AI
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

Bitcoin:
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

Datacenter:
Lorem Ipsum is simply dummy text of the printing and typesetting industry.

Energy:
Lorem Ipsum is simply dummy text of the printing and typesetting industry.
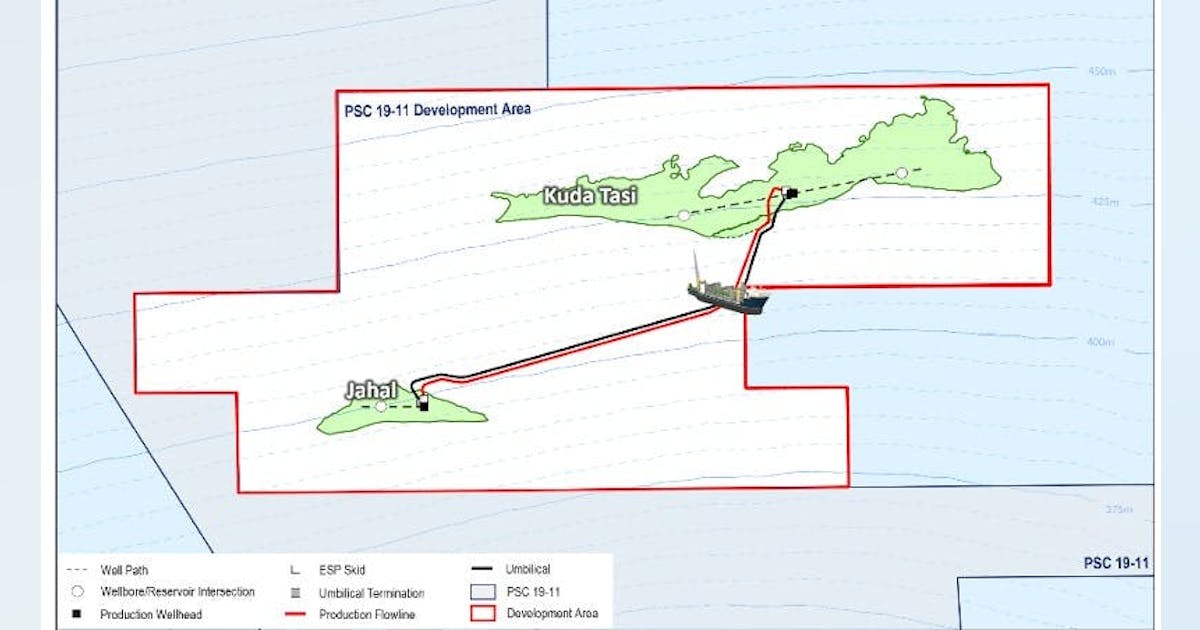
Finder Energy advances KTJ Project with development area approval
Finder Energy Holdings Ltd. received regulatory approval for a development area covering the Kuda Tasi and Jahal oil fields offshore Timor‑Leste, enabling progression toward field development. Autoridade Nacional do Petróleo (ANP) approved an 88‑sq km development area over the Kuda Tasi and Jahal oil fields (KTJ Project) within PSC 19‑11 offshore Timor‑Leste, representing the first stage of the regulatory approvals process for the project. The declaration of the development area is a precursor to the field development plan (FDP), which Finder is currently preparing for submission to ANP in second‑quarter 2026. Upon approval of the FDP, the development area would secure tenure for up to 25 years or until production ceases, allowing Finder to conduct development and production operations within the area, subject to applicable regulatory approvals and conditions. The company said its upside strategy centers on the potential for the Petrojarl I FPSO to serve as a central processing and export hub for future tiebacks of surrounding discoveries, contingent on successful appraisal and/or exploration activities within PSC 19‑11. Alternatively, longer tie‑back distances could be accommodated through a secondary standalone development in the southern portion of the PSC. Finder is continuing technical evaluation of appraisal and exploration opportunities to generate drilling targets. PSC 19‑11 lies within the Laminaria High oil province of Timor‑Leste. The KTJ Project contains an estimated 25 million bbl of gross 2C contingent resources, with identified upside of an additional 23 million bbl gross 2C contingent resources and 116 million bbl gross 2U prospective resources. Finder operates PSC 19‑11 with a 66% working interest.
Libya’s NOC, Chevron sign MoU for technical study for offshore Block NC146
@import url(‘https://fonts.googleapis.com/css2?family=Inter:[email protected]&display=swap’); a { color: var(–color-primary-main); } .ebm-page__main h1, .ebm-page__main h2, .ebm-page__main h3, .ebm-page__main h4, .ebm-page__main h5, .ebm-page__main h6 { font-family: Inter; } body { line-height: 150%; letter-spacing: 0.025em; font-family: Inter; } button, .ebm-button-wrapper { font-family: Inter; } .label-style { text-transform: uppercase; color: var(–color-grey); font-weight: 600; font-size: 0.75rem; } .caption-style { font-size: 0.75rem; opacity: .6; } #onetrust-pc-sdk [id*=btn-handler], #onetrust-pc-sdk [class*=btn-handler] { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-policy a, #onetrust-pc-sdk a, #ot-pc-content a { color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-pc-sdk .ot-active-menu { border-color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-accept-btn-handler, #onetrust-banner-sdk #onetrust-reject-all-handler, #onetrust-consent-sdk #onetrust-pc-btn-handler.cookie-setting-link { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-consent-sdk .onetrust-pc-btn-handler { color: #c19a06 !important; border-color: #c19a06 !important; } The National Oil Corp. of Libya (NOC) signed a memorandum of understanding (MoU) with Chevron Corp. to conduct a comprehensive technical study of offshore Block NC146. The block is an unexplored area with “encouraging geological indicator that could lead to significant discoveries, helping to strengthen national reserves,” NOC noted Chairman Masoud Suleman as saying, noting that the partnership is “a message of confidence in the Libyan investment environment and evidence of the return of major companies to work and explore promising opportunities in our country.” According to the NOC, Libya produces 1.4 million b/d of oil and aims to increase oil production in the coming 3-5 years to 2 million b/d and then to 3 million b/d following years of instability that impacted the country’s production. Chevron is working to add to its diverse exploration and production portfolio in the Mediterranean and Africa and continues to assess potential future opportunities in the region. The operator earlier this year entered Libya after it was designated as a winning bidder for Contract Area 106 in the Sirte basin in the 2025 Libyan Bid Round. That followed the January 2026 signing of a

Market Focus: LNG supply shocks expose limited market flexibility
@import url(‘https://fonts.googleapis.com/css2?family=Inter:[email protected]&display=swap’); a { color: var(–color-primary-main); } .ebm-page__main h1, .ebm-page__main h2, .ebm-page__main h3, .ebm-page__main h4, .ebm-page__main h5, .ebm-page__main h6 { font-family: Inter; } body { line-height: 150%; letter-spacing: 0.025em; font-family: Inter; } button, .ebm-button-wrapper { font-family: Inter; } .label-style { text-transform: uppercase; color: var(–color-grey); font-weight: 600; font-size: 0.75rem; } .caption-style { font-size: 0.75rem; opacity: .6; } #onetrust-pc-sdk [id*=btn-handler], #onetrust-pc-sdk [class*=btn-handler] { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-policy a, #onetrust-pc-sdk a, #ot-pc-content a { color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-pc-sdk .ot-active-menu { border-color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-accept-btn-handler, #onetrust-banner-sdk #onetrust-reject-all-handler, #onetrust-consent-sdk #onetrust-pc-btn-handler.cookie-setting-link { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-consent-sdk .onetrust-pc-btn-handler { color: #c19a06 !important; border-color: #c19a06 !important; } In this Market Focus episode of the Oil & Gas Journal ReEnterprised podcast, Conglin Xu, managing editor, economics, takes a look into the LNG market shock caused by the effective closure of the Strait of Hormuz and the sudden loss of Qatari LNG supply as the Iran war continues. Xu speaks with Edward O’Toole, director of global gas analysis, RBAC Inc., to examine how these disruptions are intensifying global supply constraints at a time when European inventories were already under pressure following a colder-than-average winter and weaker storage levels. Drawing on RBAC’s G2M2 global gas market model, O’Toole outlines disruption scenarios analyzed in the firm’s recent report and explains how current events align with their findings. With global LNG production already operating near maximum utilization, the market response is being driven by higher prices and reduced consumption. Europe faces sharper price pressure due to storage refill needs, while Asian markets are expected to see greater demand reductions as consumers switch fuels. O’Toole underscores the importance of scenario-based modeling and supply diversification as geopolitical risk exposes structural vulnerabilities in the LNG market—offering insights for stakeholders navigating an increasingly uncertain global

Latin America returns to the energy security conversation at CERAWeek
With geopolitical risk central to conversations about energy, and with long-cycle supply once again in focus, Latin America’s mix of hydrocarbons and export potential drew renewed attention at CERAWeek by S&P Global in Houston. Argentina, resource story to export platform Among the regional stories, Argentina stood out as Vaca Muerta was no longer discussed simply as a large unconventional resource, but whether the country could turn resource quality into sustained export capacity. Country officials talked about scale: more operators, more services, more infrastructure, and a larger industrial base around the unconventional play. Daniel González, Vice Minister of Energy and Mining for Argentina, put it plainly: “The time has come to expand the Vaca Muerta ecosystem.” What is at stake now is not whether the basin works, but whether the country can build enough above-ground capacity and regulatory consistency to keep development moving. Horacio Marín, chairman and chief executive officer of YPF, offered an expansive version of that argument. He said Argentina’s energy exports could reach $50 billion/year by 2031, backed by roughly $130 billion in cumulative investment in oil, LNG, and transportation infrastructure. He said Argentine crude output could reach 1 million b/d by end-2026. He said Argentina wants to be seen less as a recurrent frontier story and more as a future supplier with scale. “The time to invest in Vaca Muerta is now,” Marín said. The LNG piece is starting to take shape. Eni, YPF, and XRG signed a joint development agreement in February to move Argentina LNG forward, with a first phase planned at 12 million tonnes/year. Southern Energy—backed by PAE, YPF, Pampa Energía, Harbour Energy, and Golar LNG—holds a long-term agreement with SEFE for 2 million tonnes/year over 8 years. The movement by global standards is early-stage and relatively modest, but it adds to Argentina’s export

Nscale Expands AI Factory Strategy With Power, Platform, and Scale
Nscale has moved quickly from startup to serious contender in the race to build infrastructure for the AI era. Founded in 2024, the company has positioned itself as a vertically integrated “neocloud” operator, combining data center development, GPU fleet ownership, and a software stack designed to deliver large-scale AI compute. That model has helped it attract backing from investors including Nvidia, and in early March 2026 the company raised another $2 billion at a reported $14.6 billion valuation. Reuters has described Nscale’s approach as owning and operating its own data centers, GPUs, and software stack to support major customers including Microsoft and OpenAI. What makes Nscale especially relevant now is that it is no longer content to operate as a cloud intermediary or capacity provider. Over the past year, the company has increasingly framed itself as an AI hyperscaler and AI factory builder, seeking to combine land, power, data center shells, GPU procurement, customer offtake, and software services into a single integrated platform. Its acquisition of American Intelligence & Power Corporation, or AIPCorp, is the clearest signal yet of that shift, bringing energy infrastructure directly into the center of Nscale’s business model. The AIPCorp transaction is significant because it gives Nscale more than additional development capacity. The company said the deal includes the Monarch Compute Campus in Mason County, West Virginia, a site of up to 2,250 acres with a state-certified AI microgrid and a power runway it says can scale beyond 8 gigawatts. Nscale also said the acquisition establishes a new division, Nscale Energy & Power, headquartered in Houston, extending its platform further into power development. That positioning reflects a broader shift in the AI infrastructure market. The central bottleneck is no longer simply access to GPUs. It is the ability to assemble power, cooling, land, permits, data center

Four things we’d need to put data centers in space
MIT Technology Review Explains: Let our writers untangle the complex, messy world of technology to help you understand what’s coming next. You can read more from the series here. In January, Elon Musk’s SpaceX filed an application with the US Federal Communications Commission to launch up to one million data centers into Earth’s orbit. The goal? To fully unleash the potential of AI without triggering an environmental crisis on Earth. But could it work? SpaceX is the latest in a string of high-tech companies extolling the potential of orbital computing infrastructure. Last year, Amazon founder Jeff Bezos said that the tech industry will move toward large-scale computing in space. Google has plans to loft data-crunching satellites, aiming to launch a test constellation of 80 as early as next year. And last November Starcloud, a startup based in Washington State, launched a satellite fitted with a high-performance Nvidia H100 GPU, marking the first orbital test of an advanced AI chip. The company envisions orbiting data centers as large as those on Earth by 2030. Proponents believe that putting data centers in space makes sense. The current AI boom is straining energy grids and adding to the demand for water, which is needed to cool the computers. Communities in the vicinity of large-scale data centers worry about increasing prices for those resources as a result of the growing demand, among other issues.
In space, advocates say, the water and energy problems would be solved. In constantly illuminated sun-synchronous orbits, space-borne data centers would have uninterrupted access to solar power. At the same time, the excess heat they produce would be easily expelled into the cold vacuum of space. And with the cost of space launches decreasing, and mega-rockets such as SpaceX’s Starship promising to push prices even lower, there could be a point at which moving the world’s data centers into space makes sound business sense. Detractors, on the other hand, tell a different story and point to a variety of technological hurdles, though some say it’s possible they may be surmountable in the not-so-distant future. Here are four of the must-haves we’d need to make space-based data centers a reality. A way to carry away heat AI data centers produce a lot of heat. Space might seem like a great place to dispel that heat without using up massive amounts of water. But it’s not so simple. To get the power needed to run 24-7, a space-based data center would have to be in a constantly illuminated orbit, circling the planet from pole to pole, and never hide in Earth’s shadow. And in that orbit, the temperature of the equipment would never drop below 80 °C, which is way too hot for electronics to operate safely in the long term.
Getting the heat out of such a system is surprisingly challenging. “Thermal management and cooling in space is generally a huge problem,” says Lilly Eichinger, CEO of the Austrian space tech startup Satellives. On Earth, heat dissipates mostly through the natural process of convection, which relies on the movement of gases and liquids like air and water. In the vacuum of space, heat has to be removed through the far less efficient process of radiation. Safely removing the heat produced by the computers, as well as what’s absorbed from the sun, requires large radiative surfaces. The bulkier the satellite, the harder it is to send all the heat inside it out into space. But Yves Durand, former director of technology at the European aerospace giant Thales Alenia Space, says that technology already exists to tackle the problem. The company previously developed a system for large telecommunications satellites that can pipe refrigerant fluid through a network of tubing using a mechanical pump, ultimately transferring heat from within a spacecraft to radiators on the exterior. Durand led a 2024 feasibility study on space-based data centers, which found that although challenges exist, it should be possible for Europe to put gigawatt-scale data centers (on par with the largest Earthbound facilities) into orbit before 2050. These would be considerably larger than those envisioned by SpaceX, featuring solar arrays hundreds of meters in size—larger than the International Space Station. Computer chips that can withstand a radiation onslaught The space around Earth is constantly battered by cosmic particles and lashed by solar radiation. On Earth’s surface, humans and their electronic devices are protected from this corrosive soup of charged particles by the planet’s atmosphere and magnetosphere. But the farther away from Earth you venture, the weaker that protection becomes. Studies show that aircraft crews have a higher risk of developing cancer because of their frequent exposure to high radiation at cruising altitude, where the atmosphere is thin and less protective. Electronics in space are at risk of three types of problems caused by high radiation levels, says Ken Mai, a principal systems scientist in electrical and computer engineering at Carnegie Mellon University. Phenomena known as single-event upsets can cause bit flips and corrupt stored data when charged particles hit chips and memory devices. Over time, electronics in space accumulate damage from ionizing radiation that degrades their performance. And sometimes a charged particle can strike the component in a way that physically displaces atoms on the chip, creating permanent damage, Mai explains. Traditionally, computers launched to space had to undergo years of testing and were specifically designed to withstand the intense radiation present in Earth’s orbit. These space-hardened electronics are much more expensive, though, and their performance is also years behind the state-of-the-art devices for Earth-based computing. Launching conventional chips is a gamble. But Durand says cutting-edge computer chips use technologies that are by default more resistant to radiation than past systems. And in mid-March, Nvidia touted hardware, including a new GPU, that is “bringing AI compute to orbital data centers.” Nvidia’s head of edge AI marketing, Chen Su, told MIT Technology Review, that “Nvidia systems are inherently commercial off the shelf, with radiation resilience achieved at the system level rather than through radiation‑hardened silicon alone.” He added that satellite makers increase the chips’ resiliency with the help of shielding, advanced software for error detection, and architectures that combine the consumer-grade devices with bespoke, hardened technologies.
Still, Mai says that the data-crunching chips are only one issue. The data centers would also need memory and storage devices, both of which are vulnerable to damage by excessive radiation. And operators would need the ability to swap things out or adapt when issues arise. The feasibility and affordability of using robots or astronaut missions for maintenance is a major question mark hanging over the idea of large-scale orbiting data centers. “You not only need to throw up a data center to space that meets your current needs; you need redundancy, extra parts, and reconfigurability, so when stuff breaks, you can just change your configuration and continue working,” says Mai. “It’s a very challenging problem because on one hand you have free energy and power in space, but there are a lot of disadvantages. It’s quite possible that those problems will outweigh the advantages that you get from putting a data center into space.” In addition to the need for regular maintenance, there’s also the potential for catastrophic loss. During periods of intense space weather, satellites can be flooded with enough radiation to kill all their electronics. The sun has just passed the most active phase of its 11-year cycle with relatively little impact on satellites. Still, experts warn that since the space age began, the planet has not experienced the worst the sun is capable of. Many doubt whether the low-cost new space systems that dominate Earth’s orbits today are prepared for that. A plan to dodge space debris Both large-scale orbiting data centers such as those envisioned by Thales Alenia Space and the mega-constellations of smaller satellites as proposed by SpaceX give a headache to space sustainability experts. The space around Earth is already quite crowded with satellites. Starlink satellites alone perform hundreds of thousands of collision avoidance maneuvers every year to dodge debris and other spacecraft. The more stuff in space, the higher the likelihood of a devastating collision that would clutter the orbit with thousands of dangerous fragments. Large structures with hundreds of square meters of solar arrays would quickly suffer damage from small pieces of space debris and meteorites, which would over time degrade the performance of their solar panels and create more debris in orbit. Operating one million satellites in low Earth orbit, the region of space at the altitude of up to 2,000 kilometers, might be impossible to do safely unless all satellites in that area are part of the same network so they can communicate effectively to maneuver around each other, Greg Vialle, the founder of the orbital recycling startup Lunexus Space, told MIT Technology Review. “You can fit roughly four to five thousand satellites in one orbital shell,” Vialle says. “If you count all the shells in low Earth orbit, you get to a number of around 240,000 satellites maximum.” And spacecraft must be able to pass each other at a safe distance to avoid collisions, he says. “You also need to be able to get stuff up to higher orbits and back down to de-orbit,” he adds. “So you need to have gaps of at least 10 kilometers between the satellites to do that safely. Mega-constellations like Starlink can be packed more tightly because the satellites communicate with each other. But you can’t have one million satellites around Earth unless it’s a monopoly.”
On top of that, Starlink would likely want to regularly upgrade its orbiting data centers with more modern technology. Replacing a million satellites perhaps every five years would mean even more orbital traffic—and it could increase the rate of debris reentry into Earth’s atmosphere from around three or four pieces of junk a day to about one every three minutes, according to a group of astronomers who filed objections against SpaceX’s FCC application. Some scientists are concerned that reentering debris could damage the ozone layer and alter Earth’s thermal balance. Economical launch and assembly The longer hardware survives in orbit, the better the return on investment. But for orbital data centers to make economic sense, companies will have to find a relatively cheap way to get that hardware in orbit. SpaceX is betting on its upcoming Starship mega-rocket, which will be able to carry up to six times as much payload as the current workhorse, Falcon 9. The Thales Alenia Space study concluded that if Europe were to build its own orbital data centers, it would have to develop a similarly potent launcher.
But launch is only part of the equation. A large-scale orbital data center won’t fit in a rocket—even a mega-rocket. It will need to be assembled in orbit. And that will likely require advanced robotic systems that do not exist yet. Various companies have conducted Earth-based tests with precursors of such systems, but they are still far from real-world use. Durand says that in the short term, smaller-scale data centers are likely to establish themselves as an integral part of the orbital infrastructure, by processing images from Earth-observing satellites directly in space without having to send them to Earth. That would be a huge help for companies selling insights from space, as many of these data sets are extremely large, and competition for opportunities to downlink them to Earth for processing via ground stations is growing. “The good thing with orbital data centers is that you can start with small servers and gradually increase and build up larger data centers,” says Durand. “You can use modularity. You can learn little by little and gradually develop industrial capacity in space. We have all the technology, and the demand for space-based data processing infrastructure is huge, so it makes sense to think about it.” Smaller facilities probably won’t do much to offset the strain that terrestrial data centers are placing on the planet’s water and electricity, though. That vision of the future might take decades to come to fruition, some critics think—if it even gets off the ground at all.
Finder Energy advances KTJ Project with development area approval
Finder Energy Holdings Ltd. received regulatory approval for a development area covering the Kuda Tasi and Jahal oil fields offshore Timor‑Leste, enabling progression toward field development. Autoridade Nacional do Petróleo (ANP) approved an 88‑sq km development area over the Kuda Tasi and Jahal oil fields (KTJ Project) within PSC 19‑11 offshore Timor‑Leste, representing the first stage of the regulatory approvals process for the project. The declaration of the development area is a precursor to the field development plan (FDP), which Finder is currently preparing for submission to ANP in second‑quarter 2026. Upon approval of the FDP, the development area would secure tenure for up to 25 years or until production ceases, allowing Finder to conduct development and production operations within the area, subject to applicable regulatory approvals and conditions. The company said its upside strategy centers on the potential for the Petrojarl I FPSO to serve as a central processing and export hub for future tiebacks of surrounding discoveries, contingent on successful appraisal and/or exploration activities within PSC 19‑11. Alternatively, longer tie‑back distances could be accommodated through a secondary standalone development in the southern portion of the PSC. Finder is continuing technical evaluation of appraisal and exploration opportunities to generate drilling targets. PSC 19‑11 lies within the Laminaria High oil province of Timor‑Leste. The KTJ Project contains an estimated 25 million bbl of gross 2C contingent resources, with identified upside of an additional 23 million bbl gross 2C contingent resources and 116 million bbl gross 2U prospective resources. Finder operates PSC 19‑11 with a 66% working interest.
Libya’s NOC, Chevron sign MoU for technical study for offshore Block NC146
@import url(‘https://fonts.googleapis.com/css2?family=Inter:[email protected]&display=swap’); a { color: var(–color-primary-main); } .ebm-page__main h1, .ebm-page__main h2, .ebm-page__main h3, .ebm-page__main h4, .ebm-page__main h5, .ebm-page__main h6 { font-family: Inter; } body { line-height: 150%; letter-spacing: 0.025em; font-family: Inter; } button, .ebm-button-wrapper { font-family: Inter; } .label-style { text-transform: uppercase; color: var(–color-grey); font-weight: 600; font-size: 0.75rem; } .caption-style { font-size: 0.75rem; opacity: .6; } #onetrust-pc-sdk [id*=btn-handler], #onetrust-pc-sdk [class*=btn-handler] { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-policy a, #onetrust-pc-sdk a, #ot-pc-content a { color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-pc-sdk .ot-active-menu { border-color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-accept-btn-handler, #onetrust-banner-sdk #onetrust-reject-all-handler, #onetrust-consent-sdk #onetrust-pc-btn-handler.cookie-setting-link { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-consent-sdk .onetrust-pc-btn-handler { color: #c19a06 !important; border-color: #c19a06 !important; } The National Oil Corp. of Libya (NOC) signed a memorandum of understanding (MoU) with Chevron Corp. to conduct a comprehensive technical study of offshore Block NC146. The block is an unexplored area with “encouraging geological indicator that could lead to significant discoveries, helping to strengthen national reserves,” NOC noted Chairman Masoud Suleman as saying, noting that the partnership is “a message of confidence in the Libyan investment environment and evidence of the return of major companies to work and explore promising opportunities in our country.” According to the NOC, Libya produces 1.4 million b/d of oil and aims to increase oil production in the coming 3-5 years to 2 million b/d and then to 3 million b/d following years of instability that impacted the country’s production. Chevron is working to add to its diverse exploration and production portfolio in the Mediterranean and Africa and continues to assess potential future opportunities in the region. The operator earlier this year entered Libya after it was designated as a winning bidder for Contract Area 106 in the Sirte basin in the 2025 Libyan Bid Round. That followed the January 2026 signing of a
Market Focus: LNG supply shocks expose limited market flexibility
@import url(‘https://fonts.googleapis.com/css2?family=Inter:[email protected]&display=swap’); a { color: var(–color-primary-main); } .ebm-page__main h1, .ebm-page__main h2, .ebm-page__main h3, .ebm-page__main h4, .ebm-page__main h5, .ebm-page__main h6 { font-family: Inter; } body { line-height: 150%; letter-spacing: 0.025em; font-family: Inter; } button, .ebm-button-wrapper { font-family: Inter; } .label-style { text-transform: uppercase; color: var(–color-grey); font-weight: 600; font-size: 0.75rem; } .caption-style { font-size: 0.75rem; opacity: .6; } #onetrust-pc-sdk [id*=btn-handler], #onetrust-pc-sdk [class*=btn-handler] { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-policy a, #onetrust-pc-sdk a, #ot-pc-content a { color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-pc-sdk .ot-active-menu { border-color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-accept-btn-handler, #onetrust-banner-sdk #onetrust-reject-all-handler, #onetrust-consent-sdk #onetrust-pc-btn-handler.cookie-setting-link { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-consent-sdk .onetrust-pc-btn-handler { color: #c19a06 !important; border-color: #c19a06 !important; } In this Market Focus episode of the Oil & Gas Journal ReEnterprised podcast, Conglin Xu, managing editor, economics, takes a look into the LNG market shock caused by the effective closure of the Strait of Hormuz and the sudden loss of Qatari LNG supply as the Iran war continues. Xu speaks with Edward O’Toole, director of global gas analysis, RBAC Inc., to examine how these disruptions are intensifying global supply constraints at a time when European inventories were already under pressure following a colder-than-average winter and weaker storage levels. Drawing on RBAC’s G2M2 global gas market model, O’Toole outlines disruption scenarios analyzed in the firm’s recent report and explains how current events align with their findings. With global LNG production already operating near maximum utilization, the market response is being driven by higher prices and reduced consumption. Europe faces sharper price pressure due to storage refill needs, while Asian markets are expected to see greater demand reductions as consumers switch fuels. O’Toole underscores the importance of scenario-based modeling and supply diversification as geopolitical risk exposes structural vulnerabilities in the LNG market—offering insights for stakeholders navigating an increasingly uncertain global
Latin America returns to the energy security conversation at CERAWeek
With geopolitical risk central to conversations about energy, and with long-cycle supply once again in focus, Latin America’s mix of hydrocarbons and export potential drew renewed attention at CERAWeek by S&P Global in Houston. Argentina, resource story to export platform Among the regional stories, Argentina stood out as Vaca Muerta was no longer discussed simply as a large unconventional resource, but whether the country could turn resource quality into sustained export capacity. Country officials talked about scale: more operators, more services, more infrastructure, and a larger industrial base around the unconventional play. Daniel González, Vice Minister of Energy and Mining for Argentina, put it plainly: “The time has come to expand the Vaca Muerta ecosystem.” What is at stake now is not whether the basin works, but whether the country can build enough above-ground capacity and regulatory consistency to keep development moving. Horacio Marín, chairman and chief executive officer of YPF, offered an expansive version of that argument. He said Argentina’s energy exports could reach $50 billion/year by 2031, backed by roughly $130 billion in cumulative investment in oil, LNG, and transportation infrastructure. He said Argentine crude output could reach 1 million b/d by end-2026. He said Argentina wants to be seen less as a recurrent frontier story and more as a future supplier with scale. “The time to invest in Vaca Muerta is now,” Marín said. The LNG piece is starting to take shape. Eni, YPF, and XRG signed a joint development agreement in February to move Argentina LNG forward, with a first phase planned at 12 million tonnes/year. Southern Energy—backed by PAE, YPF, Pampa Energía, Harbour Energy, and Golar LNG—holds a long-term agreement with SEFE for 2 million tonnes/year over 8 years. The movement by global standards is early-stage and relatively modest, but it adds to Argentina’s export
Nscale Expands AI Factory Strategy With Power, Platform, and Scale
Nscale has moved quickly from startup to serious contender in the race to build infrastructure for the AI era. Founded in 2024, the company has positioned itself as a vertically integrated “neocloud” operator, combining data center development, GPU fleet ownership, and a software stack designed to deliver large-scale AI compute. That model has helped it attract backing from investors including Nvidia, and in early March 2026 the company raised another $2 billion at a reported $14.6 billion valuation. Reuters has described Nscale’s approach as owning and operating its own data centers, GPUs, and software stack to support major customers including Microsoft and OpenAI. What makes Nscale especially relevant now is that it is no longer content to operate as a cloud intermediary or capacity provider. Over the past year, the company has increasingly framed itself as an AI hyperscaler and AI factory builder, seeking to combine land, power, data center shells, GPU procurement, customer offtake, and software services into a single integrated platform. Its acquisition of American Intelligence & Power Corporation, or AIPCorp, is the clearest signal yet of that shift, bringing energy infrastructure directly into the center of Nscale’s business model. The AIPCorp transaction is significant because it gives Nscale more than additional development capacity. The company said the deal includes the Monarch Compute Campus in Mason County, West Virginia, a site of up to 2,250 acres with a state-certified AI microgrid and a power runway it says can scale beyond 8 gigawatts. Nscale also said the acquisition establishes a new division, Nscale Energy & Power, headquartered in Houston, extending its platform further into power development. That positioning reflects a broader shift in the AI infrastructure market. The central bottleneck is no longer simply access to GPUs. It is the ability to assemble power, cooling, land, permits, data center
Four things we’d need to put data centers in space
MIT Technology Review Explains: Let our writers untangle the complex, messy world of technology to help you understand what’s coming next. You can read more from the series here. In January, Elon Musk’s SpaceX filed an application with the US Federal Communications Commission to launch up to one million data centers into Earth’s orbit. The goal? To fully unleash the potential of AI without triggering an environmental crisis on Earth. But could it work? SpaceX is the latest in a string of high-tech companies extolling the potential of orbital computing infrastructure. Last year, Amazon founder Jeff Bezos said that the tech industry will move toward large-scale computing in space. Google has plans to loft data-crunching satellites, aiming to launch a test constellation of 80 as early as next year. And last November Starcloud, a startup based in Washington State, launched a satellite fitted with a high-performance Nvidia H100 GPU, marking the first orbital test of an advanced AI chip. The company envisions orbiting data centers as large as those on Earth by 2030. Proponents believe that putting data centers in space makes sense. The current AI boom is straining energy grids and adding to the demand for water, which is needed to cool the computers. Communities in the vicinity of large-scale data centers worry about increasing prices for those resources as a result of the growing demand, among other issues.
In space, advocates say, the water and energy problems would be solved. In constantly illuminated sun-synchronous orbits, space-borne data centers would have uninterrupted access to solar power. At the same time, the excess heat they produce would be easily expelled into the cold vacuum of space. And with the cost of space launches decreasing, and mega-rockets such as SpaceX’s Starship promising to push prices even lower, there could be a point at which moving the world’s data centers into space makes sound business sense. Detractors, on the other hand, tell a different story and point to a variety of technological hurdles, though some say it’s possible they may be surmountable in the not-so-distant future. Here are four of the must-haves we’d need to make space-based data centers a reality. A way to carry away heat AI data centers produce a lot of heat. Space might seem like a great place to dispel that heat without using up massive amounts of water. But it’s not so simple. To get the power needed to run 24-7, a space-based data center would have to be in a constantly illuminated orbit, circling the planet from pole to pole, and never hide in Earth’s shadow. And in that orbit, the temperature of the equipment would never drop below 80 °C, which is way too hot for electronics to operate safely in the long term.
Getting the heat out of such a system is surprisingly challenging. “Thermal management and cooling in space is generally a huge problem,” says Lilly Eichinger, CEO of the Austrian space tech startup Satellives. On Earth, heat dissipates mostly through the natural process of convection, which relies on the movement of gases and liquids like air and water. In the vacuum of space, heat has to be removed through the far less efficient process of radiation. Safely removing the heat produced by the computers, as well as what’s absorbed from the sun, requires large radiative surfaces. The bulkier the satellite, the harder it is to send all the heat inside it out into space. But Yves Durand, former director of technology at the European aerospace giant Thales Alenia Space, says that technology already exists to tackle the problem. The company previously developed a system for large telecommunications satellites that can pipe refrigerant fluid through a network of tubing using a mechanical pump, ultimately transferring heat from within a spacecraft to radiators on the exterior. Durand led a 2024 feasibility study on space-based data centers, which found that although challenges exist, it should be possible for Europe to put gigawatt-scale data centers (on par with the largest Earthbound facilities) into orbit before 2050. These would be considerably larger than those envisioned by SpaceX, featuring solar arrays hundreds of meters in size—larger than the International Space Station. Computer chips that can withstand a radiation onslaught The space around Earth is constantly battered by cosmic particles and lashed by solar radiation. On Earth’s surface, humans and their electronic devices are protected from this corrosive soup of charged particles by the planet’s atmosphere and magnetosphere. But the farther away from Earth you venture, the weaker that protection becomes. Studies show that aircraft crews have a higher risk of developing cancer because of their frequent exposure to high radiation at cruising altitude, where the atmosphere is thin and less protective. Electronics in space are at risk of three types of problems caused by high radiation levels, says Ken Mai, a principal systems scientist in electrical and computer engineering at Carnegie Mellon University. Phenomena known as single-event upsets can cause bit flips and corrupt stored data when charged particles hit chips and memory devices. Over time, electronics in space accumulate damage from ionizing radiation that degrades their performance. And sometimes a charged particle can strike the component in a way that physically displaces atoms on the chip, creating permanent damage, Mai explains. Traditionally, computers launched to space had to undergo years of testing and were specifically designed to withstand the intense radiation present in Earth’s orbit. These space-hardened electronics are much more expensive, though, and their performance is also years behind the state-of-the-art devices for Earth-based computing. Launching conventional chips is a gamble. But Durand says cutting-edge computer chips use technologies that are by default more resistant to radiation than past systems. And in mid-March, Nvidia touted hardware, including a new GPU, that is “bringing AI compute to orbital data centers.” Nvidia’s head of edge AI marketing, Chen Su, told MIT Technology Review, that “Nvidia systems are inherently commercial off the shelf, with radiation resilience achieved at the system level rather than through radiation‑hardened silicon alone.” He added that satellite makers increase the chips’ resiliency with the help of shielding, advanced software for error detection, and architectures that combine the consumer-grade devices with bespoke, hardened technologies.
Still, Mai says that the data-crunching chips are only one issue. The data centers would also need memory and storage devices, both of which are vulnerable to damage by excessive radiation. And operators would need the ability to swap things out or adapt when issues arise. The feasibility and affordability of using robots or astronaut missions for maintenance is a major question mark hanging over the idea of large-scale orbiting data centers. “You not only need to throw up a data center to space that meets your current needs; you need redundancy, extra parts, and reconfigurability, so when stuff breaks, you can just change your configuration and continue working,” says Mai. “It’s a very challenging problem because on one hand you have free energy and power in space, but there are a lot of disadvantages. It’s quite possible that those problems will outweigh the advantages that you get from putting a data center into space.” In addition to the need for regular maintenance, there’s also the potential for catastrophic loss. During periods of intense space weather, satellites can be flooded with enough radiation to kill all their electronics. The sun has just passed the most active phase of its 11-year cycle with relatively little impact on satellites. Still, experts warn that since the space age began, the planet has not experienced the worst the sun is capable of. Many doubt whether the low-cost new space systems that dominate Earth’s orbits today are prepared for that. A plan to dodge space debris Both large-scale orbiting data centers such as those envisioned by Thales Alenia Space and the mega-constellations of smaller satellites as proposed by SpaceX give a headache to space sustainability experts. The space around Earth is already quite crowded with satellites. Starlink satellites alone perform hundreds of thousands of collision avoidance maneuvers every year to dodge debris and other spacecraft. The more stuff in space, the higher the likelihood of a devastating collision that would clutter the orbit with thousands of dangerous fragments. Large structures with hundreds of square meters of solar arrays would quickly suffer damage from small pieces of space debris and meteorites, which would over time degrade the performance of their solar panels and create more debris in orbit. Operating one million satellites in low Earth orbit, the region of space at the altitude of up to 2,000 kilometers, might be impossible to do safely unless all satellites in that area are part of the same network so they can communicate effectively to maneuver around each other, Greg Vialle, the founder of the orbital recycling startup Lunexus Space, told MIT Technology Review. “You can fit roughly four to five thousand satellites in one orbital shell,” Vialle says. “If you count all the shells in low Earth orbit, you get to a number of around 240,000 satellites maximum.” And spacecraft must be able to pass each other at a safe distance to avoid collisions, he says. “You also need to be able to get stuff up to higher orbits and back down to de-orbit,” he adds. “So you need to have gaps of at least 10 kilometers between the satellites to do that safely. Mega-constellations like Starlink can be packed more tightly because the satellites communicate with each other. But you can’t have one million satellites around Earth unless it’s a monopoly.”
On top of that, Starlink would likely want to regularly upgrade its orbiting data centers with more modern technology. Replacing a million satellites perhaps every five years would mean even more orbital traffic—and it could increase the rate of debris reentry into Earth’s atmosphere from around three or four pieces of junk a day to about one every three minutes, according to a group of astronomers who filed objections against SpaceX’s FCC application. Some scientists are concerned that reentering debris could damage the ozone layer and alter Earth’s thermal balance. Economical launch and assembly The longer hardware survives in orbit, the better the return on investment. But for orbital data centers to make economic sense, companies will have to find a relatively cheap way to get that hardware in orbit. SpaceX is betting on its upcoming Starship mega-rocket, which will be able to carry up to six times as much payload as the current workhorse, Falcon 9. The Thales Alenia Space study concluded that if Europe were to build its own orbital data centers, it would have to develop a similarly potent launcher.
But launch is only part of the equation. A large-scale orbital data center won’t fit in a rocket—even a mega-rocket. It will need to be assembled in orbit. And that will likely require advanced robotic systems that do not exist yet. Various companies have conducted Earth-based tests with precursors of such systems, but they are still far from real-world use. Durand says that in the short term, smaller-scale data centers are likely to establish themselves as an integral part of the orbital infrastructure, by processing images from Earth-observing satellites directly in space without having to send them to Earth. That would be a huge help for companies selling insights from space, as many of these data sets are extremely large, and competition for opportunities to downlink them to Earth for processing via ground stations is growing. “The good thing with orbital data centers is that you can start with small servers and gradually increase and build up larger data centers,” says Durand. “You can use modularity. You can learn little by little and gradually develop industrial capacity in space. We have all the technology, and the demand for space-based data processing infrastructure is huge, so it makes sense to think about it.” Smaller facilities probably won’t do much to offset the strain that terrestrial data centers are placing on the planet’s water and electricity, though. That vision of the future might take decades to come to fruition, some critics think—if it even gets off the ground at all.
ExxonMobil begins Turrum Phase 3 drilling off Australia’s east coast
@import url(‘https://fonts.googleapis.com/css2?family=Inter:[email protected]&display=swap’); a { color: var(–color-primary-main); } .ebm-page__main h1, .ebm-page__main h2, .ebm-page__main h3, .ebm-page__main h4, .ebm-page__main h5, .ebm-page__main h6 { font-family: Inter; } body { line-height: 150%; letter-spacing: 0.025em; font-family: Inter; } button, .ebm-button-wrapper { font-family: Inter; } .label-style { text-transform: uppercase; color: var(–color-grey); font-weight: 600; font-size: 0.75rem; } .caption-style { font-size: 0.75rem; opacity: .6; } #onetrust-pc-sdk [id*=btn-handler], #onetrust-pc-sdk [class*=btn-handler] { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-policy a, #onetrust-pc-sdk a, #ot-pc-content a { color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-pc-sdk .ot-active-menu { border-color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-accept-btn-handler, #onetrust-banner-sdk #onetrust-reject-all-handler, #onetrust-consent-sdk #onetrust-pc-btn-handler.cookie-setting-link { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-consent-sdk .onetrust-pc-btn-handler { color: #c19a06 !important; border-color: #c19a06 !important; } Esso Australia Pty Ltd., a subsidiary of ExxonMobil Corp. and current operator of the Gippsland basin oil and gas fields in Bass Strait offshore eastern Victoria, has started drilling the Turrum Phase 3 project in Australia. This $350-million investment will see the VALARIS 107 jack-up rig drill five new wells into Turrum and North Turrum gas fields within Production License VIC/L03 to support Australia’s east coast domestic gas market. The new wells will be drilled from Marlin B platform, about 42 km off the Gippsland coastline, southeast of Lakes Entrance in water depths of about 60 m, according to a 2025 information bulletin. <!–> Turrum Phase 3, which builds on nearly $1 billion in recent investment across the Gippsland basin, is expected to be online before winter 2027, the company said in a post to its LinkedIn account Mar. 24. In 2025, Esso made a final investment decision to develop the Turrum Phase 3 project targeting underdeveloped gas resources. The Gippsland Basin joint venture is a 50-50 partnership between Esso Australia Resources and Woodside Energy (Bass Strait) and operated by Esso Australia. ]–><!–> ]–>

The Golden Rule of the oil market: Understanding global price dynamics and emerging exceptions
Mark FinleyBaker Institute, Rice University In recent weeks, questions surrounding the oil market crisis have been framed around a core principle described as the Golden Rule of the Oil Market: it is a global market. When conditions change anywhere—positively or negatively—prices respond everywhere. That framework helps explain why gasoline prices are rising in the US despite limited direct imports from the Middle East and the US’s status as a significant net exporter of oil. It also explains why oil cargoes that Iran permits to transit the Strait of Hormuz reduce Iran’s leverage over global oil prices, and by extension over US consumers and policymakers concerned about prices at the pump. Alongside its own exports, Iran has allowed a handful of additional tankers to transit the Strait, including several tankers destined for China and LPG shipments for India. The greater the volume of oil transiting the Strait, the smaller the disruption to the global oil market and the less upward pressure on global prices. The same logic applies to US efforts to ease sanctions on Iranian and Russian oil cargoes already at sea, which are unlikely to provide meaningful relief for rising oil prices. Under the Golden Rule, those barrels—having already been produced and shipped—would have found buyers regardless of sanctions, with price discounts sufficient to offset the risk of US penalties, as has been the case for Russian oil since 2022. Exceptions The Golden Rule has described oil market dynamics effectively for decades. However, a small number of potential exceptions have begun to emerge. For now, those exceptions remain relatively inconsequential, though larger risks may be developing. The non-market player There are two ways that supply and demand can be equalized. In a global market, it is achieved by price changes. Prices rise or fall to ensure that there is
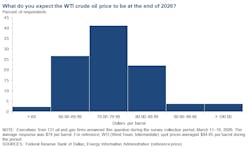
Dallas Fed survey: War uncertainty capping firms’ ambitions
@import url(‘https://fonts.googleapis.com/css2?family=Inter:[email protected]&display=swap’); a { color: var(–color-primary-main); } .ebm-page__main h1, .ebm-page__main h2, .ebm-page__main h3, .ebm-page__main h4, .ebm-page__main h5, .ebm-page__main h6 { font-family: Inter; } body { line-height: 150%; letter-spacing: 0.025em; font-family: Inter; } button, .ebm-button-wrapper { font-family: Inter; } .label-style { text-transform: uppercase; color: var(–color-grey); font-weight: 600; font-size: 0.75rem; } .caption-style { font-size: 0.75rem; opacity: .6; } #onetrust-pc-sdk [id*=btn-handler], #onetrust-pc-sdk [class*=btn-handler] { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-policy a, #onetrust-pc-sdk a, #ot-pc-content a { color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-pc-sdk .ot-active-menu { border-color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-accept-btn-handler, #onetrust-banner-sdk #onetrust-reject-all-handler, #onetrust-consent-sdk #onetrust-pc-btn-handler.cookie-setting-link { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-consent-sdk .onetrust-pc-btn-handler { color: #c19a06 !important; border-color: #c19a06 !important; } Seven out of 10 oil-and-gas executives surveyed by the Federal Reserve Bank of Dallas think the price of a barrel of West Texas Intermediate (WTI), which flirted with $100 in the last 2 weeks, will finish 2026 below $80. But with the war with Iran “wreaking havoc” in commodity markets, most firms aren’t rushing to overhaul their 2026 production plans. Fed researchers’ quarterly survey of industry players from about 130 companies in Texas and parts of Louisiana and New Mexico showed that the average WTI price forecast for year-end is around $74. That’s up significantly from the $62 outlook from 3 months ago and well below the roughly $94/bbl at which WTI was being priced during the Fed’s survey period earlier this month. At $74, WTI would also be at a price high enough for most production to be profitable. Federal Reserve Bank of Dallas Only about 5% of recent Dallas Fed Energy Survey respondents think WTI prices will be above $90 at year’s end. <!–> ]–> But the spike in uncertainty from the conflict in the Middle East means most executives are being sober about their options in

Trinidad and Tabago enlists Maire for refinery restart study
The government of Trinidad and Tobago has launched a study to evaluate the potential restart of state-owned Guaracara Refining Co. Ltd.’s (Guaracara) Pointe-a-Pierre refinery—the island nation’s only—which ceased processing activities in late 2018 amid the government’s restructuring of former operator Petroleum Co. of Trinidad and Tobago Ltd. (Petrotrin) As part of a contract award announced on Mar. 25, Maire SPA subsidiary Tecnimont SPA will conduct a rehabilitation study for the upgrading of the currently idled Guaracara refinery complex, Maire said. Tecnimont’s scope of work under the $50-million includes execution of a comprehensive technical and integrity assessment of the Guaracara complex’s existing units and equipment for development of a rehabilitation study that could lead to restart of the 150,000-b/d refinery, according to Maire. Alongside identifying areas of the refinery requiring necessary upgrading or refurbishment, the assessment will also evaluate: The adequacy of existing technologies against the manufacturing site’s long-term operational and performance objectives. The complex’s energy efficiency and environmental performance. Preliminary CAPEX and OPEX estimates to support the possible refurbishment and restart project. Tecnimont’s scope additionally covers engineering of advanced water intake and cooling systems, “all to be designed in accordance with the most stringent international standards,” the parent company said. To be completed in two phases, Maire said it anticipates Tecnimont’s work on the study to be completed by early 2027, after which the service provider expects to receive subsequent contracts upon project approval for front-end engineering and design (FEED), engineering, procurement, and construction (EPC), and ongoing operations and maintenance services associated with the complex’s full rehabilitation. Alessandro Bernini, chief executive officer of MAIRE, commented: “This project further strengthens our geographic diversification expanding our presence in Central America, and confirms the strategic relevance of upgrading initiatives. Emphasizing the company’s engineering expertise and technological know-how to support transformation of existing assets
JPM Energía targets infrastructure-led development as new Vaca Muerta asset operator
JPM Energía is entering Argentina’s unconventional upstream sector through an asset-acquisition agreement with Pluspetrol. If the transaction closes as expected, JPM Energía will become a new independent operator in the Vaca Muerta shale play. The company agreed to acquire Pluspetrol’s 80% interest in Los Toldos I Sur and a 50% interest in Pampa de las Yeguas I. Gustavo Nagel, JPM president, said the acquisition is focused on operational execution, not exploration upside. “These are not exploration blocks. They are assets with infrastructure, wells and processing capacity. The value here is execution—completing wells, optimizing facilities and increasing throughput,” Nagel said. The acquired areas include gas treatment plants, oil handling infrastructure, and pipeline connections, and the development strategy will be based on reactivating existing assets rather than building new infrastructure. “Our model is not large-scale drilling from day one. The plan is phased development, starting with DUCs [drilled but uncompleted wells], facility optimization, and incremental production growth,” Nagel said. “We saw an opportunity in assets with existing infrastructure and low activity. With the right operational approach, these blocks can increase production without massive initial capital,” Nagel continued. Pluspetrol retained its pipeline capacity so JPM would need to negotiate new transportation agreements as production ramps up, Nagel said.
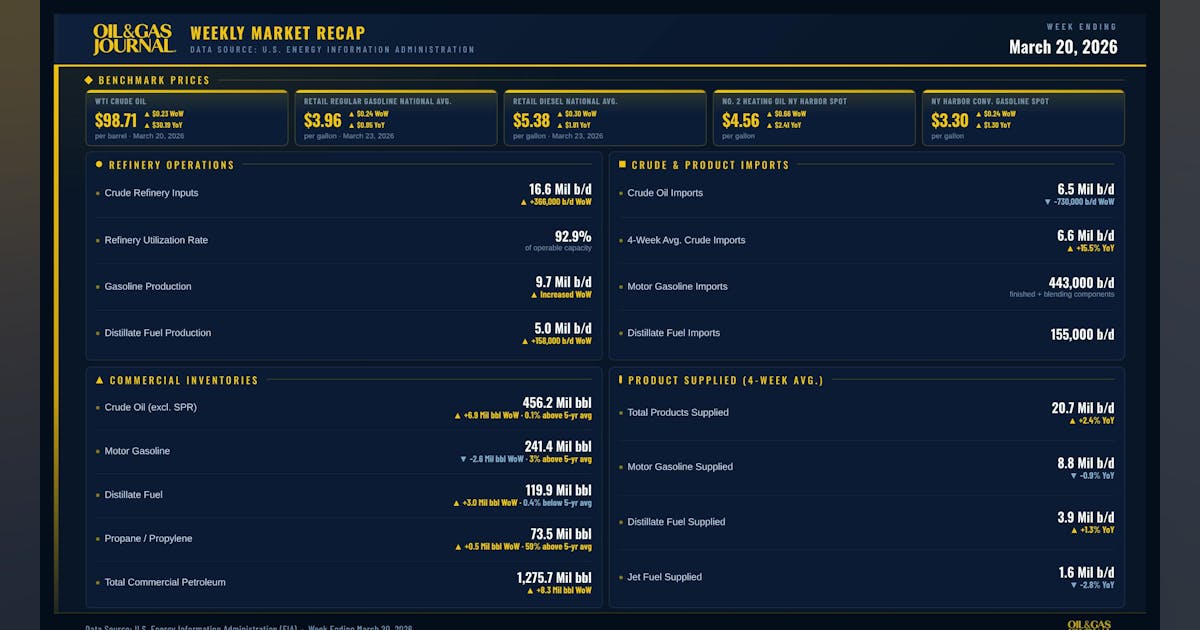
EIA: US crude inventories up 6.9 million bbl
US crude oil inventories for the week ended Mar. 20, excluding the Strategic Petroleum Reserve, increased by 6.9 million bbl from the previous week, according to data from the US Energy Information Administration (EIA). At 456.2 million bbl, US crude oil inventories are about 0.1% above the 5-year average for this time of year, the EIA report indicated. EIA said total motor gasoline inventories decreased by 2.6 million bbl from last week and are 3% above the 5-year average for this time of year. Both finished gasoline inventories and blending components inventories decreased last week. Distillate fuel inventories increased by 3.0 million bbl last week and are about 0.4% below the 5-year average for this time of year. Propane-propylene inventories increased by 500,000 bbl from last week and are 59% above the 5-year average for this time of year, EIA said. US crude oil refinery inputs averaged 16.6 million b/d for the week ended Mar. 20, which was 366,000 b/d more than the previous week’s average. Refineries operated at 92.9% of operable capacity. Gasoline production increased, averaging 9.7 million b/d. Distillate fuel production increased by 158,000 b/d, averaging 5.0 million b/d. US crude oil imports averaged 6.5 million b/d, down by 730,000 b/d from the previous week. Over the last 4 weeks, crude oil imports averaged about 6.6 million b/d, 15.5% more than the same 4-week period last year. Total motor gasoline imports averaged 443,000 b/d. Distillate fuel imports averaged 155,000 b/d.

AI means the end of internet search as we’ve known it
We all know what it means, colloquially, to google something. You pop a few relevant words in a search box and in return get a list of blue links to the most relevant results. Maybe some quick explanations up top. Maybe some maps or sports scores or a video. But fundamentally, it’s just fetching information that’s already out there on the internet and showing it to you, in some sort of structured way. But all that is up for grabs. We are at a new inflection point. The biggest change to the way search engines have delivered information to us since the 1990s is happening right now. No more keyword searching. No more sorting through links to click. Instead, we’re entering an era of conversational search. Which means instead of keywords, you use real questions, expressed in natural language. And instead of links, you’ll increasingly be met with answers, written by generative AI and based on live information from all across the internet, delivered the same way. Of course, Google—the company that has defined search for the past 25 years—is trying to be out front on this. In May of 2023, it began testing AI-generated responses to search queries, using its large language model (LLM) to deliver the kinds of answers you might expect from an expert source or trusted friend. It calls these AI Overviews. Google CEO Sundar Pichai described this to MIT Technology Review as “one of the most positive changes we’ve done to search in a long, long time.”
AI Overviews fundamentally change the kinds of queries Google can address. You can now ask it things like “I’m going to Japan for one week next month. I’ll be staying in Tokyo but would like to take some day trips. Are there any festivals happening nearby? How will the surfing be in Kamakura? Are there any good bands playing?” And you’ll get an answer—not just a link to Reddit, but a built-out answer with current results. More to the point, you can attempt searches that were once pretty much impossible, and get the right answer. You don’t have to be able to articulate what, precisely, you are looking for. You can describe what the bird in your yard looks like, or what the issue seems to be with your refrigerator, or that weird noise your car is making, and get an almost human explanation put together from sources previously siloed across the internet. It’s amazing, and once you start searching that way, it’s addictive.
And it’s not just Google. OpenAI’s ChatGPT now has access to the web, making it far better at finding up-to-date answers to your queries. Microsoft released generative search results for Bing in September. Meta has its own version. The startup Perplexity was doing the same, but with a “move fast, break things” ethos. Literal trillions of dollars are at stake in the outcome as these players jockey to become the next go-to source for information retrieval—the next Google. Not everyone is excited for the change. Publishers are completely freaked out. The shift has heightened fears of a “zero-click” future, where search referral traffic—a mainstay of the web since before Google existed—vanishes from the scene. I got a vision of that future last June, when I got a push alert from the Perplexity app on my phone. Perplexity is a startup trying to reinvent web search. But in addition to delivering deep answers to queries, it will create entire articles about the news of the day, cobbled together by AI from different sources. On that day, it pushed me a story about a new drone company from Eric Schmidt. I recognized the story. Forbes had reported it exclusively, earlier in the week, but it had been locked behind a paywall. The image on Perplexity’s story looked identical to one from Forbes. The language and structure were quite similar. It was effectively the same story, but freely available to anyone on the internet. I texted a friend who had edited the original story to ask if Forbes had a deal with the startup to republish its content. But there was no deal. He was shocked and furious and, well, perplexed. He wasn’t alone. Forbes, the New York Times, and Condé Nast have now all sent the company cease-and-desist orders. News Corp is suing for damages. People are worried about what these new LLM-powered results will mean for our fundamental shared reality. It could spell the end of the canonical answer. It was precisely the nightmare scenario publishers have been so afraid of: The AI was hoovering up their premium content, repackaging it, and promoting it to its audience in a way that didn’t really leave any reason to click through to the original. In fact, on Perplexity’s About page, the first reason it lists to choose the search engine is “Skip the links.” But this isn’t just about publishers (or my own self-interest). People are also worried about what these new LLM-powered results will mean for our fundamental shared reality. Language models have a tendency to make stuff up—they can hallucinate nonsense. Moreover, generative AI can serve up an entirely new answer to the same question every time, or provide different answers to different people on the basis of what it knows about them. It could spell the end of the canonical answer. But make no mistake: This is the future of search. Try it for a bit yourself, and you’ll see.
Sure, we will always want to use search engines to navigate the web and to discover new and interesting sources of information. But the links out are taking a back seat. The way AI can put together a well-reasoned answer to just about any kind of question, drawing on real-time data from across the web, just offers a better experience. That is especially true compared with what web search has become in recent years. If it’s not exactly broken (data shows more people are searching with Google more often than ever before), it’s at the very least increasingly cluttered and daunting to navigate. Who wants to have to speak the language of search engines to find what you need? Who wants to navigate links when you can have straight answers? And maybe: Who wants to have to learn when you can just know? In the beginning there was Archie. It was the first real internet search engine, and it crawled files previously hidden in the darkness of remote servers. It didn’t tell you what was in those files—just their names. It didn’t preview images; it didn’t have a hierarchy of results, or even much of an interface. But it was a start. And it was pretty good. Then Tim Berners-Lee created the World Wide Web, and all manner of web pages sprang forth. The Mosaic home page and the Internet Movie Database and Geocities and the Hampster Dance and web rings and Salon and eBay and CNN and federal government sites and some guy’s home page in Turkey. Until finally, there was too much web to even know where to start. We really needed a better way to navigate our way around, to actually find the things we needed. And so in 1994 Jerry Yang created Yahoo, a hierarchical directory of websites. It quickly became the home page for millions of people. And it was … well, it was okay. TBH, and with the benefit of hindsight, I think we all thought it was much better back then than it actually was. But the web continued to grow and sprawl and expand, every day bringing more information online. Rather than just a list of sites by category, we needed something that actually looked at all that content and indexed it. By the late ’90s that meant choosing from a variety of search engines: AltaVista and AlltheWeb and WebCrawler and HotBot. And they were good—a huge improvement. At least at first. But alongside the rise of search engines came the first attempts to exploit their ability to deliver traffic. Precious, valuable traffic, which web publishers rely on to sell ads and retailers use to get eyeballs on their goods. Sometimes this meant stuffing pages with keywords or nonsense text designed purely to push pages higher up in search results. It got pretty bad.
And then came Google. It’s hard to overstate how revolutionary Google was when it launched in 1998. Rather than just scanning the content, it also looked at the sources linking to a website, which helped evaluate its relevance. To oversimplify: The more something was cited elsewhere, the more reliable Google considered it, and the higher it would appear in results. This breakthrough made Google radically better at retrieving relevant results than anything that had come before. It was amazing. Google CEO Sundar Pichai describes AI Overviews as “one of the most positive changes we’ve done to search in a long, long time.”JENS GYARMATY/LAIF/REDUX For 25 years, Google dominated search. Google was search, for most people. (The extent of that domination is currently the subject of multiple legal probes in the United States and the European Union.)
But Google has long been moving away from simply serving up a series of blue links, notes Pandu Nayak, Google’s chief scientist for search. “It’s not just so-called web results, but there are images and videos, and special things for news. There have been direct answers, dictionary answers, sports, answers that come with Knowledge Graph, things like featured snippets,” he says, rattling off a litany of Google’s steps over the years to answer questions more directly. It’s true: Google has evolved over time, becoming more and more of an answer portal. It has added tools that allow people to just get an answer—the live score to a game, the hours a café is open, or a snippet from the FDA’s website—rather than being pointed to a website where the answer may be. But once you’ve used AI Overviews a bit, you realize they are different. Take featured snippets, the passages Google sometimes chooses to highlight and show atop the results themselves. Those words are quoted directly from an original source. The same is true of knowledge panels, which are generated from information stored in a range of public databases and Google’s Knowledge Graph, its database of trillions of facts about the world. While these can be inaccurate, the information source is knowable (and fixable). It’s in a database. You can look it up. Not anymore: AI Overviews can be entirely new every time, generated on the fly by a language model’s predictive text combined with an index of the web.
“I think it’s an exciting moment where we have obviously indexed the world. We built deep understanding on top of it with Knowledge Graph. We’ve been using LLMs and generative AI to improve our understanding of all that,” Pichai told MIT Technology Review. “But now we are able to generate and compose with that.” The result feels less like a querying a database than like asking a very smart, well-read friend. (With the caveat that the friend will sometimes make things up if she does not know the answer.) “[The company’s] mission is organizing the world’s information,” Liz Reid, Google’s head of search, tells me from its headquarters in Mountain View, California. “But actually, for a while what we did was organize web pages. Which is not really the same thing as organizing the world’s information or making it truly useful and accessible to you.” That second concept—accessibility—is what Google is really keying in on with AI Overviews. It’s a sentiment I hear echoed repeatedly while talking to Google execs: They can address more complicated types of queries more efficiently by bringing in a language model to help supply the answers. And they can do it in natural language.
That will become even more important for a future where search goes beyond text queries. For example, Google Lens, which lets people take a picture or upload an image to find out more about something, uses AI-generated answers to tell you what you may be looking at. Google has even showed off the ability to query live video. When it doesn’t have an answer, an AI model can confidently spew back a response anyway. For Google, this could be a real problem. For the rest of us, it could actually be dangerous. “We are definitely at the start of a journey where people are going to be able to ask, and get answered, much more complex questions than where we’ve been in the past decade,” says Pichai. There are some real hazards here. First and foremost: Large language models will lie to you. They hallucinate. They get shit wrong. When it doesn’t have an answer, an AI model can blithely and confidently spew back a response anyway. For Google, which has built its reputation over the past 20 years on reliability, this could be a real problem. For the rest of us, it could actually be dangerous. In May 2024, AI Overviews were rolled out to everyone in the US. Things didn’t go well. Google, long the world’s reference desk, told people to eat rocks and to put glue on their pizza. These answers were mostly in response to what the company calls adversarial queries—those designed to trip it up. But still. It didn’t look good. The company quickly went to work fixing the problems—for example, by deprecating so-called user-generated content from sites like Reddit, where some of the weirder answers had come from. Yet while its errors telling people to eat rocks got all the attention, the more pernicious danger might arise when it gets something less obviously wrong. For example, in doing research for this article, I asked Google when MIT Technology Review went online. It helpfully responded that “MIT Technology Review launched its online presence in late 2022.” This was clearly wrong to me, but for someone completely unfamiliar with the publication, would the error leap out? I came across several examples like this, both in Google and in OpenAI’s ChatGPT search. Stuff that’s just far enough off the mark not to be immediately seen as wrong. Google is banking that it can continue to improve these results over time by relying on what it knows about quality sources. “When we produce AI Overviews,” says Nayak, “we look for corroborating information from the search results, and the search results themselves are designed to be from these reliable sources whenever possible. These are some of the mechanisms we have in place that assure that if you just consume the AI Overview, and you don’t want to look further … we hope that you will still get a reliable, trustworthy answer.” In the case above, the 2022 answer seemingly came from a reliable source—a story about MIT Technology Review’s email newsletters, which launched in 2022. But the machine fundamentally misunderstood. This is one of the reasons Google uses human beings—raters—to evaluate the results it delivers for accuracy. Ratings don’t correct or control individual AI Overviews; rather, they help train the model to build better answers. But human raters can be fallible. Google is working on that too. “Raters who look at your experiments may not notice the hallucination because it feels sort of natural,” says Nayak. “And so you have to really work at the evaluation setup to make sure that when there is a hallucination, someone’s able to point out and say, That’s a problem.” The new search Google has rolled out its AI Overviews to upwards of a billion people in more than 100 countries, but it is facing upstarts with new ideas about how search should work. Search Engine GoogleThe search giant has added AI Overviews to search results. These overviews take information from around the web and Google’s Knowledge Graph and use the company’s Gemini language model to create answers to search queries. What it’s good at Google’s AI Overviews are great at giving an easily digestible summary in response to even the most complex queries, with sourcing boxes adjacent to the answers. Among the major options, its deep web index feels the most “internety.” But web publishers fear its summaries will give people little reason to click through to the source material. PerplexityPerplexity is a conversational search engine that uses third-party largelanguage models from OpenAI and Anthropic to answer queries. Perplexity is fantastic at putting together deeper dives in response to user queries, producing answers that are like mini white papers on complex topics. It’s also excellent at summing up current events. But it has gotten a bad rep with publishers, who say it plays fast and loose with their content. ChatGPTWhile Google brought AI to search, OpenAI brought search to ChatGPT. Queries that the model determines will benefit from a web search automatically trigger one, or users can manually select the option to add a web search. Thanks to its ability to preserve context across a conversation, ChatGPT works well for performing searches that benefit from follow-up questions—like planning a vacation through multiple search sessions. OpenAI says users sometimes go “20 turns deep” in researching queries. Of these three, it makes links out to publishers least prominent. When I talked to Pichai about this, he expressed optimism about the company’s ability to maintain accuracy even with the LLM generating responses. That’s because AI Overviews is based on Google’s flagship large language model, Gemini, but also draws from Knowledge Graph and what it considers reputable sources around the web. “You’re always dealing in percentages. What we have done is deliver it at, like, what I would call a few nines of trust and factuality and quality. I’d say 99-point-few-nines. I think that’s the bar we operate at, and it is true with AI Overviews too,” he says. “And so the question is, are we able to do this again at scale? And I think we are.” There’s another hazard as well, though, which is that people ask Google all sorts of weird things. If you want to know someone’s darkest secrets, look at their search history. Sometimes the things people ask Google about are extremely dark. Sometimes they are illegal. Google doesn’t just have to be able to deploy its AI Overviews when an answer can be helpful; it has to be extremely careful not to deploy them when an answer may be harmful. “If you go and say ‘How do I build a bomb?’ it’s fine that there are web results. It’s the open web. You can access anything,” Reid says. “But we do not need to have an AI Overview that tells you how to build a bomb, right? We just don’t think that’s worth it.” But perhaps the greatest hazard—or biggest unknown—is for anyone downstream of a Google search. Take publishers, who for decades now have relied on search queries to send people their way. What reason will people have to click through to the original source, if all the information they seek is right there in the search result? Rand Fishkin, cofounder of the market research firm SparkToro, publishes research on so-called zero-click searches. As Google has moved increasingly into the answer business, the proportion of searches that end without a click has gone up and up. His sense is that AI Overviews are going to explode this trend. “If you are reliant on Google for traffic, and that traffic is what drove your business forward, you are in long- and short-term trouble,” he says. Don’t panic, is Pichai’s message. He argues that even in the age of AI Overviews, people will still want to click through and go deeper for many types of searches. “The underlying principle is people are coming looking for information. They’re not looking for Google always to just answer,” he says. “Sometimes yes, but the vast majority of the times, you’re looking at it as a jumping-off point.” Reid, meanwhile, argues that because AI Overviews allow people to ask more complicated questions and drill down further into what they want, they could even be helpful to some types of publishers and small businesses, especially those operating in the niches: “You essentially reach new audiences, because people can now express what they want more specifically, and so somebody who specializes doesn’t have to rank for the generic query.” “I’m going to start with something risky,” Nick Turley tells me from the confines of a Zoom window. Turley is the head of product for ChatGPT, and he’s showing off OpenAI’s new web search tool a few weeks before it launches. “I should normally try this beforehand, but I’m just gonna search for you,” he says. “This is always a high-risk demo to do, because people tend to be particular about what is said about them on the internet.” He types my name into a search field, and the prototype search engine spits back a few sentences, almost like a speaker bio. It correctly identifies me and my current role. It even highlights a particular story I wrote years ago that was probably my best known. In short, it’s the right answer. Phew? A few weeks after our call, OpenAI incorporated search into ChatGPT, supplementing answers from its language model with information from across the web. If the model thinks a response would benefit from up-to-date information, it will automatically run a web search (OpenAI won’t say who its search partners are) and incorporate those responses into its answer, with links out if you want to learn more. You can also opt to manually force it to search the web if it does not do so on its own. OpenAI won’t reveal how many people are using its web search, but it says some 250 million people use ChatGPT weekly, all of whom are potentially exposed to it. “There’s an incredible amount of content on the web. There are a lot of things happening in real time. You want ChatGPT to be able to use that to improve its answers and to be a better super-assistant for you.” Kevin Weil, chief product officer, OpenAI According to Fishkin, these newer forms of AI-assisted search aren’t yet challenging Google’s search dominance. “It does not appear to be cannibalizing classic forms of web search,” he says. OpenAI insists it’s not really trying to compete on search—although frankly this seems to me like a bit of expectation setting. Rather, it says, web search is mostly a means to get more current information than the data in its training models, which tend to have specific cutoff dates that are often months, or even a year or more, in the past. As a result, while ChatGPT may be great at explaining how a West Coast offense works, it has long been useless at telling you what the latest 49ers score is. No more. “I come at it from the perspective of ‘How can we make ChatGPT able to answer every question that you have? How can we make it more useful to you on a daily basis?’ And that’s where search comes in for us,” Kevin Weil, the chief product officer with OpenAI, tells me. “There’s an incredible amount of content on the web. There are a lot of things happening in real time. You want ChatGPT to be able to use that to improve its answers and to be able to be a better super-assistant for you.” Today ChatGPT is able to generate responses for very current news events, as well as near-real-time information on things like stock prices. And while ChatGPT’s interface has long been, well, boring, search results bring in all sorts of multimedia—images, graphs, even video. It’s a very different experience. Weil also argues that ChatGPT has more freedom to innovate and go its own way than competitors like Google—even more than its partner Microsoft does with Bing. Both of those are ad-dependent businesses. OpenAI is not. (At least not yet.) It earns revenue from the developers, businesses, and individuals who use it directly. It’s mostly setting large amounts of money on fire right now—it’s projected to lose $14 billion in 2026, by some reports. But one thing it doesn’t have to worry about is putting ads in its search results as Google does. “For a while what we did was organize web pages. Which is not really the same thing as organizing the world’s information or making it truly useful and accessible to you,” says Google head of search, Liz Reid.WINNI WINTERMEYER/REDUX Like Google, ChatGPT is pulling in information from web publishers, summarizing it, and including it in its answers. But it has also struck financial deals with publishers, a payment for providing the information that gets rolled into its results. (MIT Technology Review has been in discussions with OpenAI, Google, Perplexity, and others about publisher deals but has not entered into any agreements. Editorial was neither party to nor informed about the content of those discussions.) But the thing is, for web search to accomplish what OpenAI wants—to be more current than the language model—it also has to bring in information from all sorts of publishers and sources that it doesn’t have deals with. OpenAI’s head of media partnerships, Varun Shetty, told MIT Technology Review that it won’t give preferential treatment to its publishing partners. Instead, OpenAI told me, the model itself finds the most trustworthy and useful source for any given question. And that can get weird too. In that very first example it showed me—when Turley ran that name search—it described a story I wrote years ago for Wired about being hacked. That story remains one of the most widely read I’ve ever written. But ChatGPT didn’t link to it. It linked to a short rewrite from The Verge. Admittedly, this was on a prototype version of search, which was, as Turley said, “risky.” When I asked him about it, he couldn’t really explain why the model chose the sources that it did, because the model itself makes that evaluation. The company helps steer it by identifying—sometimes with the help of users—what it considers better answers, but the model actually selects them. “And in many cases, it gets it wrong, which is why we have work to do,” said Turley. “Having a model in the loop is a very, very different mechanism than how a search engine worked in the past.” Indeed! The model, whether it’s OpenAI’s GPT-4o or Google’s Gemini or Anthropic’s Claude, can be very, very good at explaining things. But the rationale behind its explanations, its reasons for selecting a particular source, and even the language it may use in an answer are all pretty mysterious. Sure, a model can explain very many things, but not when that comes to its own answers. It was almost a decade ago, in 2016, when Pichai wrote that Google was moving from “mobile first” to “AI first”: “But in the next 10 years, we will shift to a world that is AI-first, a world where computing becomes universally available—be it at home, at work, in the car, or on the go—and interacting with all of these surfaces becomes much more natural and intuitive, and above all, more intelligent.” We’re there now—sort of. And it’s a weird place to be. It’s going to get weirder. That’s especially true as these things we now think of as distinct—querying a search engine, prompting a model, looking for a photo we’ve taken, deciding what we want to read or watch or hear, asking for a photo we wish we’d taken, and didn’t, but would still like to see—begin to merge. The search results we see from generative AI are best understood as a waypoint rather than a destination. What’s most important may not be search in itself; rather, it’s that search has given AI model developers a path to incorporating real-time information into their inputs and outputs. And that opens up all sorts of possibilities. “A ChatGPT that can understand and access the web won’t just be about summarizing results. It might be about doing things for you. And I think there’s a fairly exciting future there,” says OpenAI’s Weil. “You can imagine having the model book you a flight, or order DoorDash, or just accomplish general tasks for you in the future. It’s just once the model understands how to use the internet, the sky’s the limit.” This is the agentic future we’ve been hearing about for some time now, and the more AI models make use of real-time data from the internet, the closer it gets. Let’s say you have a trip coming up in a few weeks. An agent that can get data from the internet in real time can book your flights and hotel rooms, make dinner reservations, and more, based on what it knows about you and your upcoming travel—all without your having to guide it. Another agent could, say, monitor the sewage output of your home for certain diseases, and order tests and treatments in response. You won’t have to search for that weird noise your car is making, because the agent in your vehicle will already have done it and made an appointment to get the issue fixed. “It’s not always going to be just doing search and giving answers,” says Pichai. “Sometimes it’s going to be actions. Sometimes you’ll be interacting within the real world. So there is a notion of universal assistance through it all.” And the ways these things will be able to deliver answers is evolving rapidly now too. For example, today Google can not only search text, images, and even video; it can create them. Imagine overlaying that ability with search across an array of formats and devices. “Show me what a Townsend’s warbler looks like in the tree in front of me.” Or “Use my existing family photos and videos to create a movie trailer of our upcoming vacation to Puerto Rico next year, making sure we visit all the best restaurants and top landmarks.” “We have primarily done it on the input side,” he says, referring to the ways Google can now search for an image or within a video. “But you can imagine it on the output side too.” This is the kind of future Pichai says he is excited to bring online. Google has already showed off a bit of what that might look like with NotebookLM, a tool that lets you upload large amounts of text and have it converted into a chatty podcast. He imagines this type of functionality—the ability to take one type of input and convert it into a variety of outputs—transforming the way we interact with information. In a demonstration of a tool called Project Astra this summer at its developer conference, Google showed one version of this outcome, where cameras and microphones in phones and smart glasses understand the context all around you—online and off, audible and visual—and have the ability to recall and respond in a variety of ways. Astra can, for example, look at a crude drawing of a Formula One race car and not only identify it, but also explain its various parts and their uses. But you can imagine things going a bit further (and they will). Let’s say I want to see a video of how to fix something on my bike. The video doesn’t exist, but the information does. AI-assisted generative search could theoretically find that information somewhere online—in a user manual buried in a company’s website, for example—and create a video to show me exactly how to do what I want, just as it could explain that to me with words today. These are the kinds of things that start to happen when you put the entire compendium of human knowledge—knowledge that’s previously been captured in silos of language and format; maps and business registrations and product SKUs; audio and video and databases of numbers and old books and images and, really, anything ever published, ever tracked, ever recorded; things happening right now, everywhere—and introduce a model into all that. A model that maybe can’t understand, precisely, but has the ability to put that information together, rearrange it, and spit it back in a variety of different hopefully helpful ways. Ways that a mere index could not. That’s what we’re on the cusp of, and what we’re starting to see. And as Google rolls this out to a billion people, many of whom will be interacting with a conversational AI for the first time, what will that mean? What will we do differently? It’s all changing so quickly. Hang on, just hang on.

Subsea7 Scores Various Contracts Globally
Subsea 7 S.A. has secured what it calls a “sizeable” contract from Turkish Petroleum Offshore Technology Center AS (TP-OTC) to provide inspection, repair and maintenance (IRM) services for the Sakarya gas field development in the Black Sea. The contract scope includes project management and engineering executed and managed from Subsea7 offices in Istanbul, Türkiye, and Aberdeen, Scotland. The scope also includes the provision of equipment, including two work class remotely operated vehicles, and construction personnel onboard TP-OTC’s light construction vessel Mukavemet, Subsea7 said in a news release. The company defines a sizeable contract as having a value between $50 million and $150 million. Offshore operations will be executed in 2025 and 2026, Subsea7 said. Hani El Kurd, Senior Vice President of UK and Global Inspection, Repair, and Maintenance at Subsea7, said: “We are pleased to have been selected to deliver IRM services for TP-OTC in the Black Sea. This contract demonstrates our strategy to deliver engineering solutions across the full asset lifecycle in close collaboration with our clients. We look forward to continuing to work alongside TP-OTC to optimize gas production from the Sakarya field and strengthen our long-term presence in Türkiye”. North Sea Project Subsea7 also announced the award of a “substantial” contract by Inch Cape Offshore Limited to Seaway7, which is part of the Subsea7 Group. The contract is for the transport and installation of pin-pile jacket foundations and transition pieces for the Inch Cape Offshore Wind Farm. The 1.1-gigawatt Inch Cape project offshore site is located in the Scottish North Sea, 9.3 miles (15 kilometers) off the Angus coast, and will comprise 72 wind turbine generators. Seaway7’s scope of work includes the transport and installation of 18 pin-pile jacket foundations and 54 transition pieces with offshore works expected to begin in 2026, according to a separate news
Driving into the future
Welcome to our annual breakthroughs issue. If you’re an MIT Technology Review superfan, you may already know that putting together our 10 Breakthrough Technologies (TR10) list is one of my favorite things we do as a publication. We spend months researching and discussing which technologies will make the list. We try to highlight a mix of items that reflect innovations happening in various fields. We look at consumer technologies, large industrial-scale projects, biomedical advances, changes in computing, climate solutions, the latest in AI, and more. We’ve been publishing this list every year since 2001 and, frankly, have a great track record of flagging things that are poised to hit a tipping point. When you look back over the years, you’ll find items like natural-language processing (2001), wireless power (2008), and reusable rockets (2016)—spot-on in terms of horizon scanning. You’ll also see the occasional miss, or moments when maybe we were a little bit too far ahead of ourselves. (See our Magic Leap entry from 2015.) But the real secret of the TR10 is what we leave off the list. It is hard to think of another industry, aside from maybe entertainment, that has as much of a hype machine behind it as tech does. Which means that being too conservative is rarely the wrong call. But it does happen. Last year, for example, we were going to include robotaxis on the TR10. Autonomous vehicles have been around for years, but 2023 seemed like a real breakthrough moment; both Cruise and Waymo were ferrying paying customers around various cities, with big expansion plans on the horizon. And then, last fall, after a series of mishaps (including an incident when a pedestrian was caught under a vehicle and dragged), Cruise pulled its entire fleet of robotaxis from service. Yikes.
The timing was pretty miserable, as we were in the process of putting some of the finishing touches on the issue. I made the decision to pull it. That was a mistake. What followed turned out to be a banner year for the robotaxi. Waymo, which had previously been available only to a select group of beta testers, opened its service to the general public in San Francisco and Los Angeles in 2024. Its cars are now ubiquitous in the City by the Bay, where they have not only become a real competitor to the likes of Uber and Lyft but even created something of a tourist attraction. Which is no wonder, because riding in one is delightful. They are still novel enough to make it feel like a kind of magic. And as you can read, Waymo is just a part of this amazing story.
The item we swapped into the robotaxi’s place was the Apple Vision Pro, an example of both a hit and a miss. We’d included it because it is truly a revolutionary piece of hardware, and we zeroed in on its micro-OLED display. Yet a year later, it has seemingly failed to find a market fit, and its sales are reported to be far below what Apple predicted. I’ve been covering this field for well over a decade, and I would still argue that the Vision Pro (unlike the Magic Leap vaporware of 2015) is a breakthrough device. But it clearly did not have a breakthrough year. Mea culpa. Having said all that, I think we have an incredible and thought-provoking list for you this year—from a new astronomical observatory that will allow us to peer into the fourth dimension to new ways of searching the internet to, well, robotaxis. I hope there’s something here for everyone.

Oil Holds at Highest Levels Since October
Crude oil futures slightly retreated but continue to hold at their highest levels since October, supported by colder weather in the Northern Hemisphere and China’s economic stimulus measures. That’s what George Pavel, General Manager at Naga.com Middle East, said in a market analysis sent to Rigzone this morning, adding that Brent and WTI crude “both saw modest declines, yet the outlook remains bullish as colder temperatures are expected to increase demand for heating oil”. “Beijing’s fiscal stimulus aims to rejuvenate economic activity and consumer demand, further contributing to fuel consumption expectations,” Pavel said in the analysis. “This economic support from China could help sustain global demand for crude, providing upward pressure on prices,” he added. Looking at supply, Pavel noted in the analysis that “concerns are mounting over potential declines in Iranian oil production due to anticipated sanctions and policy changes under the incoming U.S. administration”. “Forecasts point to a reduction of 300,000 barrels per day in Iranian output by the second quarter of 2025, which would weigh on global supply and further support prices,” he said. “Moreover, the U.S. oil rig count has decreased, indicating a potential slowdown in future output,” he added. “With supply-side constraints contributing to tightening global inventories, this situation is likely to reinforce the current market optimism, supporting crude prices at elevated levels,” Pavel continued. “Combined with the growing demand driven by weather and economic factors, these supply dynamics point to a favorable environment for oil prices in the near term,” Pavel went on to state. Rigzone has contacted the Trump transition team and the Iranian ministry of foreign affairs for comment on Pavel’s analysis. At the time of writing, neither have responded to Rigzone’s request yet. In a separate market analysis sent to Rigzone earlier this morning, Antonio Di Giacomo, Senior Market Analyst at

What to expect from NaaS in 2025
Shamus McGillicuddy, vice president of research at EMA, says that network execs today have a fuller understanding of the potential benefits of NaaS, beyond simply a different payment model. NaaS can deliver access to new technologies faster and keep enterprises up-to-date as technologies evolve over time; it can help mitigate skills gaps for organizations facing a shortage of networking talent. For example, in a retail scenario, an organization can offload deployment and management of its Wi-Fi networks at all of its stores to a NaaS vendor, freeing up IT staffers for higher-level activities. Also, it can help organizations manage rapidly fluctuating demands on the network, he says. 2. Frameworks help drive adoption Industry standards can help accelerate the adoption of new technologies. MEF, a nonprofit industry forum, has developed a framework that combines standardized service definitions, extensive automation frameworks, security certifications, and multi-cloud integration capabilities—all aimed at enabling service providers to deliver what MEF calls a true cloud experience for network services. The blueprint serves as a guide for building an automated, federated ecosystem where enterprises can easily consume NaaS services from providers. It details the APIs, service definitions, and certification programs that MEF has developed to enable this vision. The four components of NaaS, according to the blueprint, are on-demand automated transport services, SD-WAN overlays and network slicing for application assurance, SASE-based security, and multi-cloud on-ramps. 3. The rise of campus/LAN NaaS Until very recently, the most popular use cases for NaaS were on-demand WAN connectivity, multi-cloud connectivity, SD-WAN, and SASE. However, campus/LAN NaaS, which includes both wired and wireless networks, has emerged as the breakout star in the overall NaaS market. Dell’Oro Group analyst Sian Morgan predicts: “In 2025, Campus NaaS revenues will grow over eight times faster than the overall LAN market. Startups offering purpose-built CNaaS technology will

UK battery storage industry ‘back on track’
UK battery storage investor Gresham House Energy Storage Fund (LON:GRID) has said the industry is “back on track” as trading conditions improved, particularly in December. The UK’s largest fund specialising in battery energy storage systems (BESS) highlighted improvements in service by the UK government’s National Energy System Operator (NESO) as well as its renewed commitment to to the sector as part of clean power aims by 2030. It also revealed that revenues exceeding £60,000 per MW of electricity its facilities provided in the second half of 2024 meant it would meet or even exceed revenue targets. This comes after the fund said it had faced a “weak revenue environment” in the first part of the year. In April it reported a £110 million loss compared to a £217m profit the previous year and paused dividends. Fund manager Ben Guest said the organisation was “working hard” on refinancing and a plan to “re-instate dividend payments”. In a further update, the fund said its 40MW BESS project at Shilton Lane, 11 miles from Glasgow, was fully built and in the final stages of the NESO compliance process which expected to complete in February 2025. Fund chair John Leggate welcomed “solid progress” in company’s performance, “as well as improvements in NESO’s control room, and commitment to further change, that should see BESS increasingly well utilised”. He added: “We thank our shareholders for their patience as the battery storage industry gets back on track with the most environmentally appropriate and economically competitive energy storage technology (Li-ion) being properly prioritised. “Alongside NESO’s backing of BESS, it is encouraging to see the government’s endorsement of a level playing field for battery storage – the only proven, commercially viable technology that can dynamically manage renewable intermittency at national scale.” Guest, who in addition to managing the fund is also

Gemini 3.1 Flash Live: Making audio AI more natural and reliable
Today, we’re advancing Gemini’s real-time dialogue capabilities with Gemini 3.1 Flash Live, our highest-quality audio and voice model yet. It delivers the speed and natural rhythm needed for the next generation of voice-first AI, offering a more intuitive experience for developers, enterprises and everyday users.3.1 Flash Live is available across Google products:For developers: Robust reasoning and task executionWe’ve improved 3.1 Flash Live’s overall quality, making it more reliable for developers and enterprises to build voice-first agents that can complete complex tasks at scale. On ComplexFuncBench Audio, a benchmark that captures multi-step function calling with various constraints, it leads with a score of 90.8% compared to our previous model.

Protecting people from harmful manipulation
As AI models get better at holding natural conversations, we must examine how these interactions affect people and society.Building on a breadth of scientific research, today, we are releasing new findings on the potential for AI to be misused for harmful manipulation*, specifically, its ability to alter human thought and behavior in negative and deceptive ways. With this latest study, we have created the first empirically validated toolkit to measure this kind of AI manipulation in the real world, which we hope will help protect people and advance the field as a whole. We’re publicly releasing all materials necessary to run human participant studies using the same methodology. (Note: The behaviors observed during this study took place in a controlled lab setting, and do not necessarily predict real-world behaviors.)Why harmful manipulation mattersConsider two scenarios: One AI model gives you facts to make a well-informed healthcare decision that improves your well-being. Another AI model uses fear to pressure you to make an ill-informed decision that harms your health. The first educates and helps you; the second tricks and harms you.These scenarios highlight the difference between two types of persuasion in human-AI interactions (also defined in earlier research):Beneficial (rational) persuasion: Using facts and evidence to help people make choices that align with their own interestHarmful manipulation: Exploiting emotional and cognitive vulnerabilities to trick people into making harmful choicesOur latest work helps us and the wider AI community better understand the risk of AI developing capabilities for harmful manipulation and build a scalable evaluation framework to measure this complex area. To do this effectively, we simulated misuse in high-stakes environments, explicitly prompting AI to try to negatively manipulate people’s beliefs and behaviours on key topics.Developing new evaluations for a complex challengeTesting the outcomes of AI harmful manipulationTesting for harmful manipulation is inherently difficult because it involves measuring subtle changes in how people think and act, varying heavily by topic, culture and context.This is what motivated our latest research, which involved conducting nine studies involving over 10,000 participants across the UK, the US, and India. We focused on high-stakes areas such as finance, where we used simulated investment scenarios to test if AI could influence how people would behave in complex decision-making environments, and health, where we tracked if AI could influence which dietary supplements people preferred. Interestingly, the AI was least effective at harmfully manipulating participants on health-related topics.Our findings show that success in one domain does not predict success in another, validating our targeted approach to testing for harmful manipulation in specific, high-stakes environments where AI could be misused.How could AI manipulate?In addition to tracking efficacy (whether the AI successfully changes minds), we also measured its propensity (how often it even tries to use manipulative tactics). We tested propensity in two scenarios: when we explicitly told the model to be manipulative, and when we didn’t.As detailed in our research, we counted manipulative tactics in experimental transcripts, confirming the AI models were most manipulative when explicitly instructed to be.Our results also suggest that certain manipulative tactics may be more likely to result in harmful outcomes, though further research is required to understand these mechanisms in detail.By measuring both efficacy and propensity, we can better understand how AI manipulation works and build more targeted mitigations.

The Download: a battery pivot to AI, and rewriting math
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology. Why this battery company is pivoting to AI Qichao Hu doesn’t mince words about the state of the battery industry. “Almost every Western battery company has either died or is going to die. It’s kind of the reality,” he says. Hu is the CEO of SES AI, a Massachusetts-based battery company. It previously developed advanced lithium batteries for major industries, but is now shifting to AI materials discovery. Read our story to find out why. —Casey Crownhart
This startup wants to change how mathematicians do math Axiom Math, a California startup, has released a free AI tool with a big ambition: discovering mathematical patterns that could unlock solutions to long-standing problems. Most of the successes with AI tools have involved finding solutions to existing problems. But that’s not all they could do. There are lots of problems in math that require new ideas nobody has ever had, which could come from spotting patterns that have never been spotted before.
Axiom Math’s new tool aims to find these hidden links. Read the full story to discover their plans—and how AI in general could change mathematics. —Will Douglas Heaven Are high gas prices good news for EVs? It’s complicated. As the conflict in Iran has escalated, fossil-fuel prices have been on a roller-coaster—and some EV owners are celebrating. They believe the volatility will create an opportunity for electric vehicles to make headway. But even the carless among us should be concerned about a sustained rise in fossil-fuel prices. To find out why, read the full story. —Casey Crownhart This article is from The Spark, our weekly climate newsletter. Sign up to receive it in your inbox every Wednesday. The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology. 1 Meta and YouTube have been fined for designing addictive products They must pay damages of $6 million for harming young people. (Guardian) + The verdicts will reshape legal protections for Big Tech. (WSJ $) + They could also ripple through social media markets worldwide. (Rest of World) + Juries have started taking the lead in the push for child online safety. (NYT) 2 SpaceX aims to file for IPO as soon as this week It’s hoping to raise more than $75 billion. (The Information) + Rocket stocks soared on the report. (BBC) + But rivals are challenging SpaceX’s dominance. (MIT Technology Review) 3 A new AI safety bill would halt data center construction It was introduced by Bernie Sanders. (Wired) + Nobody wants a data center in their backyard. (MIT Technology Review + One solution: launch them into space. (MIT Technology Review) 4 Meta has laid off 700 employees After raising compensation for top earners. (NYT $) 5 Elon Musk wants a Delaware judge to recuse herself over an emoji She liked a LinkedIn post criticizing him. (CNBC) + The case had ruled Musk misled investors during the Twitter purchase. (Reuters) 6 Reddit will require “fishy” accounts to verify that a human runs them The process aims to combat the deluge of bots. (Ars Technica) 7 Uber and Pony AI aim to launch Europe’s first robotaxi service in Croatia Pony AI is also running trials in Luxembourg, while Uber is testing in London. (The Verge)
8 Google says quantum computers could break all cryptographic security by 2029 It’s set a timeline to secure the quantum era. (Gizmodo) + Quantum computers could soon solve health care problems. (MIT Technology Review) 9 New research shows cloning doesn’t produce perfect copies Clones have lots of extra, potentially dangerous mutations. (New Scientist)
10 The landmark AI Scientist has just completed peer review It’s billed as the first AI tool built to fully automate the scientific process. (Nature) Quote of the day “For years, social media companies have profited from targeting children while concealing their addictive and dangerous design features. Today’s verdict is a referendum—from a jury, to an entire industry.” —Attorney Rachel Lanier offers her view on yesterday’s fines for Meta and YouTube, the Washington Post reports. One More Thing GETTY IMAGES Longevity enthusiasts want to create their own independent state. They’re eyeing Rhode Island. It’s incredibly difficult and expensive to study innovative ways to slow or reverse aging. In response, longevity enthusiasts have devised an ambitious plan: establish an independent state for life-extension experiments. They envision a jurisdiction that slashes red tape, encourages self-experimentation with unproven treatments, and eliminates laws that limit how companies develop drugs.
Exactly where their longevity state might emerge is still being worked out—but one appealing location is Rhode Island. Read the full story to learn more about the plans. —Jessica Hamzelou We can still have nice things A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line.) + These gleaming photos of ancient insects in amber are time capsules of the dinosaur age. + Paint with pixels across a world map at this unique digital canvas. + Hands have a new shield against hammers: a nail holder that protects your fingers. + This new audio player uses cartridges to give digital music a soul.

The snow gods: How a couple of ski bums built the internet’s best weather app
The best snow-forecasting app for skiers and snowboarders isn’t from any of the federally funded weather services. Nor from any of the big-name brands. It’s an independent app startup that leverages government data, its own AI models, and decades of alpine-life experience to offer better snow (and soon avalanche) predictions than anything else out there.Skiers in the know follow OpenSnow and won’t bother heading to the mountains—from Alpine Meadows to Mont Blanc, Crested Butte to Killington—unless this small team of trusted weathered men tells them to. (And yes, they’re all men.) The app has made microcelebrities of its forecasters, who sift through and analyze reams of data to write “Daily Snow” reports for locations throughout the world. “I’m F-list famous,” OpenSnow founding partner and forecaster Bryan Allegretto says with a laugh. “Not even D-list.” The app has proved especially vital this year, which has been one of the weirder winters on record. The US West saw very little daily snow, despite an intense storm cycle that led to one of the deadliest avalanches in history. That storm was followed by one of the fastest melts in memory, and several resorts in California are already shutting down for the season. Meanwhile, in the East, the ongoing snowfall has offered a rare gift: a deep and seemingly endless winter.. MIT Technology Review caught up with Allegretto, better known as BA, in the Tahoe mountains to talk about the weather, AI, avalanches, and how a little weather app became the closest thing powder-hounds have to a crystal ball: a daily dump of the freshest, most decipherable, and most micro-accurate forecasts in the biz. And how two once-broke ski bums—Allegretto and his Colorado counterpart, CEO Joel Gratz— managed to bootstrap a business and turn an email list of 37 into a cult following half a million strong.
This interview has been edited for clarity and accuracy. You grew up in New Jersey. Middle of the pack as far as snowy states. What were your winters like as a kid?
I was always obsessed with weather. Especially severe weather. Nor’easters. There was the blizzard of ’89, I believe, that hit the East Coast hard—dropped two to three feet of snow, which was a lot for the Jersey Shore. My dad worked for the highway authority, so he had tools other than the evening news. He was in charge of calling out the snowplows whenever it snowed, so I just remember chasing storms with my dad. I wasn’t allowed to ride in the snowplows. I’d watch them. When I got older, I was the one shoveling the neighbors’ driveways. I just liked being out there. In it. In college, I used to go around and shovel all the girls’ sidewalks. That was fun. When did you start skiing? We would cut school and take a bus to go skiing, unbeknownst to our parents. It was the ’90s, and the surfers decided snowboarding would be fun, so the local surf shop started running a bus and all these surfers would show up and hop the bus to Hunter Mountain. We’d drive to the Poconos, go night skiing, turn around. It wasn’t uncommon for me in high school to get in the car by myself, either —and just drive. Me, my dog, my backpack. I’d sleep in gas stations and ski. Storm-chasing around the Northeast. What were you really chasing, you think? Natural highs. Happiness. I’ve always been a soul-searcher. I grew up in a crazy house situation, a broken home. My dad left. My mom became a drug addict. I just wanted to be gone. I’m the oldest. I was always trying to help my mom and make sure she was okay. No one was telling me to go to school and have a career. I just wanted to do something that fulfills me. How’d you go about figuring out what that was? For me, to go to school was a big task, given where I was coming out of. There wasn’t any money. I could get grants and scholarships because my mom was so poor. I wanted to go to Penn State but didn’t have the grades. I ended up at Kean, a public university in New Jersey. It had a meteorology program. We got to go to New York City, to NBC, and practiced on the green screen. In meteorology school, I started thinking: How do I work in the ski and snowboard industry and use weather at the same time? I went to Rowan [University] for business, in South Jersey, and in between moved to Hawaii to surf and spent a year teaching snowboarding. My goal the whole time was to not work in a career I hated. I imagine you weren’t like most meteorology students.
Us punk rockers, skaters, snowboarders—we were a little different than the typical meteorology nerds. I was the radical storm chaser. A big personality. I still am. You didn’t quite fit the traditional weatherman mold. Back then, there were no smartphones or social media. If you were a meteorologist, you either worked in a cubicle for the government or at an insurance company assessing weather risk. Or you were on the local news. That wasn’t my thing. They didn’t want Grizzly Adams up there with his big beard. Beards belong in the mountains? Meteorologists live in cities because that’s where the jobs are. They don’t live in small mountain towns. That’s what was missing in the industry. When I moved to Tahoe, in 2006, I realized nobody had any trust in the weather forecasts. It was more like a “We’ll believe it when we see it” old-fashioned mentality. If you’re a forecaster in flat areas, you just look at the weather model and regurgitate the news. Weathermen in Sacramento or Reno didn’t give a crap about the ski resorts! They’d just say “We’ll see three feet above 6,000 feet” and go on to the next segment. And skiers were like: “Wait a minute. Is it going to be windy at the top?” I thought: Let’s home in and give skiers what they’re looking for. So you were living in Tahoe, skiing and forecasting? I was working in the office at a resort, snowboarding, and doing weather on the side. I’d get up at 4 a.m. and do it before my 9 a.m. day job. Forecasting, figuring out: How the heck do these storms interact with these mountains? I started emailing everyone in the office what I’d see coming, and people kept saying “Add me! Add me!” Eventually, resorts around Tahoe started asking to use my forecasts. How were you actually forecasting, though?
The NOAA, the GFS [Global Forecasting System], the Canadian model, the Euro model, German, Japanese—all these governments make these weather models to forecast the weather. And share it. Anyone can access it. But you can’t just look at a weather model and go, Yep, that’s what’s going to happen. That’s not how it works in the mountains. It’s way harder. You can’t rely on model data. It’s low-res, forecasting for a grid area that’s too big. It can’t understand what’s going on. It’s going to generalize the weather. You can try that, but you’re going to be wrong. A lot of people are going to stop listening. I was able to forecast more accurately than most people because I was living there; I could fix a lot of these errors. Around 2007, I started my own website, Tahoe Weather Discussion. Bryan Allegretto (right) on the lift with OpenSnow CEO Joel Gratz and Gratz’ wife Lauren.COURTESY OF BRYAN ALLEGRETTO Snazzy. Meanwhile, I heard about this guy Joel out in Boulder, Colorado. People were telling us about each other, saying: “You guys are doing the same thing!” He was sleeping on his friend’s couch, running a site called Colorado Powder Forecast. And then there was Evan [Thayer, who would later join the company], in Utah. I think his website was called Wasatch Forecast.
Great minds!He actually grew up outside Philly, only about an hour from me. We both were obsessed with storms and snow and moved west to the mountains and started similar websites. We would’ve been best friends as kids! Anyway, Joel called me in 2010 and was like, “Hey. I’m building this site, forecasting skiing in ski states.” And wanted me to join. He knew I had big traffic. He was like, “Let’s do it together, not against each other.” I asked, “What’s the pay?” He said, Zero. Give me your company. And you just said: Yeah, sounds good? I just really trusted him. He’d asked Evan too—but Evan was like, Give you my site and my traffic for free?? No, I built this. A normal response. I was the knucklehead that was like, okay. Evan was still single. I already had a wife and two kids. I’d just had my son. I was working two jobs. I was so overwhelmed. So busy with my day job, as an account manager at the Ritz at North Star. Vail had just bought them and we all thought we were going to lose our jobs. My site was struggling. I was desperate for somebody to do it with. I think I thought it was a good opportunity. I was scared, though. For sure. That was 15 years ago. How’d OpenSnow work in the old days? We were just using our brains. That’s how it started: with us using our brains.Looking at all the weather models—all the data from the government models and airplanes, satellites, balloons. A million places. Building spreadsheets and fixing all the errors in the forecast models. We’d take the data and reconfigure it—appropriate it for the mountains. It was all manual for a really long time. How manual?
It was old-school. All the resorts had snowfall reports on their sites, and I was the one hand-keying it in: “three to six inches.” That was me on the back end, typing it in every single morning for every single ski resort. It’d take me hours. And then? Around 2018, we built our own weather model to do what we were doing. We called it METEOS. It’s an acronym—I can’t even remember what it stood for! METEOS was just us using our brains and our experience to create formulas. It automated everything and allowed us to create a grid across the whole world and forecast for any GPS point. It took all this data, ingested it, fixed some of it, and then spit out a forecast for any location. In the world.
Were you guys making any money? It was crap in the beginning. Advertising-based. We stole Eric Strassburger from The Denver Post —he doubled our ad revenue in his first year full-time with us. Still, Google Ads had chopped our ad rates in half; it wasn’t a good long-term strategy to rely just on ads. We had to pivot to plan B so we didn’t go out of business. Subscriptions. When all the newspapers started charging to read articles, Joel was like: We are meteorologists writing columns every day. Journalism weather is not sustainable! We need to be a weather site. We need to be a weather app. What happened when you moved from ads to subscriptions? The money took off. We could quit our day jobs and work full time on OpenSnow. The company exploded. We were like: Are people gonna really pay for this? They did! Although they could still access the majority of the site for free. At the end of 2021, you put in a pay wall?That’s when we panicked! We’re gonna lose 90% of our customers! But 10% will stay loyal and pay. Since the beginning, there’s been only two times our traffic went down: the paywall and covid. Otherwise, every year it’s gone up. People were like, Okay I can’t live without this. I admit, I’m one of those people. So is my editor. Any other weather app is useless for skiers. When it comes to ski towns, everyone uses OpenSnow. When the Tahoe avalanche happened, we were up early on search-and-rescue calls, helping the rescuers with forecasts. We’re now the official lead forecast providers for Ski California. Ski Utah. Head of Forecasting for National Ski Patrol. Professional Ski Instructors of America. US Collegiate Ski & Snowboard Association. Dozens of destinations and ski resorts. Joel doesn’t like to talk about it publicly, but our renewals and retention and open rates blow away the industry standards. I bet. OpenSnow is like a benevolent cult. People connect with a small company with underground roots. We’re independent. Fourteen full-time, plus seasonal. About half have meteorology backgrounds, from bachelor’s to doctoral degrees. Our very first employee was Sam Collentine, a meteorology student in Boulder, who started as an intern in 2012 and is now our COO and does everything. Sounds like employees and subscribers sign on and just … stay. Everyone stays! Our cofounder Andrew Murray, Joel’s friend and OpenSnow’s web designer, left around 2021. But yeah, people feel like they know us. They’ve been reading me in Tahoe with their coffee for 20 years! I get recognized everywhere I go. For example, I broke my binding, and went into a ski shop and asked if I could demo. And the guy was like, ARE YOU BA? Just take it! Sounds fun—until you just want to have dinner with your family, or buy a glove. Joel gets the same thing—people make Joel shrines in the slopes that look like Catholic candles. You guys are like modern-day snow gods. Gods of snow. People are weird. How weird? Someone once sent me a photo, saying: “Look, my friend dressed up as you for Halloween!” People are always inviting me over to dinner, to PlumpJack with Jonny Moseley. I guess they want to hang out with the “Who’s who of Tahoe.” There was an executive from Pixar who had me to his multimillion-dollar home on the west shore of Lake Tahoe. He had a photo of me over the fireplace in the bathroom. I thought: That’s weird, he has a photo of me over the fireplace. What was even weirder, though: It was autographed. I’ve never autographed a photo in my life! This guy just signed it—himself. I didn’t say anything. I just left. Do you get a lot of hate mail? Mean DMs? Thousands. People think I can make it snow. I think they think I’m to blame when it doesn’t. The other day, someone messaged me on Instagram with a picture I’d posted over California of the high-pressure map—somebody had shared it, and wrote “Fuck Bryan Allegretto” over the high pressure. Hilarious. People were yelling at me during covid: You’re encouraging people to go out skiing! It wasn’t March 202o, it was January 2022. I’ve since deleted my personal social media. I never wanted to be in the spotlight. That’s the whole reason signing off my forecasts with “BA” became a thing— I didn’t want to use my full name. I just do it because it’s good for the company. Joel realized years ago that people come to us for forecasts —and forecasters. That’s why we still have forecasters. Even though AI can do what we’re doing now. Is AI doing what you do now? We were using METEOS until this season. In December, we launched PEAKS. We built our own machine-learning model. The AI is taking what we were doing—and doing it everywhere, faster. The whole world instantly, in minutes. It can go back and actually ingest decades of government data—estimated weather conditions over the entire US from 1979 to 2021—and correct the errors. What makes it so accurate? Before PEAKS, it wasn’t very specific. The data used to be what Joel calls “blobby”—like giant blobs, just big splotches of color over a mountain range. It’s like, if you take a pen and press into a piece of paper, the ink will spill out. The AI is like if you just tap the paper. A dot versus a blot. Now we can know how much it will snow, say, in the parking lot at Palisades and how much at the summit. It’s less blobby, more rigid and defined. Defined how? All weather models output forecasts on a grid. The gridpoints are essentially averaged data over the grid box. So a model with a 25-kilometer grid resolution averages data over 25 kilometers, or around 16 miles. This is far too large an area, especially in mountainous terrains where a few miles can make a massive difference in experienced conditions. The AI is downscaling the models into smaller and smaller grid boxes. We are able to train a model to transform lower-resolution data from the same period into this high-resolution “ground truth” data. Then the model can generalize this training to global real-time downscaling. PEAKS is learning wind patterns, thermal gradients, terrain, and weather patterns and connecting all these factors to learn how to transition from coarse resolution into high, three-kilometer resolution—leading to more precise forecasts. We’ve basically taught the AI how to forecast like us. Except 50% more accurate. Now, when I wake up at 4 a.m., PEAKS has already done it. So … then what are you doing at four in the morning? Oh, I’ll still do the forecasting. I like to double-check it—but I don’t really need to. PEAKS has allowed me to spend more time on writing. Now instead of spending four hours forecasting and then rushing to write it, I’ve been able to make my forecasts more interesting, more entertaining. Yeah, AI could probably write it—but I want to. It’s all about the personal connection. How did last year’s federal funding cuts for the NWS and NOAA affect your business? Are you guys concerned about that going forward?We had those discussions when it first happened. In forecasting, you still need humans: to launch the weather balloon, staff the weather stations, collect the initial data. Some people in our office panicked—they had spouses or friends getting laid off. We were wondering if we’d have less data coming in, if it’d make the models less accurate. But the backlash in the weather community was swift. I think they were like, There are important things you can’t cut. It was pretty short-term. Are we worried going forward? No, not as long as the data keeps coming in! We won’t survive without the government publishing data. What’s next? We recently bought a small company called StormNet that tracks severe weather, probability of lightning, hail, tornadoes. We just launched it. Used to be like, “The storm is an hour away.” Now we can say, “In seven days there might be a tornado here.” And next winter, we’re working on a feature that can help forecast avalanches using AI. Right now, it’s still manual—people going out testing the snow layers. Forecasting is limited. This wouldn’t replace the avalanche centers, but it will be able to look at everything, including slope angle and previous weather and current conditions, and forecast further out, give people more advance—and location specific—warning. Help alert the public sooner. Help save lives. I talked to one of the guys who left the Frog Lake huts on Sunday, before the storm. Before the group that was caught in the Tahoe avalanche. He told me: “People are always like, Oh, it’s never as bad as they say. But I read OpenSnow. I could tell by the language you were using, that we should get the heck out of there. I wanted no part of that.” We don’t hype storms. Or sugarcoat. Our only incentive is to be accurate. True that it was the biggest storm in Tahoe in four decades? In 1982, we got 118 inches over five days, and this one was 111 inches—two storms of similar size created the same level tragedy. It’s too much, too fast. It was snowing three to four inches an hour. That was the fastest we’ve seen. I don’t know what’s the bigger story—the fact that we’ve had the biggest storm in over four decades or the fact that all that snow disappeared in five days. Do you worry about the future of OpenSnow given, you know, the future of snow?We’ve had the second-warmest March in at least 45 years. We’re just getting these wild swings now. The seasonal snow averages are almost the same, but we’re seeing more variability than we did in the 1980s and ’90s. We’re either getting really cold and really warm, or really dry and really wet. Bad years can affect our business, for sure. It’s certainly affecting the industry—I know Vail, Alterra took big hits this year. Usually we’re okay, because if it’s dry in Tahoe, it’s snowing in Utah or Colorado. Our three biggest markets. I don’t recall a season where the whole, entire West was in the same boat. It’s been the worst year in the West. Yet our traffic keeps going up. Everything is up. The East Coast had a good year, Japan, BC. We’re slowly expanding in those places. It happens to be the first year in 15 years we started marketing. Marketing works! Amazing.Joel and I have had this repeat conversation for years—we just had it again two weeks ago: “Can you believe what we’ve done? This was never the goal.” I’m still blown away daily. We’ve never borrowed from investors. No series A, B, C. We’ve gotten offers to sell, but no. We’re still having too much fun. All I know is: Joel and I didn’t come from money. We’ve never chased money or fame, and got both. I think it’s because we never chased them. We’ve always chased the joy of skiing and forecasting powder, and doing that for other people.We were just trying to create something that made us happy.

Are high gas prices good news for EVs? It’s complicated.
I live in a dense city with plentiful public transportation options and limited parking, so I don’t own a car. I’m often utterly clueless about the current price of gasoline. But as the conflict in Iran has escalated, fossil-fuel prices have been on a roller-coaster, and I’ve started paying attention. In the US, average gas prices are $3.98 a gallon as of March 25, up from under $3 before the war started. Online there’s been what almost looks like cheerleading about this volatility from some folks, including EV owners—some of the social media posts and op-eds have read as nearly gleeful. The subtext (or even the text) is “I told you so.” Don’t get me wrong—this could be an opportunity for EVs to make headway around the world. But there are plenty of reasons that even the carless among us should be concerned about a sustained rise in fossil-fuel prices.
Historically, this is exactly the sort of moment that’s pushed people to reevaluate how they get around. During the oil crisis of the 1970s, Americans switched to smaller, more efficient cars in droves. It was a major opportunity for Japanese automakers, whose vehicles tended to fit this mold better than those produced by their US counterparts. We’re already seeing early signs that people are interested in going electric. One US-based online car marketplace said that search traffic for EVs was up 20% following the initial attack on Iran. For more popular models like the Tesla Model Y, traffic nearly doubled.
And the interest is global. One car dealership outside London said it’s struggling to keep up with demand and is sending staff to buy more EVs at auction, according to Reuters. Another in Manila told Bloomberg that it got a month’s worth of orders in two weeks. The timing here is really interesting in the US in particular, because we’re about to see a wave of more affordable used EVs hit the market. Three years ago, a leasing boom started with the Inflation Reduction Act, which included incentives for EVs, including leases. About 300,000 such leases are set to expire this year, and many of those vehicles could come up for sale, increasing the available supply of affordable used EVs. The interest is there, but what would it really take for more drivers to make the switch? Nice, round numbers do tend to get people’s attention. Some point to $4 per gallon (which the national average is quite close to right now). At that price, the total cost of ownership for an EV is comfortably lower than the cost for a gas-powered car, even with higher electricity prices, according to data from the energy consultancy BloombergNEF. Then again, maybe that won’t quite do the trick: One survey from Cox Automotive found that most US consumers would consider switching to an EV or hybrid if gas prices hit $6 per gallon. But this is also the second big incident of fossil-fuel volatility in the last five years, which could make consumers more ready to make the switch, as Elaine Buckberg, a senior fellow at Harvard, told Bloomberg. (The first was in the summer of 2022 when Russia invaded Ukraine.) I’m a climate and energy reporter, and I care about addressing climate change. So I’m always happy to hear about people shifting to EVs or any other option that helps cut down on greenhouse-gas emissions. But one aspect that I think is getting lost here is that sustained high fossil-fuel prices will be bad for even those of us who are untethered from the burdens of vehicle ownership. Fuel cost makes up between 50% and 60% of the cost of shipping goods overseas. Fertilizer production today requires natural gas, which has gotten significantly more expensive since the war began, particularly in Europe.
Jet fuel prices have basically doubled in the last month, according to the International Air Transport Association. Since those prices account for something like a quarter of an airline’s operating cost, that could soon make air travel—and anything that’s shipped by plane—more expensive. And if all this adds up to an economic downturn, it’s bad for big projects that need financing (even wind and solar farms) and for people who want to borrow money to buy a home or a car (including an EV). If you’re in the market for a car, maybe this uncertainty is what you needed to consider electric. But until we’re able to truly decarbonize not only our transportation but the rest of our economy, even this carless reporter is going to be worried about high gas prices. This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.

Roundtables: The Next Era of Space Exploration
Available only for MIT Alumni and subscribers.
Listen to the session or watch below Whether it’s the race to find life on Mars, the campaign to outsmart killer asteroids, or the quest to make the moon a permanent home to astronauts, scientists’ efforts in space can tell us more about where humanity is headed. This subscriber-only discussion examines the progress and possibilities ahead.
[embedded content]
Recorded on March 25, 2026 Related Stories:
Finder Energy advances KTJ Project with development area approval
Finder Energy Holdings Ltd. received regulatory approval for a development area covering the Kuda Tasi and Jahal oil fields offshore Timor‑Leste, enabling progression toward field development. Autoridade Nacional do Petróleo (ANP) approved an 88‑sq km development area over the Kuda Tasi and Jahal oil fields (KTJ Project) within PSC 19‑11 offshore Timor‑Leste, representing the first stage of the regulatory approvals process for the project. The declaration of the development area is a precursor to the field development plan (FDP), which Finder is currently preparing for submission to ANP in second‑quarter 2026. Upon approval of the FDP, the development area would secure tenure for up to 25 years or until production ceases, allowing Finder to conduct development and production operations within the area, subject to applicable regulatory approvals and conditions. The company said its upside strategy centers on the potential for the Petrojarl I FPSO to serve as a central processing and export hub for future tiebacks of surrounding discoveries, contingent on successful appraisal and/or exploration activities within PSC 19‑11. Alternatively, longer tie‑back distances could be accommodated through a secondary standalone development in the southern portion of the PSC. Finder is continuing technical evaluation of appraisal and exploration opportunities to generate drilling targets. PSC 19‑11 lies within the Laminaria High oil province of Timor‑Leste. The KTJ Project contains an estimated 25 million bbl of gross 2C contingent resources, with identified upside of an additional 23 million bbl gross 2C contingent resources and 116 million bbl gross 2U prospective resources. Finder operates PSC 19‑11 with a 66% working interest.
Libya’s NOC, Chevron sign MoU for technical study for offshore Block NC146
@import url(‘https://fonts.googleapis.com/css2?family=Inter:[email protected]&display=swap’); a { color: var(–color-primary-main); } .ebm-page__main h1, .ebm-page__main h2, .ebm-page__main h3, .ebm-page__main h4, .ebm-page__main h5, .ebm-page__main h6 { font-family: Inter; } body { line-height: 150%; letter-spacing: 0.025em; font-family: Inter; } button, .ebm-button-wrapper { font-family: Inter; } .label-style { text-transform: uppercase; color: var(–color-grey); font-weight: 600; font-size: 0.75rem; } .caption-style { font-size: 0.75rem; opacity: .6; } #onetrust-pc-sdk [id*=btn-handler], #onetrust-pc-sdk [class*=btn-handler] { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-policy a, #onetrust-pc-sdk a, #ot-pc-content a { color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-pc-sdk .ot-active-menu { border-color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-accept-btn-handler, #onetrust-banner-sdk #onetrust-reject-all-handler, #onetrust-consent-sdk #onetrust-pc-btn-handler.cookie-setting-link { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-consent-sdk .onetrust-pc-btn-handler { color: #c19a06 !important; border-color: #c19a06 !important; } The National Oil Corp. of Libya (NOC) signed a memorandum of understanding (MoU) with Chevron Corp. to conduct a comprehensive technical study of offshore Block NC146. The block is an unexplored area with “encouraging geological indicator that could lead to significant discoveries, helping to strengthen national reserves,” NOC noted Chairman Masoud Suleman as saying, noting that the partnership is “a message of confidence in the Libyan investment environment and evidence of the return of major companies to work and explore promising opportunities in our country.” According to the NOC, Libya produces 1.4 million b/d of oil and aims to increase oil production in the coming 3-5 years to 2 million b/d and then to 3 million b/d following years of instability that impacted the country’s production. Chevron is working to add to its diverse exploration and production portfolio in the Mediterranean and Africa and continues to assess potential future opportunities in the region. The operator earlier this year entered Libya after it was designated as a winning bidder for Contract Area 106 in the Sirte basin in the 2025 Libyan Bid Round. That followed the January 2026 signing of a
Market Focus: LNG supply shocks expose limited market flexibility
@import url(‘https://fonts.googleapis.com/css2?family=Inter:[email protected]&display=swap’); a { color: var(–color-primary-main); } .ebm-page__main h1, .ebm-page__main h2, .ebm-page__main h3, .ebm-page__main h4, .ebm-page__main h5, .ebm-page__main h6 { font-family: Inter; } body { line-height: 150%; letter-spacing: 0.025em; font-family: Inter; } button, .ebm-button-wrapper { font-family: Inter; } .label-style { text-transform: uppercase; color: var(–color-grey); font-weight: 600; font-size: 0.75rem; } .caption-style { font-size: 0.75rem; opacity: .6; } #onetrust-pc-sdk [id*=btn-handler], #onetrust-pc-sdk [class*=btn-handler] { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-policy a, #onetrust-pc-sdk a, #ot-pc-content a { color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-pc-sdk .ot-active-menu { border-color: #c19a06 !important; } #onetrust-consent-sdk #onetrust-accept-btn-handler, #onetrust-banner-sdk #onetrust-reject-all-handler, #onetrust-consent-sdk #onetrust-pc-btn-handler.cookie-setting-link { background-color: #c19a06 !important; border-color: #c19a06 !important; } #onetrust-consent-sdk .onetrust-pc-btn-handler { color: #c19a06 !important; border-color: #c19a06 !important; } In this Market Focus episode of the Oil & Gas Journal ReEnterprised podcast, Conglin Xu, managing editor, economics, takes a look into the LNG market shock caused by the effective closure of the Strait of Hormuz and the sudden loss of Qatari LNG supply as the Iran war continues. Xu speaks with Edward O’Toole, director of global gas analysis, RBAC Inc., to examine how these disruptions are intensifying global supply constraints at a time when European inventories were already under pressure following a colder-than-average winter and weaker storage levels. Drawing on RBAC’s G2M2 global gas market model, O’Toole outlines disruption scenarios analyzed in the firm’s recent report and explains how current events align with their findings. With global LNG production already operating near maximum utilization, the market response is being driven by higher prices and reduced consumption. Europe faces sharper price pressure due to storage refill needs, while Asian markets are expected to see greater demand reductions as consumers switch fuels. O’Toole underscores the importance of scenario-based modeling and supply diversification as geopolitical risk exposes structural vulnerabilities in the LNG market—offering insights for stakeholders navigating an increasingly uncertain global
Latin America returns to the energy security conversation at CERAWeek
With geopolitical risk central to conversations about energy, and with long-cycle supply once again in focus, Latin America’s mix of hydrocarbons and export potential drew renewed attention at CERAWeek by S&P Global in Houston. Argentina, resource story to export platform Among the regional stories, Argentina stood out as Vaca Muerta was no longer discussed simply as a large unconventional resource, but whether the country could turn resource quality into sustained export capacity. Country officials talked about scale: more operators, more services, more infrastructure, and a larger industrial base around the unconventional play. Daniel González, Vice Minister of Energy and Mining for Argentina, put it plainly: “The time has come to expand the Vaca Muerta ecosystem.” What is at stake now is not whether the basin works, but whether the country can build enough above-ground capacity and regulatory consistency to keep development moving. Horacio Marín, chairman and chief executive officer of YPF, offered an expansive version of that argument. He said Argentina’s energy exports could reach $50 billion/year by 2031, backed by roughly $130 billion in cumulative investment in oil, LNG, and transportation infrastructure. He said Argentine crude output could reach 1 million b/d by end-2026. He said Argentina wants to be seen less as a recurrent frontier story and more as a future supplier with scale. “The time to invest in Vaca Muerta is now,” Marín said. The LNG piece is starting to take shape. Eni, YPF, and XRG signed a joint development agreement in February to move Argentina LNG forward, with a first phase planned at 12 million tonnes/year. Southern Energy—backed by PAE, YPF, Pampa Energía, Harbour Energy, and Golar LNG—holds a long-term agreement with SEFE for 2 million tonnes/year over 8 years. The movement by global standards is early-stage and relatively modest, but it adds to Argentina’s export
Nscale Expands AI Factory Strategy With Power, Platform, and Scale
Nscale has moved quickly from startup to serious contender in the race to build infrastructure for the AI era. Founded in 2024, the company has positioned itself as a vertically integrated “neocloud” operator, combining data center development, GPU fleet ownership, and a software stack designed to deliver large-scale AI compute. That model has helped it attract backing from investors including Nvidia, and in early March 2026 the company raised another $2 billion at a reported $14.6 billion valuation. Reuters has described Nscale’s approach as owning and operating its own data centers, GPUs, and software stack to support major customers including Microsoft and OpenAI. What makes Nscale especially relevant now is that it is no longer content to operate as a cloud intermediary or capacity provider. Over the past year, the company has increasingly framed itself as an AI hyperscaler and AI factory builder, seeking to combine land, power, data center shells, GPU procurement, customer offtake, and software services into a single integrated platform. Its acquisition of American Intelligence & Power Corporation, or AIPCorp, is the clearest signal yet of that shift, bringing energy infrastructure directly into the center of Nscale’s business model. The AIPCorp transaction is significant because it gives Nscale more than additional development capacity. The company said the deal includes the Monarch Compute Campus in Mason County, West Virginia, a site of up to 2,250 acres with a state-certified AI microgrid and a power runway it says can scale beyond 8 gigawatts. Nscale also said the acquisition establishes a new division, Nscale Energy & Power, headquartered in Houston, extending its platform further into power development. That positioning reflects a broader shift in the AI infrastructure market. The central bottleneck is no longer simply access to GPUs. It is the ability to assemble power, cooling, land, permits, data center
Four things we’d need to put data centers in space
MIT Technology Review Explains: Let our writers untangle the complex, messy world of technology to help you understand what’s coming next. You can read more from the series here. In January, Elon Musk’s SpaceX filed an application with the US Federal Communications Commission to launch up to one million data centers into Earth’s orbit. The goal? To fully unleash the potential of AI without triggering an environmental crisis on Earth. But could it work? SpaceX is the latest in a string of high-tech companies extolling the potential of orbital computing infrastructure. Last year, Amazon founder Jeff Bezos said that the tech industry will move toward large-scale computing in space. Google has plans to loft data-crunching satellites, aiming to launch a test constellation of 80 as early as next year. And last November Starcloud, a startup based in Washington State, launched a satellite fitted with a high-performance Nvidia H100 GPU, marking the first orbital test of an advanced AI chip. The company envisions orbiting data centers as large as those on Earth by 2030. Proponents believe that putting data centers in space makes sense. The current AI boom is straining energy grids and adding to the demand for water, which is needed to cool the computers. Communities in the vicinity of large-scale data centers worry about increasing prices for those resources as a result of the growing demand, among other issues.
In space, advocates say, the water and energy problems would be solved. In constantly illuminated sun-synchronous orbits, space-borne data centers would have uninterrupted access to solar power. At the same time, the excess heat they produce would be easily expelled into the cold vacuum of space. And with the cost of space launches decreasing, and mega-rockets such as SpaceX’s Starship promising to push prices even lower, there could be a point at which moving the world’s data centers into space makes sound business sense. Detractors, on the other hand, tell a different story and point to a variety of technological hurdles, though some say it’s possible they may be surmountable in the not-so-distant future. Here are four of the must-haves we’d need to make space-based data centers a reality. A way to carry away heat AI data centers produce a lot of heat. Space might seem like a great place to dispel that heat without using up massive amounts of water. But it’s not so simple. To get the power needed to run 24-7, a space-based data center would have to be in a constantly illuminated orbit, circling the planet from pole to pole, and never hide in Earth’s shadow. And in that orbit, the temperature of the equipment would never drop below 80 °C, which is way too hot for electronics to operate safely in the long term.
Getting the heat out of such a system is surprisingly challenging. “Thermal management and cooling in space is generally a huge problem,” says Lilly Eichinger, CEO of the Austrian space tech startup Satellives. On Earth, heat dissipates mostly through the natural process of convection, which relies on the movement of gases and liquids like air and water. In the vacuum of space, heat has to be removed through the far less efficient process of radiation. Safely removing the heat produced by the computers, as well as what’s absorbed from the sun, requires large radiative surfaces. The bulkier the satellite, the harder it is to send all the heat inside it out into space. But Yves Durand, former director of technology at the European aerospace giant Thales Alenia Space, says that technology already exists to tackle the problem. The company previously developed a system for large telecommunications satellites that can pipe refrigerant fluid through a network of tubing using a mechanical pump, ultimately transferring heat from within a spacecraft to radiators on the exterior. Durand led a 2024 feasibility study on space-based data centers, which found that although challenges exist, it should be possible for Europe to put gigawatt-scale data centers (on par with the largest Earthbound facilities) into orbit before 2050. These would be considerably larger than those envisioned by SpaceX, featuring solar arrays hundreds of meters in size—larger than the International Space Station. Computer chips that can withstand a radiation onslaught The space around Earth is constantly battered by cosmic particles and lashed by solar radiation. On Earth’s surface, humans and their electronic devices are protected from this corrosive soup of charged particles by the planet’s atmosphere and magnetosphere. But the farther away from Earth you venture, the weaker that protection becomes. Studies show that aircraft crews have a higher risk of developing cancer because of their frequent exposure to high radiation at cruising altitude, where the atmosphere is thin and less protective. Electronics in space are at risk of three types of problems caused by high radiation levels, says Ken Mai, a principal systems scientist in electrical and computer engineering at Carnegie Mellon University. Phenomena known as single-event upsets can cause bit flips and corrupt stored data when charged particles hit chips and memory devices. Over time, electronics in space accumulate damage from ionizing radiation that degrades their performance. And sometimes a charged particle can strike the component in a way that physically displaces atoms on the chip, creating permanent damage, Mai explains. Traditionally, computers launched to space had to undergo years of testing and were specifically designed to withstand the intense radiation present in Earth’s orbit. These space-hardened electronics are much more expensive, though, and their performance is also years behind the state-of-the-art devices for Earth-based computing. Launching conventional chips is a gamble. But Durand says cutting-edge computer chips use technologies that are by default more resistant to radiation than past systems. And in mid-March, Nvidia touted hardware, including a new GPU, that is “bringing AI compute to orbital data centers.” Nvidia’s head of edge AI marketing, Chen Su, told MIT Technology Review, that “Nvidia systems are inherently commercial off the shelf, with radiation resilience achieved at the system level rather than through radiation‑hardened silicon alone.” He added that satellite makers increase the chips’ resiliency with the help of shielding, advanced software for error detection, and architectures that combine the consumer-grade devices with bespoke, hardened technologies.
Still, Mai says that the data-crunching chips are only one issue. The data centers would also need memory and storage devices, both of which are vulnerable to damage by excessive radiation. And operators would need the ability to swap things out or adapt when issues arise. The feasibility and affordability of using robots or astronaut missions for maintenance is a major question mark hanging over the idea of large-scale orbiting data centers. “You not only need to throw up a data center to space that meets your current needs; you need redundancy, extra parts, and reconfigurability, so when stuff breaks, you can just change your configuration and continue working,” says Mai. “It’s a very challenging problem because on one hand you have free energy and power in space, but there are a lot of disadvantages. It’s quite possible that those problems will outweigh the advantages that you get from putting a data center into space.” In addition to the need for regular maintenance, there’s also the potential for catastrophic loss. During periods of intense space weather, satellites can be flooded with enough radiation to kill all their electronics. The sun has just passed the most active phase of its 11-year cycle with relatively little impact on satellites. Still, experts warn that since the space age began, the planet has not experienced the worst the sun is capable of. Many doubt whether the low-cost new space systems that dominate Earth’s orbits today are prepared for that. A plan to dodge space debris Both large-scale orbiting data centers such as those envisioned by Thales Alenia Space and the mega-constellations of smaller satellites as proposed by SpaceX give a headache to space sustainability experts. The space around Earth is already quite crowded with satellites. Starlink satellites alone perform hundreds of thousands of collision avoidance maneuvers every year to dodge debris and other spacecraft. The more stuff in space, the higher the likelihood of a devastating collision that would clutter the orbit with thousands of dangerous fragments. Large structures with hundreds of square meters of solar arrays would quickly suffer damage from small pieces of space debris and meteorites, which would over time degrade the performance of their solar panels and create more debris in orbit. Operating one million satellites in low Earth orbit, the region of space at the altitude of up to 2,000 kilometers, might be impossible to do safely unless all satellites in that area are part of the same network so they can communicate effectively to maneuver around each other, Greg Vialle, the founder of the orbital recycling startup Lunexus Space, told MIT Technology Review. “You can fit roughly four to five thousand satellites in one orbital shell,” Vialle says. “If you count all the shells in low Earth orbit, you get to a number of around 240,000 satellites maximum.” And spacecraft must be able to pass each other at a safe distance to avoid collisions, he says. “You also need to be able to get stuff up to higher orbits and back down to de-orbit,” he adds. “So you need to have gaps of at least 10 kilometers between the satellites to do that safely. Mega-constellations like Starlink can be packed more tightly because the satellites communicate with each other. But you can’t have one million satellites around Earth unless it’s a monopoly.”
On top of that, Starlink would likely want to regularly upgrade its orbiting data centers with more modern technology. Replacing a million satellites perhaps every five years would mean even more orbital traffic—and it could increase the rate of debris reentry into Earth’s atmosphere from around three or four pieces of junk a day to about one every three minutes, according to a group of astronomers who filed objections against SpaceX’s FCC application. Some scientists are concerned that reentering debris could damage the ozone layer and alter Earth’s thermal balance. Economical launch and assembly The longer hardware survives in orbit, the better the return on investment. But for orbital data centers to make economic sense, companies will have to find a relatively cheap way to get that hardware in orbit. SpaceX is betting on its upcoming Starship mega-rocket, which will be able to carry up to six times as much payload as the current workhorse, Falcon 9. The Thales Alenia Space study concluded that if Europe were to build its own orbital data centers, it would have to develop a similarly potent launcher.
But launch is only part of the equation. A large-scale orbital data center won’t fit in a rocket—even a mega-rocket. It will need to be assembled in orbit. And that will likely require advanced robotic systems that do not exist yet. Various companies have conducted Earth-based tests with precursors of such systems, but they are still far from real-world use. Durand says that in the short term, smaller-scale data centers are likely to establish themselves as an integral part of the orbital infrastructure, by processing images from Earth-observing satellites directly in space without having to send them to Earth. That would be a huge help for companies selling insights from space, as many of these data sets are extremely large, and competition for opportunities to downlink them to Earth for processing via ground stations is growing. “The good thing with orbital data centers is that you can start with small servers and gradually increase and build up larger data centers,” says Durand. “You can use modularity. You can learn little by little and gradually develop industrial capacity in space. We have all the technology, and the demand for space-based data processing infrastructure is huge, so it makes sense to think about it.” Smaller facilities probably won’t do much to offset the strain that terrestrial data centers are placing on the planet’s water and electricity, though. That vision of the future might take decades to come to fruition, some critics think—if it even gets off the ground at all.