to try different things and fail and learn from that, it could evolve into something very similar to human intelligence. Researchers at MIT believe that as AI continues to evolve, expand, and proliferate, the Institute has a special duty to channel these technologies toward useful, attainable ends. “Right now, in the AI world there is a lot of hype and fluff,” says Ahmed, who is developing generative AI tools to help tackle complex engineering and design problems. “The digital world is overflowing with stuff,” he says, and there’s a lot happening on the AI front with images, text, and video. “But the physical world is still less affected, and we are seeing a lot more happening at the intersection of physical and AI at MIT.” AI’s future includes potential triumphs and potential pitfalls. Researchers still worry about “hallucinations”—results spit out of AI models that make no sense in the real world. They worry, as well, that some practitioners will rely too heavily on AI tools, omitting key insights and safeguards that keep an experiment or production facility on track. And they worry about overpromising—unrealistically presenting AI as a magical solution to all problems great and small. “It’s impossible to predict how good these models are going to get,” says MechE’s Hart. “Where they are going to shine and where they are going to limit.” But instead of sensing danger, Hart sees opportunity, especially at MIT: “We have the learned expertise and experience that allows us to frame the right questions and use these tools in the right way.” The challenge for the MITs of the world, he says, is to figure out how to use AI tools to create faster, better solutions and navigate more complex problems than we ever could before.
Caring for service dogs
Brenda Schafer Kennedy, SM ’93, knows that sometimes the best medicine comes with four legs and fur. Kennedy is the chief veterinary and research officer for Canine Companions, a California-based, nationwide organization that provides assistance dogs at no cost to children, veterans, and adults with disabilities. “The need is enormous: One in four people in the US has a disability. We have so many people who could benefit from these dogs,” Kennedy says. While service dogs might be best known for guiding the blind, Canine Companions trains dogs to do such things as open doors for wheelchair users or alert deaf people to doorbells, fire alarms, and other key sounds. Its psychiatric service dogs help veterans suffering from post-traumatic stress disorder—waking them from nightmares, for example. To date, it’s paired more than 7,000 dogs with people in need. It’s critical to ensure that every service dog placed is healthy, and Kennedy—a veterinarian—spearheads the organization’s efforts to breed dogs with that in mind. “We wouldn’t place a dog that might have a life-shortening or a significant medical issue that a person might have to manage,” she says.
Kennedy also takes the lead in developing tech to support Canine Companions’ work. She is a co-inventor of CanineAlert, a patented device that sends a signal to a dog’s collar so the dog can interrupt a nightmare when its owner’s heart rate spikes. The technology may soon expand to address daytime anxiety episodes. “These dogs can really be not only life-transforming in terms of providing people with independence, but critically essential and even life-saving,” she says.
An animal lover since childhood, Kennedy earned her undergraduate degree from Northwestern University before coming to MIT for her master’s in biology. “I found incredible mentors at MIT,” she says, noting that she particularly enjoyed working with Professor Hazel Sive, whose lab studied African clawed frogs. The research was fascinating, but Kennedy wanted to work in hands-on medicine, so she obtained her veterinary degree from Tufts University. She then spent 16 years in private practice. Today, she is delighted to combine animal care with research at Canine Companions. “I had a passion for doing something really mission-oriented,” she says. “I love the idea of helping people through the human-canine bond.” In additional to providing service, dogs also offer something elemental, Kennedy says: “Dogs add unconditional love to the mix. They support emotional and mental health for people and can be bridges to the community.”
The new word in home construction could be “plastics”
Single-use plastics are a persistent source of environmental pollution, and the need to house a growing global population puts increasing pressure on resources such as timber. MIT engineers have an idea that could make a dent in both problems at once. In a recent study, a team led by mechanical engineering professor David Hardt, SM ’74, PhD ’79, and lecturer and research scientist AJ Perez ’13, MEng ’14, PhD ’23, laid out a plan for using recycled plastic to 3D-print construction-grade beams, trusses, and other structures that could one day offer lighter, more sustainable alternatives to traditional wood-based framing. Although some companies are working on using large-scale additive manufacturing to create walls, they’re mainly using concrete or clay, whose production typically has a large negative environmental impact. These engineers are among the first to explore printing structural framing elements—and to do so using recycled plastic. The design they came up with is similar in shape to the traditional wooden trusses that support flooring, with beams that connect in a pattern resembling a ladder with diagonal rungs. To test it, they obtained pellets made of recycled PET polymers and glass fibers from an aerospace materials company and fed them into a room-size 3D printer as “ink.” When they printed four long trusses with this material and configured them into a conventional plywood-topped floor frame, the result had a load-bearing capacity of over 4,000 pounds, far exceeding key building standards set by the US Department of Housing and Urban Development. The plastic-printed trusses weigh about 13 pounds each, light enough to transport without a flatbed truck. An industrial printer can crank one out in under 13 minutes. Crucially, the researchers are developing the process to work with “dirty” plastic that hasn’t been cleaned or preprocessed. In addition to floor trusses, they are working on printing other elements and combining them into a full frame for a modest-size house.
“We’ve estimated that the world needs about 1 billion new homes by 2050. If we try to make that many homes using wood, we would need to clear-cut the equivalent of the Amazon rainforest three times over,” says Perez. “The key here is: We recycle dirty plastic into building products for homes that are lighter, more durable, and sustainable.” The researchers envision that one day, trash like used bottles and food containers could be sent directly into a shredder, turned into pellets, and fed into a large-scale additive manufacturing machine to become structural composite construction components. At the construction site, the elements could be quickly fitted into a lightweight yet sturdy home frame. “The idea is to bring shipping containers close to where you know you’ll have a lot of plastic, like next to a football stadium,” Perez says. “Then you could use off-the-shelf shredding technology and feed that dirty shredded plastic into a large-scale additive manufacturing system, which could exist in micro-factories, just like bottling centers, around the world. You could print the parts for entire buildings that would be light enough to transport on a moped or pickup truck to where homes are most needed.”
A natural protein may protect the GI tract from infection
Embedded in the body’s mucosal surfaces, proteins called lectins bind to sugars found on cell surfaces. A team led by MIT chemistry professor Laura Kiessling has found that one such protein, intelectin-2, both helps fortify the mucosal barrier and offers broad-spectrum protection against harmful bacteria found in the GI tract. Intelectin-2 binds to a sugar molecule called galactose that is found on bacterial membranes, the team found, trapping the bacteria and hindering their growth; the trapped microbes eventually disintegrate, suggesting that the protein is able to kill them by disrupting their cell membranes. It also helps strengthen the intestine’s protective lining by binding to the galactose in the mucins that make up mucus. “What’s remarkable is that intelectin-2 operates in two complementary ways. It helps stabilize the mucus layer, and if that barrier is compromised, it can directly neutralize or restrain bacteria that begin to escape,” says Kiessling, who conducted the study with colleagues including Amanda Dugan, a former MIT postdoc and research scientist, and Deepsing Syangtan, PhD ’24. Because intelectin-2 can neutralize or eliminate pathogens such as Staphylococcus aureus and Klebsiella pneumoniae, which are often difficult to treat with antibiotics, it could someday be adapted as an antimicrobial agent, the researchers say. Restoring desirable levels of intelectin-2 could also help people with disorders such as inflammatory bowel disease, who may have either too little of it (potentially weakening the mucus barrier) or too much (killing off beneficial gut bacteria). “Harnessing human lectins as tools to combat antimicrobial resistance opens up a fundamentally new strategy that draws on our own innate immune defenses,” Kiessling says. “Taking advantage of proteins that the body already uses to protect itself against pathogens is compelling and a direction that we are pursuing.”
Inventor recalls eye imaging breakthrough
If you’ve been to an eye doctor and had an image taken of the inside of your eye, chances are good it was done with optical coherence tomography (OCT)—a technology invented by clinician-scientist David Huang ’85, SM ’89, PhD ’93, and now used in 40 million procedures per year. OCT is a noninvasive technique used to produce detailed images of complicated biological tissues such as the retina and the plaques that can build up in coronary arteries. It maps the time-of-flight of light waves reflected from tissue and paints a high-resolution picture of internal structures. “It uses infrared light that’s barely visible compared to the bright flash of fundus photography [another common method of eye imaging] and provides a lot more information—three-dimensional rather than two-dimensional information—at higher resolution,” Huang says. The discovery earned him and his co-inventors slots in the National Inventors Hall of Fame in 2025 as well as the Lasker Award and the National Medals of Technology and Innovation in 2023. Huang didn’t expect to change the paradigm of eye imaging when he began studying electrical engineering as an undergraduate at MIT, but he was interested in using an engineering mindset to contribute to medical advancements. That, he thought, could be his way to follow in the footsteps of his father, who was a family practitioner.
OCT emerged from his work as an MD-PhD student in the Harvard-MIT Program in Health Sciences and Technology. While studying ultrafast lasers at MIT under James Fujimoto ’79, SM ’81, PhD ’84, the Elihu Thomson Professor of Electrical Engineering, Huang was tasked with using the lasers to improve various ophthalmological tasks, including measuring the thickness of the cornea and retina. Huang thought an approach known as interferometry, which could measure the time of flight down to one quadrillionth of a second, could improve thickness measurements to micrometer resolution. Huang’s experiments revealed that the technique was able to detect very faint signals arising from fine internal structures within the retina. Fujimoto and Huang realized the potential for inventing a new type of imaging and enlisted the help of Eric Swanson, SM ’84, who was using interferometry for intersatellite communications at Lincoln Laboratory, to develop an OCT machine for biological applications. Huang tested the new machine on several types of tissues accessed through Harvard Medical School and found it particularly successful in imaging retinal and coronary artery samples. He and his colleagues published their initial findings in Science in 1991, establishing OCT as a new imaging modality.
“Because of our ability to form collaborations with medical doctors and the more advanced technologies that were easily accessible at Lincoln Lab and MIT, we were able to make this new imaging technology take off when other people who were exploring around the same area were not able to demonstrate imaging results,” he says. After the groundbreaking invention, Huang finished his academic and medical training as an ophthalmologist while Fujimoto and Swanson formed a startup company to ensure that the device got into medical offices. Over the next decades, Huang has continued to refine OCT for various applications. Today, as the director of research at Oregon Health and Science University’s Casey Eye Institute, he leads research groups exploring new ways to use OCT in techniques such as OCT angiography (imaging blood flow down to the capillary level) and OCT optoretinography (mapping the light response in retinal photoreceptor cells). In addition to conducting research, he also sees patients and is the cofounder of GoCheck Kids, a digital platform for pediatric eye screening. Huang credits his knack for innovation to his position at the nexus of diverse fields. “It’s hard for a pure medical doctor or a pure laser engineer to realize that there is an opportunity to invent a new device that solves a real problem in the clinic,” he says. “But it’s really easy when you have knowledge on both sides.”

Energy Department Awards New Contracts from Strategic Petroleum Reserve, Advancing Emergency Exchange
WASHINGTON—The U.S. Department of Energy’s (DOE) Hydrocarbons and Geothermal Energy Office (HGEO) today announced awards of contracts to exchange 26 million barrels of crude oil from the Strategic Petroleum Reserve (SPR) at the West Hackberry site, marking the next phase of DOE’s execution of the United States’ 172-million-barrel contribution to the International Energy Agency’s collective action to stabilize global oil supply. These awards follow DOE’s recent Request for Proposal (RFP) for this portion of the emergency exchange, with deliveries beginning immediately as the Department continues to move quickly to address short-term supply disruptions and strengthen energy security for the United States. “Through this emergency exchange, the Department is taking swift action to support near‑term supply needs while strengthening the Strategic Petroleum Reserve for the long term,” said Kyle Haustveit, Assistant Secretary of the Hydrocarbons and Geothermal Energy Office. “By returning additional premium barrels at no cost to taxpayers, this exchange reinforces market reliability today and delivers meaningful value to the American people when those barrels are returned.” Under these awards, DOE will move forward with an exchange of 26 million barrels of crude oil, which will be returned with additional premium barrels by next year—supporting energy security and delivering value for the American people at no cost to taxpayers. This action builds on earlier exchange actions, which have already awarded approximately 55 million barrels from the Bayou Choctaw, Bryan Mound, and West Hackberry sites, demonstrating the reserve’s ability to deliver crude efficiently under emergency conditions. To date, more than 10 million barrels have already been delivered to market. The exchange also allows participating companies to take advantage of the President’s limited Jones Act waiver, helping accelerate critical near-term oil flows into the market. Companies can begin scheduling deliveries immediately. DOE will continue to evaluate market conditions and operational capacity as it advances

Apply Now: 2026 Waste to Energy and Materials Technical Assistance for State, Local, and Tribal Governments
The U.S. Department of Energy’s Alternative Fuels and Feedstocks Office (AFFO), formerly known as the Bioenergy Technologies Office, and the National Laboratory of the Rockies (NLR) are launching the 2026 Waste to Energy and Materials Technical Assistance Program for state, local, and Tribal governments. The scope of this year’s program has been expanded to include additional municipal solid waste materials such as electronics, industrial wastewater, and other byproducts. U.S. waste streams present significant logistical and economic challenges for states, counties, municipalities, and Tribal governments. However, waste is also a resource that can be used as an unconventional additional source of energy, advanced materials, and critical minerals. This program provides no-cost technical assistance to states, counties, municipalities, and Tribal governments with the most relevant data to guide decision-making—providing local solutions to the various aspects of waste management, taking into consideration current handling practices, costs, and infrastructure. It is designed to help officials evaluate the most sensible end uses for their waste, whether repurposing it for on-site heat and power, upgrading it into transportation fuels, or using it for material and mineral recovery. Program technical assistance includes: Waste resource information Infrastructure considerations Techno-economic comparison of energy, material, and mineral recovery options Evaluation and sharing of case studies (to the extent possible) from similar communities/projects The 2026 Waste to Energy and Materials Technical Assistance application portal is now open and applications will be accepted through May 30, 2026. For information on applicant eligibility and how to apply, please visit NLR’s technical assistance webpage. Timeline for Technical Assistance Opportunity Date Action April 15, 2026 Application Portal Opens May 30, 2026 Application Portal Closes July – August 2026 Selections Made and Recipients Informed Learn more about AFFO-supported waste to energy and materials technical assistance. If you have further questions, please see frequently asked questions or contact the Waste to

Energy Deputy Secretary Danly Commends FERC Action on Large Load Interconnection Reform
WASHINGTON—U.S. Deputy Secretary of Energy James P. Danly issued the following statement after the Federal Energy Regulatory Commission (FERC or Commission) announced it will take action by June 2026 on the large load interconnection proceeding initiated at the direction of U.S. Secretary of Energy Chris Wright: “FERC’s announcement today demonstrates Chairman Swett’s commitment to implement Secretary Wright’s directive that the Commission ensure the timely and orderly integration of large electric loads that deliver on President Trump’s goal of American energy dominance. “I expect that the Commission will act quickly and decisively to improve interconnection processes, support the co-location of load and generation, and accelerate the addition of new generation to ensure that supply is built alongside demand—delivering affordable, reliable, and secure energy for all Americans. “Having served at FERC as commissioner and chairman, I understand FERC’s role in ensuring the reliability of the nation’s bulk power system, and I commend Chairman Swett for focusing on affordability and reliability.” ###
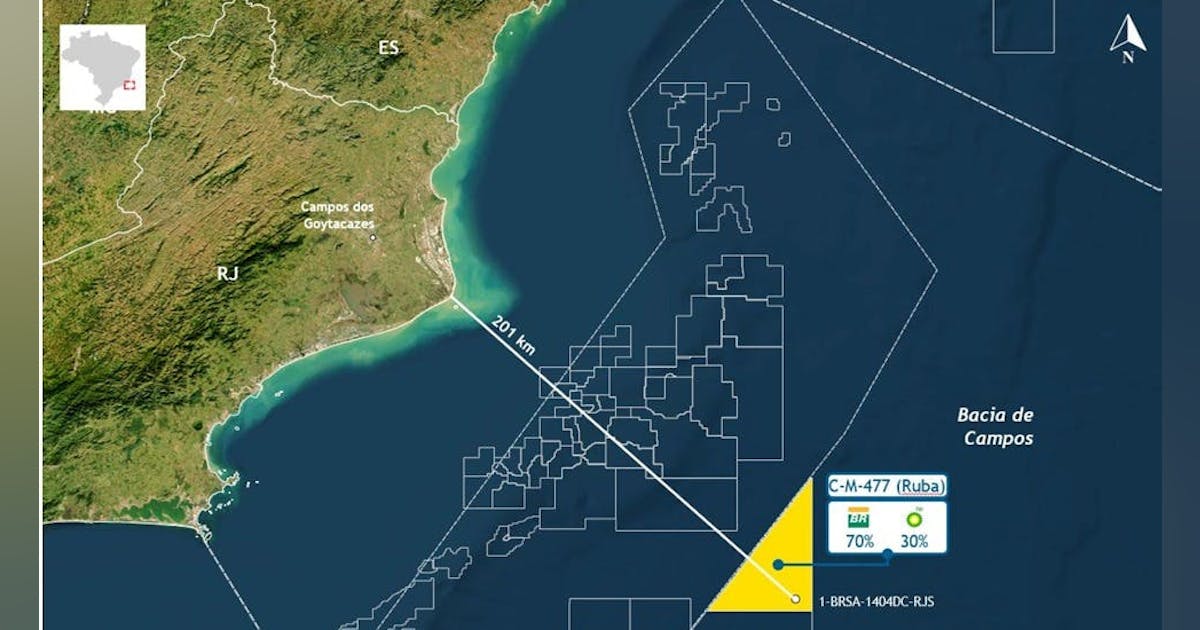
Petrobras discovers hydrocarbons in Campos basin presalt offshore Brazil
@import url(‘https://fonts.googleapis.com/css2?family=Inter:[email protected]&display=swap’); .ebm-page__main h1, .ebm-page__main h2, .ebm-page__main h3, .ebm-page__main h4, .ebm-page__main h5, .ebm-page__main h6 { font-family: Inter; } body { line-height: 150%; letter-spacing: 0.025em; } button, .ebm-button-wrapper { font-family: Inter; } .label-style { text-transform: uppercase; color: var(–color-grey); font-weight: 600; font-size: 0.75rem; } .caption-style { font-size: 0.75rem; opacity: .6; } #onetrust-pc-sdk [id*=btn-handler], #onetrust-pc-sdk [class*=btn-handler] { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-policy a, #onetrust-pc-sdk a, #ot-pc-content a { color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-pc-sdk .ot-active-menu { border-color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-accept-btn-handler, #onetrust-banner-sdk #onetrust-reject-all-handler, #onetrust-consent-sdk #onetrust-pc-btn-handler.cookie-setting-link { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-consent-sdk .onetrust-pc-btn-handler { color: #c19a06 !important; border-color: #c19a06 !important; } Petrobras has discovered presence in the Campos basin presalt offshore Brazil during exploration in sector SC-AP4, block CM-477. Samples taken from the well, 1-BRSA-1404DC-RJS, will be sent for laboratory analysis with the aim of characterizing the conditions of the reservoirs and fluids found to enable continued evaluation of the area’s potential, the company said in a release Apr. 13. The discovery well was drilled 201 km off the coast of the state of Rio de Janeiro in water depth of 2,984 m. The hydrocarbon-bearing interval was confirmed through electrical profiles, gas evidence, and fluid sampling. Petrobras is the operator of block CM-477 with 70% interest. bp plc holds the remaining 30%.
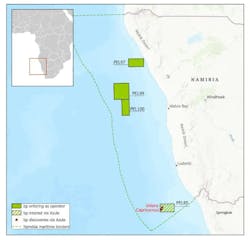
bp to operate blocks offshore Namibia through acquisition
@import url(‘https://fonts.googleapis.com/css2?family=Inter:[email protected]&display=swap’); .ebm-page__main h1, .ebm-page__main h2, .ebm-page__main h3, .ebm-page__main h4, .ebm-page__main h5, .ebm-page__main h6 { font-family: Inter; } body { line-height: 150%; letter-spacing: 0.025em; } button, .ebm-button-wrapper { font-family: Inter; } .label-style { text-transform: uppercase; color: var(–color-grey); font-weight: 600; font-size: 0.75rem; } .caption-style { font-size: 0.75rem; opacity: .6; } #onetrust-pc-sdk [id*=btn-handler], #onetrust-pc-sdk [class*=btn-handler] { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-policy a, #onetrust-pc-sdk a, #ot-pc-content a { color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-pc-sdk .ot-active-menu { border-color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-accept-btn-handler, #onetrust-banner-sdk #onetrust-reject-all-handler, #onetrust-consent-sdk #onetrust-pc-btn-handler.cookie-setting-link { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-consent-sdk .onetrust-pc-btn-handler { color: #c19a06 !important; border-color: #c19a06 !important; } Map from bp plc <!–> –> bp plc aims to become operator of three exploration blocks offshore Namibia through acquisition of a 60% interest from Eco Atlantic Oil & Gas. Subject to Namibian government and joint venture partner approvals, bp will operate blocks PEL97, PEL99, and PEL100 in Walvis basin. In a release Apr. 13, bp said entering the blocks builds on its recent exploration successes in Namibia through Azule Energy, a 50-50 joint venture between bp and Eni. Eco Atlantic will remain a partner, along with Namibia’s national oil company NAMCOR, following the deal’s closing, which is subject to closing conditions.

ConocoPhillips sends team to Venezuela to evaluate oil, gas opportunities
ConocoPhillips sent a team to Venezuela to evaluate oil and gas opportunities, the company confirmed to Oil & Gas Journal Apr. 13. In an email to OGJ, a company spokesperson said “ConocoPhillips can confirm that we sent a small evaluation team to Venezuela during the week of Apr. 6 to better understand the potential for in-country oil and gas opportunities.” Asked what clarity the company seeks, the spokesperson said the team “will evaluate Venezuela against other international opportunities as part of our disciplined investment framework.” The operator left Venezuela in 2007 after then-President Hugo Chavez’s government reverted privately run oil fields to state control. ConocoPhillips, along with ExxonMobil, refused the government’s terms and took claims to the World Bank’s International Centre for the Settlement of Investment Disputes (ICSID). ConocoPhillips is owed about $12 billion following two judgements, an amount still sought by the company, which, prior to the expropriation of its interests, held a 50.1% interest in Petrozuata, a 40% interest in Hamaca, and a 32.5% interest in Corocoro heavy oil projects in Venezuela. In January, following the removal of Venezuela’s leader Nicolas Maduro, US President Donald Trump urged oil and gas companies to spend billions to rebuild Venezuela’s energy sector. ExxonMobil, which also exited the country in 2007, sent a technical team to Venezuela in March to evaluate the infrastructure and investment opportunities. In a discussion at CERAWeek by S&P Global in Houston in March, ConocoPhillips’ chief executive officer, Ryan Lance, said Venezuela needs to “completely rewire” its fiscal system to attract new investment. The South American country holds a large cache of proven oil reserves, but has faced decades of production challenges due to mismanagement, underinvestment, and sanctions.

Microsoft will invest $80B in AI data centers in fiscal 2025
And Microsoft isn’t the only one that is ramping up its investments into AI-enabled data centers. Rival cloud service providers are all investing in either upgrading or opening new data centers to capture a larger chunk of business from developers and users of large language models (LLMs). In a report published in October 2024, Bloomberg Intelligence estimated that demand for generative AI would push Microsoft, AWS, Google, Oracle, Meta, and Apple would between them devote $200 billion to capex in 2025, up from $110 billion in 2023. Microsoft is one of the biggest spenders, followed closely by Google and AWS, Bloomberg Intelligence said. Its estimate of Microsoft’s capital spending on AI, at $62.4 billion for calendar 2025, is lower than Smith’s claim that the company will invest $80 billion in the fiscal year to June 30, 2025. Both figures, though, are way higher than Microsoft’s 2020 capital expenditure of “just” $17.6 billion. The majority of the increased spending is tied to cloud services and the expansion of AI infrastructure needed to provide compute capacity for OpenAI workloads. Separately, last October Amazon CEO Andy Jassy said his company planned total capex spend of $75 billion in 2024 and even more in 2025, with much of it going to AWS, its cloud computing division.

John Deere unveils more autonomous farm machines to address skill labor shortage
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More Self-driving tractors might be the path to self-driving cars. John Deere has revealed a new line of autonomous machines and tech across agriculture, construction and commercial landscaping. The Moline, Illinois-based John Deere has been in business for 187 years, yet it’s been a regular as a non-tech company showing off technology at the big tech trade show in Las Vegas and is back at CES 2025 with more autonomous tractors and other vehicles. This is not something we usually cover, but John Deere has a lot of data that is interesting in the big picture of tech. The message from the company is that there aren’t enough skilled farm laborers to do the work that its customers need. It’s been a challenge for most of the last two decades, said Jahmy Hindman, CTO at John Deere, in a briefing. Much of the tech will come this fall and after that. He noted that the average farmer in the U.S. is over 58 and works 12 to 18 hours a day to grow food for us. And he said the American Farm Bureau Federation estimates there are roughly 2.4 million farm jobs that need to be filled annually; and the agricultural work force continues to shrink. (This is my hint to the anti-immigration crowd). John Deere’s autonomous 9RX Tractor. Farmers can oversee it using an app. While each of these industries experiences their own set of challenges, a commonality across all is skilled labor availability. In construction, about 80% percent of contractors struggle to find skilled labor. And in commercial landscaping, 86% of landscaping business owners can’t find labor to fill open positions, he said. “They have to figure out how to do

2025 playbook for enterprise AI success, from agents to evals
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More 2025 is poised to be a pivotal year for enterprise AI. The past year has seen rapid innovation, and this year will see the same. This has made it more critical than ever to revisit your AI strategy to stay competitive and create value for your customers. From scaling AI agents to optimizing costs, here are the five critical areas enterprises should prioritize for their AI strategy this year. 1. Agents: the next generation of automation AI agents are no longer theoretical. In 2025, they’re indispensable tools for enterprises looking to streamline operations and enhance customer interactions. Unlike traditional software, agents powered by large language models (LLMs) can make nuanced decisions, navigate complex multi-step tasks, and integrate seamlessly with tools and APIs. At the start of 2024, agents were not ready for prime time, making frustrating mistakes like hallucinating URLs. They started getting better as frontier large language models themselves improved. “Let me put it this way,” said Sam Witteveen, cofounder of Red Dragon, a company that develops agents for companies, and that recently reviewed the 48 agents it built last year. “Interestingly, the ones that we built at the start of the year, a lot of those worked way better at the end of the year just because the models got better.” Witteveen shared this in the video podcast we filmed to discuss these five big trends in detail. Models are getting better and hallucinating less, and they’re also being trained to do agentic tasks. Another feature that the model providers are researching is a way to use the LLM as a judge, and as models get cheaper (something we’ll cover below), companies can use three or more models to
OpenAI’s red teaming innovations define new essentials for security leaders in the AI era
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More OpenAI has taken a more aggressive approach to red teaming than its AI competitors, demonstrating its security teams’ advanced capabilities in two areas: multi-step reinforcement and external red teaming. OpenAI recently released two papers that set a new competitive standard for improving the quality, reliability and safety of AI models in these two techniques and more. The first paper, “OpenAI’s Approach to External Red Teaming for AI Models and Systems,” reports that specialized teams outside the company have proven effective in uncovering vulnerabilities that might otherwise have made it into a released model because in-house testing techniques may have missed them. In the second paper, “Diverse and Effective Red Teaming with Auto-Generated Rewards and Multi-Step Reinforcement Learning,” OpenAI introduces an automated framework that relies on iterative reinforcement learning to generate a broad spectrum of novel, wide-ranging attacks. Going all-in on red teaming pays practical, competitive dividends It’s encouraging to see competitive intensity in red teaming growing among AI companies. When Anthropic released its AI red team guidelines in June of last year, it joined AI providers including Google, Microsoft, Nvidia, OpenAI, and even the U.S.’s National Institute of Standards and Technology (NIST), which all had released red teaming frameworks. Investing heavily in red teaming yields tangible benefits for security leaders in any organization. OpenAI’s paper on external red teaming provides a detailed analysis of how the company strives to create specialized external teams that include cybersecurity and subject matter experts. The goal is to see if knowledgeable external teams can defeat models’ security perimeters and find gaps in their security, biases and controls that prompt-based testing couldn’t find. What makes OpenAI’s recent papers noteworthy is how well they define using human-in-the-middle

Three Aberdeen oil company headquarters sell for £45m
Three Aberdeen oil company headquarters have been sold in a deal worth £45 million. The CNOOC, Apache and Taqa buildings at the Prime Four business park in Kingswells have been acquired by EEH Ventures. The trio of buildings, totalling 275,000 sq ft, were previously owned by Canadian firm BMO. The financial services powerhouse first bought the buildings in 2014 but took the decision to sell the buildings as part of a “long-standing strategy to reduce their office exposure across the UK”. The deal was the largest to take place throughout Scotland during the last quarter of 2024. Trio of buildings snapped up London headquartered EEH Ventures was founded in 2013 and owns a number of residential, offices, shopping centres and hotels throughout the UK. All three Kingswells-based buildings were pre-let, designed and constructed by Aberdeen property developer Drum in 2012 on a 15-year lease. © Supplied by CBREThe Aberdeen headquarters of Taqa. Image: CBRE The North Sea headquarters of Middle-East oil firm Taqa has previously been described as “an amazing success story in the Granite City”. Taqa announced in 2023 that it intends to cease production from all of its UK North Sea platforms by the end of 2027. Meanwhile, Apache revealed at the end of last year it is planning to exit the North Sea by the end of 2029 blaming the windfall tax. The US firm first entered the North Sea in 2003 but will wrap up all of its UK operations by 2030. Aberdeen big deals The Prime Four acquisition wasn’t the biggest Granite City commercial property sale of 2024. American private equity firm Lone Star bought Union Square shopping centre from Hammerson for £111m. © ShutterstockAberdeen city centre. Hammerson, who also built the property, had originally been seeking £150m. BP’s North Sea headquarters in Stoneywood, Aberdeen, was also sold. Manchester-based

2025 ransomware predictions, trends, and how to prepare
Zscaler ThreatLabz research team has revealed critical insights and predictions on ransomware trends for 2025. The latest Ransomware Report uncovered a surge in sophisticated tactics and extortion attacks. As ransomware remains a key concern for CISOs and CIOs, the report sheds light on actionable strategies to mitigate risks. Top Ransomware Predictions for 2025: ● AI-Powered Social Engineering: In 2025, GenAI will fuel voice phishing (vishing) attacks. With the proliferation of GenAI-based tooling, initial access broker groups will increasingly leverage AI-generated voices; which sound more and more realistic by adopting local accents and dialects to enhance credibility and success rates. ● The Trifecta of Social Engineering Attacks: Vishing, Ransomware and Data Exfiltration. Additionally, sophisticated ransomware groups, like the Dark Angels, will continue the trend of low-volume, high-impact attacks; preferring to focus on an individual company, stealing vast amounts of data without encrypting files, and evading media and law enforcement scrutiny. ● Targeted Industries Under Siege: Manufacturing, healthcare, education, energy will remain primary targets, with no slowdown in attacks expected. ● New SEC Regulations Drive Increased Transparency: 2025 will see an uptick in reported ransomware attacks and payouts due to new, tighter SEC requirements mandating that public companies report material incidents within four business days. ● Ransomware Payouts Are on the Rise: In 2025 ransom demands will most likely increase due to an evolving ecosystem of cybercrime groups, specializing in designated attack tactics, and collaboration by these groups that have entered a sophisticated profit sharing model using Ransomware-as-a-Service. To combat damaging ransomware attacks, Zscaler ThreatLabz recommends the following strategies. ● Fighting AI with AI: As threat actors use AI to identify vulnerabilities, organizations must counter with AI-powered zero trust security systems that detect and mitigate new threats. ● Advantages of adopting a Zero Trust architecture: A Zero Trust cloud security platform stops
This tool could show how consciousness works
How does the physical matter in our brains translate into thoughts, sensations, and emotions? It’s hard to explore that question without neurosurgery. But in a recent paper, MIT philosopher Matthias Michel, Lincoln Lab researcher Daniel Freeman, and colleagues outline a strategy for doing so with an emerging tool called transcranial focused ultrasound. This noninvasive technology reaches deeper into the brain, with greater resolution, than techniques such as EEG and MRI. It works by sending acoustic waves through the skull to focus on an area of a few millimeters, allowing specific brain structures to be stimulated so the effects can be studied. The researchers lay out an experimental approach that would use the tool to help test two competing conceptions of consciousness. The “cognitivist” concept holds that brain activity generating conscious experience must involve higher-level processes such as reasoning or self-reflection, likely using the frontal cortex. The “non-cognitivist” idea is that specific patterns of neural activity—more localized in subcortical structures or at the back of the cortex—give rise to subjective experiences directly. “This is a tool that’s not just useful for medicine, or even basic science, but could also help address the hard problem of consciousness,” Freeman says. “It can probe where in the brain are the neural circuits that generate a sense of pain, a sense of vision, or even something as complex as human thought.”

Analog computing from waste heat
Heat generated by electronic devices is usually a problem, but a team led by Giuseppe Romano, a research scientist at MIT’s Institute for Soldier Nanotechnologies, has found a way to use it for data processing that doesn’t rely on electricity. In this analog computing method, input data is encoded not as binary 1s and 0s but as a set of temperatures based on the waste heat already present in a device. The flow and distribution of that heat through tiny silicon structures, designed by a physics-based optimization algorithm they developed, forms the basis of the calculation. Then the output is represented by the power collected at the other end. The researchers used these structures to perform a simple form of matrix vector multiplication, the fundamental mathematical technique machine-learning models like large language models use to process information and make predictions. The results were more than 99% accurate in many cases. The researchers still have to overcome many hurdles to scale up this computing method for modern deep-learning models, such as the challenges involved in tiling millions of these structures together. As the matrices become more complicated, the results also become less accurate, especially when there is a large distance between the input and output terminals. But the technique could also have a more immediate use: detecting problematic heat sources and measuring temperature changes in electronics without consuming extra energy. This would also eliminate the need for multiple temperature sensors that can currently take up space on a chip. “Most of the time, when you are performing computations in an electronic device, heat is the waste product,” says Caio Silva, an undergraduate student in the Department of Physics and lead author of a paper on the work. “You often want to get rid of as much heat as you can. But here, we’ve taken the opposite approach by using heat as a form of information itself.”

Early life may have breathed oxygen earlier than believed
Around 2.3 billion years ago, a pivotal period known as the Great Oxidation Event set the evolutionary course for oxygen-breathing life on Earth. But MIT geobiologists and colleagues have found evidence that some early forms of life evolved the ability to use oxygen hundreds of millions of years before that. By mapping enzyme sequences from several thousand modern organisms onto an evolutionary tree of life, the researchers traced the origins of an enzyme that enables organisms to use oxygen to the Mesoarchean period, 3.2 to 2.8 billion years ago. The team’s results may help explain a longstanding puzzle in Earth’s history: Given that the first oxygen-producing microbes likely emerged before the Mesoarchean, why didn’t oxygen build up in the atmosphere until hundreds of millions of years later? Having evolved the key enzyme, organisms living near those microbes, called cyanobacteria, may have gobbled up the small amounts of oxygen they produced. “This does dramatically change the story of aerobic respiration,” says Fatima Husain, SM ’18, PhD ’25, a research scientist in MIT’s Department of Earth, Atmospheric, and Planetary Sciences (EAPS) and a coauthor with Gregory Fournier, an associate professor of geobiology, of a paper on the research. “It shows us how incredibly innovative life is at all periods in Earth’s history.”

Recent books from the MIT community
Priority Technologies: Ensuring US Security and Shared ProsperityEdited by Elisabeth B. Reynolds, professor of the practice of urban studies and planning and former executive director of the MIT Task Force on the Work of the Future MIT PRESS, 2026, $24.95 The Shape of Wonder: How Scientists Think, Work, and LiveBy Alan Lightman, professor of the practice of the humanities, and Martin ReesPENGUIN RANDOM HOUSE, 2025, $28 Spheres of Injustice: The Ethical Promise of Minority Presence By Bruno Perreau, professor of French studies and language MIT PRESS, 2025, $34 The Analytics Edge in HealthcareBy Dimitris Bertsimas, SM ’87, PhD ’88, professor of management and operations research and associate dean of online education and AI; Agni Orfanoudaki, PhD ’21; and Holly Wiberg DYNAMIC IDEAS, 2025, $110
The Art of Monetary Policy: Lessons from Sun Tzu for Central BanksBy Kristin J. Forbes, PhD ’98, professor of management and global economicsMIT PRESS, 2026, $30 SuperShifts: Transforming How We Live, Learn, and Work in the Age of Intelligence By Ja-Naé Duane, academic research fellow at MIT’s Center for Information Systems Research, and Steve FisherWILEY, 2025, $28 Send book news to [email protected] or 196 Broadway, 3rd Floor Cambridge, MA 02139

Get ready for hotter, muggier, stormier summers
A long stretch of humid heat followed by a powerful thunderstorm is a familiar weather pattern in the tropics, but it’s also becoming more common in midlatitude regions such as the US Midwest. A recent study by two MIT scientists identifies a key atmospheric condition that determines how hot, humid, and stormy such a region can get: inversions, in which a layer of warm air settles over cooler air. Inversions were already known to act as an atmospheric blanket that traps pollutants at ground level. Now Funing Li, a postdoc in MIT’s Department of Earth, Atmospheric and Planetary Sciences (EAPS), and Talia Tamarin-Brodsky, an assistant professor of EAPS, have found that they also trap heat and moisture at the surface. The more persistent an inversion, the more heat and humidity a region can accumulate, which can lead to more oppressive, longer-lasting humid heat waves. And when an inversion eventually weakens, intense thunderstorms and heavy rainfall can be the result. In typical conditions, the atmosphere’s layers get colder with altitude, and a heat wave that warms the air at ground level will trigger convection: The warmer, lighter air will rise, prompting colder air to sink. When the warm air hits colder altitudes, it condenses into droplets that fall as rain, often cooling things down. Li and Tamarin-Brodsky found that when warm or light air has settled over colder or heavier ground-level air, more heat and moisture are needed for a given “parcel” of air to build up enough energy to rise through that inversion layer. The upper limit on how hot and humid it can get depends on how stable the inversion is. If a blanket of warm air parks over a region for a long time without moving, it allows more moisture and heat to build up, which also makes the eventual storm more intense when it finally happens.
Inversions often form at night, when surfaces that warmed during the day radiate heat to space so that the air in contact with them becomes cooler and denser than the air above. Or they can form when a shallow layer of cool marine air moves inland and slides beneath warmer air over the land. In some cases, however, persistent inversions can form when air heated over sun-warmed mountains is carried over low-lying regions. In the US, Li says, “the Great Plains and the Midwest have had many inversions historically due to the Rocky Mountains.” But global warming is likely to make the effect more pronounced. “Our analysis shows that the eastern and midwestern regions of the US and the eastern Asian regions may be new hot spots for humid heat,” he says. “As the climate warms, theoretically the atmosphere will be able to hold more moisture,” says Tamarin-Brodsky.And because inversions will likely intensify, “new regions in the midlatitudes could experience moist heat waves that will cause stress that they weren’t used to before.” She adds, “Our theory gives an understanding of the limit for humid heat and severe convection for these communities that will be future heat wave and thunderstorm hot spots.”
Inventor recalls eye imaging breakthrough
If you’ve been to an eye doctor and had an image taken of the inside of your eye, chances are good it was done with optical coherence tomography (OCT)—a technology invented by clinician-scientist David Huang ’85, SM ’89, PhD ’93, and now used in 40 million procedures per year. OCT is a noninvasive technique used to produce detailed images of complicated biological tissues such as the retina and the plaques that can build up in coronary arteries. It maps the time-of-flight of light waves reflected from tissue and paints a high-resolution picture of internal structures. “It uses infrared light that’s barely visible compared to the bright flash of fundus photography [another common method of eye imaging] and provides a lot more information—three-dimensional rather than two-dimensional information—at higher resolution,” Huang says. The discovery earned him and his co-inventors slots in the National Inventors Hall of Fame in 2025 as well as the Lasker Award and the National Medals of Technology and Innovation in 2023. Huang didn’t expect to change the paradigm of eye imaging when he began studying electrical engineering as an undergraduate at MIT, but he was interested in using an engineering mindset to contribute to medical advancements. That, he thought, could be his way to follow in the footsteps of his father, who was a family practitioner.
OCT emerged from his work as an MD-PhD student in the Harvard-MIT Program in Health Sciences and Technology. While studying ultrafast lasers at MIT under James Fujimoto ’79, SM ’81, PhD ’84, the Elihu Thomson Professor of Electrical Engineering, Huang was tasked with using the lasers to improve various ophthalmological tasks, including measuring the thickness of the cornea and retina. Huang thought an approach known as interferometry, which could measure the time of flight down to one quadrillionth of a second, could improve thickness measurements to micrometer resolution. Huang’s experiments revealed that the technique was able to detect very faint signals arising from fine internal structures within the retina. Fujimoto and Huang realized the potential for inventing a new type of imaging and enlisted the help of Eric Swanson, SM ’84, who was using interferometry for intersatellite communications at Lincoln Laboratory, to develop an OCT machine for biological applications. Huang tested the new machine on several types of tissues accessed through Harvard Medical School and found it particularly successful in imaging retinal and coronary artery samples. He and his colleagues published their initial findings in Science in 1991, establishing OCT as a new imaging modality.
“Because of our ability to form collaborations with medical doctors and the more advanced technologies that were easily accessible at Lincoln Lab and MIT, we were able to make this new imaging technology take off when other people who were exploring around the same area were not able to demonstrate imaging results,” he says. After the groundbreaking invention, Huang finished his academic and medical training as an ophthalmologist while Fujimoto and Swanson formed a startup company to ensure that the device got into medical offices. Over the next decades, Huang has continued to refine OCT for various applications. Today, as the director of research at Oregon Health and Science University’s Casey Eye Institute, he leads research groups exploring new ways to use OCT in techniques such as OCT angiography (imaging blood flow down to the capillary level) and OCT optoretinography (mapping the light response in retinal photoreceptor cells). In addition to conducting research, he also sees patients and is the cofounder of GoCheck Kids, a digital platform for pediatric eye screening. Huang credits his knack for innovation to his position at the nexus of diverse fields. “It’s hard for a pure medical doctor or a pure laser engineer to realize that there is an opportunity to invent a new device that solves a real problem in the clinic,” he says. “But it’s really easy when you have knowledge on both sides.”
SUSE bets automated migration can break VMware’s grip on virtualization
CSCS, part of Switzerland’s ETH domain of research organizations, receives government funding and must spend it wisely. “We could spend more money on VMware or on developing new technology,” Conciatore said. The organization chose the latter. CSCS Associate Director Dr. Maria Grazia Giuffreda told the SUSEcon audience that the shift has freed up engineering capacity. “Because of SUSE Virtualization, we reduced the amount of time managing infrastructure by 70%,” she said. “You are freeing the time of very excellent engineers to take on new challenges rather than routine and boring work.” Conciatore noted, however, that CSCS didn’t abandon VMware. “We’re not leaving completely,” he said. “The main thing is, we didn’t expand VMware in the last few years, and started buying alternatives.” The bigger picture For enterprises still weighing their options, the decision may come down to how deeply they are embedded in the VMware network, Nadkarni said. “It’s not just VMware, but the whole ecosystem of tools tied into the VMware way of doing things. That’s what Broadcom is exploiting.” CSCS had an advantage, Conciatore said: Its automation treated physical and virtual machines the same way, making it easier to decouple. Not every enterprise will have that flexibility. “SUSE is pushing this as a VMware alternative because they have something that works,” he said. “Currently, the fact that we are not vendor-locked is very important.”
AI at MIT
At MIT, AI has become so pervasive that you can almost find your way into it without meaning to. Take Sili Deng, an associate professor of mechanical engineering. Deng says she still doesn’t know whether she’d have gone all in on artificial intelligence had it not been for the covid pandemic. She had joined the faculty in 2019 and was in the process of setting up her lab to study combustion kinetics, emissions reduction, and flame synthesis of energy materials when covid hit, putting a halt to all lab renovations. Because she needed to start from scratch, she challenged herself and her postdocs to try machine learning “and see, with the fundamental knowledge we have on the combustion side, what are the gaps that we think machine learning could [fill].” Under her leadership, Deng’s Energy and Nanotechnology Group used AI to develop a “digital twin” that mirrors the performance of an energy/flow device—a digital replica of a physical system. Eventually, this model should be able to predict and control the workings of fuel combustion systems in real time. Unlike Deng, who came to AI through the slings and arrows of outrageous fortune, Zachary Cordero, an associate professor of aero-astro, began using AI thanks to a colleague’s expertise. In 2024 John Hart, head of the Department of Mechanical Engineering, suggested that Cordero, who develops novel materials and structures for emerging aerospace applications, meet with Faez Ahmed, an associate professor of mechanical engineering and an expert in machine learning and optimization for engineering design. Cordero says he hadn’t previously been pursuing AI-related research: “This is all totally new to me.” Working with Ahmed and other collaborators on a project sponsored by the US Defense Advanced Research Projects Agency (DARPA), Cordero developed an AI tool that can optimize the material composition of what’s known as a blisk—a bladed disk that’s a key component in jet and rocket turbine engines. Their work aims to improve engine performance and longevity and could lead to more reliable reusable rocket engines for heavy-lift launch vehicles. Cordero says the AI system augmented human intuition—even “on problems where it’s almost impossible to have intuition.” Professor Ju Li posits that if AI is given autonomy to do experiments, to try different things and fail and learn from that, it could evolve into something very similar to human intelligence. Stories like these abound at MIT. In every department, in almost every lab on campus, AI technologies such as machine learning, large language models, and neural networks are transforming research—turbocharging existing methods, opening previously unexplored or inaccessible pathways, and creating novel opportunities in drug development, computing, energy technologies, manufacturing, robotics, neuroscience, metallurgy, and even wildlife preservation. “I cannot think of a single group meeting that we have where we’re not talking about these tools,” says Angela Koehler, the Charles W. and Jennifer C. Johnson Professor of Biological Engineering and faculty lead of the MIT Health and Life Sciences Collaborative (MIT HEALS). Her research group uses AI models to develop drug candidates designed to attach to molecular targets previously considered “undruggable,” such as transcription factors, RNA-binding proteins, or cytokines. “I would say 90% of the thesis committees I’m on involve a significant AI component,” she says. “And that definitely was not the case five years ago.” “Artificial intelligence is everywhere on campus,” says Ian Waitz, MIT’s vice president for research and the Jerome C. Hunsaker Professor of Aero-Astro. “Any field with a tremendous amount of complexity will benefit from it. Life sciences. Materials science. Anyone who does any kind of image analysis uses these tools now. I don’t know of a single research field here at MIT that hasn’t been impacted by AI.”
AI isn’t exactly new at MIT Though Deng and Cordero may have come to it through happenstance or clever matchmaking, most developments in AI at MIT don’t arise that way. Nor is the interest in it new. More than 70 years ago, in 1954, computer researcher Belmont G. Farley and physicist Wesley A. Clark ran the world’s first computer simulation of a neural network at MIT. Interest in neural network technology—now better known as deep learning—waxed and waned over the next decades. Ju Li, PhD ’00, the Carl Richard Soderberg Professor of Power Engineering (as well as a professor of nuclear science and engineering and materials science and engineering), remembers taking a course on neural networks during Independent Activities Period (IAP) in 1995, when he was a graduate student. “It was not a deep network—just a few layers,” recalls Li, who researches materials used in nuclear energy, batteries, electrolyzers, and energy-efficient computing. He characterizes it as essentially a regression tool that they used to fit curves. But over the past few years, activity in AI has exploded globally, fueled by powerful new models and an enormous increase in the computing power of chips; the resulting proliferation and evolution of data centers has in turn sparked more activity. Today, neural networks can have more than a thousand layers. Backed by massive investments in AI in both the public and private spheres, AI researchers have created a suite of tools that can scan almost immeasurable quantities and types of data; interface with sensors, robotics, and other mechanical devices; and communicate with human researchers in natural language.
RACHEL WU VIA MIT NEWS OFFICE “Many of the tools that we developed in the lab— they’re very broadly used in the pharmaceutical industry. And they’re really making significant impact.” Regina Barzilay Regina Barzilay has been working on AI since she came to MIT in 2003. Today, she’s the School of Engineering Distinguished Professor for AI and Health and AI faculty lead of the MIT Abdul Latif Jameel Clinic for Machine Learning in Health. But she says that if anyone had told her even 10 years ago where the field would be now and what kinds of things she’d be working on, she “absolutely” wouldn’t have believed it. AI applications for drug discovery and development, one of Barzilay’s areas of expertise, have been particularly prolific and successful at MIT. Giovanni Traverso’s lab, for example, has used AI to design nanoparticles that can deliver RNA vaccines and other therapies more efficiently than previous systems. Researchers at CSAIL (the Computer Science & Artificial Intelligence Laboratory, where Barzilay is a principal investigator) have used AI models to explain how a narrow-spectrum antibiotic specifically targets harmful microbes in people with Crohn’s disease. The Jameel Clinic has helped build models that can predict which flu vaccine will be most effective in a given year. “Many of the tools that we developed in the lab—they’re very broadly used in the pharmaceutical industry,” she explains. “And they’re really making significant impact.” She says there’s not even a question anymore about whether they make a difference. They’ve become standard tools because they work every day. One such tool is Boltz, an open-source AI model developed by a group at the Jameel Clinic and initially released in November 2024 as Boltz-1. Inspired by DeepMind’s AlphaFold2—a model that earned Demis Hassabis and John Jumper the 2024 Nobel Prize in chemistry—Boltz-1 helps scientists predict the 3D structures of proteins and other biological molecules. The Jameel Clinic researchers soon followed up with Boltz-2, which in addition to predicting molecular structure can also predict affinity—the strength with which a protein binds with a small molecule. Assays to measure affinity, a vital measure in drug development, are among the most importantperformed in biology and chemistry labs. In October 2025, the Jameel Clinic released its latest iteration, BoltzGen—a generative AI model capable of designing custom proteins that could bind with a wide range of biomolecular targets. Molecular binders already play important roles in fields including therapeutics, diagnostics, and biotechnology. BoltzGen is the first advanced, large-scale model that considers every single atom in the potential new protein and every atom in its target molecule, providing greater accuracy. Hannes Stärk, the fourth-year PhD student at CSAIL who built BoltzGen, says the model works because it actually learns—drawing inferences from the data it is trained with and then producing novel ideas inspired by that data. With machine learning, you want the model to generalize from the data you use to train it, says Stärk, who created BoltzGen over seven months, often working up to 12 hours a day. “Because otherwise,” he says, “your solution is already in your training data.” Stärk has also assembled a network of over 30 scientists both within and beyond MIT to explore the design and applications of molecular binders for use in drug development, metabolomics, and structural biology as well as in treating cancer, autoimmune diseases, and genetic diseases. “It’s nice to have one model that can do all of this,” he says. Training across all these areas also makes the model better at generalizing. Beyond drug discovery As labs working in drug development continue to reap benefits from AI, other researchers across the Institute are busy applying existing AI tools or, more often, developing their own models for use in myriad disciplines and applications. A cross-disciplinary group involving the Department of Electrical Engineering and Computer Science (EECS), CSAIL, and Mass General Hospital has launched MultiverSeg, a tool that quickly annotates areas of interest in medical images and could help scientists develop new treatments and map disease progression. MIT researchers are also designing and running AI-directed automated laboratories to accelerate and refine the process of discovering new components for sustainable materials and solar panels. And Ahmed’s MechE group is developing AI models to do such things as help automakers design high-performance vehicles or determine whether a large shipping vessel can be considered seaworthy. Ahmed also teaches a course titled AI and Machine Learning for Engineering Design. First offered in 2021, it attracts not only mechanical, civil, and environmental engineers but students from aero-astro, Sloan, and more. MIT TECHNOLOGY REVIEW “The goal is to tap into diverse types of raw data and turn that into “something that helps us understand what is putting species at risk.” Sara Beery Meanwhile, Priya Donti, an assistant professor of EECS and a PI at the Laboratory for Information & Decision Systems (LIDS), has developed AI-enabled optimization approaches to help schedule power generation resources on power grids. The machine-learning tools her group builds will help utility operators respond to many inevitable grid issues. “The big challenge is that on a power grid, you need to maintain this exact balance between the amount of power you’re producing and putting into the grid and the amount that you’re taking out on the other side,” she explains. “When you have a lot of variation from solar, wind, and other sources of power whose output varies based on the weather, you have to coordinate the grid much more tightly in order to maintain that balance.” Information about the physics of how power grids work is embedded in Donti’s AI model, so it functions and reacts much as a real grid would. MIT researchers are even applying AI tools to explore and analyze the natural world. Sara Beery, an assistant professor of EECS who specializes in AI and decision-making, develops AI methods that discover and dig into ecological data collected by a wide range of remote sensing technologies to analyze and predict how species and ecosystems are changing around the globe. These technologies enable Beery and her colleagues to gather data on a far greater number of endangered species than ever before, and at an unprecedented scale. Historically, most ecological research has focused on collecting incredibly rich data about single species in really small regions, she says, but “we’ve realized that’s not sufficient.” Information gleaned from, say, a small part of one river ecosystem will not help us understand or prevent what she calls “the exponential increase in species extinction rates that we’re currently facing.” Already, Beery says, “we’re using multimodal AI to enable experts to quickly search massive repositories of image data, to discover data points that were previously very difficult to find.” But she says the goal is to be able to readily tap into diverse types of raw data—from satellite and bioacoustic sensor data to camera images and DNA—and “actually turn that into some sort of scientific insight, something that helps us understand what is putting species at risk.”
Mens et manus in AI While some MIT researchers have successfully used AI to help invent technologies ranging from novel cancer therapies to safer high-performance automobiles, others are also using machine learning and other AI tools to help determine whether these technologies perform as promised—or can be produced successfully and economically at scale. Connor Coley, SM ’16, PhD ’19, an associate professor of chemical engineering and EECS, designs new molecules—and recipes for making new molecules, primarily small organic molecules—for potential use by pharmaceutical, agricultural, and other chemical companies. Coley, a former MIT Technology Review Innovators Under 35 honoree, has developed a “genetic” algorithm that uses biologically inspired processes including selection and mutation. This tool encodes potential polymer blends drawn from a large database of polymers into what is effectively a digital chromosome, which the algorithm then improves to generate the most promising material combinations. Working at the intersection of chemistry and computer science, Coley believes AI could one day help his lab discover polymer blends that would lead to improved battery electrolytes and tailored nanoparticles for safer drug delivery. He and his lab also work to develop machine-learning tools that streamline the discovery and production processes. “If you want AI to be the brain behind some of the science you’re doing, you need the hands as well,” says Coley, who was one of the first MIT faculty members hired into the MIT Schwarzman College of Computing. He and his group have coupled a robotic liquid-handling platform with an optimization algorithm. In the project designed to look for optimal polymer blends, the autonomous system not only chooses which polymer solutions to test but also performs the physical testing. The system, which can generate and test 700 new polymer blends in a day, has identified one that performed 18% better than any of its components. Systems with a similar level of autonomy could also have a big impact on early-stage drug discovery. One effect, he observes, should be to reduce the time it takes to advance a drug from the lab into clinical trials. But the real question, he says, is “What might we be able to do that we just couldn’t do with any reasonable amount of resources previously?” Alexander Siemenn, PhD ’25, also uses AI both to search for new materials and to control robots that test the physical properties of those materials. For his doctoral thesis, Siemenn built from scratch a fully autonomous AI-driven robotic laboratory to discover and test sustainable high-performance materials for solar panels. The system incorporates computer vision, machine learning, and an optimization algorithm and runs 24 hours a day. “We are pairing conventional methods [of measurement] that have been almost entirely manual to this point with the AI methods,” says Siemenn. “The goal is to be able to not just improve their accuracy but also make them fast and autonomous.” Hits and near misses Institute labs are also encountering some of the first real borders of the brave new AI-enhanced world. Many researchers at MIT and elsewhere agree that most of the “low-hanging fruit” has already been collected. That includes AI’s contributions to managing massive data sets and accelerating existing discovery and testing processes, at times to near light speed. Beyond those immediate gains, though, results vary—even in drug development, which has seen some of the most spectacular achievements of AI. “There are some areas where you would assume we should be doing much better here and we are not,” observes Barzilay. “The reason we cannot cure neurodegenerative diseases like Alzheimer’s or very advanced cancer is because we don’t really understand fully—on the molecular level—the disease itself, the drivers, and how to control it.” And AI still hasn’t made what she calls “a significant transformation” in terms of understanding those underlying disease mechanisms. “There are some helper tools,” she says, but AI hasn’t provided a profoundly new understanding of any disease—“So this is a place that we would hope to see more.” MIT TECHNOLOGY REVIEW “In AI, scaling is synergistic and good. In chemistry and materials, scaling is kind of a scary beast that you need to beat in order to make an impact.” Rafael Gómez-Bombarelli Limits in materials science are also emerging, particularly in translating digital solutions proposed by AI into objects made of atoms and molecules. Rafael Gómez-Bombarelli, an associate professor of materials science and engineering, develops physics-based machine-learning simulations to accelerate the discovery cycle for sustainable polymers and materials for use in energy, health care, and batteries. While physics-based simulations in themselves have been an unmitigated success, he says, results have been spottier when it comes to manufacturing the materials themselves; many of the solutions generated by these simulators fail in the physical world. “It turns out these simulators don’t capture lots of things that are important,” he says. “They operate on the atomically resolved problems for nanosecond-timescale questions. But many, many [materials] problems don’t happen in nanoseconds, don’t involve just a few ten thousands of atoms.” And they often involve physics more complicated than current AI models account for. What’s more, when the goal might be to produce millions of tons of a new material, scaling errors can be disastrous. “In AI, scaling is synergistic and good,” Gómez-Bombarelli says. “In chemistry and materials, scaling is kind of a scary beast that you need to beat in order to make an impact.”
New methods, new insights While AI has already produced myriad results and surprises, researchers at MIT believe much of its potential is still waiting to be discovered. And they are eager to search for high-impact applications. Ila Fiete, a professor of brain and cognitive sciences, builds AI tools and mathematical models to expand our knowledge of how the brain develops and reshapes its neural connections. Her work, she believes, can help us understand how we form memories or perceive ourselves in space—and that, in turn, can lead to improvements in AI. Many features of AI, including parallel computing in neural networks, were inspired by the human brain. “AI has [helped] and will continue to help us do more science and better science,” she says. “But neuroscientists believe there is a lot about how humans and other biological intelligences learn and solve problems that is better in some dimensions than current AI models. And by learning better how that works, we can actually inform better AI architectures.” Li agrees that certain elements of human intelligence and learning could benefit AI and help it solve some of our world’s most pressing and complex problems, including global poverty and climate change. “Large language models today have read tens of millions of papers and books,” he says, adding that they are “much more interdisciplinary than any of us.” Yet he notes that scientific literature is strongly biased toward success. “The day-to-day experience in the lab is 95% frustration, and I think it’s the failure cases which build character,” he says. He posits that if AI is given autonomy to do experiments, to try different things and fail and learn from that, it could evolve into something very similar to human intelligence. Researchers at MIT believe that as AI continues to evolve, expand, and proliferate, the Institute has a special duty to channel these technologies toward useful, attainable ends. “Right now, in the AI world there is a lot of hype and fluff,” says Ahmed, who is developing generative AI tools to help tackle complex engineering and design problems. “The digital world is overflowing with stuff,” he says, and there’s a lot happening on the AI front with images, text, and video. “But the physical world is still less affected, and we are seeing a lot more happening at the intersection of physical and AI at MIT.” AI’s future includes potential triumphs and potential pitfalls. Researchers still worry about “hallucinations”—results spit out of AI models that make no sense in the real world. They worry, as well, that some practitioners will rely too heavily on AI tools, omitting key insights and safeguards that keep an experiment or production facility on track. And they worry about overpromising—unrealistically presenting AI as a magical solution to all problems great and small. “It’s impossible to predict how good these models are going to get,” says MechE’s Hart. “Where they are going to shine and where they are going to limit.” But instead of sensing danger, Hart sees opportunity, especially at MIT: “We have the learned expertise and experience that allows us to frame the right questions and use these tools in the right way.” The challenge for the MITs of the world, he says, is to figure out how to use AI tools to create faster, better solutions and navigate more complex problems than we ever could before.
Caring for service dogs
Brenda Schafer Kennedy, SM ’93, knows that sometimes the best medicine comes with four legs and fur. Kennedy is the chief veterinary and research officer for Canine Companions, a California-based, nationwide organization that provides assistance dogs at no cost to children, veterans, and adults with disabilities. “The need is enormous: One in four people in the US has a disability. We have so many people who could benefit from these dogs,” Kennedy says. While service dogs might be best known for guiding the blind, Canine Companions trains dogs to do such things as open doors for wheelchair users or alert deaf people to doorbells, fire alarms, and other key sounds. Its psychiatric service dogs help veterans suffering from post-traumatic stress disorder—waking them from nightmares, for example. To date, it’s paired more than 7,000 dogs with people in need. It’s critical to ensure that every service dog placed is healthy, and Kennedy—a veterinarian—spearheads the organization’s efforts to breed dogs with that in mind. “We wouldn’t place a dog that might have a life-shortening or a significant medical issue that a person might have to manage,” she says.
Kennedy also takes the lead in developing tech to support Canine Companions’ work. She is a co-inventor of CanineAlert, a patented device that sends a signal to a dog’s collar so the dog can interrupt a nightmare when its owner’s heart rate spikes. The technology may soon expand to address daytime anxiety episodes. “These dogs can really be not only life-transforming in terms of providing people with independence, but critically essential and even life-saving,” she says.
An animal lover since childhood, Kennedy earned her undergraduate degree from Northwestern University before coming to MIT for her master’s in biology. “I found incredible mentors at MIT,” she says, noting that she particularly enjoyed working with Professor Hazel Sive, whose lab studied African clawed frogs. The research was fascinating, but Kennedy wanted to work in hands-on medicine, so she obtained her veterinary degree from Tufts University. She then spent 16 years in private practice. Today, she is delighted to combine animal care with research at Canine Companions. “I had a passion for doing something really mission-oriented,” she says. “I love the idea of helping people through the human-canine bond.” In additional to providing service, dogs also offer something elemental, Kennedy says: “Dogs add unconditional love to the mix. They support emotional and mental health for people and can be bridges to the community.”
The new word in home construction could be “plastics”
Single-use plastics are a persistent source of environmental pollution, and the need to house a growing global population puts increasing pressure on resources such as timber. MIT engineers have an idea that could make a dent in both problems at once. In a recent study, a team led by mechanical engineering professor David Hardt, SM ’74, PhD ’79, and lecturer and research scientist AJ Perez ’13, MEng ’14, PhD ’23, laid out a plan for using recycled plastic to 3D-print construction-grade beams, trusses, and other structures that could one day offer lighter, more sustainable alternatives to traditional wood-based framing. Although some companies are working on using large-scale additive manufacturing to create walls, they’re mainly using concrete or clay, whose production typically has a large negative environmental impact. These engineers are among the first to explore printing structural framing elements—and to do so using recycled plastic. The design they came up with is similar in shape to the traditional wooden trusses that support flooring, with beams that connect in a pattern resembling a ladder with diagonal rungs. To test it, they obtained pellets made of recycled PET polymers and glass fibers from an aerospace materials company and fed them into a room-size 3D printer as “ink.” When they printed four long trusses with this material and configured them into a conventional plywood-topped floor frame, the result had a load-bearing capacity of over 4,000 pounds, far exceeding key building standards set by the US Department of Housing and Urban Development. The plastic-printed trusses weigh about 13 pounds each, light enough to transport without a flatbed truck. An industrial printer can crank one out in under 13 minutes. Crucially, the researchers are developing the process to work with “dirty” plastic that hasn’t been cleaned or preprocessed. In addition to floor trusses, they are working on printing other elements and combining them into a full frame for a modest-size house.
“We’ve estimated that the world needs about 1 billion new homes by 2050. If we try to make that many homes using wood, we would need to clear-cut the equivalent of the Amazon rainforest three times over,” says Perez. “The key here is: We recycle dirty plastic into building products for homes that are lighter, more durable, and sustainable.” The researchers envision that one day, trash like used bottles and food containers could be sent directly into a shredder, turned into pellets, and fed into a large-scale additive manufacturing machine to become structural composite construction components. At the construction site, the elements could be quickly fitted into a lightweight yet sturdy home frame. “The idea is to bring shipping containers close to where you know you’ll have a lot of plastic, like next to a football stadium,” Perez says. “Then you could use off-the-shelf shredding technology and feed that dirty shredded plastic into a large-scale additive manufacturing system, which could exist in micro-factories, just like bottling centers, around the world. You could print the parts for entire buildings that would be light enough to transport on a moped or pickup truck to where homes are most needed.”
A natural protein may protect the GI tract from infection
Embedded in the body’s mucosal surfaces, proteins called lectins bind to sugars found on cell surfaces. A team led by MIT chemistry professor Laura Kiessling has found that one such protein, intelectin-2, both helps fortify the mucosal barrier and offers broad-spectrum protection against harmful bacteria found in the GI tract. Intelectin-2 binds to a sugar molecule called galactose that is found on bacterial membranes, the team found, trapping the bacteria and hindering their growth; the trapped microbes eventually disintegrate, suggesting that the protein is able to kill them by disrupting their cell membranes. It also helps strengthen the intestine’s protective lining by binding to the galactose in the mucins that make up mucus. “What’s remarkable is that intelectin-2 operates in two complementary ways. It helps stabilize the mucus layer, and if that barrier is compromised, it can directly neutralize or restrain bacteria that begin to escape,” says Kiessling, who conducted the study with colleagues including Amanda Dugan, a former MIT postdoc and research scientist, and Deepsing Syangtan, PhD ’24. Because intelectin-2 can neutralize or eliminate pathogens such as Staphylococcus aureus and Klebsiella pneumoniae, which are often difficult to treat with antibiotics, it could someday be adapted as an antimicrobial agent, the researchers say. Restoring desirable levels of intelectin-2 could also help people with disorders such as inflammatory bowel disease, who may have either too little of it (potentially weakening the mucus barrier) or too much (killing off beneficial gut bacteria). “Harnessing human lectins as tools to combat antimicrobial resistance opens up a fundamentally new strategy that draws on our own innate immune defenses,” Kiessling says. “Taking advantage of proteins that the body already uses to protect itself against pathogens is compelling and a direction that we are pursuing.”
Inventor recalls eye imaging breakthrough
If you’ve been to an eye doctor and had an image taken of the inside of your eye, chances are good it was done with optical coherence tomography (OCT)—a technology invented by clinician-scientist David Huang ’85, SM ’89, PhD ’93, and now used in 40 million procedures per year. OCT is a noninvasive technique used to produce detailed images of complicated biological tissues such as the retina and the plaques that can build up in coronary arteries. It maps the time-of-flight of light waves reflected from tissue and paints a high-resolution picture of internal structures. “It uses infrared light that’s barely visible compared to the bright flash of fundus photography [another common method of eye imaging] and provides a lot more information—three-dimensional rather than two-dimensional information—at higher resolution,” Huang says. The discovery earned him and his co-inventors slots in the National Inventors Hall of Fame in 2025 as well as the Lasker Award and the National Medals of Technology and Innovation in 2023. Huang didn’t expect to change the paradigm of eye imaging when he began studying electrical engineering as an undergraduate at MIT, but he was interested in using an engineering mindset to contribute to medical advancements. That, he thought, could be his way to follow in the footsteps of his father, who was a family practitioner.
OCT emerged from his work as an MD-PhD student in the Harvard-MIT Program in Health Sciences and Technology. While studying ultrafast lasers at MIT under James Fujimoto ’79, SM ’81, PhD ’84, the Elihu Thomson Professor of Electrical Engineering, Huang was tasked with using the lasers to improve various ophthalmological tasks, including measuring the thickness of the cornea and retina. Huang thought an approach known as interferometry, which could measure the time of flight down to one quadrillionth of a second, could improve thickness measurements to micrometer resolution. Huang’s experiments revealed that the technique was able to detect very faint signals arising from fine internal structures within the retina. Fujimoto and Huang realized the potential for inventing a new type of imaging and enlisted the help of Eric Swanson, SM ’84, who was using interferometry for intersatellite communications at Lincoln Laboratory, to develop an OCT machine for biological applications. Huang tested the new machine on several types of tissues accessed through Harvard Medical School and found it particularly successful in imaging retinal and coronary artery samples. He and his colleagues published their initial findings in Science in 1991, establishing OCT as a new imaging modality.
“Because of our ability to form collaborations with medical doctors and the more advanced technologies that were easily accessible at Lincoln Lab and MIT, we were able to make this new imaging technology take off when other people who were exploring around the same area were not able to demonstrate imaging results,” he says. After the groundbreaking invention, Huang finished his academic and medical training as an ophthalmologist while Fujimoto and Swanson formed a startup company to ensure that the device got into medical offices. Over the next decades, Huang has continued to refine OCT for various applications. Today, as the director of research at Oregon Health and Science University’s Casey Eye Institute, he leads research groups exploring new ways to use OCT in techniques such as OCT angiography (imaging blood flow down to the capillary level) and OCT optoretinography (mapping the light response in retinal photoreceptor cells). In addition to conducting research, he also sees patients and is the cofounder of GoCheck Kids, a digital platform for pediatric eye screening. Huang credits his knack for innovation to his position at the nexus of diverse fields. “It’s hard for a pure medical doctor or a pure laser engineer to realize that there is an opportunity to invent a new device that solves a real problem in the clinic,” he says. “But it’s really easy when you have knowledge on both sides.”